显存大就一定跑得快?一文看懂AI芯片容量与带宽的核心误区

显存大就一定跑得快?一文看懂AI芯片容量与带宽的核心误区

GPUS Lady
发布于 2026-06-29 13:24:41
发布于 2026-06-29 13:24:41

在AI大模型算力芯片的宣传中,显存容量一直是最抓人眼球的参数。近期AMD新一代AI加速卡MI455X对标英伟达Rubin芯片,凭借1.5倍的显存容量赚足了关注度。很多人会理所当然认为:显存更大的AMD芯片,生成AI文本Token的速度一定更快。
但事实恰恰相反:纸面显存更大的MI455X,大模型推理速度反而略逊于Rubin。这背后藏着绝大多数人都分不清的两个关键概念:显存容量和显存带宽。二者看似都和内存相关,却决定了AI芯片完全不同的性能上限,今天我们结合两款旗舰芯片,一次性讲透其中底层逻辑。
一、同源显存硬件:同款HBM4,两家厂商走了两条路
首先破除第一个误区:AMD MI455X和英伟达Rubin,用的是完全一模一样的基础显存颗粒。
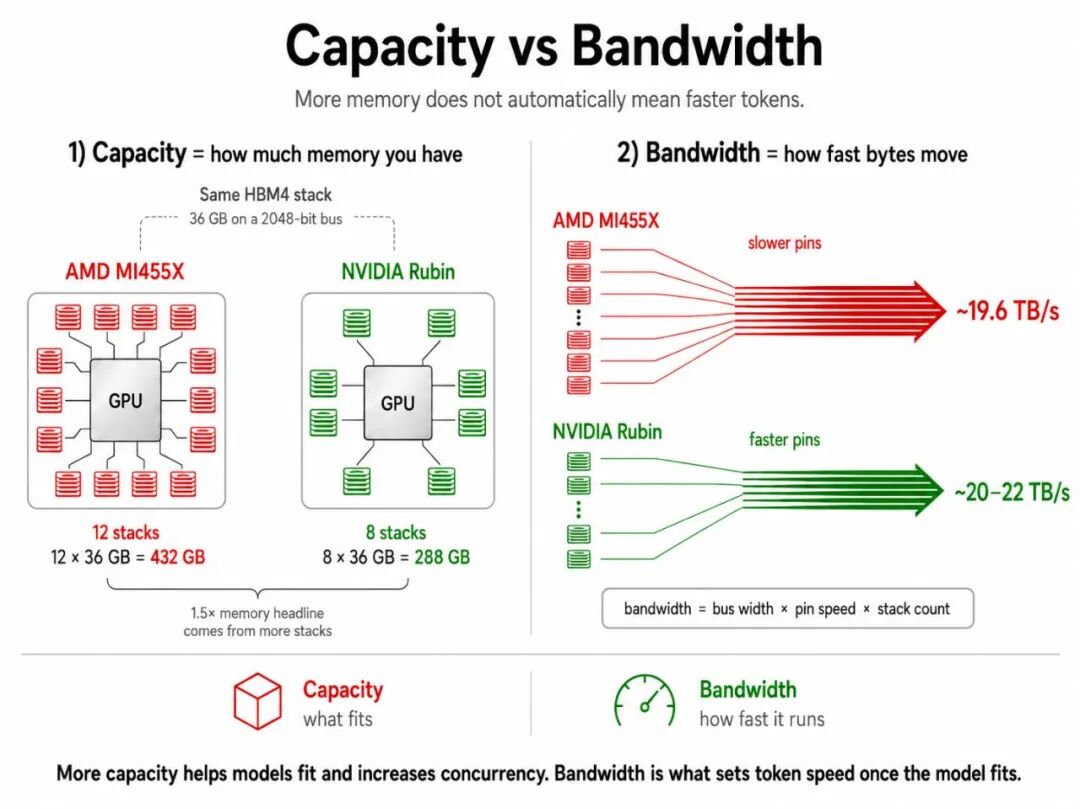
两款芯片均搭载单颗36GB容量的HBM4高带宽显存堆栈,统一采用2048位位宽总线,硬件底子毫无区别。最终显存参数拉开差距,并不是硬件用料不同,而是两家厂商做了两个完全相反的设计决策:显存堆栈数量、显存引脚运行频率。
决策1:堆更多显存堆栈,拉高总容量
AMD选择堆料扩容:单颗MI455X搭载12组HBM4显存堆栈,总显存容量达到432GB。
英伟达选择精简堆栈:Rubin仅搭载8组HBM4显存堆栈,总显存容量为288GB。
432GB对比288GB,刚好就是市面上宣传的1.5倍显存差距,这也是大众最直观能看到的参数差异。
决策2:调整显存频率,改变数据传输速度
如果AMD只多堆4组显存堆栈,带宽理应远超对手,但两家厂商在显存频率上走向了完全相反的方向,直接抹平了堆栈数量带来的带宽差距:
- AMD MI455X:降频运行。为了保证多堆栈运行稳定性,AMD刻意压低显存引脚频率,单引脚速率仅6.4Gbps,低于HBM4官方标准最高规格。靠更多的堆栈数量补齐带宽,最终整机显存带宽为19.6TB/s。
- 英伟达Rubin:超频拉满。英伟达放弃更多堆栈数量,全力拉高显存运行频率,单引脚速率突破10Gbps,超过HBM4官方额定上限。依靠极致的高频,8组高速堆栈实现了不输甚至反超AMD的带宽,官方标称带宽22TB/s,正式上市后大概率回落至20TB/s左右。 核心结论:更多显存堆栈≠更高显存带宽。 AMD用数量换容量,英伟达用频率换速度,同款HBM4显存,走出了两种截然不同的产品定位。
二、硬核科普:容量和带宽,到底分别管什么?
很多普通人甚至行业入门从业者,都会混淆这两个参数,我们用通俗的仓库比喻一秒理解:
- 显存容量(仓库大小):仓库能放下多少货物。决定你的大模型能不能完整装进显卡、能同时承接多少条用户对话请求。
- 显存带宽(仓库大门通行速度):仓库大门每秒能运出多少货物。决定了每次调取模型数据、生成文字Token有多快。
放到大模型推理场景中,逻辑更加清晰:大模型解码生成每一个Token时,需要从显存中读取一次全部激活权重参数。Token生成速度=显存带宽÷模型大小。
在这个核心公式里,显存容量完全没有参与计算。只要模型能够完整装入显存,后续生成文本的快慢,只由显存带宽决定。这也是为什么8位量化模型换成4位量化模型,推理速度直接翻倍:需要搬运的数据量减半,无需改动芯片算力,速度直接提升。
三、两款芯片优劣拆解:大显存不等于高性能
1. 英伟达Rubin:更快的单请求推理速度
Rubin拥有更高的显存带宽,面对已经装入显存的大模型,单次对话生成文字速度更快,延迟更低。适合对单轮响应速度、低延迟有极致要求的场景,比如实时对话机器人、AI实时文案生成、交互式AI服务。
同时英伟达还有独家兜底方案:在HBM4高速显存之外,搭配大容量低速CPU内存组成分级显存架构。部分场景下可以借用系统内存扩容,模糊纯HBM显存的容量短板。
2. AMD MI455X:更强的多并发、大模型承载能力
虽然MI455X带宽略低,单条对话生成Token稍慢,但432GB超大显存带来了两大核心优势:
- 可承载更大规格大模型:无需多卡拆分模型,单卡就能运行更大参数的原生大模型,降低集群部署难度;
- 并发能力近乎翻倍:可以容纳更多上下文KV缓存,同时承接近两倍的长文本对话请求,适合大规模离线推理、云端高并发AI服务、长文档问答场景。
四、写给所有人的选购避坑指南
看完两款旗舰芯片的设计博弈,我们可以总结出通用的AI芯片参数避坑技巧,不管是采购服务器还是看懂行业资讯都适用:
- 不要迷信显存容量倍率:看到“显存大一倍”“显存大50%”的宣传,不要直接等同于性能更强,容量只决定能不能装下模型、能跑多少并发;
- 看推理速度认准显存带宽:实时AI对话、低延迟生成场景,显存带宽才是第一核心指标;
- HBM4的核心进化意义:新一代HBM4将显存位宽翻倍至2048位,本质就是让厂商可以自由取舍容量和带宽:想要大显存就多堆栈降频率,想要高带宽就少堆栈提频率,二者可以独立优化,不再绑定。
结语
AMD MI455X和英伟达Rubin没有绝对的输赢,只是两家厂商基于自身生态,做出了不同的取舍:AMD主打大容量、高并发,英伟达主打高带宽、低延迟。
往后再看到AI芯片显存相关宣传,别再被单纯的容量数字误导。记住一句话:容量决定上限有多大,带宽决定跑得多快,二者同源但互不等同。看懂这两个参数,才算真正看懂AI芯片的内存实力。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-28,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号