ChatBI V2 迭代实录:把「规则问答」升级成可验收的 Agent

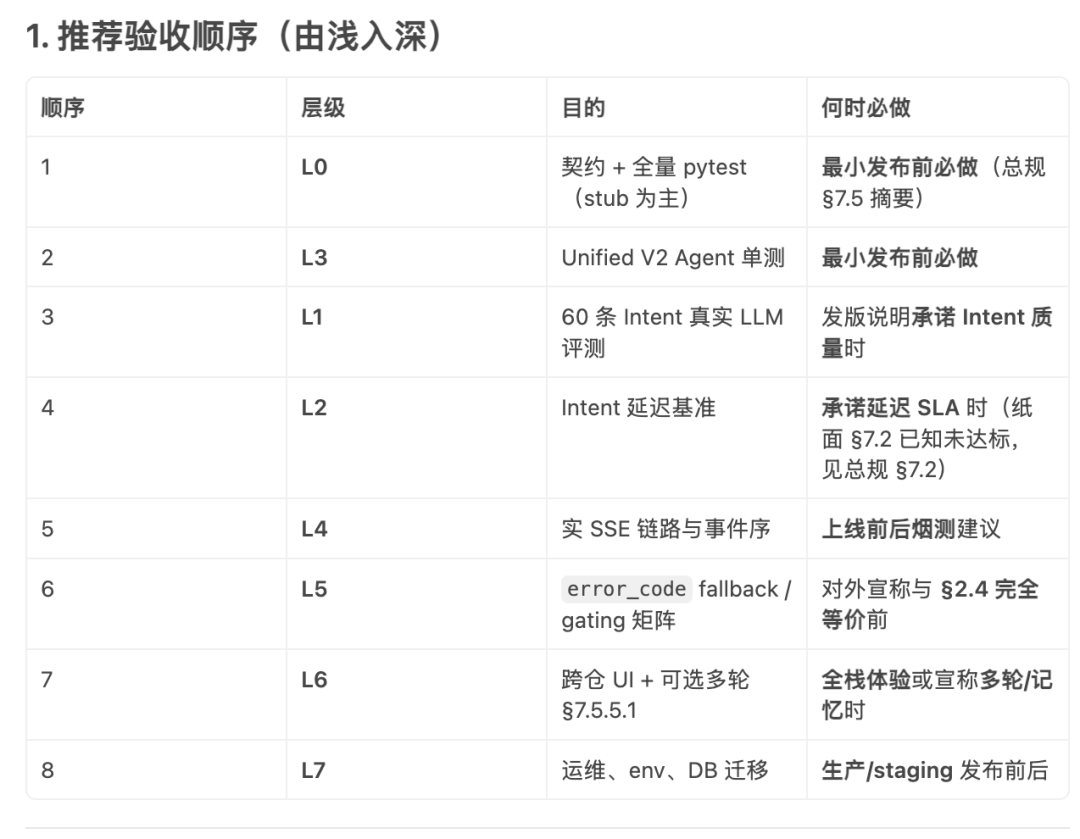
ChatBI V2 迭代实录:把「规则问答」升级成可验收的 Agent

小小猪排画中游
发布于 2026-06-16 17:13:10
发布于 2026-06-16 17:13:10

时间范围:正文主体为 2026 年 4 月 29 日 — 5 月 10 日的 V2 改进;5 月 11 日 在工程侧完成 V2 文档与 Runner 收口归档,并合入 Text2SQL 防漂移:YAML 值域与 DISTINCT 探针联动(见 §二第 6 节续篇)。下文「整体进度」与《项目设计大纲》里程碑对齐说明。 依据:ChatBI V2 规格体系(总规目标、事件策略、验收与回归口径)与 《项目设计大纲》 中的 V1 / V2 / V3 版本分层与交付边界——「已交付」与「下一版规划」不混写。
一、为什么要做 V2?
V1 本质是 「规则路由 + 固定分支」:能跑通 RAG、Text2SQL 和流式输出,但遇到复杂问题时,决策不可解释、多步协作弱、失败只能报错。V2 在规格里定下的方向可以概括成五句话:
- 由 LLM 参与意图与工具选择,规则路由退居 超时 / 低置信时的降级路径。
- 用类 ReAct 的循环 支持多步推理、工具切换与按失败类型的回退(含「无检索命中时是否允许转 SQL」等 门控)。
- 多轮记忆 与会话落库可追溯,而不是「只记住最后一次提问」。
- 事件流兼容:对外仍保留旧版模式语义,对内增加 Agent 过程帧,且 契约化(类型与最小字段可校验),避免前后端各说各话。
- 可验收:除功能外,要有 分级回归(L0~L7)、样例输出与文档索引,证明不是一次性脚本。
《项目设计大纲》里与之对齐的原则是:里程碑可核对、对外叙事不自相矛盾——V2 清单只写 本里程碑内已落地 的能力;企业级权限、语法级 SQL 防护、熔断限流、多租户等,明确放在 V3 / V4 规划,不提前算进 V2「已交付」。
二、这三周,V2 具体改进了什么?(按主题,不讲工程目录细节)
1. Agent 骨架与「能讲清楚」的过程
- 4 月底:把 多步 Agent 从纸面落到可跑:循环上界、工具封装、失败分支策略;流里出现 步骤开始 / 思考摘要 / 意图结果 / 步骤结束 / 最终汇总 等过程帧,并和 契约表 对齐,避免「后端多发了字段、前端不敢用」或反过来 流水线一推就红。
- 价值:对外技术分享时,可以讲清 决策循环 + 可观测事件 + 契约门禁,而不是只讲「接了大模型 API」。
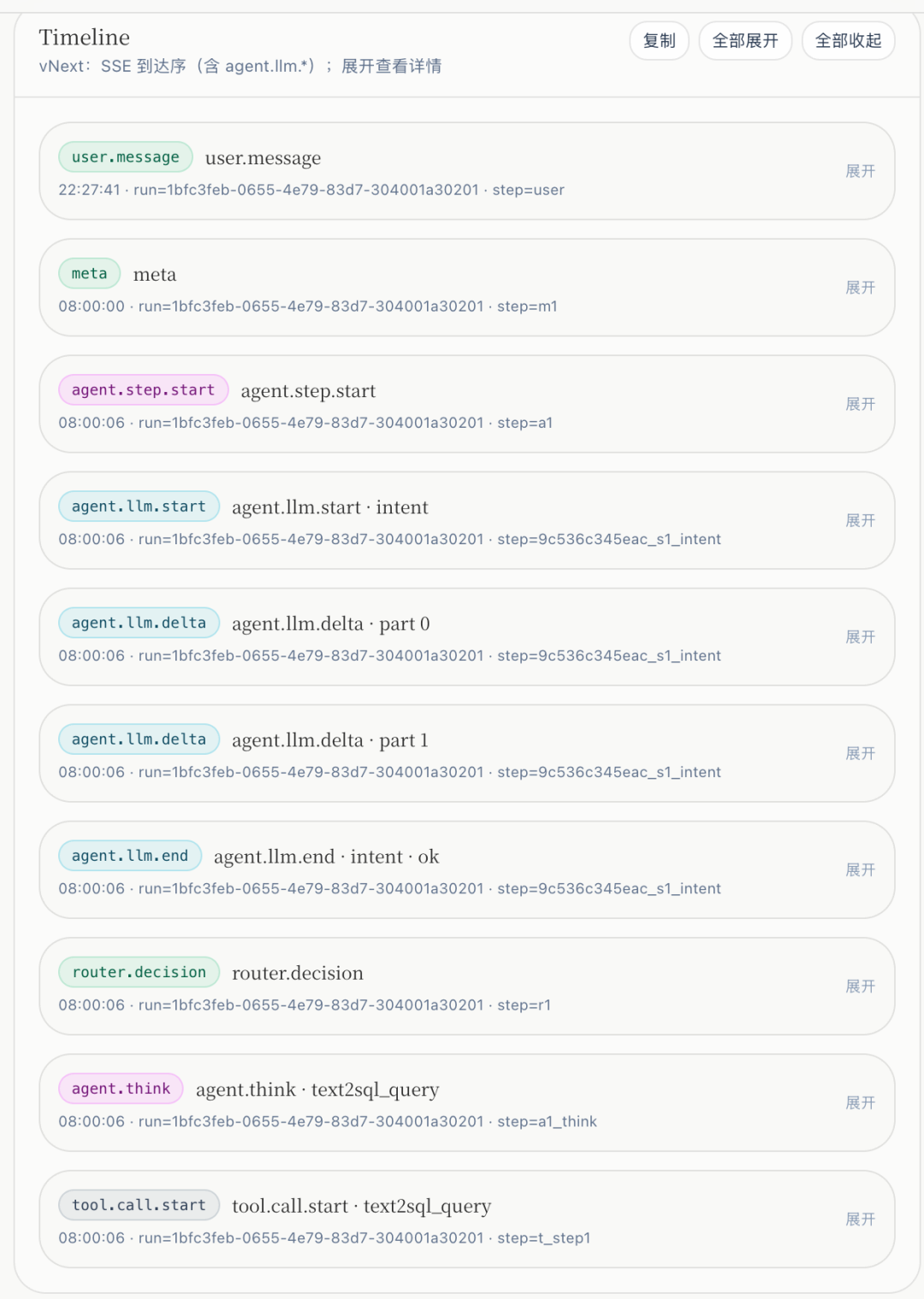
2. 路由可解释:从「黑盒 prefer」到「证据上屏」
- 4 月 30 日一带:把 路由证据 做成独立事件,前端时间线可展示;默认 落库追溯,请求级调试开关再决定是否下发「候选列表级」细节,兼顾 线上隐私 与 排障需要。
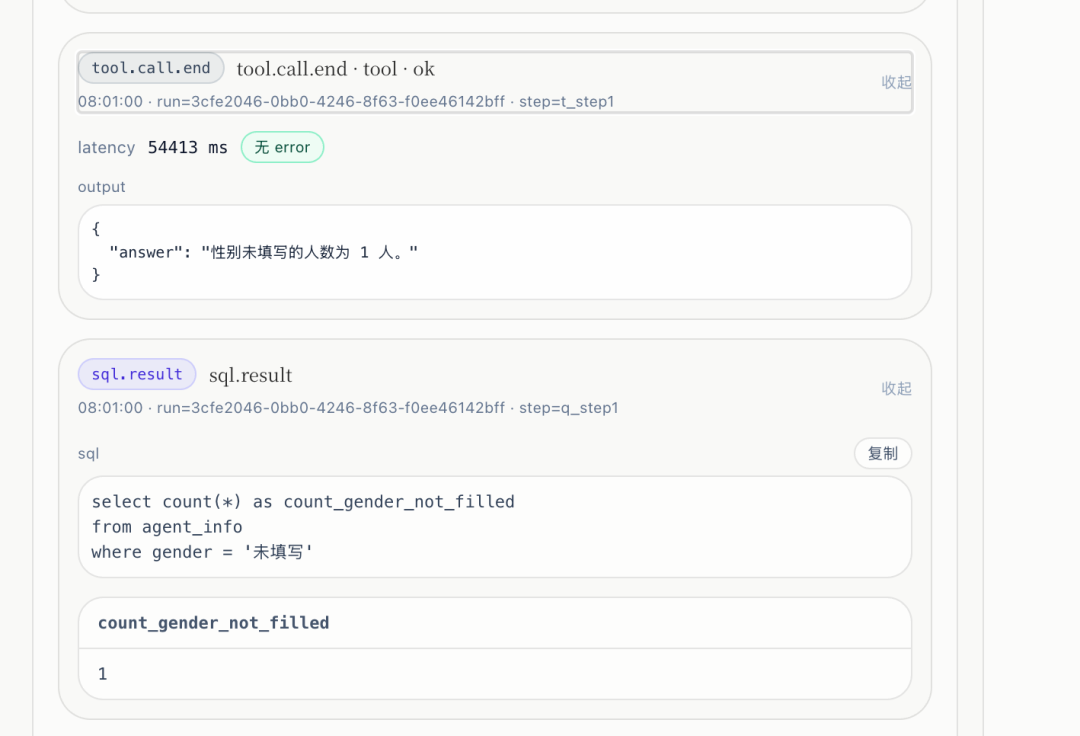
- 同步补齐 路由全链路轨迹、Text2SQL 执行摘要等,让「为什么走了 SQL / 为什么降级」能 事后复盘。
3. 流式与网关:假超时、断流、序列化雷区
- 5 月上旬:长耗时阶段若 长时间没有字节写出,中间网关会误判超时——通过 注释型保活帧、把重落库挪到 异步 且不挡主 emit,稳住长连接。
- 同时修了 流结束时的边界 bug、SQL 结果里 非 JSON 友好类型 导致整条 SSE 崩溃等问题;并对 旧库表结构 做了 写入降级(新列不存在时仍能插入核心字段),避免「一上线全挂」。
技术点归纳:SSE 不仅是「把字符串推出去」,而是 背压、保活、序列化、兼容旧数据 的组合题。
4. 意图层工程化:评测、缓存、Prompt 与历史窗口
- Intent 评测:固定用例集、导出表格/日志,默认自动化测试不把真实大模型评测打开(避免流水线或本地全量跑死),需要时再显式打开。
- 缓存:LRU + TTL、复合键(含历史摘要)、命中/未命中与耗时 可在时间线上看到,和规格里「可观测」一致。
- Prompt 与历史:收紧「要执行查询 vs 问概念」的边界,限制 历史条数与每条长度,减少多轮指代时的胡答。
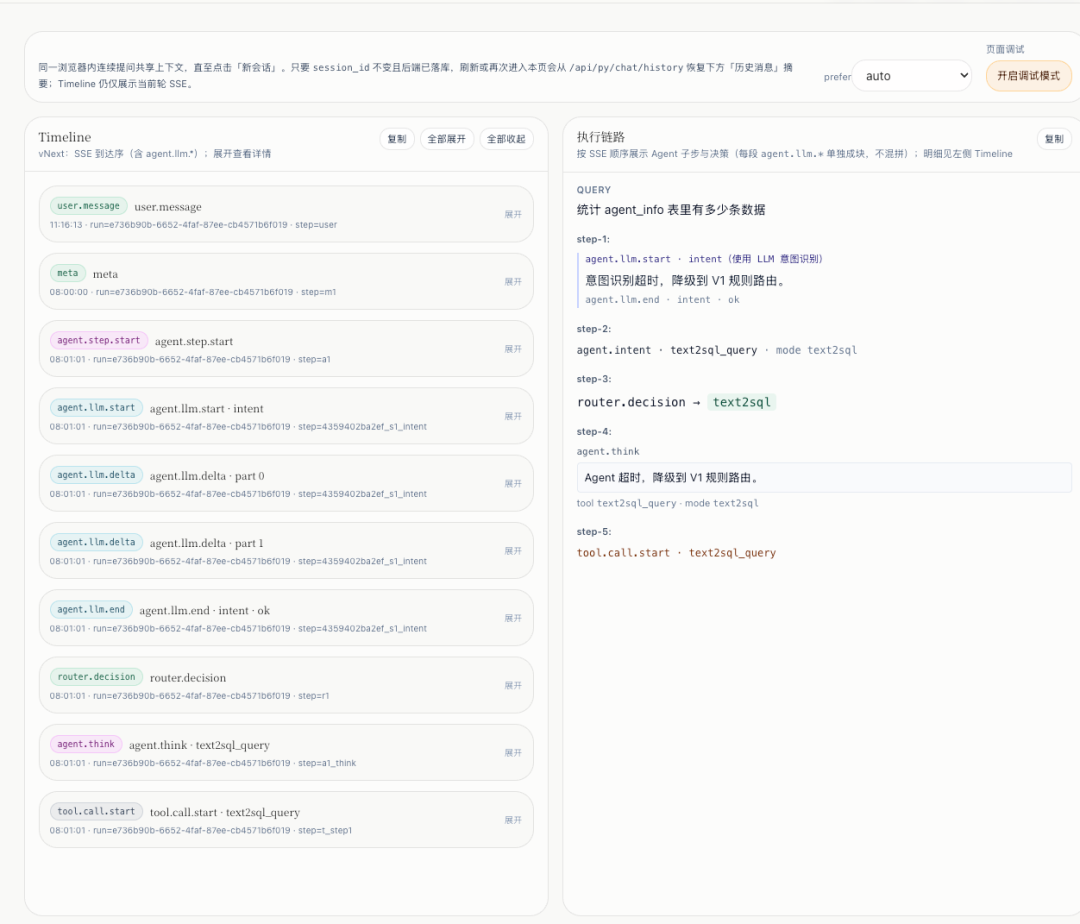
5. 增量流式体验:双栏、契约版本、契约校验「减误报」
- 5 月 8 日前后:前后端约定 流式协议版本号(请求头声明),未升级客户端仍走 整段回放;升级后走 增量 LLM 子阶段帧,界面默认 左时间线、右增量文本,并把 仅 UI 使用的辅助字段 从「跨仓契约强校验」里剥离,减少 假阳性漂移告警。
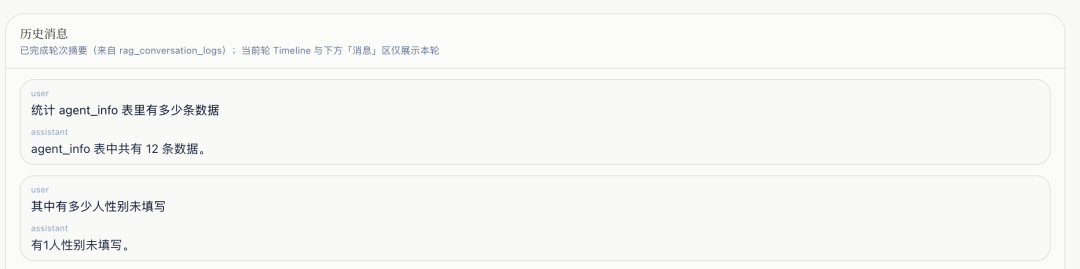
6. 多轮与 Text2SQL:语义承接与「值域提示」
- 5 月 9 日一带:前端 多轮 transcript(已完成轮与当前轮分工)、Strict 模式下的双写与 key 重复 修复;后端 多轮 grounding 与 多轮语义承接 规约落地,避免只靠 prompt「赌指代」。
- 列值域 YAML:把「枚举/取值提示」从 prompt 里抽成 可版本化数据:
**values** 表示库内枚举真值,**synonyms**把口语映射到真值,便于评审与 diff,而不是把整本业务词典塞进一段 prompt。与下文 DISTINCT 探针的并集配合见 §8(5 月 11 日补充)。
7. 验收阶梯与「能自证」的 Runner(截至 5 月 10 日)
- 5 月 10 日:把 L0~L3 写成可复制的命令与证据索引;L4 落 SSE 文本样例;L5 把失败矩阵类用例从「跳过」改为 默认必须过;L6 多轮 UI 侧验收成文;并在企业能力差距总览里 单独立项「工具链延迟观测」等 V3 入口,与 V2 交付边界划清。
说明(与 5 月 11 日关系):5 月 10 日已完成 L0~L6 与大量留证、任务归档 的可讲述版本;5 月 11 日 完成 V2 文档验收归档与索引封卷。对外可一句话概括:「能力与分级验收在 5 月 10 日已闭环;文档与归档在次日收口。」 与《项目设计大纲》中的 V2 里程碑结点 一致。
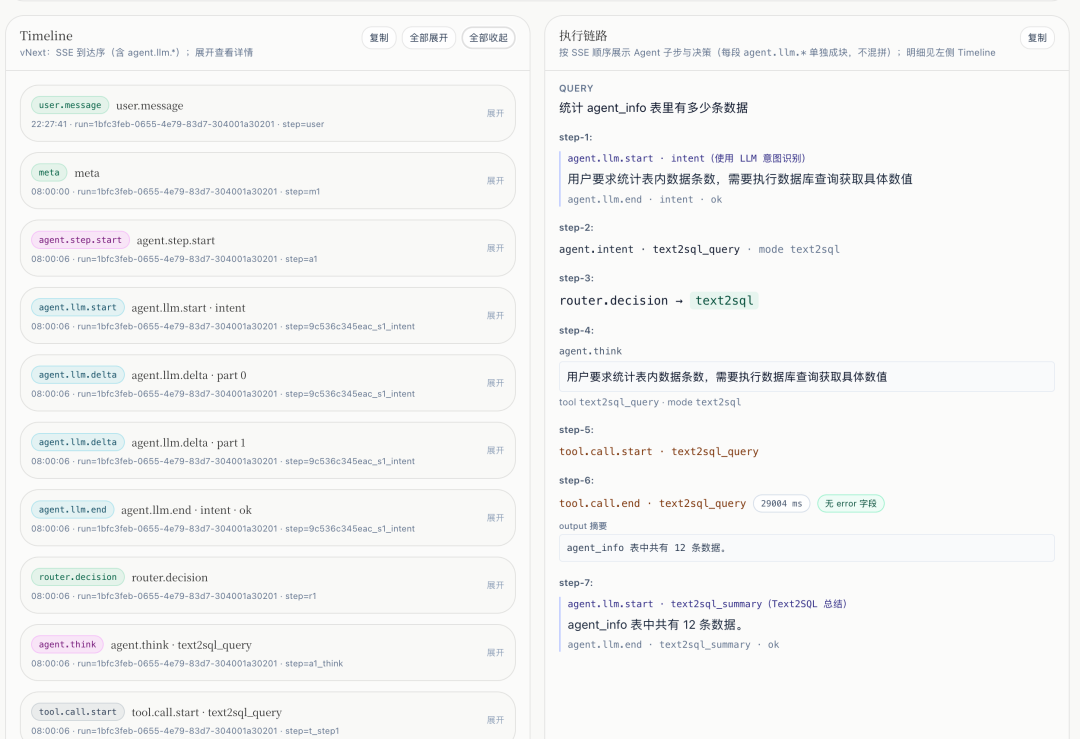
8. DISTINCT 探针与 YAML:「字典 ∪ 采样」防漂移(5 月 11 日工程补充)
与《项目设计大纲》中 Text2SQL 防漂移 / 可观测 同一脉络:在 V2 里程碑封卷日 与 子阶段 SSE 耗时、结构化观测日志、HTTP 重试 等同一波工程合入;其中 「DISTINCT 与 YAML 值域并集」 对应封卷日的 B-PR2 级交付口径。
自然语言问数时,大模型最容易在 枚举类字段 上「编一个看起来像的值」——仅靠 YAML 闭集,库侧真实枚举一变就漂移;仅靠模型自由发挥,又 不可审计。做法是 两层真值并成一层提示:
- YAML 字典(人维护)
**values**:业务认定的 库内枚举真值。**synonyms:口语 → 真值**,探针采不到的新说法仍靠人工或流程补,不把同义词交给模型瞎造。
- DISTINCT 探针(只读、可关)
- 在 白名单列 上对真实库执行
**SELECT DISTINCT … LIMIT N** 的 只读采样(需 显式开关 + 列清单,避免全表扫)。 - 采样结果与 YAML 的
**values做并集去重**,再按 字典序 写回给模型的「可取值提示」。 - 语义:模型看到的是 「字典 ∪ 采样」的并集;在存在
LIMIT时 不是数学闭集——避免把「采样截断」误当成「全世界只有这几个值」。
- 失败与降级
- 探针若因 超时、权限、未配置业务库连接 等失败:该列自动降级为仅 YAML,不阻断整条 Text2SQL。
- 库侧新增枚举:会通过 DISTINCT 进入并集;新口语仍优先走 YAML 同义词 或人工补录。
- 与执行链路的配合
- 值域合并可与 异步线程 结合,避免阻塞主事件循环;执行侧可叠加 单条 SQL 超时、网关瞬断重试 等与「问数稳定性」同一层级的能力。
- 与 子阶段耗时、单行结构化观测 并列时,能同时回答:「模型被告知了哪些取值?」 与 「生成和执行各花了多久?」

三、整体完成进度(与《项目设计大纲》的版本分层对齐)
结合规格中的 V1→V2 目标 与 《项目设计大纲》 的 里程碑划分,可用下面这张表对外说明(勾选表示 截至 5 月 10~11 日已在当前工程中落地):
能力块 | 状态 | 备注 |
|---|---|---|
V1:RAG / Text2SQL / 规则路由 / SSE | ✅ 已完成 | 产品基座 |
V2:ReAct + 工具 + 失败回退 / 门控 | ✅ 已完成 | 含软超时语义修正(避免多步死循环) |
V2:LLM 意图 + 超时/低置信降级 V1 | ✅ 已完成 | 含评测与缓存可观测 |
V2:多轮记忆与落库、过程事件契约 | ✅ 已完成 | 含跨端契约与 CI 门禁思路 |
V2:增量流式 + 双栏时间线 | ✅ 已实现 | 协议版本开关,旧客户端可不退步 |
V2:多轮语义承接 + 值域提示数据面 | ✅ 基线已交付 | 5 月 9 日前后:YAML 列值域与多轮 grounding 基线;5 月 11 日:DISTINCT 探针与 YAML 并集合入,与防漂移同一叙事。澄清策略、DISTINCT 列级节能策略全文等仍按企业 Gap 与 V3 欠债规划,不在此表夸大 |
企业级:RBAC、语法级 SQL 防护、熔断限流、多租户 | 📋 V3 / V4 规划 | 与《项目设计大纲》中的 下一版范围 一致 |
四、实施中的坑与解决办法(故事版)
坑 | 现象 | 解决办法(可写进复盘/分享) |
|---|---|---|
长连接假超时 | Agent 或落库阶段很久不发字节,网关先断 | 保活帧 + 重 IO 异步化,主线程专注 emit |
流式收尾偶发崩溃 | 结束包处理用到未绑定变量、或类型不能 JSON 化 | 收尾逻辑单测固化;对结果表做 安全序列化 |
Strict 模式双写 | 开发态正常、Strict 下 transcript 重复 | 不要在同一状态更新函数里混写副作用;flush 后再读已提交状态;列表 key 不用纯内容当 key |
评测拖垮流水线 | 环境误开真实大模型评测,全量测试卡死 | 测试夹子里优先清理意图评测相关环境变量;真实评测改 手动或独立任务 |
契约校验误报 | 前端为布局加的辅助字段被当成「后端契约缺失」 | UI 键从强校验集合剔除(启发式 + 白名单),保留真字段门禁 |
「无检索命中就转 SQL」 | 浪费 SQL、体验差甚至有风险 | 规格里 Gated:只有结构化意图信号足够才允许转 SQL,否则追问或直接答 |
Agent 软超时误伤多步 | 每步都强制降级成规则路由,RAG 路径打转 | 仅在尚未执行任何工具前允许超时降级,后续步交给失败处理器 |
旧环境表结构落后 | 新列不存在导致插入失败 | 检测列 → 降级插入路径,关键诊断信息塞进已有 JSON 元数据 |
枚举闭集幻觉 | 模型编造库里没有的取值,或 YAML 滞后于真实库 | YAML 字典 + DISTINCT 探针并集写提示;探针失败则 仅 YAML;新口语走 synonyms 补录 |
DISTINCT 拖慢或拖死循环 | 探针无上限、或与主循环同线程执行 | 白名单列 + LIMIT;探针与重 IO 异步化,失败 降级 不阻断主链路 |
五、技术点清单(可用于公众号「要点卡片」)
- 架构:自研轻量 Agent 循环,不绑重型编排框架;工具结果统一 错误码 + 可序列化负载。
- 协议:SSE 事件 类型扩展 + 最小字段契约 + CI 静态扫描,前后端可渐进升级。
- 观测:路由证据、执行分段耗时、单行结构化日志雏形、Runner L0~L6 分级证据链。
- 体验:增量子流、双栏、时间线稳定 key、调试态可复制会话标识。
- 数据与 SQL:多轮 grounding;YAML 列值域(
values+synonyms);DISTINCT 探针与字典 并集写提示、失败降级;与 单条 SQL 超时、后续 子阶段耗时观测 同一防漂移叙事(澄清与列级节能等 完整策略 仍归 V3 / 企业 Gap)。 - 工程文化:规格—任务—验收—归档 同一叙事,与《项目设计大纲》中的 版本分层、交付边界 对齐。
六、结语
这三周的本质,不是「多接了几个 API」,而是把 ChatBI 从 能回答 推进到 能解释自己为什么这样答、失败时怎样换路、怎样在流式与网关上活下来、怎样用验收表证明不是 Demo。
若只收束三句话给读者:
- V1 是规则系统,V2 是带契约与分级验收的 Agent 化升级。
- 企业级能力写进下一版规划与企业 Gap,不与 V2 里程碑抢功。
- 最难的是流式、观测与版本边界——已落到规格、Runner 与设计大纲的同一套叙事里。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-11,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号