【TensorFlow系列教程第三章】TensorFlow 中常用数据操作全解析

【TensorFlow系列教程第三章】TensorFlow 中常用数据操作全解析

代码简单说
发布于 2026-06-16 14:09:11
发布于 2026-06-16 14:09:11
TensorFlow 中常用数据操作全解析

在这里插入图片描述
在深度学习领域,TensorFlow 作为一款强大的开源深度学习框架,为开发者提供了丰富且实用的数据操作功能,熟练掌握这些功能对于高效处理数据以及训练高质量的深度学习模型起着至关重要的作用。本文将详细介绍 TensorFlow 中常用的数据操作,主要涵盖数据加载、预处理以及转换等方面,同时也会对数据预处理中的各个具体步骤展开深入讲解,希望能帮助大家更好地理解和运用 TensorFlow 的数据处理能力。
一、数据加载
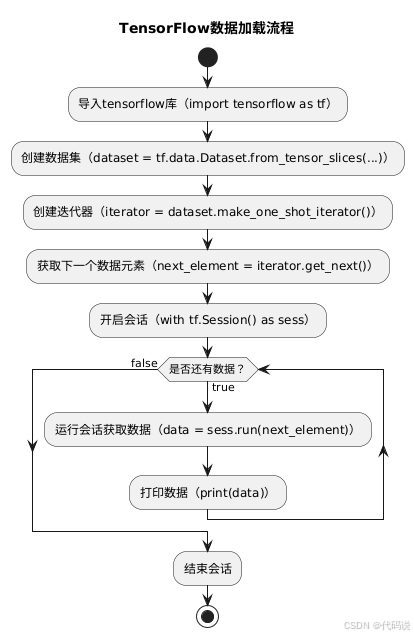
在这里插入图片描述
在 TensorFlow 中,我们可以借助 tf.data 模块来加载数据,该模块提供了一组用于构建输入数据管道的得力工具,特别适用于高效地加载和处理大规模数据集。以下是一个简单的示例代码,展示了如何使用 tf.data 模块加载数据:
import tensorflow as tf
# 加载数据集
dataset = tf.data.Dataset.from_tensor_slices([1, 2, 3, 4, 5])
# 创建迭代器
iterator = dataset.make_one_shot_iterator()
# 获取数据
next_element = iterator.get_next()
# 打印数据
with tf.Session() as sess:
while True:
try:
data = sess.run(next_element)
print(data)
except tf.errors.OutOfRangeError:
break通过上述代码,我们先是利用 from_tensor_slices 方法从给定的数据创建了数据集对象,接着创建迭代器并通过循环获取数据,直到数据集遍历完毕。
二、数据预处理
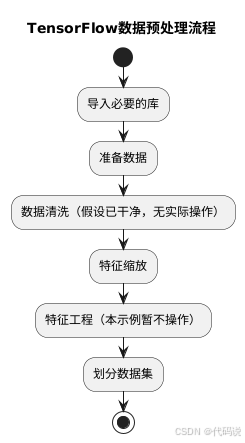
在这里插入图片描述
数据预处理在机器学习和深度学习过程中是不可或缺的关键步骤,它能够将原始数据进行加工,使其更契合模型训练的要求。在 TensorFlow 中,数据预处理通常包含多个环节,比如归一化、标准化、数据增强以及处理缺失值、异常值等操作。下面我们以图像数据为例,展示一些常见的预处理操作:
import tensorflow as tf
# 读取图像数据
image = tf.io.read_file('image.jpg')
image = tf.image.decode_jpeg(image)
# 图像归一化
image = tf.image.convert_image_dtype(image, tf.float32)
image = (image - 127.5) / 127.5
# 图像裁剪
image = tf.image.resize_image_with_crop_or_pad(image, target_height, target_width)
# 图像数据增强
image = tf.image.random_flip_left_right(image)上述代码先是读取图像文件并进行解码,然后依次进行归一化、裁剪以及数据增强等操作,这样可以让图像数据在输入模型前达到更好的状态,有助于提升模型的训练效果和泛化能力。
同时,从更宏观的数据预处理角度来看,完整的步骤一般如下:
(一)导入必要的库
首先要导入所需的库,这包括 TensorFlow 库以及其他一些辅助进行数据处理的库,示例代码如下:
import tensorflow as tf
import numpy as np
from sklearn.preprocessing import StandardScaler(二)准备数据
准备数据是预处理的基础,我们可以利用一些现有的示例数据集,例如 sklearn 自带的波士顿房价数据集,代码如下:
from sklearn.datasets import load_boston
boston = load_boston()
X = boston.data
y = boston.target(三)数据清洗
数据清洗环节主要是处理数据中的缺失值、异常值等情况,不过在本示例中,我们假设数据已经是干净的,无需进行这一步骤的实际操作。
(四)特征缩放
特征缩放的目的是将特征值缩放到合适的范围,让模型能够更容易学习。这里我们采用 StandardScaler 来对特征进行缩放,代码如下:
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)(五)特征工程
特征工程指的是依据已有的特征去创建新的特征,以此来提高模型的性能,在当前示例中我们暂不进行这一步操作。
(六)划分数据集
最后,为了后续进行模型训练和评估,需要将数据集划分为训练集和测试集,代码如下:
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.2, random_state=42)通过上述完整的步骤,就完成了 TensorFlow 中的数据预处理过程,不过在实际的应用场景中,数据预处理往往需要根据具体的业务需求和数据特点进行灵活调整与优化。
三、数据转换
在深度学习模型训练流程里,通常需要将各类数据转换成 TensorFlow 的张量形式才能进行后续处理。在 TensorFlow 中,我们可以使用 tf.convert_to_tensor() 函数来轻松实现数据转换,以下分别展示将列表和 NumPy 数组转换成张量的示例代码:
import tensorflow as tf
# 将列表转换成张量
data_list = [1, 2, 3, 4, 5]
data_tensor = tf.convert_to_tensor(data_list)
# 将NumPy数组转换成张量
import numpy as np
data_np = np.array([1, 2, 3, 4, 5])
data_tensor = tf.convert_to_tensor(data_np)总之,上述介绍的这些 TensorFlow 中常用的数据操作,包括数据加载、预处理以及转换等内容,是我们在利用 TensorFlow 进行深度学习项目开发时经常会用到的。希望通过本文的教程,能帮助大家更好地掌握这些操作,进而更高效地利用 TensorFlow 的强大功能来处理数据并训练出优秀的深度学习模型。
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2024-12-07,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号