VLSI 2026 | 英伟达3D堆叠硅光接收机突破:差分TIA实现32Gb/s下-17.3dBm灵敏度,能效低至0.484pJ/b

VLSI 2026 | 英伟达3D堆叠硅光接收机突破:差分TIA实现32Gb/s下-17.3dBm灵敏度,能效低至0.484pJ/b

光芯
发布于 2026-06-25 15:51:08
发布于 2026-06-25 15:51:08

一、研究背景与核心动机
随着AI工厂算力规模扩张,GPU间的双向带宽需求呈指数级增长,高速I/O正全面向光互联迁移,非计算功耗成为系统开销的核心来源。从NVLink2到规划中的NVLink8,单GPU带宽从300GB/s向万GB/s级演进,光链路的能量效率直接决定系统整体能效。
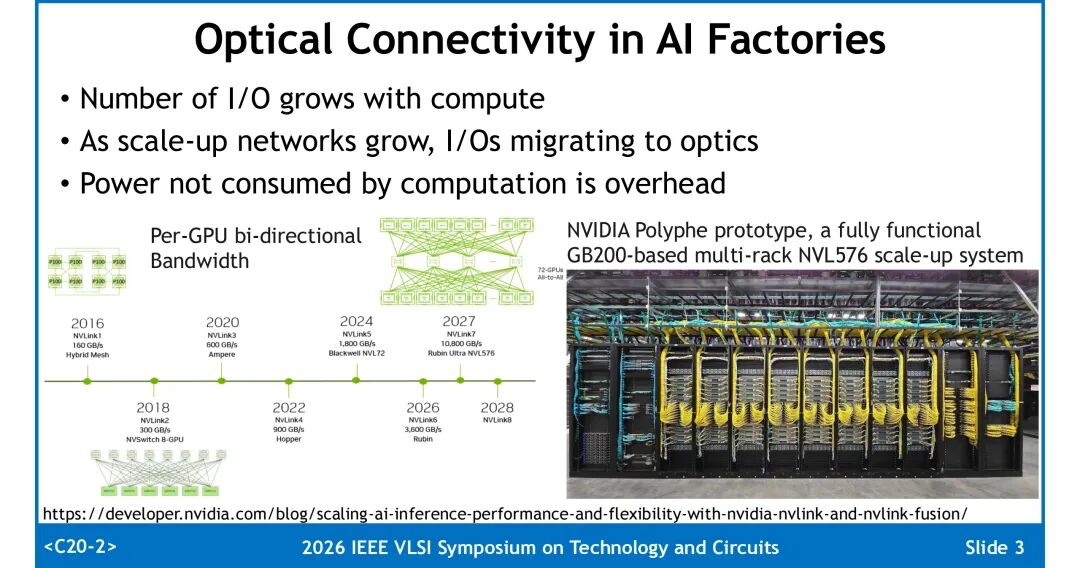
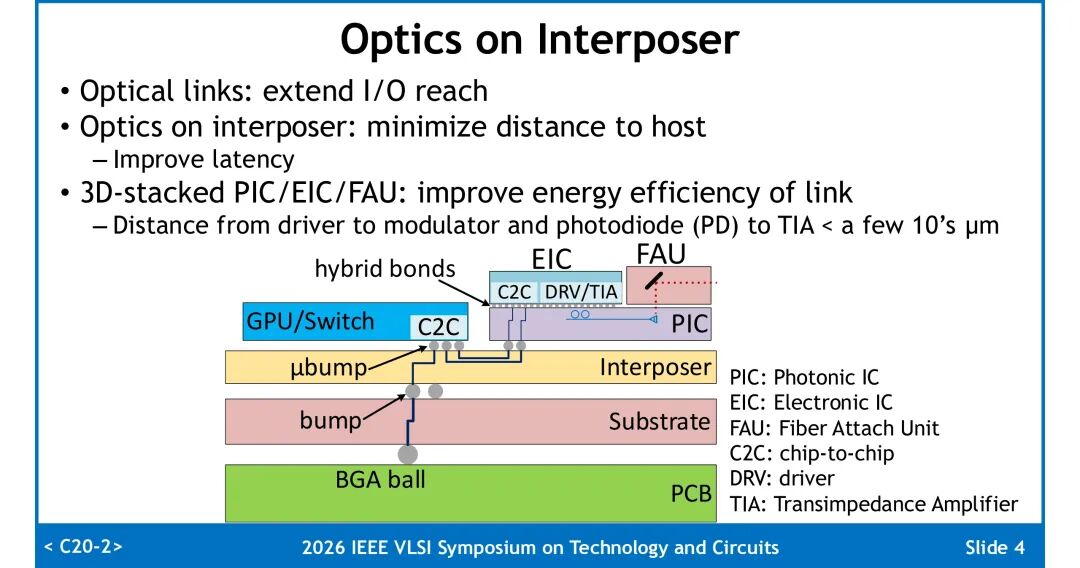
将光学引擎通过中介层与GPU/交换芯片近距离集成,可大幅缩短电互联距离、降低延迟;而采用PIC(光子芯片)、EIC(电子芯片)、FAU(光纤耦合单元)的3D堆叠方案,能将驱动-调制器、光电二极管(PD)-TIA的间距压缩至几十微米量级,从物理层面提升链路能效。
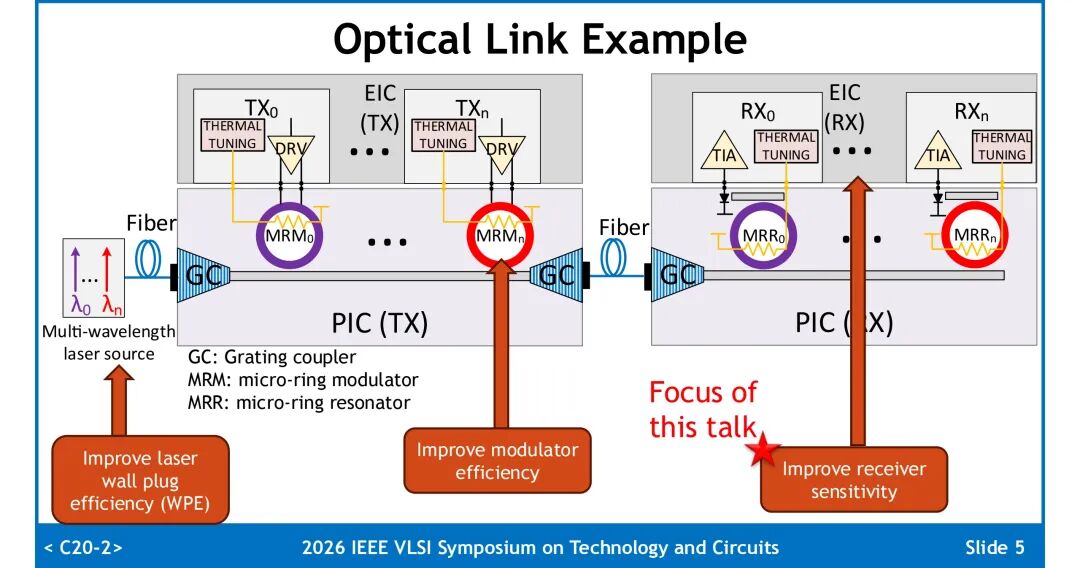
在光接收端,TIA的灵敏度直接决定链路预算与系统能效。直接检测系统通常采用单PD搭配单端TIA,若能同时利用PD阴极端的交流光电流,输出信号幅度可翻倍;在TIA热噪声主导的场景下,输出噪声仅提升√2倍,最终信噪比相比单端TIA提升√2倍,对应接收灵敏度获得同等幅度改善。该收益仅作用于TIA热噪声,对PD散粒噪声与激光相对强度噪声(RIN)无增益,而数据中心光接收机普遍以TIA热噪声为主,因此差分TIA具备极高的工程价值。

二、现有差分TIA方案的局限
要提取PD阴极的光电流,需解决PD反向偏置高压与TIA输入低电平的兼容问题,现有方案均存在明显短板:
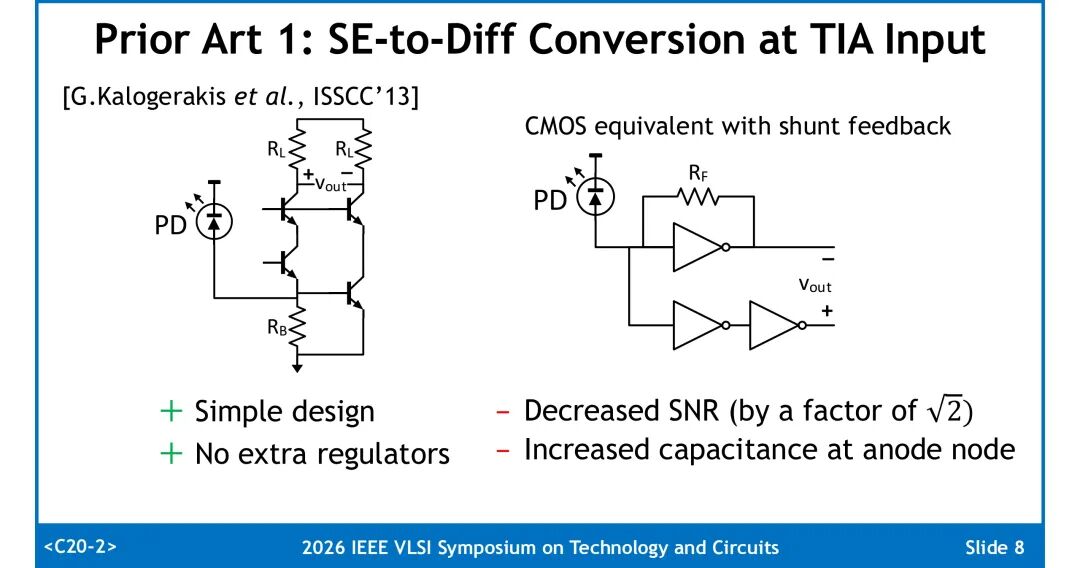
1. 阳极侧单端转差分架构:结构简单、无需额外稳压器,但转换过程会使SNR下降√2倍,同时增大阳极节点寄生电容,最终性能反而劣于单端TIA。
2. 阴极交流耦合架构:可获得灵敏度收益,高速TIA路径可采用单电源供电,但需要大尺寸交流耦合电容,且需级联多组稳压器提升阻抗,同时要求高压供电,面积与设计复杂度显著提升。
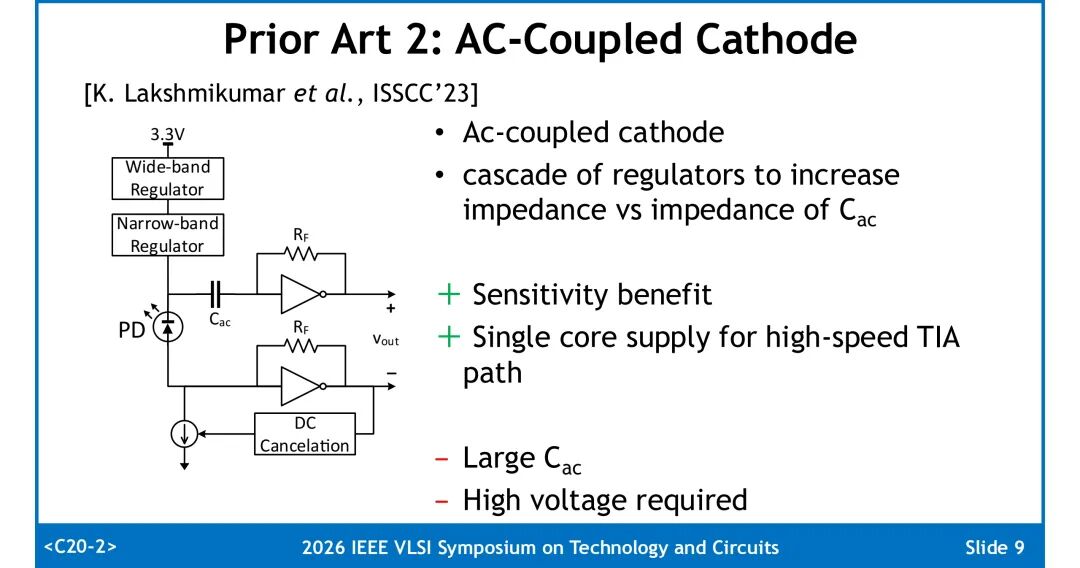
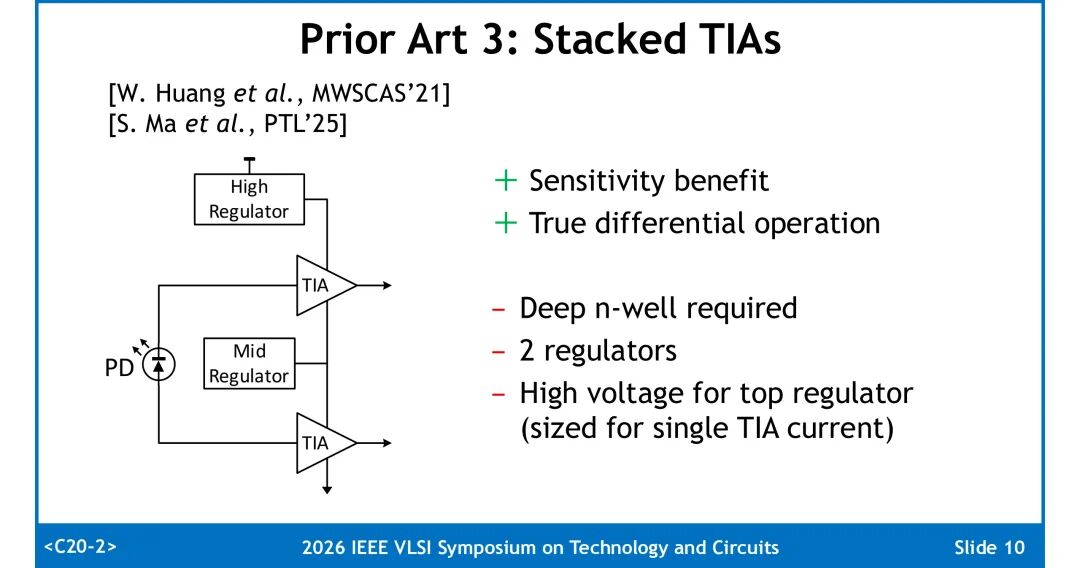
3. 堆叠式TIA架构:实现真差分工作模式,具备灵敏度优势,但需要深N阱工艺支持,需两路独立稳压器,且顶层稳压器需承载单路TIA的全部电流,供电设计难度高。
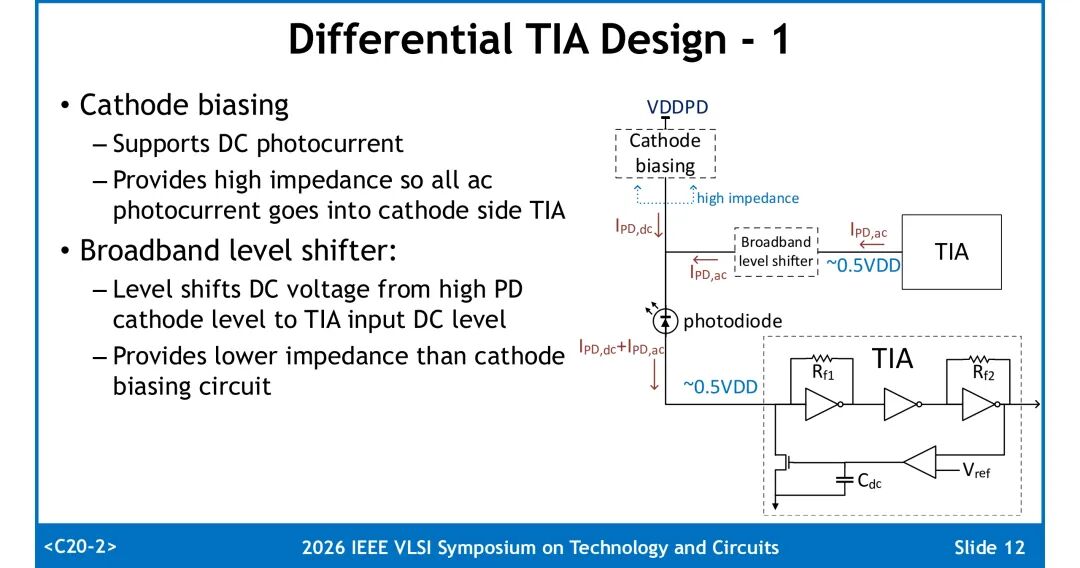
三、 本工作差分TIA设计方案
本工作的核心创新,是在PD阴极侧引入宽带电平移位网络,配合高阻抗阴极偏置电路,在单核心电源下实现真差分TIA工作,同时避免大电容与多电源的设计代价。
◆ 核心设计原理
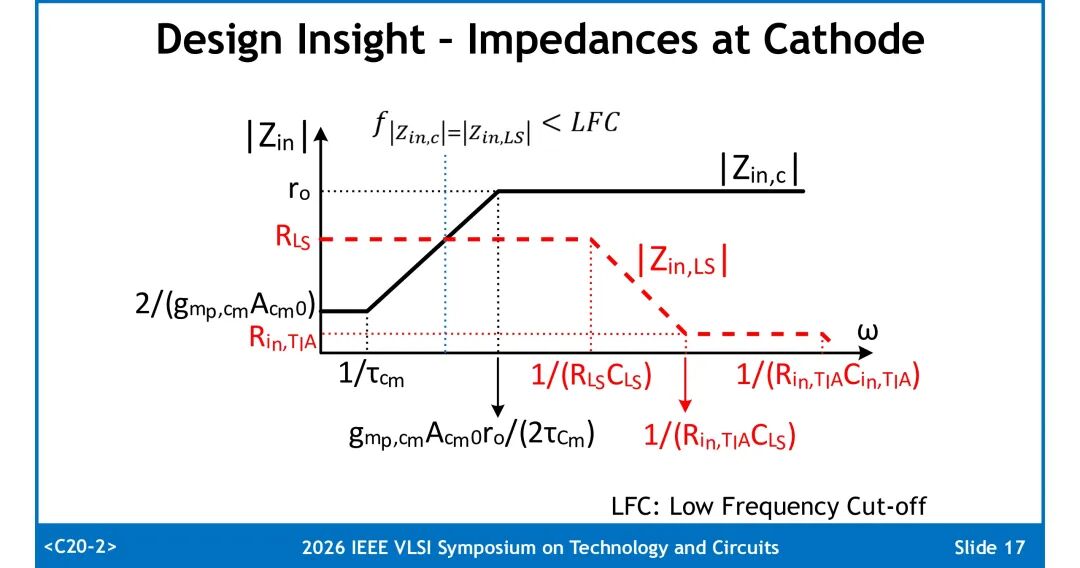
要有效利用阴极交流光电流,需满足两个条件:全工作频段内,阴极偏置电路的阻抗高于阴极侧TIA的输入阻抗,保证交流电流流入TIA;同时通过电平移位电路,将PD阴极的高直流偏置转换为TIA输入可兼容的电平。
◆ 电路细节实现
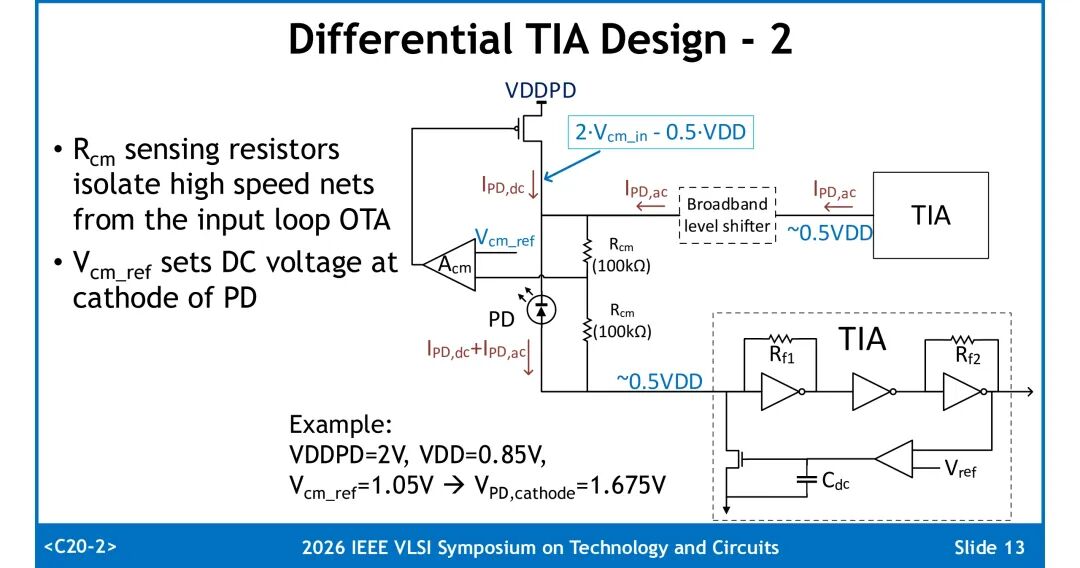
1. 阴极偏置与共模控制
采用共模反馈环路设置PD阴极直流电压:两个阻值为100kΩ的Rcm检测电阻隔离高速信号路径与输入环路,OTA根据Vcm_ref调整阴极偏置。以典型参数为例,VDDPD=2V、核心电源VDD=0.85V、Vcm_ref=1.05V时,PD阴极直流电压稳定在1.675V。
2. 宽带电平移位网络
采用RLS与CLS并联的结构实现宽带电平转换:RLS承担直流电平移位功能,同时传递光电流的低频分量;CLS传递光电流的高频分量。电平移位产生的直流电流ILS在进入阴极侧TIA前被泄放,避免影响TIA直流工作点。
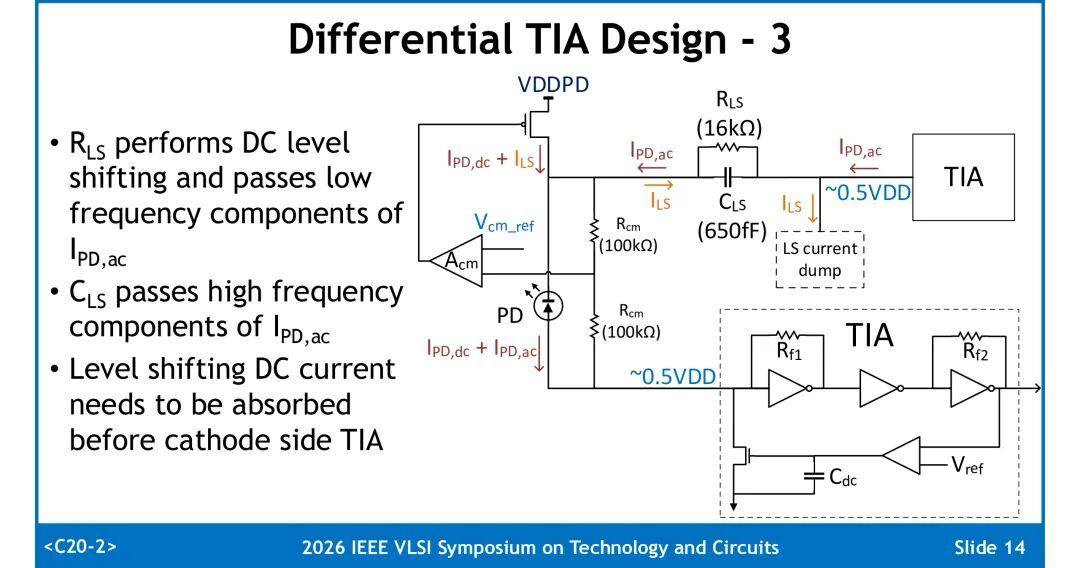
设计中RLS取值16kΩ,CLS仅需650fF,对应示例中ILS约为78μA。极小的电容值可采用MOM电容实现,且无需下层金属,寄生电容低于CLS容值的0.5%,避免寄生参数抵消差分架构的收益。
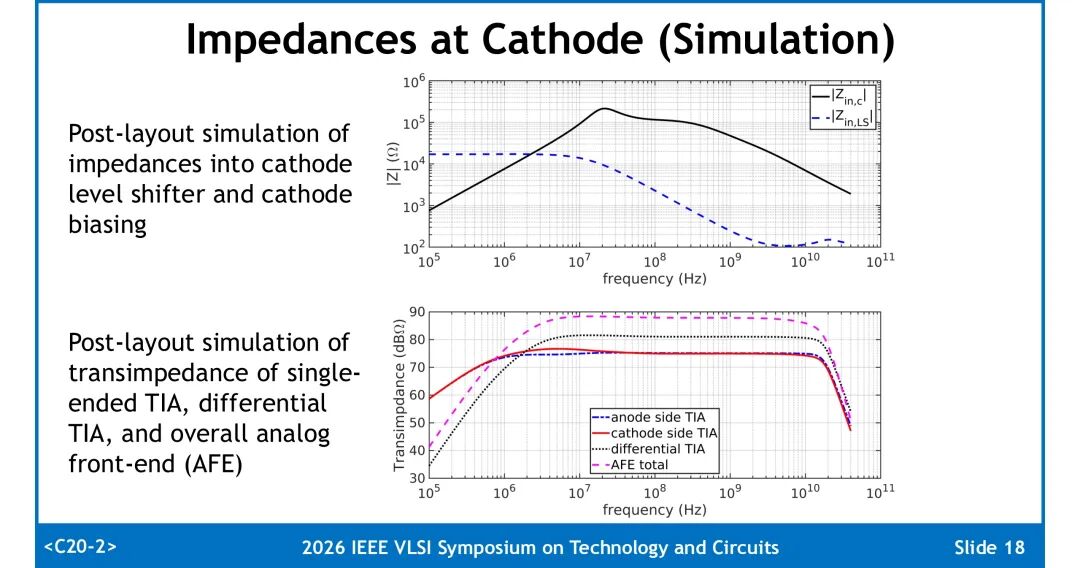
3. 阻抗匹配与频率补偿
低频段阴极偏置电路依靠共模环路增益呈现高阻抗,电平移位网络阻抗更低,保证交流光电流全部流入阴极侧TIA;高频段依靠CLS的低阻抗特性维持电流分配。两侧TIA结构基本一致,阴极侧TIA的反馈电阻Rf1比阳极高5%,用于补偿阴极节点额外寄生电容带来的高频损耗。

4. 电源与架构兼容性
PD高压电源VDDPD仅需承载PD直流光电流、电平移位直流电流与输入OTA电流,负载极低。该差分架构与单端TIA的核心设计完全正交,可兼容各类单端TIA拓扑。

四、完整光接收机架构
在差分TIA的基础上,完整接收机集成了模拟前端、电源域隔离、解串与时钟电路:
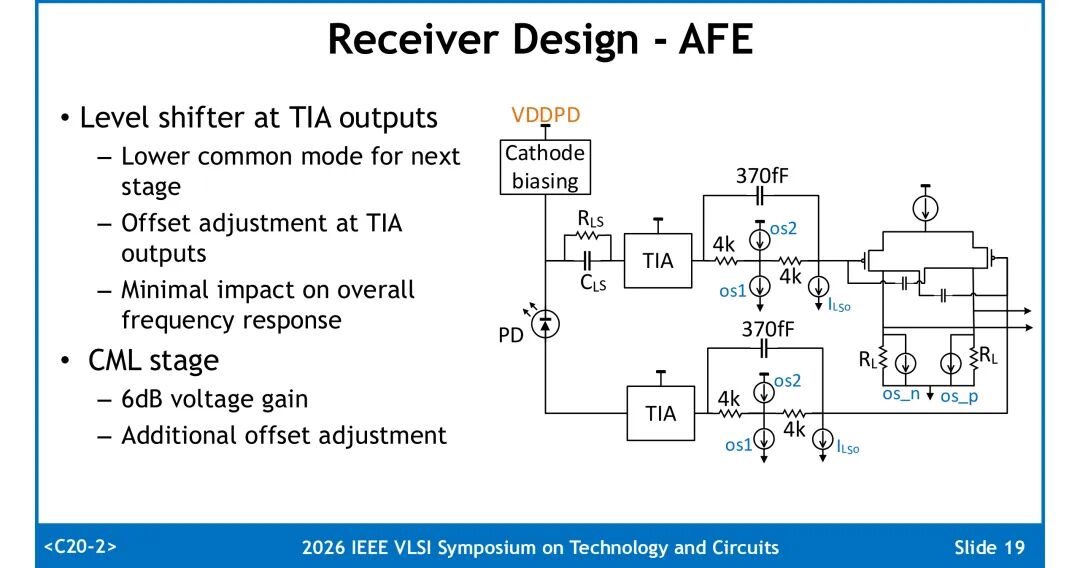
- 模拟前端:TIA输出端设置电平移位电路,降低后级共模电平,同时支持失调调节,对整体频率响应影响极小;后级CML放大级提供6dB电压增益,附带额外失调调节能力。
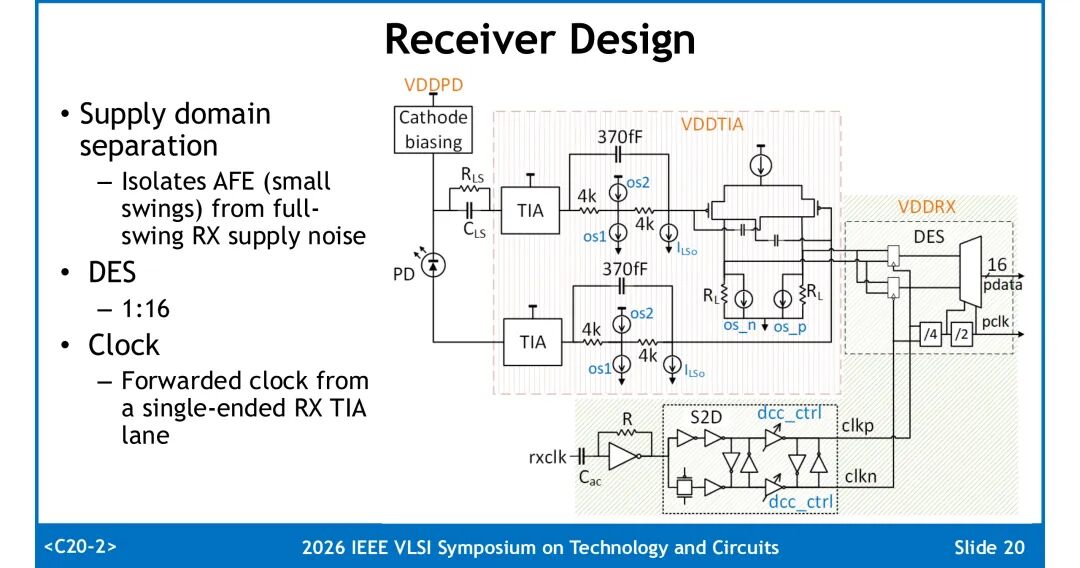
- 电源域隔离:模拟前端小信号电源域与满摆幅接收端电源域独立设计,抑制电源噪声对小信号链路的耦合干扰。
- 数字与时钟:集成1:16解串器(DES);采用转发时钟方案,时钟由单路窄带单端TIA通道接收,经调谐时钟分配网络降低非相关随机抖动。
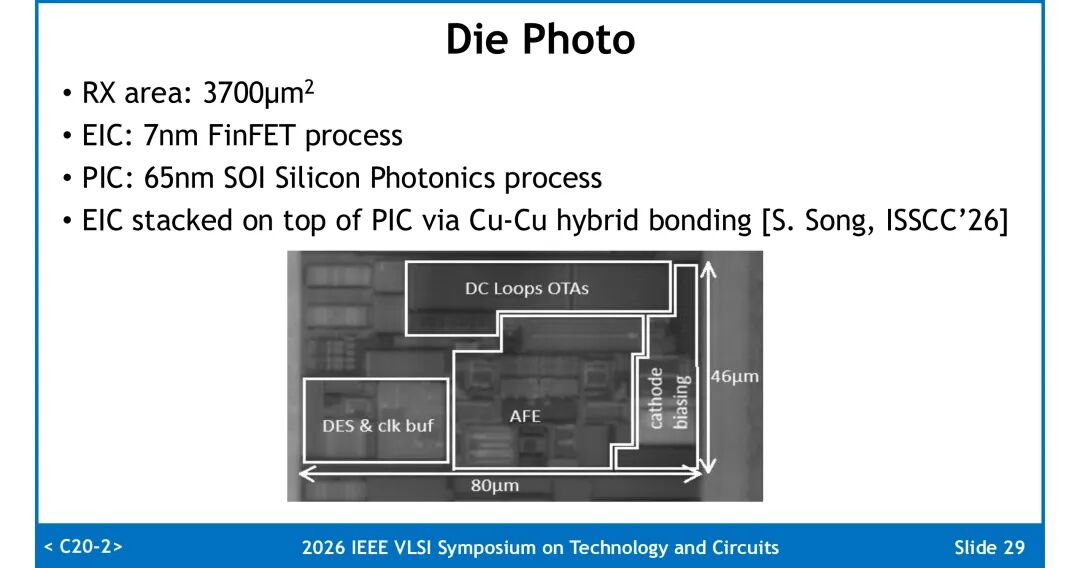
五、硅片实测性能
该接收机采用7nm FinFET工艺实现EIC,65nm SOI硅光工艺实现PIC,通过Cu-Cu混合键合完成3D堆叠,接收机总面积3700μm²。
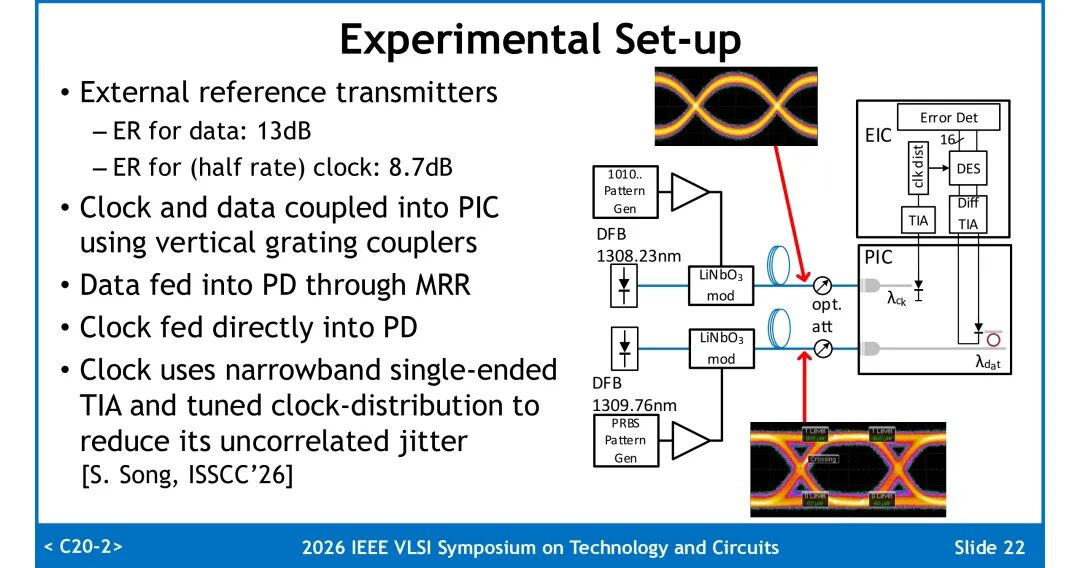
◆ 测试条件
采用外部参考发射机,数据通道光信号消光比13dB,半速率时钟通道消光比8.7dB;光信号经垂直光栅耦合器进入PIC,数据通道经微环谐振器滤波后入射PD,时钟通道直接入射PD。
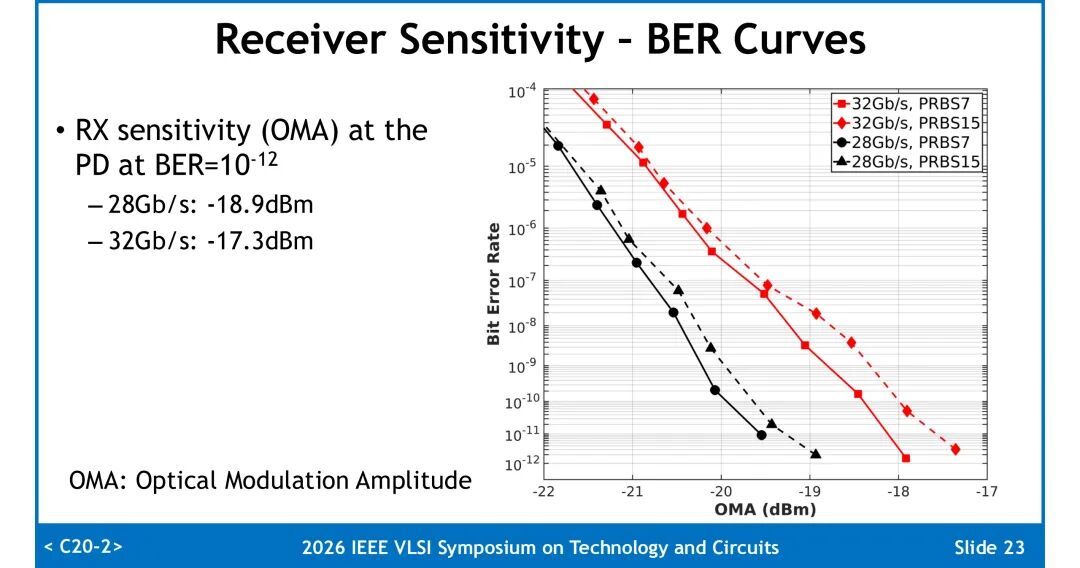
◆ 核心性能指标
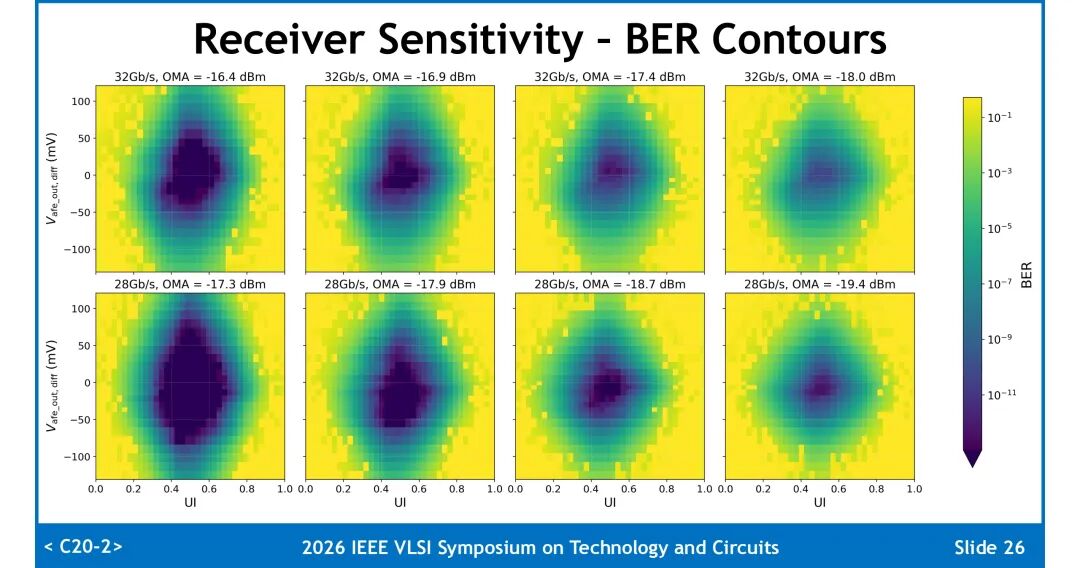
1. 接收灵敏度:在BER=10⁻¹²条件下,PD处的OMA灵敏度分别为:28Gb/s速率下-18.9dBm,32Gb/s速率下-17.3dBm。速率提升带来的灵敏度损失主要来自垂直眼闭合代价(VECP),28Gb/s下VECP为0.87dB,32Gb/s下升至1.85dB,受面积限制设计未采用电感进行高频补偿。
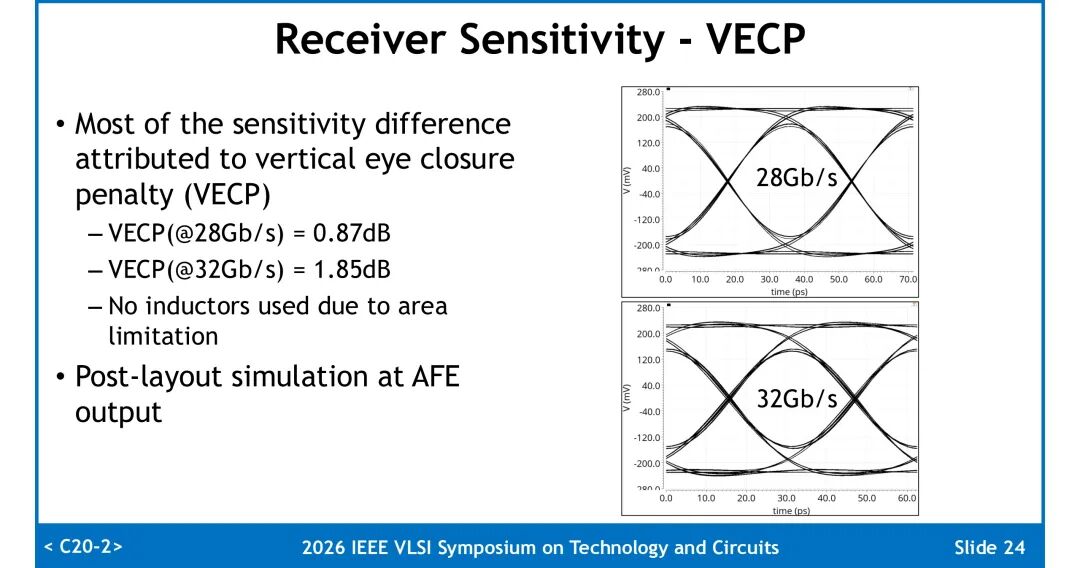
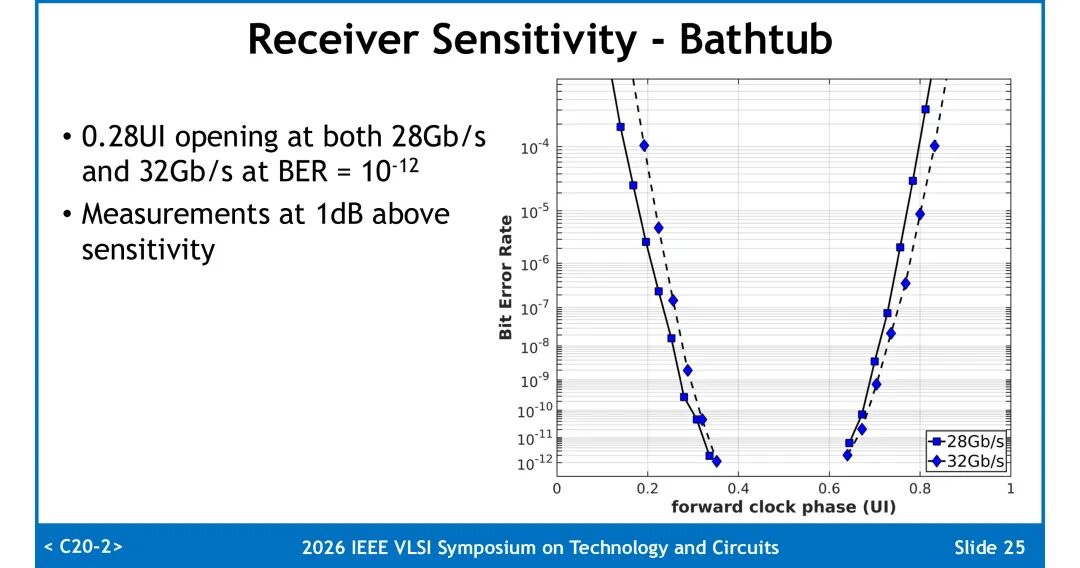
2. 眼图裕量:在灵敏度之上1dB光功率条件下,28Gb/s与32Gb/s速率下均实现0.28UI的眼图张开度。
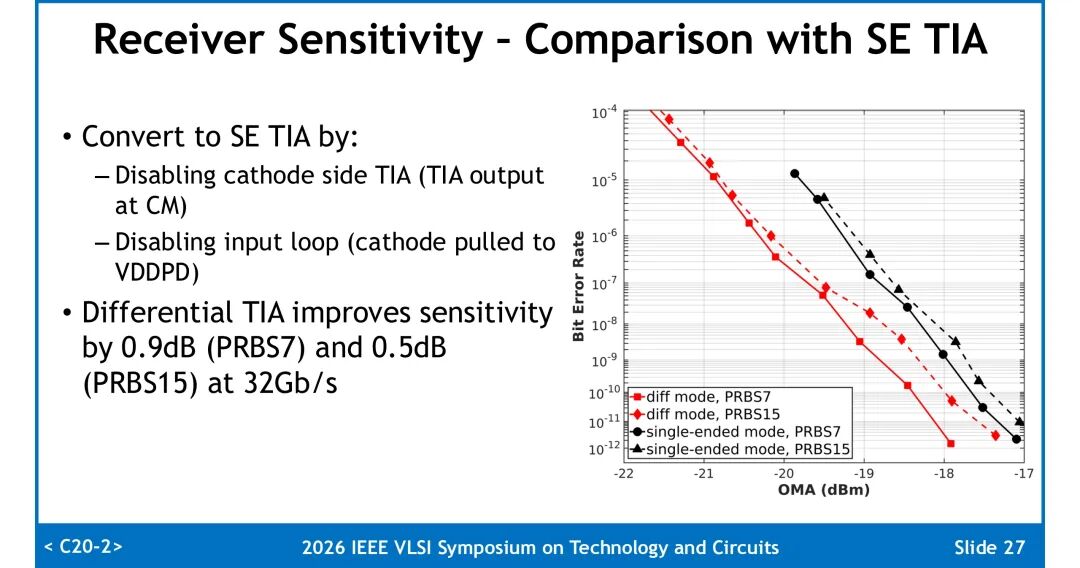
3. 差分架构增益验证:将阴极侧TIA禁用、阴极接至最高电源,配置为单端工作模式。对比测试显示,32Gb/s下差分模式相比单端模式,PRBS7码型灵敏度提升0.9dB,PRBS15码型灵敏度提升0.5dB。
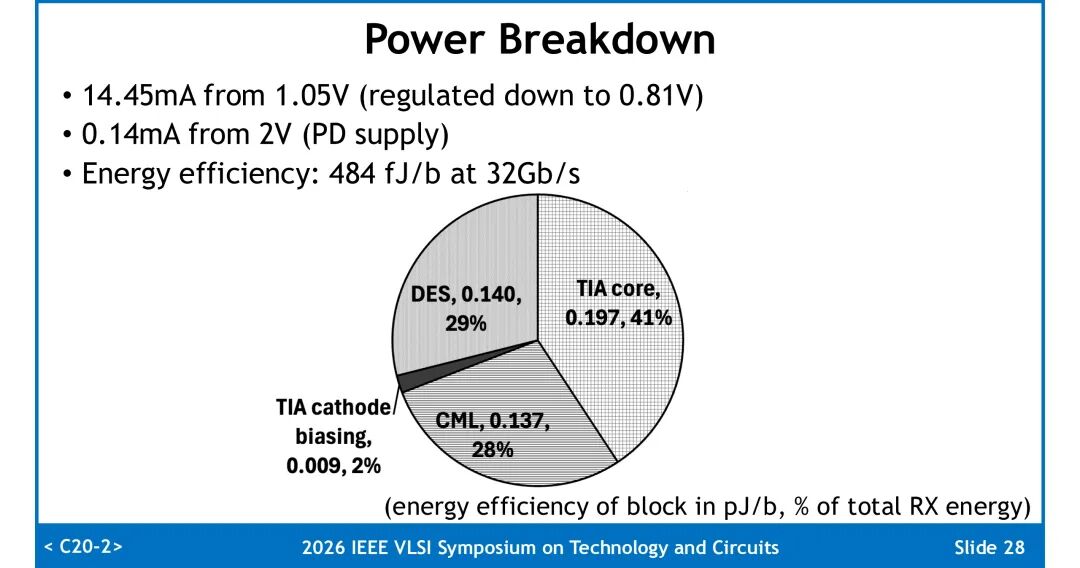
4. 功耗与能效:接收机总电流为:1.05V电源(稳压至0.81V)下14.45mA,2V PD电源下0.14mA。32Gb/s速率下总能量效率为0.484pJ/b。功耗分布为:TIA核心占41%,解串器占29%,CML级与阴极偏置电路占28%,其中阴极偏置电路仅占总功耗的2%。
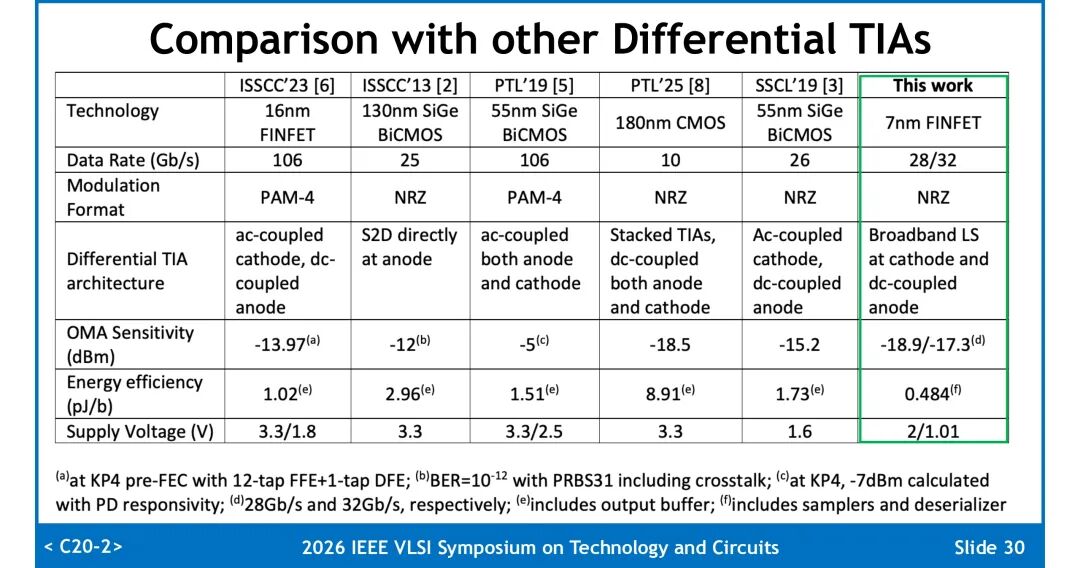
◆ 横向对比
与已发表的差分/准差分TIA方案相比,本工作是首款在7nm FinFET工艺下实现的差分TIA光接收机,在NRZ调制格式下达到了业界领先的灵敏度,同时能量效率大幅优于同类型设计,兼顾了高速率、高灵敏度与低功耗。
六、结论

本工作提出了一种基于阴极侧宽带电平移位的差分TIA架构,仅需650fF的小尺寸耦合电容,即可实现差分TIA的单核心电源供电,避免了传统方案的大电容、多电源、特殊工艺要求。实测验证该架构相比单端TIA可获得0.5~0.9dB的灵敏度提升,同时实现了3700μm²的小面积、0.484pJ/b的低能效,以及28/32Gb/s下的优异灵敏度,为3D堆叠硅光互联的高密度集成提供了核心技术支撑。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-19,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号