Gemma4 技术解析:一款实用的开源模型新选择

Gemma4 技术解析:一款实用的开源模型新选择

HELLO程序员
发布于 2026-06-26 21:19:09
发布于 2026-06-26 21:19:09
Gemma 4是谷歌最新、最强的AI模型,直接打破所有人预期,堪称国产大模型最能打的开源平替之一。
而且它跟Claude Code适配得堪称天衣无缝,我直接狂喜——终于能舒舒服服用谷歌AI模型,搭配Claude Code写代码了。

不过在你划走之前,咱先唠明白两个核心问题:
我们真的还需要一款谷歌新模型吗?它跟其他Gemini系列又有啥不一样?
Gemma 4
谷歌过去一年发了不少AI模型,但Gemma 4能脱颖而出,全靠这三大杀招:
- Apache 2.0开源协议:商用、微调、部署全放开,没任何限制
- 天生为智能体工作流打造:原生支持函数调用、结构化JSON输出、多步推理
- 本地硬件就能跑:小到树莓派,大到工作站显卡,通通拿捏
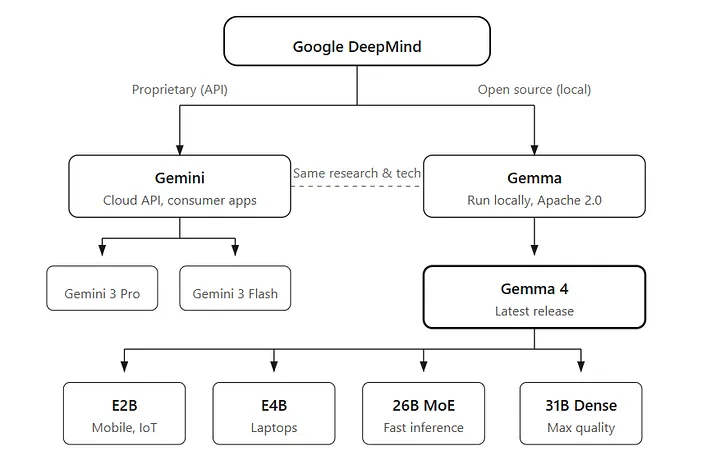
模型家族
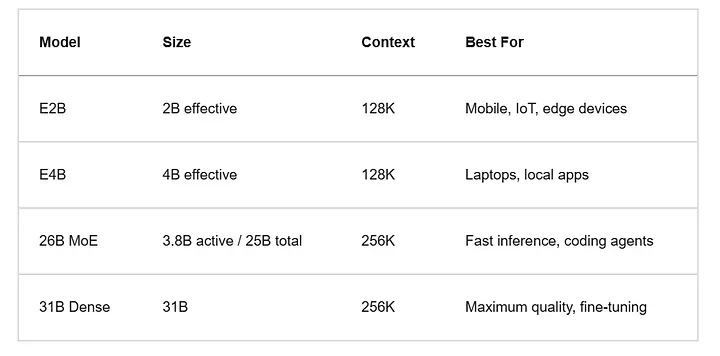
Gemma 4一共四款型号,针对性适配不同硬件和场景:
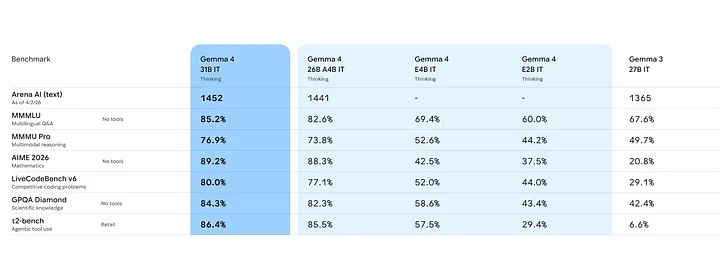
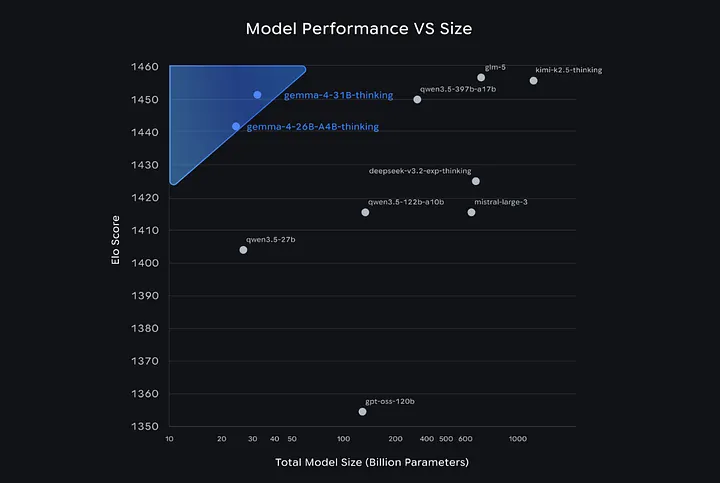
其中31B版本目前登顶Arena AI开源模型榜第三名,性能直接吊打体量是它20倍的模型。
这篇文章我就给大家扒透Gemma 4到底有啥硬实力,为啥开发者都该把它当成同类模型的首选平替。
Gemma 4核心亮点
Gemma 4的技术底子和Gemini 3同源,都是谷歌顶尖研究成果。
区别在于——它不用依赖谷歌云,你本地就能直接跑。
对开发者来说,这波更新简直戳中爽点:
推理能力&多步逻辑
Gemma 4上手就能搞定复杂推理,全系型号都支持可调节思考模式。
想快出结果就切快速响应,要深度分析就开分步推理,按需切换超灵活。
在2026年AIME数学基准测试里,31B版本不靠外部工具直接拿下89.2%的正确率。对比下就知道有多夸张:Gemma 3在同一场测试里才20.8%。
多模态支持
四款模型全都能处理文本+图像,还支持任意长宽比和分辨率。
更小的E2B、E4B版本还原生支持音频输入,能直接做语音识别。
做应用时要解析文档、图表、截图再搭配文本提示?这功能直接刚需拉满。
更长上下文窗口
边缘型号E2B、E4B支持128K tokens,大尺寸的26B、31B直接拉满256K tokens。
实际用起来,一整份代码库、长篇文档整个塞进提示词就行,不用费劲拆分切块。
代码生成能力
Gemma 4在LiveCodeBench v6基准测试斩获80%正确率,31B版本Codeforces ELO评分高达2150。
作为能离线本地跑的开源模型,这分数简直是降维打击。
覆盖140+种语言
谷歌给Gemma 4原生训练了140多种语言。
做全球化产品不用再给不同地区单独微调模型,一步到位。
专为开发者量身打造
跟前几代Gemma不一样,之前版本还有使用限制,商用部署麻烦得要命,这次Gemma 4直接用上Apache 2.0协议。
随便微调、随便上生产、随便基于它做产品卖钱,协议问题完全不用愁。
本地运行优势
本地跑模型,三大核心好处直接拉满:
- 隐私拉满:代码和数据全程留在本地,绝不外泄
- 零成本推理:硬件到位之后,推理完全免费
- 低延迟:响应速度全看你显卡性能,快到飞起
对处理敏感代码、身处强监管行业的开发者来说,这一点比跑分重要一万倍。
硬件适配要求
模型尺寸直接对应硬件档位:
26B混合专家模型推理时仅激活38亿参数,所以显存占用比预想低得多,运行速度也比31B纯稠密模型更快。

无缝集成主流工具
Gemma 4发布即适配咱们日常用的所有工具:
- Ollama:一条命令拉取运行
- Hugging Face:Transformers、TRL、vLLM全支持
- Claude Code:通过Ollama直接集成
- LM Studio:本地模型管理GUI
- Google AI Studio:网页端测试26B和31B版本
搭配Claude Code使用Gemma 4
现在Claude Code已经打通Ollama,能直接切换任意本地模型,Gemma 4自然也不在话下。
部署三步搞定:
第一步:安装Ollama
没装过Ollama的直接复制命令:
# macOS / Linux
curl -fsSL https://ollama.com/install.sh | sh
# Windows(PowerShell)
irm https://ollama.com/install.ps1 | iex
第二步:拉取Gemma 4
根据自己硬件选型号:
# 笔记本适配(下载9.6GB)
ollama pull gemma4:e4b
# 18GB+显存工作站
ollama pull gemma4:26b
# 顶配画质(20GB+显存)
ollama pull gemma4:31b
第三步:启动Claude Code加载Gemma 4
ollama launch claude --model gemma4
按照上面三步操作,就能轻松让Claude Code搭载Gemma 4跑起来,不管是日常写代码、调试程序,还是处理多模态任务,都能感受到这款开源模型的强悍实力。其实对开发者来说,Gemma 4的最大价值,从来不是单纯的跑分碾压,而是“开源无限制+本地可运行”的双重自由——不用受制于云服务的配额和隐私顾虑,也不用为商用授权头疼,拿过来就能用、能改、能落地。无论是个人开发者练手、小团队快速迭代产品,还是企业部署敏感场景应用,Gemma 4都能hold住场面。后续随着社区的优化和适配,它的潜力只会更大,感兴趣的朋友不妨赶紧上手试试,说不定会打开AI开发的新玩法~
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-07,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号