SimpleTIR如何破解大模型多轮工具推理的“训练魔咒”?

SimpleTIR如何破解大模型多轮工具推理的“训练魔咒”?

唐国梁Tommy
发布于 2026-06-25 21:10:10
发布于 2026-06-25 21:10:10
今天,我们要深入探讨一个在AI领域,特别是大模型(LLM)能力扩展方面,既令人兴奋又充满挑战的话题——工具使用。
现在的AI助手不仅能和你聊天,还能帮你编写代码、分析数据、调用API,甚至像一个初级研究员那样,通过多步骤的工具使用来解决复杂的科学问题。这就是工具集成推理(Tool-Integrated Reasoning, TIR)。

然而,当我们尝试使用强化学习(RL)——这种让AI通过“试错”来学习的强大范式——去训练一个能够进行多轮次工具交互的智能体时,常常会遇到一个令人头疼的“拦路虎”:训练过程极其不稳定,模型性能说崩就崩。
今天,我们介绍的这篇论文《SimpleTIR: End-to-End Reinforcement Learning for Multi-Turn Tool-Integrated Reasoning》,就为我们提供了一把驯服这头“狂野巨兽”的钥匙。它不仅解决了训练崩溃的难题,还将模型的性能推向了新的高度,更重要的是,它的核心思想,出奇地“简单”(Simple)。

为何多轮工具推理训练如此艰难?
在深入了解SimpleTIR的解决方案之前,我们必须先当一次“侦探”,找出导致训练崩溃的“元凶”。
1. “分布偏移(Distributional Drift)
传统的语言模型(LLM)是在海量的人类自然语言文本上进行预训练的,它们熟悉的是文章、对话、代码注释等。然而,当模型开始使用工具(比如一个Python解释器)时,它会收到一些“非自然”的反馈。
举个例子:
模型为了计算 15 * 24,生成了代码 print(15 * 24)。
工具返回的结果是:Code Execution Result: 360。
这段返回的文本,尤其是 Code Execution Result: 这个前缀,对于模型来说,就像一个在法餐厨房里突然出现的火星食材,它属于分布外(Out-of-Distribution, OOD) 数据。模型在预训练时很少见到这种格式的输入。
当模型被迫在这样一个“陌生”的上下文后继续进行下一轮推理时,它的内部状态就会被扰乱,输出变得极不确定。这种由外部工具反馈引发的“水土不服”,就是分布偏移。
2. 低概率词元的累积
分布偏移最直接的后果,是模型在后续轮次中,为本应生成的正确词元(token)分配了极低的概率。
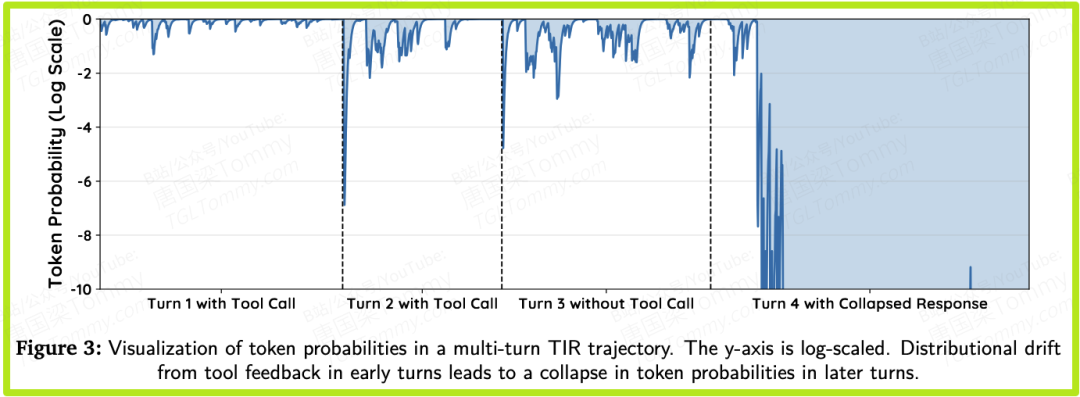
这个过程就像滚雪球:
• 第一轮:模型还比较自信,生成的词元概率较高。
• 第二轮:收到“陌生”的工具反馈后,模型开始“犯嘀咕”,生成的词元概率下降。
• 第三轮、第四轮...:随着工具反馈的不断输入,这种不确定性持续累积,模型生成的正确词元的概率会低到离谱,比如 甚至更低。
这些“低概率词元”就是摧毁训练稳定性的“毒丸”。它们通过两种致命的方式引爆整个训练过程。
3. 两大致命打击:梯度爆炸与信用分配错误
A. 梯度爆炸
强化学习的更新依赖于梯度。我们可以将梯度理解为模型根据一次“测验”结果,决定要多大程度上调整自己的知识。
低概率词元会导致梯度发生“爆炸”:
• 剧烈的新旧知识冲突:在PPO等算法中,更新依赖于一个称为重要性采样比率(新旧)的值。当模型做出一个它“旧知识”体系里认为“绝对不可能”(即 旧 极小)的行为时,这个比率 就会变得极大,导致学习系统“震惊”,产生一个巨大的、破坏性的梯度。
• 自信地犯下离奇错误:论文从理论上(公式3)证明,当模型对某个选择非常自信(概率分布很“尖锐”),但最终却随机采样到了一个概率极低的意外选项时,梯度本身也会被一个较大的因子放大。
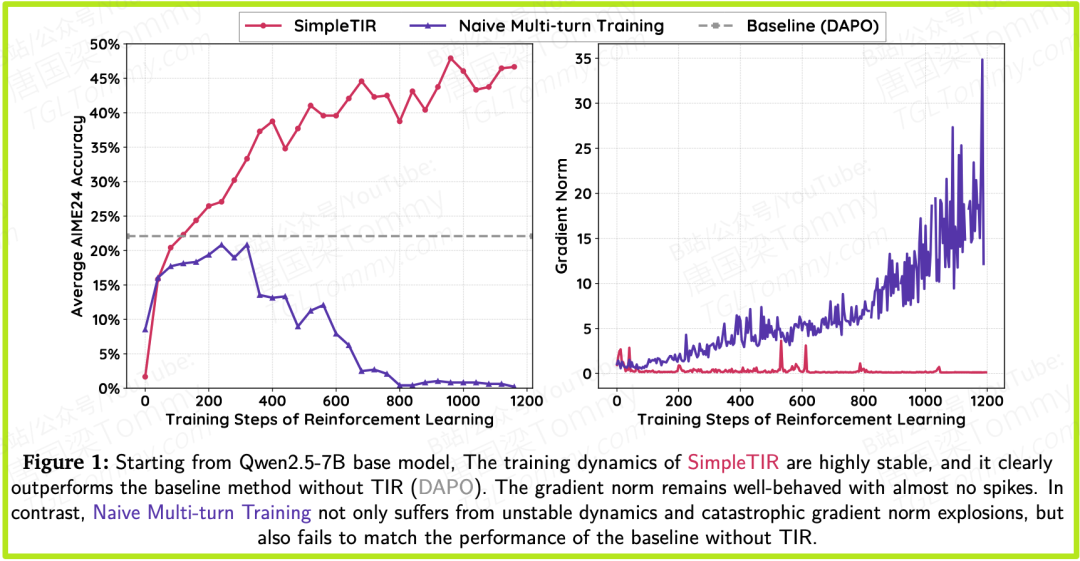
这两种效应叠加,就形成了梯度爆炸。这在论文的图1中表现为梯度范数曲线上那些灾难性的尖峰。
B. 信用分配错误
强化学习的奖励通常是稀疏的,即只有在整个任务完成后,模型才会知道自己做得好不好。
想象一个场景:一个AI智能体需要分10步解决一个复杂问题。它完美地完成了前9步,但在最后一步因为低概率词元问题而崩溃,给出了错误答案。 最终,整个任务的奖励是0(失败)。
学习算法会如何解读这次失败?它会认为从第1步到第10步的所有行为都是不好的,因此会降低第1步中那个完全正确的推理步骤的出现概率。
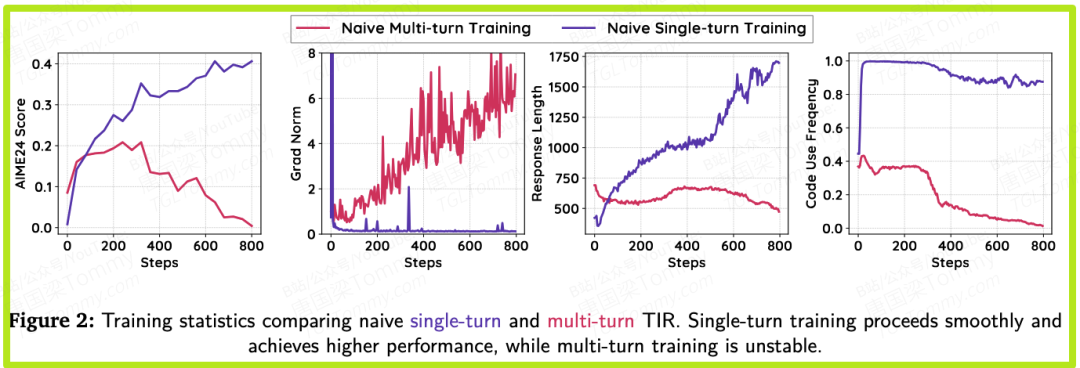
这种“一竿子打翻一船人”的惩罚机制,就是信用分配错误。它错误地惩罚了前期有效的多轮行为,导致模型产生一种“多做多错,少做少错”的倾向,最终退化到更安全、但能力也更弱的单轮次策略。
SimpleTIR的“化繁为简”之道
在诊断了问题的根源后,SimpleTIR的作者没有选择去硬磕那些复杂的概率分布或梯度计算问题,而是提出了一种极其优雅且高效的解决方案:我们不直接处理“毒丸”(低概率词元),而是去识别并隔离那些已经“中毒”的病人(问题轨迹)。
这个识别的指标,就是 “无效轮次”(Void Turn)。
一个“无效轮次”,是指模型的回复没有产生任何实质性的进展。具体来说,它既没有生成一个完整的、可供工具执行的代码块,也没有给出一个格式化的最终答案。
例如:
• 模型生成了不完整的代码:print(360 + 然后就结束了。
• 模型开始重复无意义的文本:“好的,现在我们来计算,我们来计算...”
• 模型只说了一段正确的废话,但没有任何实际操作。
“无效轮次”正是低概率词元累积、模型逻辑开始混乱的直接外在表现。因此,它是一个识别“问题轨迹”的绝佳启发式指标。
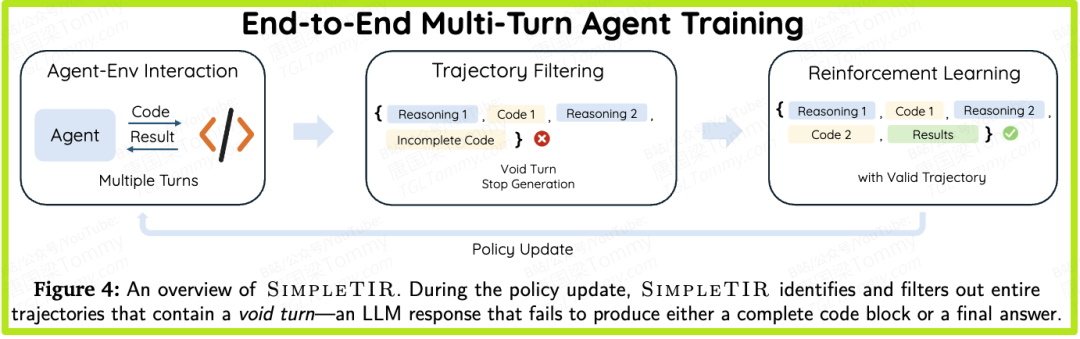
SimpleTIR算法:一个高效的“数据门卫”
SimpleTIR的实现流程简单到令人惊讶,它就像是在训练循环中安插了一个高效的“数据门卫”:
1️⃣ 生成样本:像往常一样,让模型与环境交互,生成一大批对话轨迹。
2️⃣ “门卫”检查:在将这批数据送去更新模型之前,“门卫”会逐一检查每一条轨迹。
3️⃣ 应用规则:对于每一条轨迹中的每一轮回复,“门卫”会用简单的模式匹配进行判断:
• 这个回复里有完整的代码块(由 ``` 包裹)吗?
• 或者,它有格式化的最终答案(由 \boxed{...} 或 final_answer(...) 标记)吗?
4️⃣ “一票否决”与剔除:
• 如果一轮回复两个条件都不满足,它就被标记为“无效轮次”。
• 一旦某条轨迹中出现了任何一个“无效轮次”,整条轨迹就会被贴上“不合格”的标签。
• 在最终更新模型参数时,所有“不合格”的轨迹都会被完全忽略。
通过这个简单的过滤步骤,SimpleTIR一举解决了两大难题:
• 解决了梯度爆炸:包含“无效轮次”的轨迹,其根源正是那些低概率词元。通过在梯度计算前就将这些轨迹整个丢弃,模型就永远不会接触到由它们产生的巨大梯度。
• 解决了信用分配错误:因为包含无效轮次的轨迹被整个抛弃,其中前期正确的推理步骤就不会再被后期错误的崩溃所“连累”和惩罚了。
实验结果:数据证明一切
理论说得再好,终究要靠实验结果来验证。SimpleTIR的表现堪称惊艳。
1. 性能的巨大飞跃
论文的核心实验基于强大的Qwen2.5系列模型。我们来看表1中的关键数据:
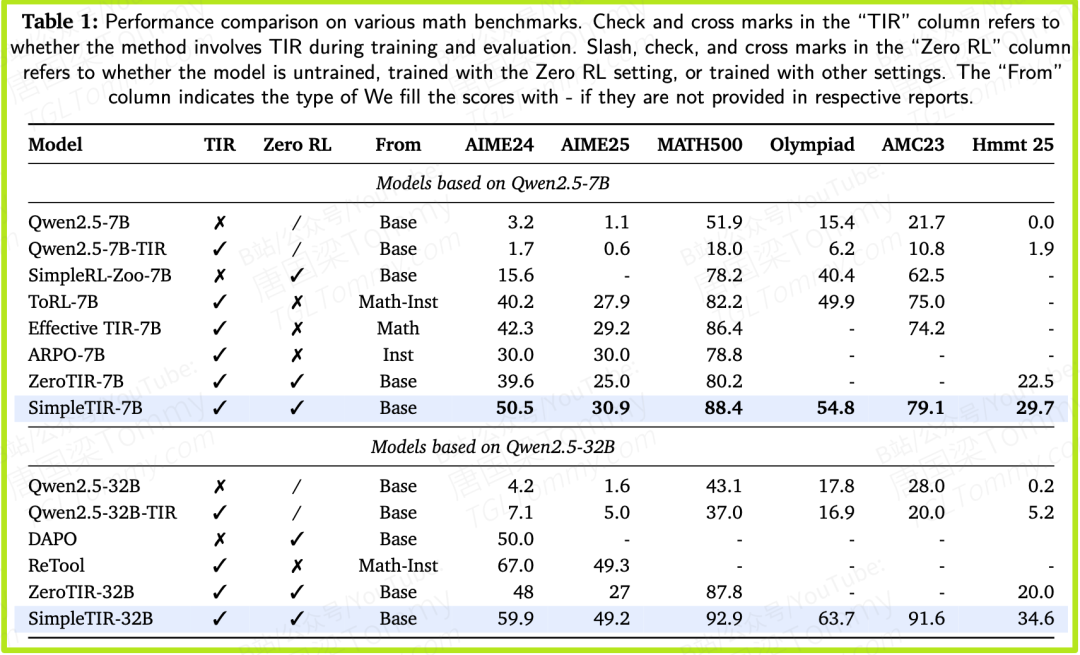
• 在极具挑战性的AIME24数学竞赛基准上,Qwen2.5-7B基础模型的纯文本基线得分仅为22.1。
• 应用了SimpleTIR进行训练后,SimpleTIR-7B模型的得分飙升至50.5!这是一个超过 128% 的巨大性能提升。
• 在更大的32B模型上,SimpleTIR-32B在AIME24上得分59.9,在另一个知名的MATH500基准上更是达到了92.9的高分。
2. 肉眼可见的训练稳定性
图1的训练曲线是SimpleTIR有效性的最直观证明。
• SimpleTIR(左图):其AIME24准确率曲线平稳、持续地上升,下方的梯度范数曲线则一直保持在较低的水平,几乎没有尖峰。
• 朴素多轮训练(右图):准确率曲线剧烈震荡,性能反复崩溃,而梯度范数曲线则经历了多次灾难性的爆炸。
3. 意外之喜:激发AI的“创造性”推理
最令人兴奋的发现,或许还不是性能的提升,而是SimpleTIR对模型推理模式多样性的激发。
在AI训练中,一种常见的做法是先用 监督微调(Supervised Fine-Tuning, SFT) 给模型“喂”一些标准答案,进行“冷启动”,然后再用强化学习。这种做法虽然能提高稳定性,但也像填鸭式教育,容易让模型的思维僵化,只会模仿SFT数据中的固定套路。
SimpleTIR采用的是 零样本强化学习(Zero RL) 路线,即直接从基础模型开始训练,不依赖任何SFT。通过过滤掉“有毒”样本,它为模型创造了一个安全的“探索乐园”。

表3的数据揭示了这一优势:
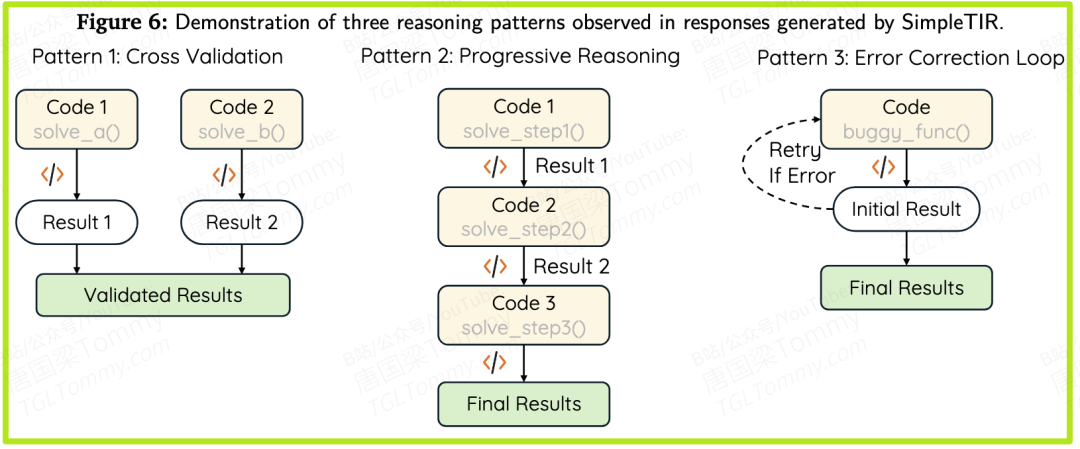
与一个经过SFT“冷启动”的强大模型ReTool相比,SimpleTIR训练出的模型表现出更高频率的复杂推理行为:
• 渐进式推理(Progressive Reasoning):将复杂问题拆解成多个小步骤,逐步解决。SimpleTIR的频率为46.5%,远高于ReTool的18.9%。
• 错误修正(Error Correction):在一步计算出错后,能意识到问题并生成新的代码进行修正。SimpleTIR的频率为38.0%,也显著高于ReTool的25.8%。
这表明,SimpleTIR不仅让模型学会了“做对题”,更重要的是,它让模型学会了如何像人一样去思考、探索和纠错,保留了预训练模型中蕴含的丰富可能性。
总结:通往更强AI Agent之路
SimpleTIR的成功,为我们揭示了几个重要的启示:
1. “少即是多”:在复杂的AI训练中,有时最有效的方法不是设计更复杂的算法,而是精准地识别并移除那些“害群之马”。有选择地“放弃”学习一部分数据,反而能取得更好的全局效果。
2. Zero RL的巨大潜力:这篇论文再次证明了,跳过SFT,直接从基础模型开始进行强化学习,是通往更通用、更具创造力AI智能体的可行路径。
3. 工程智慧的重要性:通过巧妙的提示工程(规范输出格式),将一个复杂的语义判断问题,降维成一个简单的模式匹配问题,这种化繁为简的工程智慧在AI落地中至关重要。
总而言之,SimpleTIR以其简洁的设计、强大的实证效果和深刻的启示,为我们拨开了一直笼罩在多轮次智能体训练上的迷雾。
论文名称:SimpleTIR: End-to-End Reinforcement Learning for Multi-Turn Tool-Integrated Reasoning
第一作者:南洋理工大学
论文链接:https://arxiv.org/pdf/2509.02479
最新日期:2025年9月2日
github:https://github.com/ltzheng/SimpleTIR.git本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-09-05,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号