在金融场景下,如何解决GenAI的置信度问题+避坑指南(Spotify)

在金融场景下,如何解决GenAI的置信度问题+避坑指南(Spotify)

用户10377957
发布于 2026-06-17 16:32:19
发布于 2026-06-17 16:32:19
GenAI 做 “不能出错” 的场景(比如金融、法律、医疗),一定会遇到一个关键问题:怎么判断 GenAI 的输出靠不靠谱?Spotify 的金融工程团队最近分享了他们的实战案例 —— 用 GenAI 自动化 “全球发票解析”(供应商发票格式乱、语言杂,传统方法搞不定),但金融场景要符合 SOX 合规,必须给 GenAI 输出加一个 “置信度分数”(分数够高就自动通过,不够的话,就由人工来审核)
这篇文章不聊复杂理论,只总结他们的可复用经验:从 3 种方法里筛出最优解,再到落地时要抠的细节,最后是还没解决的挑战,全是干货。
1 先明确:为什么严肃场景必须要 “置信度分数”?
Spotify 的起点很典型,先想清 “为什么要做”,再找 “怎么做”:
- 合规硬要求 金融领域要符合
SOX法案,不能 “凭感觉信 AI”,必须有明确的 “靠谱依据”; - 业务容错低 发票解析错一个数字(比如金额、税号),可能导致财务对账混乱,甚至合规风险
- 人工衔接需要 不能全靠
AI,也不能全靠人 —— 需要一个分数当 “开关”,自动划分 “AI 能搞定的” 和 “必须人工审的”,提高效率。

random
2 三种置信度方法实测:2 种淘汰,1 种留用
Spotify 试了 3 种主流方法,每一种都踩了具体的坑,最终只留下 1 个能用的。
方案 1(已淘汰):校准器模型(让 AI 评 AI)
- 做法 找一个额外的
GenAI模型,给 “主模型的输出” 打分(比如问 “这个发票金额解析对吗?打个置信分”); - 优点 能独立判断,还能学人工反馈优化
- 致命问题:
- 分数 “说不清道不明”:比如给 80 分,但说不出 “为什么 80 分”,合规场景不接受 “黑箱评分”;
- 结果不稳定:同一个输出,两次评分可能差 10 分以上,金融场景要 “确定性”,不要 “随机性”。
方案 2(已淘汰):对数概率
- 做法 看
GenAI生成每个词时的 “自信度”(比如生成 “100 元”,看模型对 “100” 和 “元” 的自信值),再平均换算成分数; - 优点 能拿到模型底层数据,看似 “客观”;
- 致命问题:分数和 “实际准确率” 没关系!比如分数 90 分的输出,实际错了;分数 70 分的,反而对了 —— 完全没用。
留用方案:多数投票(多模型比共识)
- 做法 让多个不同的
GenAI模型一起解析同一个发票(比如 5 个模型),置信度分数 =“同意同一个答案的模型比例”(5 个里 4 个同意,就是 80 分); - 为什么留用:
- 分数和准确率强相关:测试发现,同意的模型越多,答案正确率越高,符合 “分数越高越靠谱” 的预期;
- 逻辑易懂:“多数人同意” 的逻辑,合规团队能理解,人工审核时也能解释;
- 结果稳定:只要模型和数据不变,每次评分结果基本一致。

random
3 多数投票落地:3 个必须抠的细节
“多数投票” 看着简单,但直接用会踩坑,Spotify 做了 3 个关键优化:
模型数量:5-6 个最合适
- 文献说 “4-7 个模型能平衡多样性和成本”,他们实测:
- 少于 5 个:容易出现 “多数人都错” 的情况(比如 3 个模型全解析错);
- 多于 6 个:时间和成本翻倍(模型调用花钱),但准确率提升很少;
- 最终选 5-6 个,覆盖不同厂商的模型(避免同一厂商模型 “同质化犯错”)。
投票要 “加权”:准的模型话语权更大
- 不是每个模型都一样准:比如 A 模型准确率 90%,B 模型只有 80%;
- 优化:给每个模型按 “历史准确率” 加权(A 的 1 票算 1.2 分,B 的 1 票算 1 分),最后按 “加权总分” 算置信度,避免 “不准的模型拉低分数”。
分数要 “校准”:让分数和实际准确率对齐
- 问题:原始投票分和实际准确率有偏差(比如投票分 80%,实际准确率只有 70%);
- 解决:用 “Platt scaling” 算法调整分数 —— 把历史数据里 “投票分” 和 “实际对错” 做映射,比如把原始 80 分校准成 78 分,让分数更贴近真实准确率。

random
4 还没解决的挑战:两个临时应对方案
Spotify 也没做到完美,目前有 两个待解决的问题,他们的临时办法可以参考:
1. 长文本解析:拆成小块比对着
- 问题:发票里的长文本(比如地址 “北京市朝阳区 XX 街道 XX 号”),不同模型说法容易不一样(比如有的漏 “街道”,有的多 “市”),没法直接算 “共识”;
- 临时方案:把长文本拆成 “小原子”(地址拆成 “城市 + 街道 + 门牌号”),每个小块单独算投票分,最后汇总 —— 虽然麻烦,但比直接评长文本准。
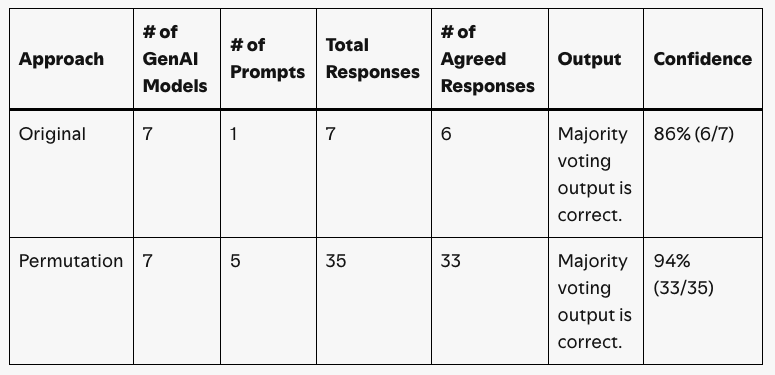
2. 分数粒度不够:多给模型 “提问题”
- 问题:7 个模型,步长是 14% 的粒度(1/7≈14%),如果需要 95% 的分数才能过审,可是 由 7 个模型给分数,95%的两侧只能是 100%或 86%;
- 临时方案:每个模型用 5 种不同的提示词(比如 “解析发票金额”“请确认发票上的金额是多少”),总回答数变成 7×5=35 个,步长粒度可以到 3%(1/35≈3%),比如 33/35≈94%,更贴近业务需求;
- 缺点:成本涨 5 倍,长期得找更省钱的办法(比如用轻量模型做多提示)。
如何得到准确的置信度
5 给你的三个核心启示
不管你是做金融、医疗还是法律的 GenAI 应用,Spotify 的经验都能复用:
- 选方法先看场景:别迷信 “复杂模型”,金融这种要 “确定性” 和 “可解释” 的场景,“多数投票” 比 “黑箱校准器” 更有用;
- 细节决定能不能用:同样是多数投票,不做 “加权” 和 “校准”,分数就是不准的,落地时一定要抠细节;
- 接受不完美,小步迭代:长文本、成本这些问题暂时解决不了没关系,先找临时方案用起来,再慢慢优化 —— 比等 “完美方案” 更重要。
如果你的团队也在做 GenAI 严肃场景,不妨从 “多数投票” 开始试,Spotify 已经帮你踩过前两个坑了~
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-08-31,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号