手把手教你用Neo4j+Python+Claude,3小时搞定一个供应链知识图谱

手把手教你用Neo4j+Python+Claude,3小时搞定一个供应链知识图谱

老周聊架构
发布于 2026-06-12 18:31:43
发布于 2026-06-12 18:31:43
上一篇文章讲了本体论和知识图谱的理论。你可能会说:"道理我都懂,代码呢?"——好,这篇给你代码。
知识图谱的教程满天飞,但大多数存在三个问题:
- 只讲概念不写代码——讲完RDF、OWL、SPARQL,读者一行代码没跑过
- 用的数据太假——"张三认识李四,李四认识王五",这种玩具数据建的图谱有什么用?
- 忽略最难的环节——知识融合和质量校验一笔带过,但这恰恰是生产环境里最要命的
今天这篇文章,我们用一个真实的业务场景——供应链知识图谱,走完全流程:
1 数据源梳理 → 本体设计 → 知识抽取 → 知识融合 → 图谱存储 → 查询应用技术栈:Neo4j 5.x + Python 3.12 + Claude API + Protégé
代码全部可运行,文末有完整GitHub仓库链接。
一、业务场景:为什么供应链需要知识图谱?
先说一个真实的痛点。
某制造企业,有3000+供应商、1200+零部件、50+工厂。采购部门每天要回答这样的问题:
- "芯片X的二级供应商是谁?如果台积电停产,影响哪些产品线?"
- "供应商A的信用评级降到了C,它供应的零部件有替代供应商吗?"
- "从原材料到成品,最长的供应链路径有几跳?瓶颈在哪里?"
用传统关系型数据库回答这些问题,需要多表JOIN到怀疑人生。4跳关联查询在MySQL上跑30秒,在Neo4j上跑30毫秒——差了1000倍。

MySQL多表JOIN 30秒 | Neo4j图遍历 30毫秒 | 性能差距 1000倍
二、第一步:用Protégé设计本体(30分钟)
不要急着写代码,先把本体设计好。
打开Protégé,创建一个新本体,命名空间设为http://example.org/supply-chain#。
2.1 定义核心概念(Class)
1 Thing
2 ├── Organization
3 │ ├── Supplier # 供应商
4 │ ├── Manufacturer # 制造商
5 │ └── Distributor # 分销商
6 ├── Product
7 │ ├── RawMaterial # 原材料
8 │ ├── Component # 零部件
9 │ └── FinishedGoods # 成品
10 ├── Location
11 │ ├── Factory # 工厂
12 │ ├── Warehouse # 仓库
13 │ └── Port # 港口
14 └── Risk # 风险事件
15 ├── NaturalDisaster # 自然灾害
16 ├── PolicyChange # 政策变动
17 └── QualityIssue # 质量问题2.2 定义关系(Object Property)
关系 | 定义域 | 值域 | 说明 |
|---|---|---|---|
suppliesTo | Supplier | Organization | 供应给 |
produces | Organization | Product | 生产 |
hasComponent | Product | Product | 包含组件 |
locatedIn | Organization | Location | 位于 |
affectedBy | Organization | Risk | 受影响于 |
alternativeSupplier | Supplier | Supplier | 替代供应商 |
2.3 定义属性约束
在Protégé里设置以下约束:
- 每个
Product至少有一个suppliedBy关系(owl:minCardinality 1) Supplier和Manufacturer互不相交(owl:disjointWith)——一个组织不能既是供应商又是制造商(在本体层面,如果实际上某公司两者都是,则创建两个实例或使用更灵活的建模)hasComponent关系是传递性的(owl:TransitiveProperty)——如果A包含B,B包含C,那么A也间接包含C
在Protégé里点"Start Reasoner"运行HermiT推理引擎,确认没有一致性错误。
导出为OWL/XML格式,保存为supply-chain-ontology.owl。

三、第二步:搭建Neo4j环境(10分钟)
3.1 Docker一键启动
1 docker run -d \
2 --name neo4j-kg \
3 -p 7474:7474 \
4 -p 7687:7687 \
5 -e NEO4J_AUTH=neo4j/your_password_here \
6 -e NEO4J_PLUGINS='["apoc","graph-data-science"]' \
7 -v neo4j_data:/data \
8 neo4j:5.26-community打开浏览器访问http://localhost:7474,用neo4j/your_password_here登录。
3.2 创建约束和索引
1 // 唯一性约束——防止重复节点
2 CREATE CONSTRAINT supplier_name IF NOT EXISTS
3 FOR (s:Supplier) REQUIRE s.name IS UNIQUE;
4
5 CREATE CONSTRAINT manufacturer_name IF NOT EXISTS
6 FOR (m:Manufacturer) REQUIRE m.name IS UNIQUE;
7
8 CREATE CONSTRAINT product_sku IF NOT EXISTS
9 FOR (p:Product) REQUIRE p.sku IS UNIQUE;
10
11 // 全文索引——支持模糊搜索
12 CREATE FULLTEXT INDEX entity_name IF NOT EXISTS
13 FOR (n:Supplier|Manufacturer|Product) ON EACH [n.name, n.alias];这一步非常重要。 没有唯一性约束,后面知识融合的时候会产生大量重复节点,清理起来比建图还累。
四、第三步:知识抽取——用Claude从非结构化数据中挖三元组(60分钟)
4.1 结构化数据直接导入
结构化数据最简单,直接从CSV导入:
import csv
from neo4j import GraphDatabase
driver = GraphDatabase.driver(
"bolt://localhost:7687",
auth=("neo4j", "your_password_here")
)
def load_suppliers(csv_path):
"""从CSV导入供应商数据"""
with open(csv_path) as f:
reader = csv.DictReader(f)
with driver.session() as session:
for row in reader:
session.run("""
MERGE (s:Supplier {name: $name})
SET s.creditRating = $rating,
s.country = $country,
s.leadTime = toInteger($lead_time),
s.annualRevenue = toFloat($revenue)
""", {
"name": row["supplier_name"],
"rating": row["credit_rating"],
"country": row["country"],
"lead_time": row["lead_time_days"],
"revenue": row["annual_revenue"]
})
def load_supply_relations(csv_path):
"""从CSV导入供应关系"""
with open(csv_path) as f:
reader = csv.DictReader(f)
with driver.session() as session:
for row in reader:
session.run("""
MATCH (s:Supplier {name: $supplier})
MATCH (m:Manufacturer {name: $manufacturer})
MERGE (s)-[r:SUPPLIES_TO]->(m)
SET r.product = $product,
r.contractStart = date($start),
r.contractEnd = date($end)
""", {
"supplier": row["supplier"],
"manufacturer": row["manufacturer"],
"product": row["product"],
"start": row["contract_start"],
"end": row["contract_end"]
})
4.2 非结构化数据用Claude抽取
这是最有意思的部分。我们用Claude的Function Calling能力,从供应链新闻、合同文本中抽取三元组。
import anthropic
import json
client = anthropic.Anthropic()
# 定义抽取的结构化输出格式
EXTRACTION_TOOLS = [{
"name": "extract_supply_chain_knowledge",
"description": "从文本中抽取供应链相关的实体和关系",
"input_schema": {
"type": "object",
"properties": {
"entities": {
"type": "array",
"items": {
"type": "object",
"properties": {
"name": {"type": "string"},
"type": {
"type": "string",
"enum": ["Supplier", "Manufacturer",
"Product", "Location", "Risk"]
},
"attributes": {"type": "object"}
},
"required": ["name", "type"]
}
},
"relations": {
"type": "array",
"items": {
"type": "object",
"properties": {
"source": {"type": "string"},
"target": {"type": "string"},
"relation": {
"type": "string",
"enum": ["SUPPLIES_TO", "PRODUCES",
"HAS_COMPONENT", "LOCATED_IN",
"AFFECTED_BY", "ALTERNATIVE_FOR"]
},
"attributes": {"type": "object"}
},
"required": ["source", "target", "relation"]
}
}
},
"required": ["entities", "relations"]
}
}]
SYSTEM_PROMPT = """你是一个供应链知识抽取专家。
从给定的文本中抽取供应链相关的实体(供应商、制造商、产品、位置、风险)
和关系(供应给、生产、包含组件、位于、受影响于、替代供应商)。
规则:
1. 实体名称使用官方全称,附带常用简称作为alias属性
2. 只抽取文本中明确提到的关系,不要推测
3. 时间、数量等信息放在关系的attributes中
4. 如果实体类型不确定,选择最合理的类型"""
def extract_knowledge(text):
"""用Claude从文本中抽取三元组"""
response = client.messages.create(
model="claude-sonnet-4-6", # 抽取任务用Sonnet够了
max_tokens=4096,
system=SYSTEM_PROMPT,
tools=EXTRACTION_TOOLS,
messages=[{
"role": "user",
"content": f"请从以下文本中抽取供应链知识:\n\n{text}"
}]
)
for block in response.content:
if block.type == "tool_use":
return json.loads(json.dumps(block.input))
return None
# 示例:从新闻中抽取
news = """
路透社2026年5月报道:由于日本九州地区发生6.2级地震,
瑞萨电子(Renesas Electronics)位于熊本县的300mm晶圆厂
被迫停产至少两周。该工厂主要生产车规级MCU芯片,
是丰田汽车、本田汽车和博世(Bosch)的核心供应商。
行业分析师指出,意法半导体(STMicroelectronics)和
德州仪器(Texas Instruments)有望成为短期替代供应商。
"""
result = extract_knowledge(news)
print(json.dumps(result, indent=2, ensure_ascii=False))
Claude会返回这样的结构化结果:
{
"entities": [
{"name": "瑞萨电子", "type": "Supplier",
"attributes": {"alias": "Renesas Electronics", "country": "日本"}},
{"name": "丰田汽车", "type": "Manufacturer",
"attributes": {"alias": "Toyota"}},
{"name": "本田汽车", "type": "Manufacturer",
"attributes": {"alias": "Honda"}},
{"name": "博世", "type": "Manufacturer",
"attributes": {"alias": "Bosch", "country": "德国"}},
{"name": "车规级MCU芯片", "type": "Product", "attributes": {}},
{"name": "熊本县晶圆厂", "type": "Location",
"attributes": {"type": "Factory", "waferSize": "300mm"}},
{"name": "九州地震", "type": "Risk",
"attributes": {"type": "NaturalDisaster", "magnitude": 6.2,
"date": "2026-05"}},
{"name": "意法半导体", "type": "Supplier",
"attributes": {"alias": "STMicroelectronics"}},
{"name": "德州仪器", "type": "Supplier",
"attributes": {"alias": "Texas Instruments"}}
],
"relations": [
{"source": "瑞萨电子", "target": "丰田汽车",
"relation": "SUPPLIES_TO", "attributes": {"product": "车规级MCU芯片"}},
{"source": "瑞萨电子", "target": "本田汽车",
"relation": "SUPPLIES_TO", "attributes": {"product": "车规级MCU芯片"}},
{"source": "瑞萨电子", "target": "博世",
"relation": "SUPPLIES_TO", "attributes": {"product": "车规级MCU芯片"}},
{"source": "瑞萨电子", "target": "熊本县晶圆厂",
"relation": "LOCATED_IN", "attributes": {}},
{"source": "瑞萨电子", "target": "九州地震",
"relation": "AFFECTED_BY",
"attributes": {"impact": "停产至少两周"}},
{"source": "意法半导体", "target": "瑞萨电子",
"relation": "ALTERNATIVE_FOR", "attributes": {"timeframe": "短期"}},
{"source": "德州仪器", "target": "瑞萨电子",
"relation": "ALTERNATIVE_FOR", "attributes": {"timeframe": "短期"}}
]
}
看到了吗?一段非结构化的新闻文本,被Claude精确地拆解成了9个实体和7个关系。 这在3年前需要一个NLP团队搞半年的事情,现在一个API调用搞定。
4.3 将抽取结果写入Neo4j
def write_knowledge_to_neo4j(knowledge, session):
"""将抽取的知识写入Neo4j"""
# 写入实体
for entity in knowledge["entities"]:
label = entity["type"]
props = {"name": entity["name"]}
props.update(entity.get("attributes", {}))
# 动态构建SET子句
set_clauses = ", ".join(
f"n.{k} = ${k}" for k in props if k != "name"
)
set_part = f"SET {set_clauses}" if set_clauses else ""
session.run(
f"MERGE (n:{label} {{name: $name}}) {set_part}",
props
)
# 写入关系
for rel in knowledge["relations"]:
attrs = rel.get("attributes", {})
set_clauses = ", ".join(
f"r.{k} = ${k}" for k in attrs
)
set_part = f"SET {set_clauses}" if set_clauses else ""
session.run(f"""
MATCH (a {{name: $source}})
MATCH (b {{name: $target}})
MERGE (a)-[r:{rel['relation']}]->(b)
{set_part}
""", {"source": rel["source"],
"target": rel["target"], **attrs})
五、第四步:知识融合——最脏最累但最关键(60分钟)
5.1 实体对齐:把"同一个东西"合并
从不同数据源抽取的同一实体,名称可能不一样。我们用三层策略来对齐:
from neo4j import GraphDatabase
import anthropic
client = anthropic.Anthropic()
driver = GraphDatabase.driver(
"bolt://localhost:7687",
auth=("neo4j", "your_password_here")
)
def find_similar_entities(session):
"""用APOC找名称相似的实体对"""
result = session.run("""
MATCH (a), (b)
WHERE id(a) < id(b)
AND labels(a) = labels(b)
AND apoc.text.jaroWinklerDistance(a.name, b.name) > 0.85
RETURN a.name AS name1, b.name AS name2,
labels(a)[0] AS label,
apoc.text.jaroWinklerDistance(a.name, b.name) AS similarity
ORDER BY similarity DESC
LIMIT 50
""")
return [dict(r) for r in result]
def llm_verify_alignment(entity_pairs):
"""用Claude验证实体是否是同一个"""
prompt = "以下是一些可能指向同一实体的名称对。\n"
prompt += "请判断每一对是否是同一个实体,返回JSON数组。\n\n"
for pair in entity_pairs:
prompt += (f"- \"{pair['name1']}\" vs \"{pair['name2']}\" "
f"(类型: {pair['label']})\n")
response = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=2048,
messages=[{"role": "user", "content": prompt}]
)
return response.content[0].text
def merge_entities(session, name_keep, name_remove):
"""合并两个实体节点,保留第一个,删除第二个"""
session.run("""
MATCH (keep {name: $keep})
MATCH (remove {name: $remove})
// 迁移所有入边
CALL {
WITH keep, remove
MATCH (remove)<-[r]-()
WITH keep, remove, collect(r) AS rels
UNWIND rels AS r
WITH keep, startNode(r) AS other, type(r) AS relType,
properties(r) AS props
CALL apoc.create.relationship(other, relType, props, keep)
YIELD rel
RETURN count(rel) AS inMoved
}
// 迁移所有出边
CALL {
WITH keep, remove
MATCH (remove)-[r]->()
WITH keep, remove, collect(r) AS rels
UNWIND rels AS r
WITH keep, endNode(r) AS other, type(r) AS relType,
properties(r) AS props
CALL apoc.create.relationship(keep, relType, props, other)
YIELD rel
RETURN count(rel) AS outMoved
}
// 将被合并实体的名称作为别名保留
SET keep.alias = CASE
WHEN keep.alias IS NULL THEN remove.name
ELSE keep.alias + ',' + remove.name
END
DETACH DELETE remove
""", {"keep": name_keep, "remove": name_remove})
5.2 融合质量校验
融合完了不是结束,还得校验质量:
def run_quality_checks(session):
"""运行一系列质量检查"""
checks = {
"孤立节点(没有任何关系的实体)": """
MATCH (n) WHERE NOT (n)--() RETURN count(n) AS count
""",
"自环关系(自己指向自己)": """
MATCH (n)-[r]->(n) RETURN count(r) AS count
""",
"重复关系": """
MATCH (a)-[r1]->(b), (a)-[r2]->(b)
WHERE id(r1) < id(r2) AND type(r1) = type(r2)
RETURN count(r1) AS count
""",
"缺少关键属性的供应商": """
MATCH (s:Supplier)
WHERE s.creditRating IS NULL
OR s.country IS NULL
RETURN count(s) AS count
""",
"没有供应商的产品": """
MATCH (p:Product)
WHERE NOT ()-[:SUPPLIES_TO]->()-[:PRODUCES]->(p)
AND NOT ()-[:SUPPLIES_TO {product: p.name}]->()
RETURN count(p) AS count
"""
}
print("=" * 60)
print("知识图谱质量报告")
print("=" * 60)
for name, query in checks.items():
result = session.run(query).single()
count = result["count"]
status = "✓ PASS" if count == 0 else f"✗ WARN ({count})"
print(f" {status} {name}")
print("=" * 60)运行结果类似:
1 ============================================================
2 知识图谱质量报告
3 ============================================================
4 ✗ WARN (12) 孤立节点(没有任何关系的实体)
5 ✓ PASS 自环关系(自己指向自己)
6 ✗ WARN (3) 重复关系
7 ✗ WARN (8) 缺少关键属性的供应商
8 ✓ PASS 没有供应商的产品
9 ============================================================看到WARN了吗?这就是知识融合里最常见的问题。 12个孤立节点大概率是抽取出来但没有建立关系的实体,需要手动检查或补充数据源。
六、第五步:图谱查询与应用(30分钟)
图谱建好了,来回答开头提出的那些业务问题。
6.1 供应链影响分析——"如果台积电停产,影响谁?"
// 查询某供应商停产的影响扩散范围(3跳以内)
MATCH path = (risk:Risk)-[:AFFECTED_BY*0..1]-(supplier:Supplier)
-[:SUPPLIES_TO*1..3]->(affected)
WHERE supplier.name = "瑞萨电子"
RETURN path
// 更精确的版本:返回所有受影响的制造商和产品
MATCH (s:Supplier {name: "瑞萨电子"})-[:SUPPLIES_TO]->(m:Manufacturer)
OPTIONAL MATCH (m)-[:PRODUCES]->(p:Product)
RETURN m.name AS affected_manufacturer,
collect(DISTINCT p.name) AS affected_products,
s.creditRating AS supplier_rating
ORDER BY m.name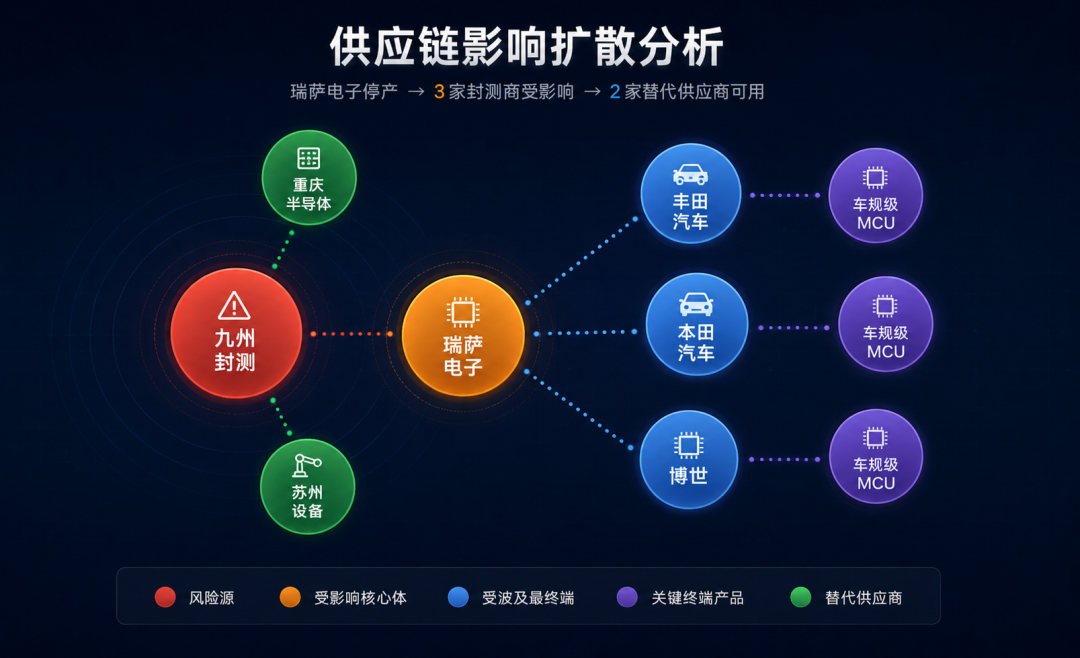
6.2 替代供应商查找——"有替代方案吗?"
// 查找某供应商的替代方案
MATCH (original:Supplier {name: "瑞萨电子"})
-[:SUPPLIES_TO]->(customer:Manufacturer)
MATCH (alt:Supplier)-[:ALTERNATIVE_FOR]->(original)
WHERE alt.creditRating IN ["A", "B"] // 只要信用好的
RETURN customer.name AS affected_customer,
alt.name AS alternative_supplier,
alt.creditRating AS rating,
alt.leadTime AS lead_time_days
ORDER BY alt.creditRating, alt.leadTime6.3 供应链路径分析——"最长供应链有多长?"
// 查找最长的供应链路径
MATCH path = (start)-[:SUPPLIES_TO|PRODUCES|HAS_COMPONENT*]->(end)
WHERE NOT ()-[:SUPPLIES_TO|PRODUCES|HAS_COMPONENT]->(start) // 起点
AND NOT (end)-[:SUPPLIES_TO|PRODUCES|HAS_COMPONENT]->() // 终点
RETURN [n IN nodes(path) | n.name] AS supply_chain,
length(path) AS depth
ORDER BY depth DESC
LIMIT 106.4 接入大模型——GraphRAG问答
最后一步,把知识图谱接入大模型,实现自然语言问答:
import json
import anthropic
from neo4j import GraphDatabase
client = anthropic.Anthropic()
driver = GraphDatabase.driver(
"bolt://localhost:7687",
auth=("neo4j", "your_password_here")
)
def graph_rag_query(user_question):
"""基于知识图谱的RAG问答"""
# Step 1: 用Claude将自然语言转为Cypher查询
cypher_response = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=1024,
system="""你是一个Cypher查询生成专家。
根据用户的自然语言问题,生成Neo4j Cypher查询语句。
图谱Schema:
- 节点: Supplier, Manufacturer, Product, Location, Risk
- 关系: SUPPLIES_TO, PRODUCES, HAS_COMPONENT, LOCATED_IN,
AFFECTED_BY, ALTERNATIVE_FOR
- 供应商属性: name, creditRating, country, leadTime
- 产品属性: name, sku, category
只返回Cypher语句,不要解释。""",
messages=[{
"role": "user",
"content": user_question
}]
)
cypher = cypher_response.content[0].text.strip()
# 去掉大模型返回中可能包含的代码围栏标记
fence = chr(96) * 3
cypher = cypher.replace(fence + "cypher", "").replace(fence, "").strip()
# Step 2: 执行Cypher查询
with driver.session() as session:
try:
result = session.run(cypher)
records = [dict(r) for r in result]
except Exception as e:
records = [{"error": str(e)}]
# Step 3: 用Claude基于查询结果生成自然语言回答
answer_response = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=2048,
system="基于知识图谱的查询结果,用中文回答用户的问题。"
"如果结果为空,说明图谱中没有相关数据。",
messages=[{
"role": "user",
"content": (f"用户问题:{user_question}\n\n"
f"Cypher查询:{cypher}\n\n"
f"查询结果:{json.dumps(records, ensure_ascii=False)}")
}]
)
return {
"question": user_question,
"cypher": cypher,
"raw_results": records,
"answer": answer_response.content[0].text
}
# 测试
result = graph_rag_query("瑞萨电子停产会影响哪些汽车制造商?有替代供应商吗?")
print(f"问题:{result['question']}")
print(f"Cypher:{result['cypher']}")
print(f"回答:{result['answer']}")
输出示例:
问题:瑞萨电子停产会影响哪些汽车制造商?有替代供应商吗?
Cypher:
MATCH (s:Supplier {name: "瑞萨电子"})-[:SUPPLIES_TO]->(m:Manufacturer)
OPTIONAL MATCH (alt:Supplier)-[:ALTERNATIVE_FOR]->(s)
RETURN m.name AS affected, collect(DISTINCT alt.name) AS alternatives
回答:根据知识图谱数据,瑞萨电子停产将直接影响以下汽车制造商:
1. 丰田汽车
2. 本田汽车
3. 博世(Bosch,虽然博世是零部件供应商,但它也从瑞萨采购MCU芯片)
目前图谱中记录的替代供应商有:
- 意法半导体(STMicroelectronics)——短期替代
- 德州仪器(Texas Instruments)——短期替代
建议关注这两家替代供应商的产能和交付周期,确认能否满足需求。
这就是知识图谱+大模型的威力:用户用自然语言问问题,系统自动查图谱,再生成人类可读的回答。 既有大模型的灵活性,又有知识图谱的准确性——鱼和熊掌兼得。
七、完整架构回顾
把所有环节串起来,完整架构如下:
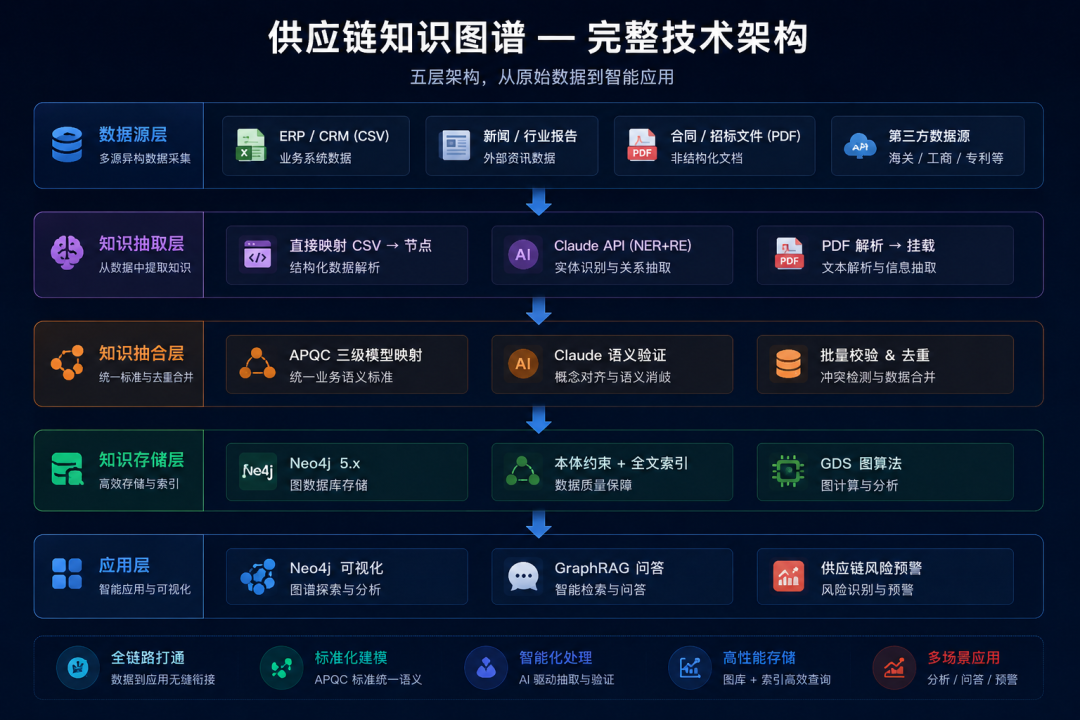
完整架构如上图所示:从数据源到最终应用,共五个层次。
八、踩坑总结:五个血泪教训
坑 | 症状 | 解决方案 |
|---|---|---|
没建唯一性约束就导数据 | 同一个实体出现几十个重复节点 | 先建约束再导数据,用MERGE不用CREATE |
本体设计过度 | 概念层次搞了7层,80%的叶子节点没有实例 | 从Top 20问题反推,够用就好 |
忽略知识融合 | 图谱里"台积电"和"TSMC"各有一套关系 | 三层策略:字符串相似度→属性对比→LLM验证 |
Cypher写得太暴力 | MATCH (a)-[*]->(b)导致全图遍历,OOM | 限制跳数[*1..3],加WHERE条件剪枝 |
只建图不维护 | 数据3个月没更新,供应商信息全过时 | 建立增量更新管道,定期跑质量检查 |
写在最后
知识图谱不是一个"建完就完"的项目,它是一个需要持续运营的数据资产。
建图谱3小时,维护图谱3年。但一旦建好了,它就是你企业的"数字神经系统"——每一个新数据点进来,整个网络都会做出反应。
来回顾一下我们今天用到的技术栈和工时分布:
环节 | 工具 | 耗时 | 难度 |
|---|---|---|---|
本体设计 | Protégé | 30分钟 | ★★★ |
环境搭建 | Docker + Neo4j | 10分钟 | ★ |
结构化数据导入 | Python + neo4j-driver | 20分钟 | ★ |
非结构化数据抽取 | Claude API | 40分钟 | ★★ |
知识融合 | APOC + Claude | 60分钟 | ★★★★ |
查询与应用 | Cypher + GraphRAG | 30分钟 | ★★ |
总计 | 约3小时 |
知识融合占了总工时的三分之一,这不是偶然——这是所有知识图谱项目的规律。
如果你的企业正在考虑上知识图谱,我的建议是:
- 先用Protégé把本体设计清楚,跟业务方对齐概念和关系
- 从结构化数据开始,先把80%的核心实体和关系导进去
- 用大模型补充非结构化数据,但一定要做好融合和质量校验
- 选一个具体的业务问题验证价值——不要做"大而全"的知识图谱
知识图谱的最大敌人不是技术难度,而是"什么都想放进去"的冲动。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-08,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号