分库分表情况下通过batch模式进一步提高读写性能

分库分表情况下通过batch模式进一步提高读写性能

用户9048088
发布于 2026-06-15 19:59:26
发布于 2026-06-15 19:59:26
分库分表情况下通过batch模式进一步提高读写性能
- 前言
- 一、基于batch方式做业务改造
- 二、针对batch模式优化索引设计
- 总结
前言
提示:本文主要介绍最近做的数据库优化,并整理成文档记录一下
之前做的数据库分库分表优化已经在线上环境跑了一年了,数据库性能指标很稳定,但是在近期由于业务需要,往数据里写入了更多的数据。从请求上看,整体数据库DML的throughput大量增加,差不多是翻了8倍,数据库集群CPU最高到90%,亟需解决。在经历了长达3个月的技术优化后,数据库集群指标终于回归正常。我们采取了batch模式,通过批量的方式提高数据库链接的使用率,降低了吞吐量,这涉及到业务改造。另外,在数据库存储引擎层面,针对batch模式,我们优化了索引设计,使得更适合用于批量写入。本文就对所做的技术优化进行总结。
一、基于batch方式做业务改造
业务数据库的优化,需要格外注意对业务的影响。但是现在出于数据库成本的压力,需要改造瓶颈业务的方式来达到降本的目的,这是不得不采取的方式。主要改造的点涉及用户在app端相关模块查询数据列表统一用批量查询,删除/更新数据通过task模式统一交由异步批量的任务执行器中执行。 异步批量任务执行器是我们针对业务设计的将单次读写场景改造成批量读写场景的抽象封装,接入时不需要关心其具体实现逻辑,只需要实现提交后的批量读写逻辑和成功/失败后的处理回调即可。其实现大致如下:
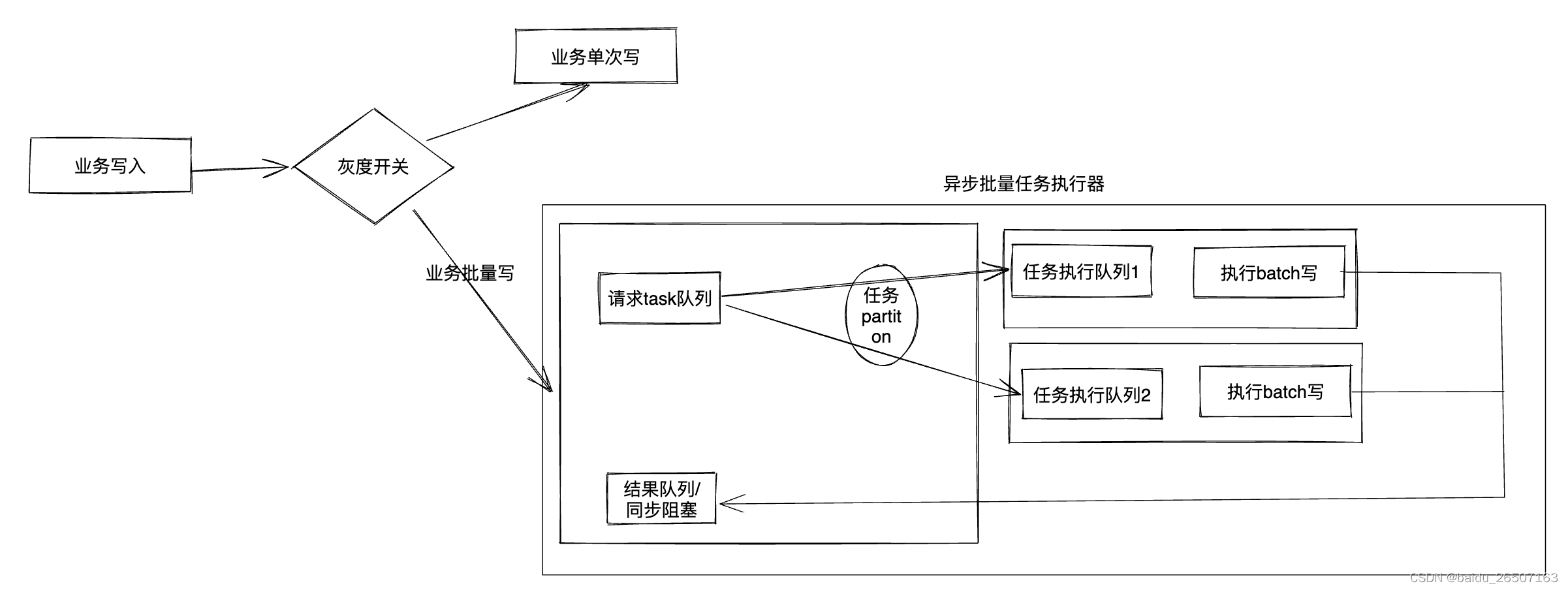
项目中使用的任务队列是kafka,任务执行器基于spring batch
为了更高的性能,基于kafka做了任务的reblance,使得同一个分表的读写都路由到一个partition中。实现方式比较简单,通过hash和分表总数和消息队列partition总数进行取mod即可。
int partiton=(id.hashCode() & Integer.MAX_VALUE)%tableCount%partitionCount具体设计可以参考demo项目kafka-rebalancer。
Tips:如果是批量insert的sql,不适合直接做sql的手动拼接(会导致sql很长,增加数据库预编译prepare statement的耗时进而导致性能下降),更合适的方式是利用数据库batch模式。例如:
SqlSession session = sqlSessionFactory.openSession(ExecutorType.BATCH, TransactionIsolationLevel.READ_COMMITTED);
try {
List insertItemList = ...;
insertItemList.forEach(insertItem -> {
itemDao.insert(insertItem); // INSERT INTO xxx VALUES (?, ?, ...);
});
session.commit();
session.clearCache();
} catch (Exception e) {
log.error("failed write to database", e);
session.rollback();
} finally {
session.close();
}为了尽可能降低对业务的影响,我们设计了灰度模式。处于灰度中的用户会通过batch模式进行数据读写,灰度外的用户则正常单次读写。
二、针对batch模式优化索引设计
由于批量读写往往本身就是一个大事务,数据库为了保证事务的AICD特性,需要对关联的所有数据申请lock(不是同时申请,而是执行到哪条语句申请哪个lock,但是整个事物没有提交前不会释放之前申请的lock),这就导致事务占有锁的粒度很大。如果存在并发访问相近的数据行,则容易产生死锁。死锁会严重降低数据库处理能力,因此需要针对batch模式的读写做优化。我们采取的方式如下:
- 数据库主键使用ulid,既避免了自增id在批量写入时的竞争性能损耗,又能避免uuid(varchar)的无序性,可以保持良好的聚簇索引结构
- 将非交易支付相关表的唯一索引(unique key)去掉,交由业务层通过分布式锁的方式控制数据的唯一性。实际业务场景中,大部分情况都不需要严格保证数据唯一,可以在后续查询时通过group by去重。去掉唯一索引后,减少了Duplicate Key校验,进一步提高了写入速度。另外使用READ COMMITED事务隔离级别通常比READ REPEATED产生的锁粒度更低,后者采用了GAP 锁来避免幻读。但是在MVCC机制下,RC比RR占用更多的数据库资源。
总结
数据库优化是门技术活,在了解了业务后,是保证业务不受影响重要,还是采取稍微激进的方式尽可能降低对业务的影响,需要进行权衡。关键还是看money该花在哪里。
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2023-08-15,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号