为什么"会自己干活的 AI"才是下一个风口
原创
为什么"会自己干活的 AI"才是下一个风口
原创
ranky
修改于 2026-06-25 15:24:55
修改于 2026-06-25 15:24:55
一个普通人都能看懂的判断:为什么"会自己干活的 AI"才是下一个风口。
先把话说清楚
这篇文章翻来覆去就讲两个词,先翻译成人话:
LLM(大语言模型):ChatGPT 背后那套技术。你可以当它是一个超级大脑,你跟它聊天它能听懂、能回答、能推理。但它只会说话。不能操作你的软件,不能查你邮箱,不能帮你订机票。
Agent(AI 智能体):给这个脑子装上手脚。Agent 不光能聊,还能自己调工具:查数据库、发邮件、写代码、操作软件。一句话:LLM 是会说话的脑子,Agent 是能干活的工人。
好了,进入正题。
主战场已经转移了
过去几年的 AI 叙事换了一茬又一茬。2022 年比参数量,2023 年比推理能力,2024 年比多模态,2025 年比安全和对齐。
都很好。但如果把数据拉出来看,一个趋势已经没法忽视:单纯把模型做得更聪明,边际收益在肉眼可见地下降。真正的差距变成了"模型能不能动手干活"。
用个比方:一个全科满分的博士,跟一群各有所长、会用工具、能协作的程序员团队,谁更能交付一个实际产品?
显然是后者。博士再聪明也只能告诉你怎么做,程序员团队能把它做出来。
一、把模型做大,已经快榨不出油水了
Epoch AI 2025 年有一项研究,追踪了三年间不同模型在各类任务上的表现变化。核心结论很直接:那些靠堆参数就能提升的任务,推理价格三年降了 40 倍以上;堆参数也提升不了的任务,价格几乎纹丝不动。
说人话:行业已经认了,有些事你模型再大十倍也没用。瓶颈不在脑子够不够聪明,在于你有没有手。
再看一个更直观的数据。
Digital Applied 今年 4 月发的多模态基准测试,市面上四款顶级模型(GPT-5.5、Gemini 3、Claude Opus 4.7、Qwen 3.5 Omni),在"看图答题"这个基础能力上,差距已经缩到只有 2.4 个百分点。2024 年这个数字还是 10 个点以上。
顶级模型之间的纯智力差距,已经小到可以忽略了。
但换一个场景立刻分出高下。同样是这些模型,任务变成"看一段监控视频判断发生了什么""读 50 页合同找风险条款",差距又拉大了。视频理解 Gemini 3 领先第二名 7 个点,长文档 OCR 上 Claude Opus 4.7 领先 5 到 8 个点。
这说明行业正在从拼通用能力转向拼场景能力。场景能力不是模型自己能解决的,它要工具、要上下文、要多步执行。
二、LLM 有三件事天生做不了
理解了模型的能力边界之后,答案其实就在 Agent 的架构里。
LLM 有三个死穴。
第一,没有手。 它可以告诉你"你应该去查一下数据库里这个用户的购买记录",但它自己点不了查询按钮。你得给它接上数据库接口,这就是工具调用,Agent 的第一个核心能力。
第二,没有记忆。 你每次打开 ChatGPT 开新对话,它都不记得你上一轮说了什么。永远初次见面。一个合格的 AI 客服记不住你昨天投诉了什么,它就不配叫 Agent,它就是个聊天框。
第三,不会规划。 "帮我做一份竞品分析报告"这件事,至少五步:搜竞品信息、收集数据、整理对比、撰写报告、排版输出。每步都可能出岔子,需要重试、换策略、判断中间结果靠不靠谱。
LLM 能一次性输出一个看上去完美的方案,但到了执行环节——搜索结果为空怎么办、第三步的数据跟第五步矛盾了怎么修——这些靠单次推理搞不定,得有一个能分步执行、能回头看、能自我纠错的系统。
把这三条反过来,就是 Agent 要做的事:用工具调用补手,用上下文记忆补脑子,用多步规划补眼睛。
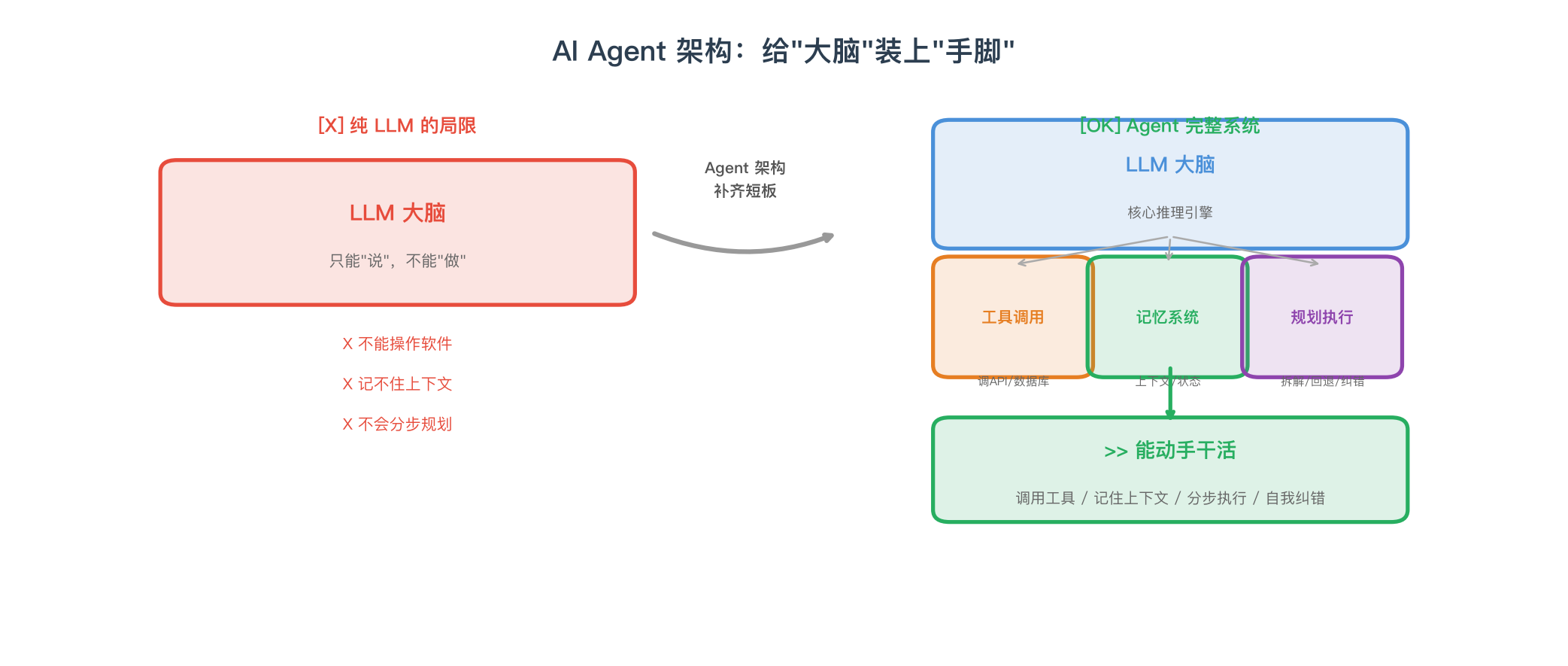
Agent 架构图:LLM + 工具调用 + 记忆 + 规划 = 能干活的系统
这不是空谈。McKinsey 2025 年企业 AI 报告显示,62% 的企业至少在一个部门试用了 AI Agent,其中 23% 已经在规模化用。但注意另一个数字:真正用出超预期效果的,只占 6%。
差在哪?同一个"模型 + 工具"的配方,架构设计的好坏直接决定了你是那 6% 还是那 56%。
三、最关键的变量:推理成本崩了
Agent 要大规模落地,光有架构还不够,得算账。
一个 Agent 完成一次复杂任务,大概消耗 1 万到 5 万个 Token。Token 就是 AI 的计费字数,每次问答,AI 公司按处理了多少 Token 收钱。
2023 年初 GPT-4 刚出的时候:每百万 Token 输入 30 美元,输出 60 美元。一次任务大概 0.3 到 1.5 美元。
看着不多?换个视角:一个企业级场景,一天 100 万次调用,月账单破百万美元。能扛的公司不多。
到了 2026 年价格已经面目全非了:
时间 | 模型 | 每百万 Token 输入价格 |
|---|---|---|
2023 年初 | GPT-4 | $30 |
2024 年中 | GPT-4o Mini | $0.60 |
2025 年初 | DeepSeek-V3(开源) | $0.28 |
2026 年 3 月 | Gemini Flash-Lite | $0.25 |
(数据来源:Epoch AI 推理成本研究 & 棱镜空间 2026 年 LLM 成本分析)
三年,降了超过 200 倍。
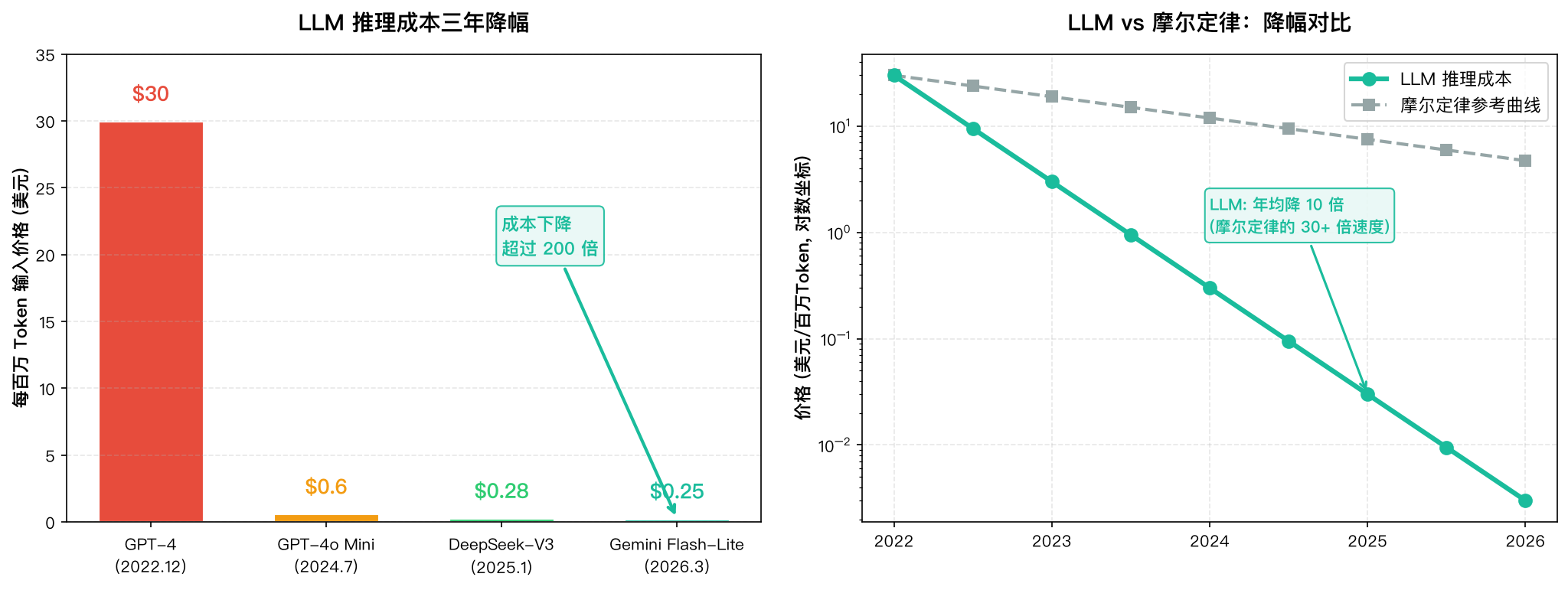
LLM 推理成本下降曲线及与摩尔定律对比
做个参照:大家熟悉的摩尔定律,芯片性能每 18 个月翻一倍,折算成年降幅大概 30%。LLM 推理成本的下降速度是摩尔定律的 30 倍以上。
按现在的低价模型重算:5 万 Token 一次任务,成本不到人民币一块钱。一天 100 万次,月成本大约 2600 美元,在企业产品里完全可接受。
成本降到某个阈值之后,整个品类就从"技术上可行但经济上划不来"变成"经济上也划得来了"。高频客服、实时语音助手、个性化 AI 辅导、24 小时不停歇的 Agent 工作流,全因此成立。
Barclays Capital 2025 年有份算力分析报告提到一个数据:未来 AI 总算力超过 70% 会被 Agent 消耗掉。不是因为 Agent 比训练模型更费算力,而是当调用一次 Agent 的成本降到几毛钱,调用量会指数级炸开。
四、Agent 的交通规则终于出现了
成本问题扫清之后,下一个问题:不同 Agent 之间怎么协同?
2024 年之前长这样:每家都在自己写代码让 AI 调用外部工具。公司 A 想让 AI 连 GitHub,得写一套;公司 B 也要连 GitHub,还得再写一套。100 家公司 × 100 个工具 = 10000 套重复劳动。
2025 到 2026 年,三套通用协议出来了。
MCP:AI 世界的 USB 接口
Anthropic 2024 年底发布的 MCP(模型上下文协议),可以理解成 AI 世界的 USB——插上就能用,不用自己写驱动。
到今年 5 月数据已经挺吓人了:活跃公共服务器超过一万个,GitHub 相关仓库超过一万五千个,每月下载接近一亿次,41% 的软件公司已经在生产环境用了(Stacklok 2026 年行业报告 & Digital Applied 统计)。
OpenAI、Google、微软的主流平台全部在支持 MCP。就跟当年所有网站都支持 HTTP 一样,现在所有 AI 工具都在接入 MCP。
A2A:让多个 AI 组队
Google 2025 年发布的 A2A(Agent-to-Agent)。MCP 解决"AI 怎么用工具",A2A 解决"多个 AI 怎么一起干活"。
场景很简单:财务 AI 查账,法务 AI 审合同,客服 AI 回复用户。一个用户投诉"我的账单有问题",客服 AI 通过 A2A 把查账甩给财务 AI、条款确认甩给法务 AI,然后汇总结果直接回复,全程不需要人调度。
多 Agent 系统市场目前以 48.5% 的年复合增长率在跑(Grand View Research 2026 年预测)。
AG-UI:让你看到 AI 在干嘛
AG-UI(Agent-User Interaction)。解决最实际的问题:AI 在后台干活的时候,你怎么知道它到哪一步了、有没有卡住、需不需要你确认什么。
它就干一件事:把 AI 的思考过程、工具调用状态、中间结果实时推到你面前的界面上。跟打车软件让你看到司机在哪一样,不用干等。
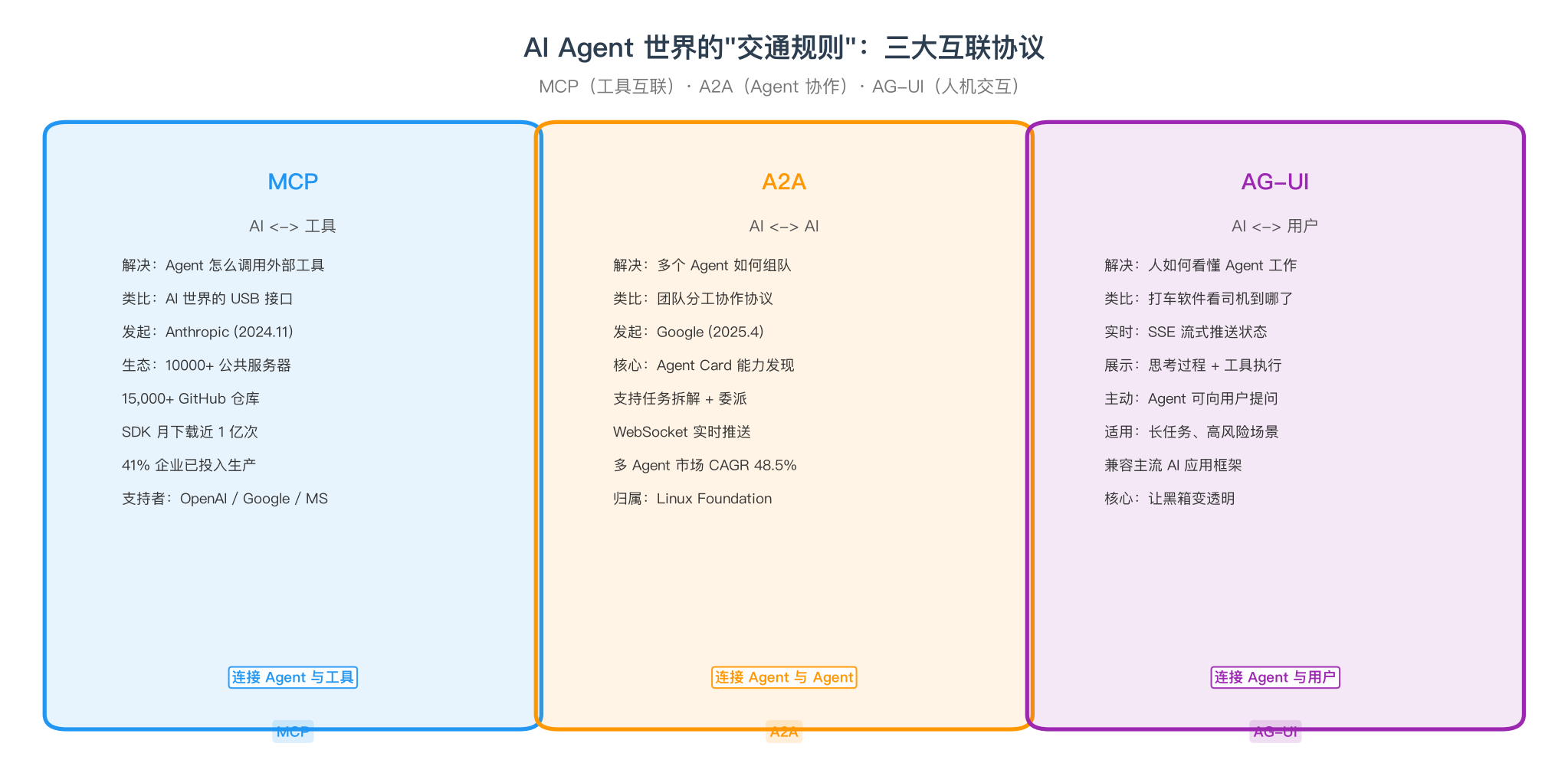
三大协议生态图
三套协议凑在一起就是 Agent 世界的交通规则。就像 HTTP 让全世界的网页能互联,MCP + A2A + AG-UI 正在让全世界的 AI Agent 能互联。
五、感知层也在补课
前面讲的全是 Agent 的动手能力——工具、规划、记忆、协议。还有一个关键问题:Agent 感知到的世界不能只有文字,它得看懂视频、合同、图表,听懂语音。不然没法真正融入真实工作流。
"多模态"在 2024 年叫多模态,就是你让 AI 描述一张照片。2026 年的关键变化不在于模型能不能看图了,而是:每种类型的多模态数据都出现了专门擅长的模型,Agent 可以按需调用。
以下数据来自 Digital Applied 今年 4 月的多模态基准测试:
看视频:Gemini 3 Deep Think 在长视频理解上做到 78.4%,领先第二名 7 个点。消防监控 Agent 能自动识别火情,不用人盯着。
读长文档:Claude Opus 4.7 能一口气读 50 页以上的合同还精准理解,远超其他模型。法律 Agent 自动审合同的日子到了。
实时语音:Qwen 3.5 Omni 语音延迟压到 300 毫秒以内,人说话的天然延迟大概 200 毫秒,支持 40 多种语言。语音 Agent 终于不卡了。
看代码截图:GPT-5.5 在图表推理上准确率 92.1%。Agent 可以直接从你的 IDE 截图里理解代码结构,不用你复制粘贴。
关键一句:没有一个模型在所有方向上都最强,但 Agent 不需要一个模型做所有事。
它可以按任务自动切换最合适的模型:文档走 Claude,视频走 Gemini,实时语音走 Qwen,代码截图走 GPT。你不会让医生去当会计,也不会让会计去做手术。Agent 的调度能力本身就是核心价值,它属于系统能力,不是模型能力。
六、得冷静一下
说了这么多前景,数据里也有不少让人清醒的东西。
40% 的项目会挂。 Gartner 今年 AI Agent 市场预测指出,到 2027 年底超过 40% 的 AI Agent 项目会被砍掉。原因不是模型不够好,是成本控不住、业务价值说不清、风险管不好。
四分之一能回本就不错了。 IBM 2025 年调查了 2000 名 CEO,过去几年只有 25% 的 AI 项目实现了预期回报。14% 明确亏损。
治理是最大的窟窿。 Deloitte 2025 年企业 AI 报告调查了 24 个国家 3235 名企业领导,只有 21% 的企业对自主 AI Agent 有成熟的管控机制。Gartner 甚至警告:到 2028 年,25% 的企业安全事件将直接跟 AI Agent 的误操作有关。
最可怕的事你可能没想过。
一个在聊天框里胡说八道的 AI,最多让你觉得搞笑。一个有权限写入数据库的 Agent 如果也胡说八道,它可能真的去删掉一行重要数据。
Agent 放大了 LLM 的优点,也同步放大了它的缺陷。幻觉、偏见、不可靠,这些 LLM 的老问题到了有手的 Agent 身上,后果严重了不止一个量级。
Agent 的落地不是"找个模型接个工具"就成的。它得在可靠性设计、权限管理、行为监控这些系统层面下硬功夫。那 40% 被砍的项目,大概率就是在这些"看着不难"的地方翻车的。
最后一件事:系统,不是模型
AI 行业走过了一条挺清晰的路径:2022 年拼模型有多大,2023 年拼推理有多强,2024 年拼能不能看懂世界。到 2026 年,顶级模型之间纯智力差距已经微乎其微。真正的战场变成了谁的系统能干活。
智能手机行业十年前也在比谁的处理器跑分高,现在你买手机关心的是什么?相机系统、生态协同、流畅度,没有一个是单颗芯片参数能决定的。
AI 也一样。下一阶段拉开差距的,不是谁的模型更聪明,而是谁的 Agent 更能干活:
- 能调用多少种工具
- 能不能记住上下文
- 会不会自己规划和纠错
- 多个 Agent 之间能不能配合
- 行为能不能被有效监控
数据已经给了答案。Agent 市场年增速接近 50%,多 Agent 系统更快。而模型能力的测评差距在不断缩小。
LLM 不会停下来等一个更大的模型出现。它的终点是一群会分工、会用工具、能协作的 Agent。像一支真正的团队那样,把事情做成。
本文数据来源:Epoch AI (2025)、Digital Applied (2026)、McKinsey (2025)、Gartner (2026)、IBM (2025)、Deloitte (2025)、Grand View Research (2026)、Barclays Capital (2025)、Stacklok (2026)、棱镜空间 (2026)
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号