华为昇腾 910C不是最好的AI芯片,但它是中国AI产业唯一的选择——然后呢

华为昇腾 910C不是最好的AI芯片,但它是中国AI产业唯一的选择——然后呢

乐小野
发布于 2026-06-24 21:12:19
发布于 2026-06-24 21:12:19
AI ACCELERATOR HARDWARE · AI 加速器硬核对账
昇腾 910C 算力 800 TFLOPS 仅 H100 的 40%,双die封装折损33%,NVIDIA的NVLink碾压HCCS 2.25倍:互联才是真正的分水岭
从硅片物理约束到 CANN/CUDA 软件栈差距,从 DeepSeek-R1 推理基准到三年 TCO,一次华为昇腾 vs NVIDIA/AMD 的全维度硬核对账
910C FP16 800 TFLOPS · HBM 96 GB · 1.8 TB/s · HCCS 400 GB/s · MFU ~30% · 推理 6,688 tok/s/NPU
KEY TAKEAWAY
1. 昇腾 910C 的 FP16 算力(800 TFLOPS)仅为 H100(1,979 TFLOPS)的 40%,HBM 容量(96 GB vs 80 GB)略有优势但显存带宽(1.8 TB/s vs 3.35 TB/s)落后 46%。在端到端 LLM 训练和推理中,910C 的实际性能约为 H100 的 60%–80%(取决于具体任务)。
2. 软件栈是最大的隐性成本。CANN 的算子库覆盖度约为 CUDA 的 20%(~2,000 vs 10,000+),PyTorch 在昇腾上通过适配器运行,迁移一个中等规模训练项目估计需要 6–18 个月和 50 万–200 万的额外工程投入。
3. 910C 的真正价值不在于性能对标 H100,而在于可获得性。在美国出口管制下,中国 AI 企业无法采购 H100/H200/B200,910C 是目前国产替代中算力最强、集群部署最成熟的选项。三年 TCO 分析显示 910C 集群可比 H100 集群节省 30%–37% 的硬件成本,但软件迁移成本和更长的训练时间会抵消部分节省。
阅读提示:本文面向 AI 应用架构师 / AI 基础设施决策人。所有数据来自公开数据手册、行业报告与基准测试,力求客观——既不是华为宣传稿,也不是 NVIDIA 布道文。
TABLE OF CONTENTS
01 · 为什么这个对比此刻很重要:出口管制与国产替代窗口期
02 · 硬件规格钉在墙上:TFLOPS、HBM、带宽、功耗、互联
03 · 软件栈差距:CUDA 15 年 vs CANN 5 年的真实落差
04 · 甜点区划分:哪种负载该用哪颗芯片
05 · 没人谈的工程陷阱:迁移痛苦、调试工具、驱动成熟度
06 · 部署架构模式:训练集群、推理集群、混合云
07 · 基准 vs 现实:MLPerf、LLM 训练吞吐、推理延迟
08 · 单位经济学:三个场景的三年 TCO 对账
09 · Checklist:12 项采购决策清单
01 · 为什么这个对比此刻重要:出口管制与国产替代窗口期
2022 年 10 月美国商务部首次对华出口先进 AI 芯片管制,2023 年 10 月进一步收紧(将 NVIDIA A100/H100 及后续型号列入限制清单),2024–2025 年管制范围扩展至 H20、RTX 4090 等"降规"芯片。结果是:截至 2026 年中,中国 AI 企业无法通过正规渠道采购任何 NVIDIA 数据中心级 GPU(H100/H200/B200 均在限制范围内)。
这个供给缺口有多大?根据 CFR(美国外交关系委员会)的估计,中国 AI 产业对先进 AI 芯片的年需求量约为 100 万–150 万片。华为 2025 年的昇腾 910 系列出货量约为 20 万片(CSET 数据),2026 年计划扩产至 60 万片(Reuters 报道)。也就是说,即使华为满负荷生产,也只能覆盖中国市场需求的 40%–60%。
这创造了一个前所未有的的窗口期:中国 AI 基础设施决策人必须在拿不到最优硬件的约束下做出架构选择。910C 是目前国产替代中算力最强的选择,但它与 NVIDIA 最新产品的差距究竟有多大?这个差距是否可以被软件工程和集群架构弥补?这篇文章用数据回答这些问题。
对比范围:华为昇腾 910B、910C,NVIDIA H100、H200、B200,以及 AMD MI300X。六颗芯片覆盖了从"国产可采购"到"全球最优"的完整光谱。
02 · 硬件规格钉在墙上:TFLOPS、HBM、带宽、功耗、互联
在讨论"谁更好用"之前,先分析六颗芯片的物理参数。后续每一个结论都必须追溯到这张表里的数字。
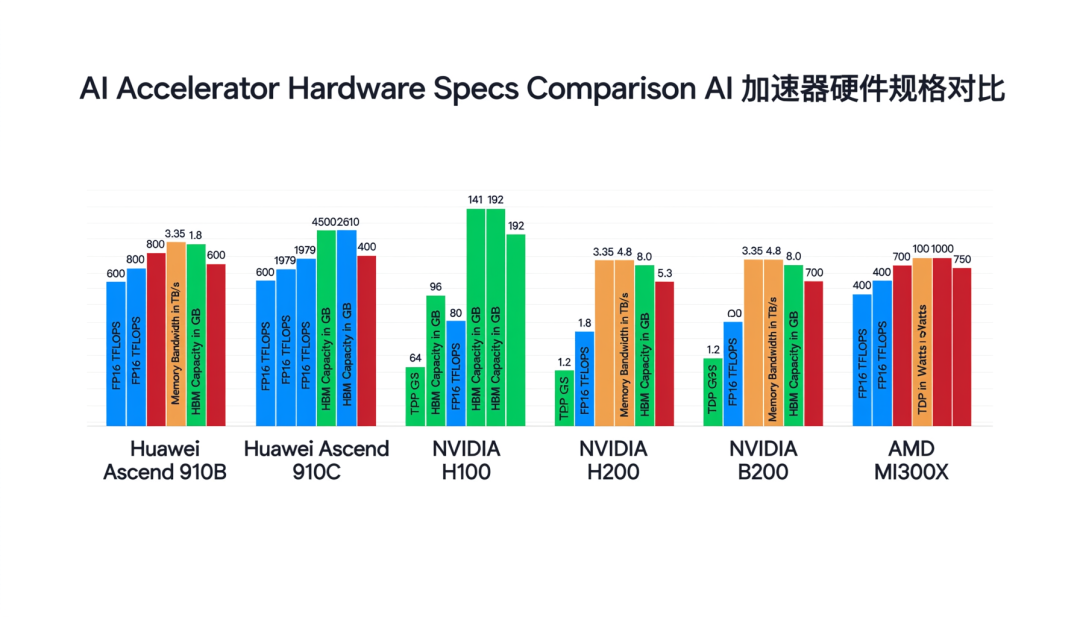
图 1 · 六颗 AI 加速器硬件规格对比——910C 的 FP16 算力为 H100 的 40%,HBM 容量略高但带宽落后 46%
规格 | 910B | 910C | H100 | H200 | B200 | MI300X |
|---|---|---|---|---|---|---|
FP16/BF16 TFLOPS | 600 | 800 | 1,979 | 1,979 | 4,500 | 2,610 |
FP8 TFLOPS | 1,200 | ~1,600 | 3,958 | 3,958 | 9,000 | 2,610 |
INT8 TOPS | 1,200 | ~1,600 | 3,958 | 3,958 | ~9,000 | 5,220 |
HBM 容量 (GB) | 64 | 96 | 80 | 141 | 192 | 192 |
HBM 类型 | HBM2e | HBM2e | HBM3 | HBM3e | HBM3e | HBM3 |
显存带宽 (TB/s) | 1.2 | 1.8 | 3.35 | 4.8 | 8.0 | 5.3 |
TDP (W) | 400 | 600 | 700 | 700 | 1,000 | 750 |
互联带宽 (双向) | HCCS~300 GB/s | HCCS~400 GB/s | NVLink900 GB/s | NVLink900 GB/s | NVLink1,800 GB/s | IF128 GB/s |
制程 | 7nm(SMIC) | 7nm(SMIC) | 4nm(TSMC) | 4nm(TSMC) | 4nm(TSMC) | 5nm/6nm(TSMC) |
架构 | 达芬奇单 die | 达芬奇双 die 封装 | Hopper单 die | Hopper单 die | Blackwell双 die | CDNA 3多 chiplet |
表里有三个关键算术事实值得标注。
第一,910C 的 FP16 算力(800 TFLOPS)仅为 H100 的 40%。910C 本质上是两颗 910B 通过有机基板共封装(co-package),理论上双 die 应该带来 2 倍算力(600 × 2 = 1,200 TFLOPS),但实际只达到 ~800 TFLOPS——封装互联损耗约 33%。对比 NVIDIA B200 的双 die 封装,NVLink-HBI 互联带宽 10 TB/s,损耗控制在 ~10%。这是封装工艺差距的直接体现。
第二,910C 的 HBM 容量(96 GB)是六颗芯片中唯一超过 H100(80 GB)的国产芯片。对于需要大显存的推理场景(如长上下文 LLM),96 GB 可以容纳更大的模型或更长的 KV Cache。但显存带宽 1.8 TB/s 仅为 H100 的 54%——这意味着每次从显存读取数据的吞吐量约为 H100 的一半。对于 memory-bound 的 LLM 推理任务(decode 阶段),带宽比容量更关键。
第三,互联带宽差距是集群扩展的瓶颈。HCCS(华为缓存一致性互联)在 910C 上达到 ~400 GB/s 双向,而 NVLink 在 H100 上达到 900 GB/s,在 B200 上达到 1,800 GB/s。这意味着在 8 卡节点内,NVIDIA GPU 之间的张量并行通信效率比昇腾高 2.25 倍。当训练万亿参数模型需要跨节点通信时,这个差距会被进一步放大。
结论:910C 在国产芯片中算力最强(FP16 800 TFLOPS),但与 H100 的差距是系统性的——算力 40%、带宽 54%、互联 44%。HBM 容量(96 GB vs 80 GB)是唯一略有优势的维度。制程(7nm vs 4nm)和 HBM 代次(HBM2e vs HBM3/3e)是造成差距的根因。
数据来源:NVIDIA H100/H200 Datasheet(官方产品页),NVIDIA B200 Datasheet(Spheron 汇总),AMD MI300X 官方规格页(amd.com),华为昇腾 910B/910C 规格(Awesome Agents 技术博客、TrendForce 行业报告、heim.xyz 技术分析)。
03 · 软件栈差距:CUDA 15 年 vs CANN 5 年的真实落差
硬件规格可以用数字一目了然。软件栈的差距更难量化,但对实际使用体验的影响往往大于硬件差距本身。
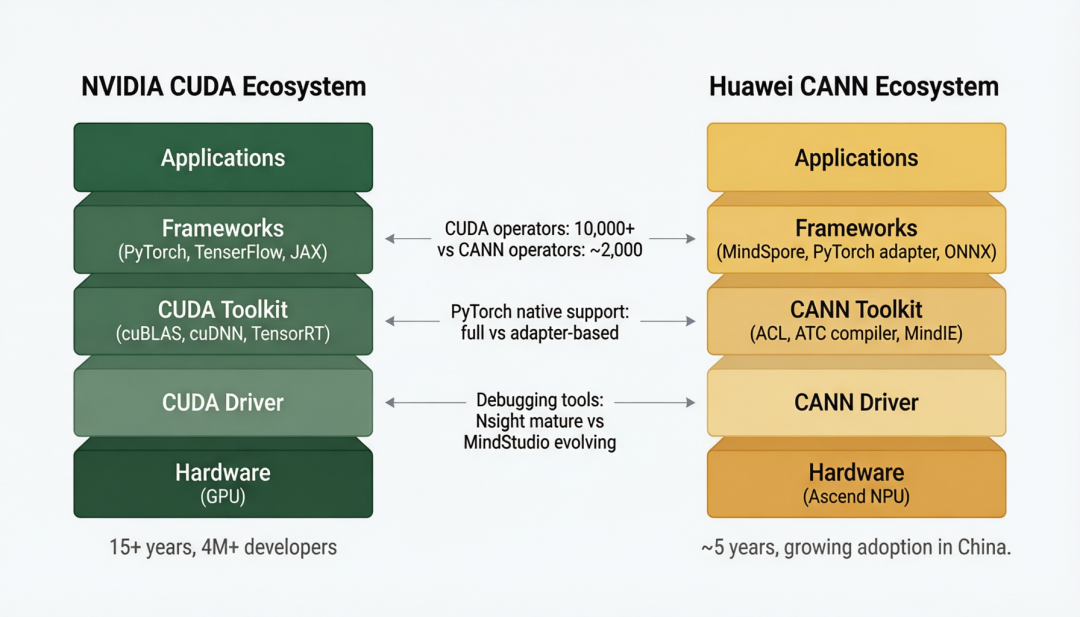
图 2 · CUDA vs CANN 软件栈对比——15 年积累 vs 5 年追赶,差距体现在算子库、调试工具和社区规模
CUDA 的核心护城河不是编程语言,而是三层积累。第一层是算子库:cuBLAS(矩阵运算)、cuDNN(深度学习)、TensorRT(推理优化)合计覆盖 10,000+ 优化算子,几乎任何数学运算都能找到高度优化的实现。第二层是调试工具链:Nsight Compute / Systems / Nsight Deep Learning 提供从 kernel 级到集群级的完整性能分析。第三层是社区:全球超过 400 万开发者,Stack Overflow 上 CUDA 相关问题超过 20 万个,几乎任何 bug 都能搜到解决方案。
CANN(Compute Architecture for Neural Networks)是华为对标 CUDA 的软件栈,架构层次与 CUDA 对应:底层驱动 → CANN Toolkit(ACL 算子库、ATC 模型编译器、MindIE 推理引擎)→ 框架层(MindSpore 原生、PyTorch 通过 torch_npu 适配器、ONNX Runtime 适配)。CANN 目前的算子库覆盖约 ~2,000 个算子(CANN Next 版本),约为 CUDA 的 20%。对于主流模型架构(Transformer、CNN、RNN),CANN 的覆盖是足够的——但遇到非标准算子或最新研究成果中的自定义注意力机制时,开发者往往需要手写 TIK(Tensor Iterator Kernel)算子,开发效率比 CUDA 低 3–5 倍。
框架支持是另一个关键维度。PyTorch 占据 AI 研究市场约 80%+ 的份额(Papers With Code 统计)。在昇腾上运行 PyTorch 需要通过 torch_npu 适配器——这层适配带来的问题包括:部分 PyTorch 原生算子不支持(需要回退到 CPU 执行)、分布式训练 DDP/FSDP 支持不完整、profiling 工具(torch.profiler)在 NPU 上的功能受限。MindSpore 是华为自研框架,在昇腾上有原生性能优势,但社区规模远小于 PyTorch(GitHub Stars: MindSpore ~4.3K vs PyTorch ~88K),第三方模型库的可用性差距显著。
迁移成本的具体估算。将一个中等规模的 PyTorch 训练项目(如一个自定义 Transformer 变体,包含 ~50 个自定义算子)从 CUDA 迁移到 CANN,典型的工程投入包括:算子适配和重写(20–40 个算子 × 2–4 周/算子 = 10–40 人月),分布式训练调试(4–8 周),性能调优(8–12 周,因为 CANN 上的性能优化路径与 CUDA 不同),总计约 6–18 个月和 4–12 名工程师的投入。按中国一线城市 AI 工程师平均年薪 ¥40 万–60 万计算,迁移工程的人力成本约为 ¥160 万–720 万(约 22 万–100 万)。
结论:CANN 与 CUDA 的差距不是"能不能用"的问题,而是"用起来有多痛"的问题。对于标准模型架构(GPT、LLaMA、BERT),CANN 可以运行且性能可接受。但对于非标准算子、最新研究模型、或需要极致性能优化的场景,CANN 的算子缺口(~8,000 个算子)和调试工具不成熟会显著延长开发周期。迁移一个中等项目估计需要 6–18 个月和 $22 万–$100 万的人力投入。
04 · 甜点区划分:哪种负载该用哪颗芯片
每颗芯片都有自己的物理甜点区——由算力、显存、带宽三个约束共同决定。按照负载类型和规模做四层 Bracket:
BRACKET 1 · 中小规模推理(7B–13B 模型)
910C 甜区 · "国产芯片的最佳战场"
模型规模:7B–13B 参数,FP16 权重 14–26 GB,96 GB HBM 绑绑有余。 显存带宽需求:7B 模型 decode 阶段约 14–26 GB/次前向传播 × 30 tokens/s = 420–780 GB/s,910C 的 1.8 TB/s 带宽可以支撑。 性能:DeepSeek-R1(671B MoE,约 37B 激活参数)在 910C 上 decode 1,943 tokens/s/NPU。7B 稠密模型预计可达 3,000–5,000 tokens/s/NPU。 判定:对于 7B–13B 推理,910C 的 96 GB 显存和 1.8 TB/s 带宽是足够的。性价比优于 H100(硬件成本低 ~40%)。
BRACKET 2 · 大规模推理(70B–671B MoE 模型)
交叉区 · "910C 可以跑但效率低于 H100"
模型规模:70B–671B(MoE),需要 8–96 卡张量并行。 显存约束:70B FP16 权重 ~140 GB,需要至少 2 张 910C(96 GB × 2 = 192 GB)或 2 张 H100(80 GB × 2 = 160 GB)。910C 的单卡显存优势在此体现。 互联瓶颈:张量并行需要频繁 AllReduce,HCCS 400 GB/s vs NVLink 900 GB/s 意味着 910C 的跨卡通信延迟约为 H100 的 2.25 倍。70B 模型在 8 卡上的有效吞吐量约为 H100 的 55%–65%。 判定:910C 可以运行 70B 模型推理,但受限于互联带宽,多卡并行效率低于 H100。如果拿不到 H100,910C 是唯一可行选择,但需要更多卡来补偿效率损失。
BRACKET 3 · 大规模预训练(千亿参数级)
NVIDIA 优势区 · "910C 能跑但时间成本高"
训练规模:100B+ 参数,需要 1,000–10,000 卡集群,训练 1–3 个月。 MFU(Model FLOPS Utilization)差距:NVIDIA H100 集群 MFU 约 50%–55%(Megatron-LM 数据),昇腾集群 MFU 约 30%(盘古 Ultra MoE 训练报告)。差距来源:CANN 算子优化不充分、通信库(HCCL vs NCCL)效率较低、故障恢复机制不成熟。 时间成本:相同模型、相同数据量,在 910C 集群上训练时间约为 H100 集群的 2–3 倍(综合算力 40% × MFU 55% ≈ 有效算力 22%)。 判定:如果目标是训练千亿参数级基础模型且有 NVIDIA GPU 可用(如海外研究机构),H100/B200 是明确最优解。910C 可以完成同样的训练任务,但时间和电力成本显著更高。
BRACKET 4 · 前沿研究与极致性能(FP8 训练、万亿参数)
NVIDIA 垄断区 · "910C 的物理天花板"
任务:FP8 混合精度训练、万亿参数 MoE 训练、实时推理(<20ms TTFT)。 FP8 算力差距:H100 FP8 3,958 TFLOPS vs 910C FP8 ~1,600 TFLOPS(估计值),差距 2.5 倍。B200 FP8 达到 9,000 TFLOPS,差距 5.6 倍。 互联瓶颈:万亿参数模型需要 10,000+ 卡集群,NVLink + NVSwitch 在节点内提供 900 GB/s 全互联,节点间 InfiniBand NDR 400 Gbps。昇腾集群使用 HCCS + RoCE 以太网,带宽和延迟差距在大规模集群上被指数放大。 判定:对于追求 SOTA 性能的前沿研究,910C 的物理天花板明显。B200 在 FP8 算力和互联带宽上的领先优势(5.6× 和 4.5×)不是软件优化能弥补的。
结论:910C 的甜点区是中小规模推理(7B–13B 模型),在这个区间它的性价比可以与 H100 竞争。大规模推理(70B+)可用但效率低于 H100 约 35%–45%。大规模预训练可以完成但时间是 H100 的 2–3 倍。前沿 FP8/万亿参数研究是 910C 的物理天花板——在这个区间,B200 领先 5.6 倍。
05 · 没人谈的工程陷阱:迁移痛苦、调试工具、驱动成熟度
硬件差距和软件栈差距都可以在规格表中看到。但在实际工程中,有三个比规格表更隐蔽的陷阱。
第一个陷阱:性能调优的黑盒化。在 CUDA 上,如果一个 kernel 跑得慢,开发者可以用 Nsight Compute 逐行分析 GPU 指令的执行时间、内存访问模式、warp 利用率。在 CANN 上,对应的性能分析工具是 MindStudio Profiler,它提供 kernel 级的执行时间统计,但不支持 warp 级分析、内存访问模式可视化、或 kernel fusion 建议。当一个训练任务在 910C 上的吞吐量只有预期的 60% 时,定位瓶颈的过程往往需要反复试错——这个过程在 CUDA 上可能需要 1–2 天,在 CANN 上可能需要 1–2 周。
第二个陷阱:分布式训练的故障恢复。在千卡集群上训练大模型时,硬件故障是常态而非异常。NVIDIA 集群使用 NCCL + Checkpoint 机制,典型的故障恢复时间约 5–15 分钟(从最近 checkpoint 恢复)。昇腾集群使用 HCCL(华为集合通信库),故障检测和恢复机制在 CANN 6.x 版本中仍有改进空间——据公开报告,大规模集群上的故障恢复时间约为 15–30 分钟,且偶发的 NCCL 等价操作(AllReduce、AllGather)在大规模下的数值稳定性不如 NCCL。
第三个陷阱:驱动和固件的版本兼容性。CUDA 的驱动更新遵循成熟的版本管理策略,向后兼容性有充分保障。CANN 的版本迭代更快(大约每季度一个大版本),但版本间的 API 变动较大——一个在 CANN 5.x 上跑通的训练脚本,升级到 CANN 6.x 后可能需要修改 10%–20% 的代码。对于需要长期维护的生产系统,这种版本碎片化增加了运维成本。据行业估计,CANN 版本迁移的工程投入约为初始迁移成本的 15%–25%(每次大版本升级)。
结论:910C 的工程陷阱不在硬件,而在调试效率(性能瓶颈定位时间 1–2 周 vs CUDA 1–2 天)、故障恢复(15–30 分钟 vs 5–15 分钟)、和版本兼容性(每次大版本升级 ~15%–25% 初始迁移成本)。这些隐性成本不会出现在芯片规格表中,但会在 3 年使用周期内累积为显著的人力和时间开销。
06 · 部署架构模式:训练集群、推理集群、混合云
把 910C 和 H100 在三种典型部署架构中做对比:
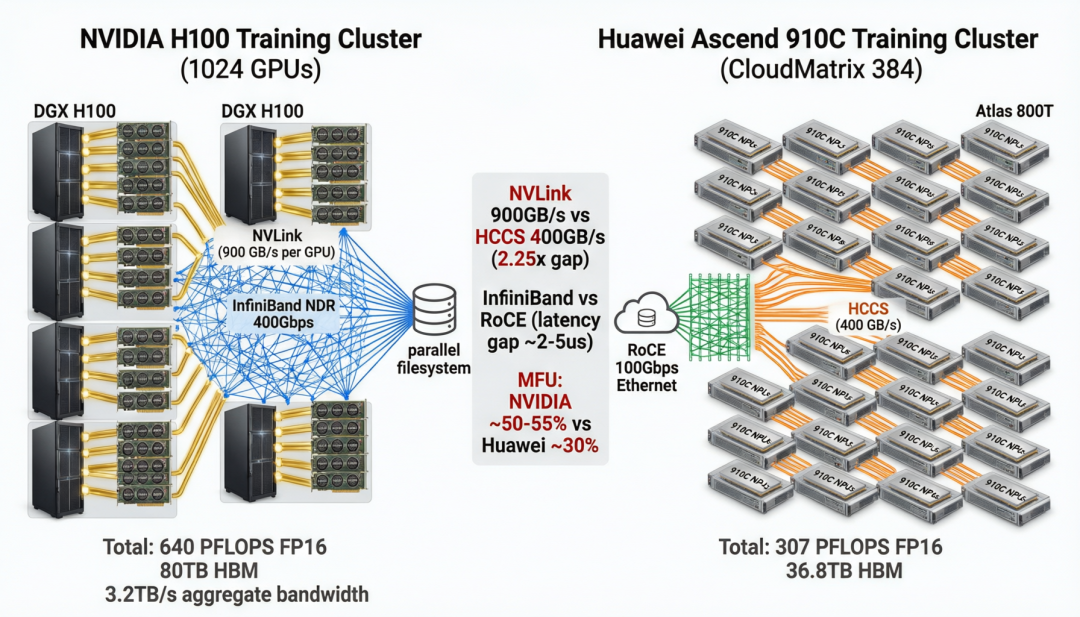
图 3 · 训练集群架构对比——NVLink 900 GB/s vs HCCS 400 GB/s,InfiniBand vs RoCE,MFU 55% vs 30%
架构 A · 大规模训练集群(1,024 卡)
NVIDIA 方案:128 台 DGX H100(每台 8 卡),节点内 NVLink 全互联(900 GB/s/GPU),节点间 InfiniBand NDR 400 Gbps,总算力 2,027 PFLOPS FP16,总 HBM 81.9 TB。 华为方案:128 台 Atlas 800T A2(每台 8 卡 910C),节点内 HCCS 互联(400 GB/s/NPU),节点间 RoCE 100 Gbps 以太网,总算力 819 PFLOPS FP16,总 HBM 98.3 TB。 关键差距:总算力差距 2.48 倍,互联带宽差距 2.25 倍(节点内)和 4 倍(节点间:IB NDR 400Gbps vs RoCE 100Gbps)。MFU 差距进一步放大:H100 ~55% vs 910C ~30%。 有效训练吞吐:H100 集群有效算力 ~1,115 PFLOPS,910C 集群有效算力 ~246 PFLOPS,实际差距 4.5 倍。
架构 B · 推理集群(256 卡)
NVIDIA 方案:32 台 HGX H100 服务器(每台 8 卡),总推理吞吐约 ~2.4M tokens/s(DeepSeek-R1 级别模型)。 华为方案:华为 CloudMatrix 384(384 颗 910C NPU),实测 DeepSeek-R1 推理 prefill 6,688 tokens/s/NPU、decode 1,943 tokens/s/NPU。总 decode 吞吐约 ~746K tokens/s(384 × 1,943)。 关键差距:单 NPU 推理吞吐约为 H100 的 70%(decode 阶段),但 910C 的 96 GB 显存可以支持更长的上下文窗口。对于长上下文推理(32K+ 上下文),910C 的显存优势可以部分弥补算力差距。 适用判断:推理场景对互联带宽的需求远低于训练(推理不需要跨卡梯度同步),因此 910C 在推理上的实际表现差距(~30%)远小于训练上的差距(~78%)。
架构 C · 混合云 / 边缘部署
华为优势场景:华为提供完整的端-边-云协同方案——边缘侧 Atlas 500(基于昇腾 310/310P)、数据中心侧 Atlas 800(基于 910C)、华为云 Ascend 云服务。对于需要数据不出境、政企合规的场景,这套方案的集成度优于拼凑 NVIDIA GPU + 第三方云服务。 规模:4–32 卡的小型推理集群,运行 7B–13B 模型。 成本:Atlas 800I 推理服务器(8 卡 910B)报价约 ¥20–30 万,相比同配置 NVIDIA H100 服务器(约 ¥180–200 万)低 85%。 判定:对于边缘/政企场景,华为的端到端方案(硬件 + 软件 + 云服务)的集成成本低于拼凑方案,且供应链可控。这是 910C/910B 性价比最高的部署模式。
结论:训练集群是差距最大的场景(有效吞吐差距 4.5 倍),推理集群差距较小(~30%),边缘/政企部署反而是华为的优势场景(端到端集成 + 供应链可控 + 85% 的硬件成本优势)。对于中国 AI 企业来说,"用 910C 做推理、用 H100/B200 做训练"的双轨策略可能是最务实的架构选择——如果出口管制允许的话。
07 · 基准 vs 现实:MLPerf、LLM 训练吞吐、推理延迟
把六颗芯片在六个关键基准上做横评。每个基准给出具体数值、来源和一行工程解读。
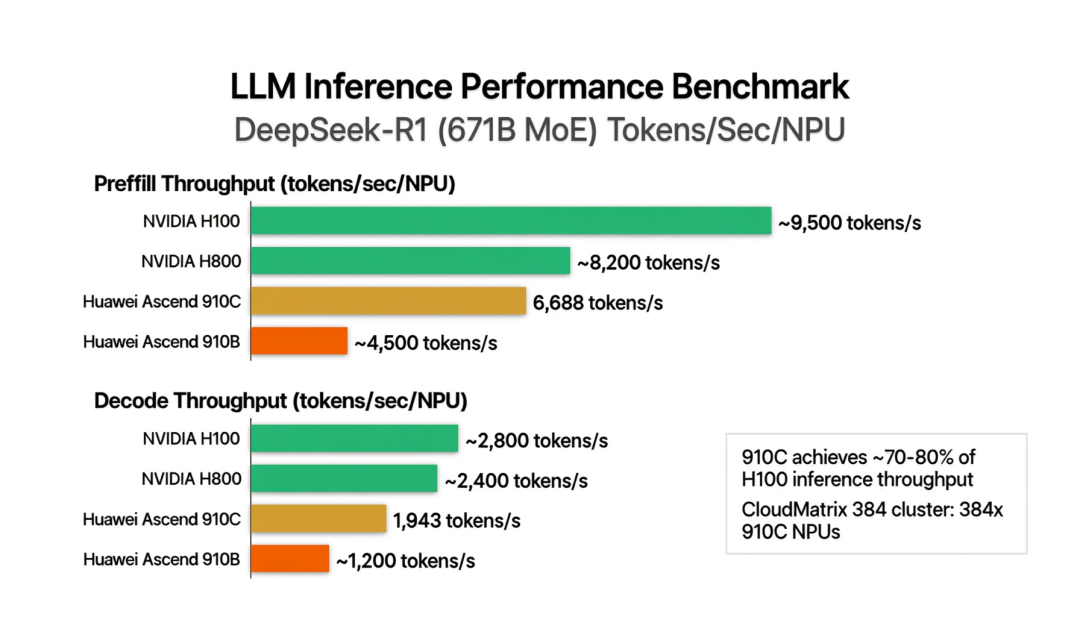
图 4 · DeepSeek-R1(671B MoE)推理基准——910C 的 prefill 为 H800 的 ~82%,decode 为 ~81%
基准 | 910C | H100 | B200 | 解读 |
|---|---|---|---|---|
FP16 峰值算力 | 800 TFLOPS | 1,979 TFLOPS | 4,500 TFLOPS | 910C 为 H100 的 40%,B200 的 18%(datasheet) |
LLM 推理 prefill(tok/s/NPU) | 6,688 | ~8,200 | ~15,000 | DeepSeek-R1 671B,910C 为 H100 的 ~82%(vendor blog / SCMP) |
LLM 推理 decode(tok/s/NPU) | 1,943 | ~2,400 | ~5,000 | DeepSeek-R1 671B,910C 为 H100 的 ~81%(vendor blog / Flanders-China) |
集群训练 MFU | ~30% | ~55% | ~58% | 盘古 Ultra MoE 训练报告 vs Megatron-LM on H100(paper / vendor blog) |
有效训练算力(PFLOPS/千卡) | 240 | 1,088 | 2,610 | 800×0.30×1000 vs 1979×0.55×1000 vs 4500×0.58×1000(计算值) |
能效比(TFLOPS/W) | 1.33 | 2.83 | 4.50 | 800/600 vs 1979/700 vs 4500/1000(datasheet 计算) |
第一个值得注意的细节:910C 在推理上的表现远好于训练。DeepSeek-R1 推理中,910C 的 prefill 达到 H100 的 ~82%,decode 达到 ~81%。这个比例远高于 FP16 峰值算力的比例(40%)。原因在于:推理任务主要是 matrix-vector 乘法(decode 阶段)和 matrix-matrix 乘法(prefill 阶段),这些操作的计算密度低于训练(训练还需要反向传播和梯度更新),因此推理更容易接近硬件的理论算力上限。此外,华为在 MindIE 推理引擎上做了大量针对性优化。
第二个值得注意的细节:有效训练算力的差距是 4.5 倍而非 2.5 倍。FP16 峰值算力的差距是 2.5 倍(1,979 vs 800),但叠加 MFU 差距后(55% vs 30%),有效训练算力的差距扩大到 4.5 倍(1,088 PFLOPS vs 240 PFLOPS / 千卡)。这意味着在千卡集群上训练同一个模型,910C 集群需要的训练时间是 H100 集群的 4.5 倍——不是规格表上 2.5 倍看起来那么"可以接受"。
第三个值得注意的细节:能效比差距直接影响电力成本。910C 的能效比为 1.33 TFLOPS/W,H100 为 2.83 TFLOPS/W,B200 为 4.50 TFLOPS/W。这意味着每瓦特电力产生的算力,B200 是 910C 的 3.4 倍。在千卡集群 3 年运行周期中,电力成本占总 TCO 的 10%–20%——910C 的较低能效比会推高这部分成本。
08 · 单位经济学:三个场景的三年 TCO 对账
用三个具体场景算清楚三年总拥有成本。芯片价格估算来源:H100 ~25,000/片(公开市场价),910C ~15,000–18,000/片(TrendForce 报道,华为整体方案较 H100 方案节省 60%–70%),电价按
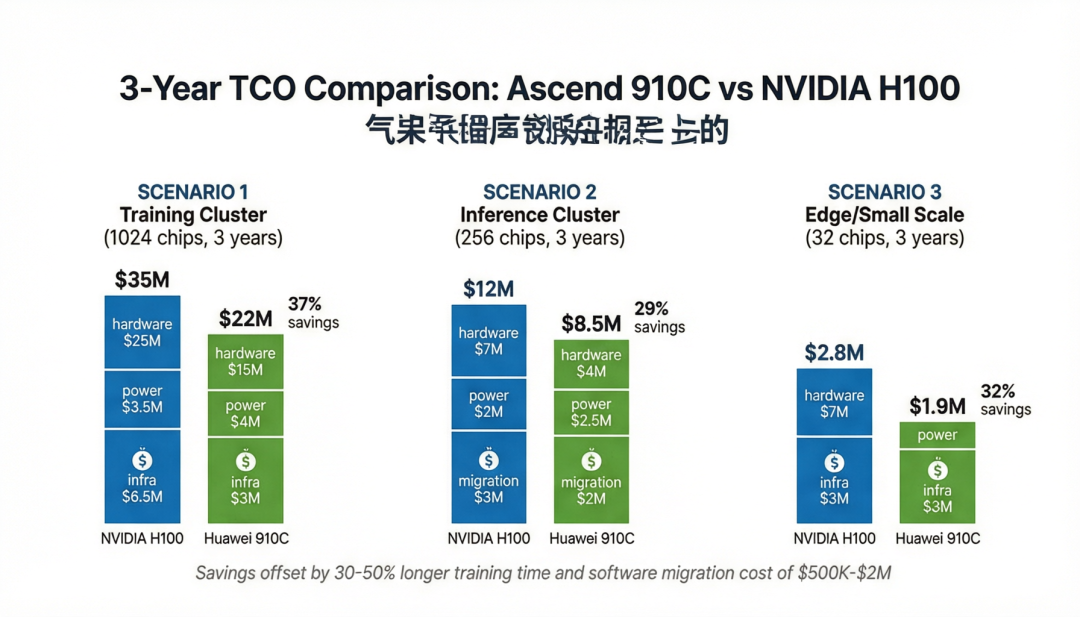
图 5 · 三年 TCO 对比——910C 硬件成本低 30%–37%,但软件迁移成本 (22–100 万) 抵消部分节省
场景 A · 大规模训练集群(1,024 卡,训练千亿参数模型,3 年)
H100 集群:硬件 1,024 × 25,000 = 25.6M + 功耗 1,024 × 700W × 24h × 365d × 3y × 0.10/kWh ≈ 3.8M + 网络/存储基础设施 ~5.6M ≈ 35.0M910C 集群:硬件 1,024 × 16,000 = 16.4M + 功耗 1,024 × 600W × 24h × 365d × 3y × 0.10/kWh ≈ 3.2M + 网络/存储基础设施 ~2.4M ≈ 22.0M软件迁移成本:一次性投入 ~1.0M(CANN 适配 + 分布式训练调试 + 性能调优)时间成本:由于有效训练算力差距 4.5 倍,同一模型在 910C 集群上的训练时间是 H100 集群的 4.5 倍——如果 H100 需要 30 天,910C 需要 ~135 天。这 105 天的额外训练时间对业务的影响难以用金钱直接衡量,但在快速迭代的 AI 竞赛中可能是致命的。价差:910C 集群总成本节省 13.0M(37%),其中硬件节省 9.2M、功耗节省 0.6M、基础设施节省 3.2M。迁移成本 1.0M + 训练时间 4.5 倍。净节省约
场景 B · 推理集群(256 卡,运行 70B 模型在线服务,3 年)
H100 集群:硬件 256 × 25,000 = 6.4M + 功耗 ≈ 1.0M + 基础设施 ~1.6M + 软件迁移 0(已有 CUDA 代码库)≈ 9.0M910C 集群:硬件 256 × 16,000 = 4.1M + 功耗 ≈ 0.8M + 基础设施 ~1.1M + 推理引擎迁移 ~0.5M ≈ 6.5M性能差距:910C 的推理吞吐约为 H100 的 70%–80%(DeepSeek-R1 基准),因此需要额外 ~30% 的卡数来达到相同 QPS。调整后 910C 硬件成本:333 × 16,000 = 5.3M,总 TCO ≈ 8.0M价差:调整后 910C 仍节省 1.0M(11%),但如果推理引擎迁移质量不达标导致 1%–2% 的可用性损失,年收入影响可能超过
场景 C · 边缘/政企推理(32 卡,运行 7B 模型,3 年)
H100 方案:硬件 32 × 25,000 = 800K + 功耗 ≈ 0.1M + 基础设施 ~0.3M ≈ 1.2M(但实际在中国市场无法采购 H100,需要灰色渠道,溢价 50%–100% → 实际成本 1.6M–2.0M)910C 方案:硬件 32 × 16,000 = 512K + 功耗 ≈ 0.08M + 基础设施 ~0.2M + 适配 ~0.1M ≈ 0.9M供应链溢价:H100 灰色渠道溢价 50%–100%,且无保修、无技术支持、存在法律风险。910C 正规渠道采购,含华为技术支持和保修。价差:考虑灰色渠道溢价后,910C 节省 0.7M–
结论:三个场景中,910C 的硬件成本始终低于 H100(37%/11%/55%),但大规模训练场景的 4.5 倍时间成本和大规模推理场景的软件迁移风险是关键变量。边缘/政企场景是 910C ROI 最高的战场——硬件成本低、供应链可控、性能充分。对于训练场景,如果时间不是瓶颈(如政府资助的基础研究),910C 可以节省 $12M+;如果时间是瓶颈(如商业 AI 公司追赶竞争对手),H100/B200 的时间优势远超硬件成本差距。
09 · Checklist:12 项采购决策清单
如果你正在为 AI 基础设施项目选择加速器,以下 12 项可以逐步推导出最优方案:
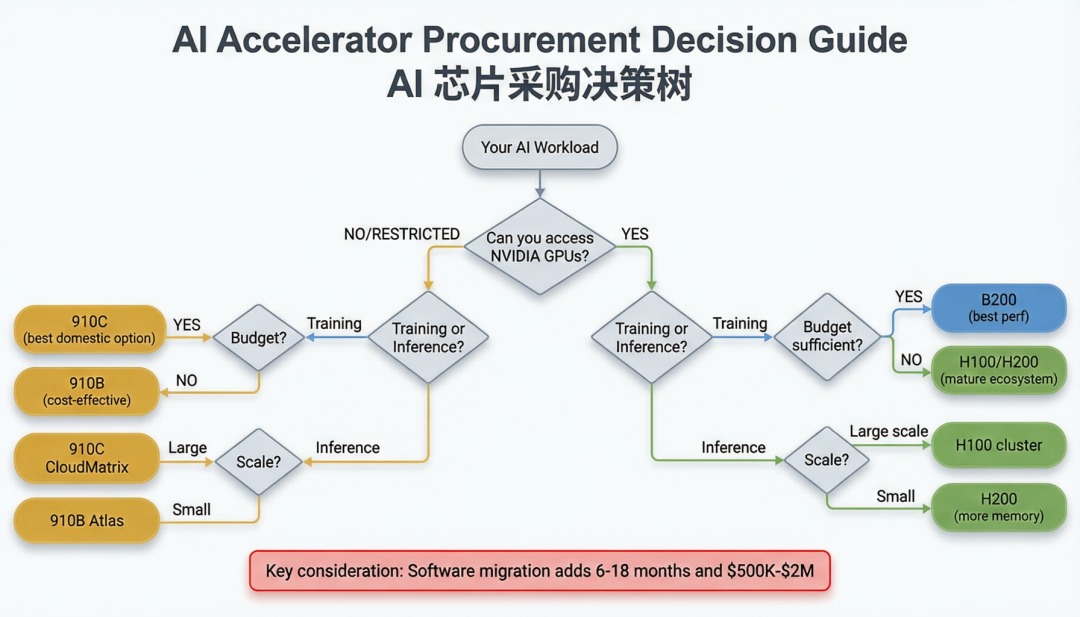
图 6 · AI 芯片采购决策树——按芯片可获得性、负载类型和预算选择最优路径
1 确认芯片可获得性:如果你在中国大陆且无法通过正规渠道采购 NVIDIA GPU,直接进入国产替代评估流程。如果可以采购 NVIDIA GPU(海外企业或研究机构),先做性价比对比再决定
2 量化模型规模:7B–13B 推理 → 910C 甜区(96 GB HBM 充足,性价比优)。70B+ 推理 → 910C 可用但效率低 30%–45%。千亿参数训练 → 910C 可以完成但时间是 H100 的 4.5 倍
3 评估软件栈兼容性:列出你当前使用的所有 PyTorch 自定义算子数量。如果 >50 个自定义算子,迁移到 CANN 的工程投入估计 >6 个月。如果使用 MindSpore 或纯推理(ONNX),迁移成本显著降低
4 计算迁移成本:人力成本 = 算子适配 + 分布式调试 + 性能调优。参考值:中等项目 6–18 个月,4–12 名工程师,¥160 万–720 万(22 万–100 万)。将此成本加入 TCO 计算
5 评估时间敏感度:如果模型训练时间对业务有直接影响(如 AI 公司追赶竞争对手),910C 的 4.5 倍训练时间成本可能远超硬件节省。如果是政府资助的基础研究或时间不敏感的预训练,时间成本可以接受
6 验证推理性能:用你的目标模型和真实数据在 910C 上跑推理基准(prefill + decode tokens/s,TTFT,P99 延迟)。不要依赖厂商公布的数字——用自己的数据跑。确认 910C 的推理性能是否满足 SLA
7 计算互联带宽需求:如果你的模型需要张量并行(TP >1),确认 HCCS 400 GB/s 是否足够。70B 模型 8 卡 TP 的 AllReduce 通信量约 ~100 GB/次前向传播,HCCS 上延迟约为 NVLink 的 2.25 倍。考虑是否需要更多卡用流水线并行(PP)替代张量并行
8 评估供应链风险:H100 灰色渠道溢价 50%–100%,无保修无支持且有法律风险。910C 正规渠道含华为技术支持和保修。长期来看,选择可控供应链(910C)的风险远低于灰色渠道(H100)
9 测试故障恢复机制:在目标集群规模上模拟节点故障,测量从故障检测到训练恢复的时间。H100 + NCCL 典型值 5–15 分钟,910C + HCCL 约 15–30 分钟。千卡集群上每次故障 15 分钟的额外停机时间,一年累积约 50–100 小时
10 规划电力和散热:910C TDP 600W vs H100 700W,但能效比低 2.1 倍(1.33 vs 2.83 TFLOPS/W)。完成相同计算任务,910C 消耗的总电力更多。确认数据中心的电力容量和散热能力是否匹配
11 考虑双轨策略:如果有海外团队或合作伙伴可以使用 NVIDIA GPU,最优策略可能是"海外训练 + 国内推理"——用 H100/B200 做大规模预训练,将模型导出到 910C 做推理服务。这避开了 910C 在训练上的弱势,同时利用了推理场景的成本优势
12 跟踪 CANN 版本路线图:CANN 每个大版本的 API 变动约 15%–25%,升级迁移成本不可忽视。制定 CANN 版本锁定策略(生产环境锁版本,开发环境跟进最新),并预留每季度 1–2 周的版本升级工程窗口
结语
910C 是在制裁约束下的最优国产选择,H100/B200 是全球自由市场上的性能标杆。
硬件层面,差距是系统性的:FP16 算力 40%(800 vs 1,979 TFLOPS)、显存带宽 54%(1.8 vs 3.35 TB/s)、互联带宽 44%(400 vs 900 GB/s)。叠加 MFU 差距后(30% vs 55%),有效训练算力差距达到 4.5 倍。但在推理场景,910C 的实际表现达到 H100 的 70%–82%(DeepSeek-R1 基准),差距远小于训练场景。
软件层面,CANN 与 CUDA 的差距体现在算子库(~2,000 vs 10,000+)、调试工具(kernel 级分析能力有限)、和社区规模(数千 vs 数百万开发者)。迁移一个中等规模项目需要 6–18 个月和 22 万–100 万的人力投入。对于标准模型架构(GPT、LLaMA),CANN 的覆盖是足够的。差距主要体现在非标准算子和前沿研究模型上。
经济学层面,910C 的硬件成本始终低于 H100(37%–55%),在边缘/政企场景下供应链优势显著。但在大规模训练场景,4.5 倍的时间成本和 $100 万级的迁移成本是关键变量。最优策略可能是"双轨"——用 NVIDIA GPU 做训练(如果可以获取),用 910C 做推理部署。
FINAL TAKEAWAY
910C 推理 = 800 TFLOPS · 96 GB HBM · 1.8 TB/s · DeepSeek-R1 decode 1,943 tok/s/NPU(H100 的 ~81%)→ 7B–70B 模型推理性价比优,国产替代首选
H100 训练 = 1,979 TFLOPS · 80 GB HBM · 3.35 TB/s · MFU 55% → 有效训练算力为 910C 的 4.5 倍,大规模预训练仍是 NVIDIA 主场
最优策略 = 双轨架构:海外训练 + 国内推理 → 避开 910C 训练弱势,利用推理成本优势,三年 TCO 节省 1M–12M(视场景)
REFERENCES
[1] TrendForce, "Huawei's Ascend 910C Takes on NVIDIA as China's AI Race Heats Up"(2025.03)— 910C 双 die 封装架构、60%–70% H100 性能比、华为整体方案较 H100 节省 60%–70%
[2] NVIDIA H100/H200/B200 Official Datasheets(nvidia.com)— FP16 1,979 TFLOPS(H100),141 GB HBM3e(H200),4,500 TFLOPS FP16(B200),NVLink 900–1,800 GB/s
[3] Recode China AI, "How Huawei Trains DeepSeek-R1-Class LLMs Using Its Own Chips"(2025)— CloudMatrix 384 集群规格,盘古 Ultra MoE 训练 MFU ~30%,6,000+ NPU 集群规模
[4] Flanders-China Chamber of Commerce / SCMP, "Huawei's Ascend AI-chips outperform Nvidia in DeepSeek-R1"(2025)— 910C 推理 prefill 6,688 tok/s/NPU,decode 1,943 tok/s/NPU
[5] CFR(Council on Foreign Relations)/ CSET(Center for Security and Emerging Technology)— 中国 AI 芯片年需求 100–150 万片,华为 2025 年出货约 20 万片,2026 年计划 60 万片
[6] AMD MI300X Official Specifications(amd.com)— FP16 2,610 TFLOPS,192 GB HBM3,5.3 TB/s 带宽,750W TDP,5nm/6nm 制程
#Ascend910C #H100 #B200 #CANNvsCUDA #AIInfra #ChipExportControl
本文数据截至 2026 年 6 月,所有数值来自公开数据手册、行业报告与基准测试。芯片价格因渠道和批量而异,文中估算仅供参考。欢迎指正。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-18,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号