为什么AI生成的单测,覆盖率看起来很高但上线还是出Bug?


我们团队的单测覆盖率曾经在28%的位置卡了将近两年。
不是没想过治,是治不了——写单测的时间成本太高,上线压力又在那,没人有余裕专门去补。后来引入AI工具,两个月内覆盖率涨到了82%,看起来是个成功故事。
但上线后的第三周,一个边界分支的Bug溜过去了。排查下来,那段代码的覆盖率是100%。
这才开始认真审视AI生成的那些测试:覆盖率数字漂亮,Mock了一堆,断言写得很满,但实际上测的是一个被完全隔离的代理方法,根本没有触到真实逻辑。
这是当时用AI生成单测时踩到最深的坑,也是这篇文章要说的核心问题。
AI生成单测的工具链:今天能落地的三条路
先说工具。市面上专注于单测生成的AI工具已经不少,但真正能进工程流水线的,目前稳定好用的主要是三条路:
Claude Code(命令行Agent)
Claude Code可以以整个代码目录为上下文,批量扫描未覆盖的方法并生成测试。命令行调用,适合集成进CI流程。最大的优势是上下文窗口大,能理解跨文件的依赖关系,生成的测试Mock策略相对合理。
典型用法:
# 针对指定文件批量生成测试
claude -p "为 src/main/java/com/example/OrderService.java 中所有 public 方法生成 JUnit 5 单元测试,
使用 Mockito,遵循 AAA(Arrange-Act-Assert)结构,
边界条件包括:空值输入、数值溢出、空集合、异常路径。
生成到 src/test/java/com/example/OrderServiceTest.java"
Cursor(IDE内Agent)
在IDE里直接选中一个类或方法,用Chat模式让它生成测试。操作门槛最低,适合单个方法的测试补充。弱点是上下文有限,跨文件依赖容易理解错。
GitHub Copilot(/tests命令)
在VS Code或JetBrains里,打开目标文件后执行/tests命令,Copilot会扫描当前文件生成测试。支持指定框架和测试范围。2026年对.NET的支持做了专项增强,但Java和Go的体验也足够用。
对于Java项目,还有一个专项工具值得知道:Diffblue Cover。它基于强化学习,专门针对Java/JUnit生态做了深度优化,在内部测试中对企业级Java项目实测可将覆盖率提升50-70%,且生成的测试通过率接近100%。缺点是商业授权,小团队成本不低。
三条路的适用场景:
工具 | 适合场景 | 弱点 |
|---|---|---|
Claude Code | 批量生成、CI集成、跨文件依赖复杂 | 每次要写Prompt |
Cursor | 单文件、即时补充 | 跨文件上下文弱 |
Copilot /tests | 快速起步、框架集成 | 复杂业务逻辑理解不深 |
Diffblue Cover | 企业Java项目、追求极致通过率 | 商业授权,价格高 |
不管用哪个工具,接下来要说的三个坑都会踩到。

AI单测生成工具对比:四款主流工具的适用场景与能力矩阵
图:四款主流AI单测工具的能力对比——Claude Code批量生成首选,Cursor单文件最便捷,Diffblue Cover企业Java专项
覆盖率数字漂亮,但测试没有价值:三个典型坑
这是我花时间最多想搞清楚的问题。AI生成的单测,为什么覆盖率能做到很高,但线上Bug依然出现?
翻了一篇2025年发布在arXiv的实证研究(分析了来自2168个仓库的120万+次提交),结论让我意外:AI工具生成的测试中,mock的比例比人类高36% vs 26%,而且95%都是标准mock,几乎不用spy或fake。
这是一个结构性问题,不是某个工具的问题。
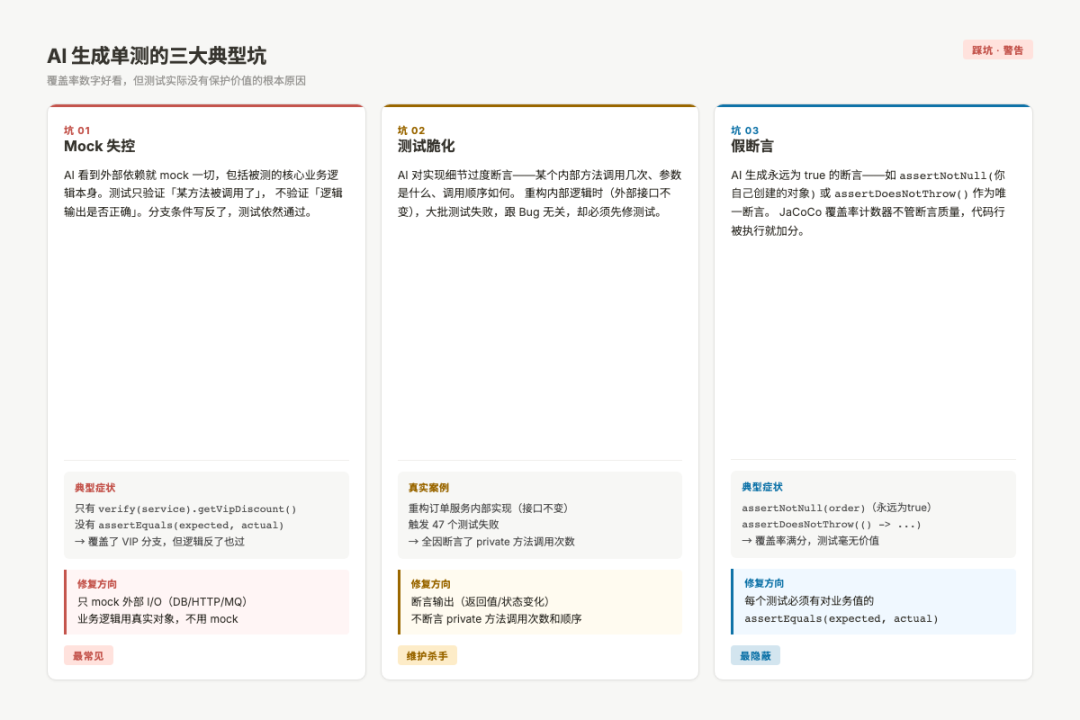
AI生成单测的三大典型坑:Mock失控、测试脆化、假断言
图:三个导致覆盖率好看但测试无价值的根本原因,以及对应的修复方向
坑一:Mock失控——测试的不是真实逻辑
AI看到一个有外部依赖的方法,第一反应就是mock所有依赖,然后验证方法是否调用了这些依赖。逻辑上没问题,但在某些情况下,被mock掉的恰恰是核心业务逻辑所在的地方。
来看一个真实的例子:
// 被测方法
public BigDecimal calculateDiscount(Order order, UserLevel userLevel) {
if (userLevel == UserLevel.VIP) {
return discountService.getVipDiscount(order);
}
return discountService.getRegularDiscount(order);
}
AI生成的测试可能长这样:
@Test
void calculateDiscount_VipUser_ShouldCallVipDiscount() {
// Arrange
Order order = mock(Order.class);
when(discountService.getVipDiscount(order)).thenReturn(new BigDecimal("0.8"));
// Act
BigDecimal result = priceService.calculateDiscount(order, UserLevel.VIP);
// Assert
verify(discountService).getVipDiscount(order); // ← 只验证了调用,没验证结果
assertEquals(new BigDecimal("0.8"), result);
}
这个测试覆盖了VIP分支,覆盖率计数器加分了。但它测的是"有没有调用getVipDiscount",而不是"折扣计算逻辑是否正确"。如果calculateDiscount里的分支条件写反了(把VIP走成了regular),这个测试照样通过。
解决方法:在Prompt里明确约束:
生成单测时:
1. 最多mock外部I/O(数据库、HTTP调用、消息队列)
2. 纯计算逻辑和条件分支,使用真实值而不是mock
3. Assert要验证返回值的内容,而不只是验证方法调用
4. 每个测试的assert至少要有一个assertEquals/assertThat对实际值的断言
坑二:测试脆化——实现改了,测试全红
AI在生成测试时倾向于对实现细节进行断言——某个内部方法是否被调用了几次、参数是什么、调用顺序是什么。
这在测试出错上线前的代码时很有用,但会带来一个维护噩梦:一旦内部实现重构,大量测试失败,跟Bug无关,但得先修测试才能继续。
这不是假设。我们重构一个订单服务的内部实现(外部接口不变),触发了47个测试失败,一个都不是因为逻辑错误,全是因为AI断言了某个private方法的调用次数。
解决方法:让测试断言行为而非实现:
约束:
- 断言的是方法的输出(返回值、状态变化、持久化结果)
- 不断言内部private方法是否被调用、被调用几次
- 不断言两个协作方法的调用顺序,除非顺序本身是业务约束
Go项目同样有这个问题,用gomock时尤其明显。gomock的使用率从2024年的12%飙升到2025年的21%,背后一部分原因就是AI生成测试时高度依赖mock——但过度使用之后,维护成本反噬得很快。
坑三:假断言——覆盖率100%,没有任何保护
这是最隐蔽的一个。AI有时会生成这样的测试:
@Test
void processOrder_NormalFlow_ShouldComplete() {
Order order = createTestOrder();
// Act
orderService.processOrder(order);
// Assert
assertNotNull(order); // ← 这断言了什么?
}
assertNotNull(order)永远为true——order是你自己创建的,不可能为null。但Jacoco的覆盖率计数器不管断言质量,它只看代码行有没有被执行到。结果是:覆盖率满分,测试毫无价值。
还有一种变体:
assertTrue(result != null); // 同上
assertDoesNotThrow(() -> service.doSomething(input)); // 只验证没抛异常,不验证结果
解决方法:Prompt里要求:
每个测试必须包含至少一个对业务语义有意义的断言,即:
- assertEquals(expectedValue, actualValue) 其中 expectedValue 是业务上正确的值
- 或 assertThat(result).satisfies(r -> ...) 包含业务约束的条件检查
- 禁止只写 assertNotNull、assertDoesNotThrow 作为唯一断言
从30%到80%的可复用工作流
讲完坑,说说怎么真的把覆盖率推上去。这套流程是我们跑通之后整理的,可以直接参考。
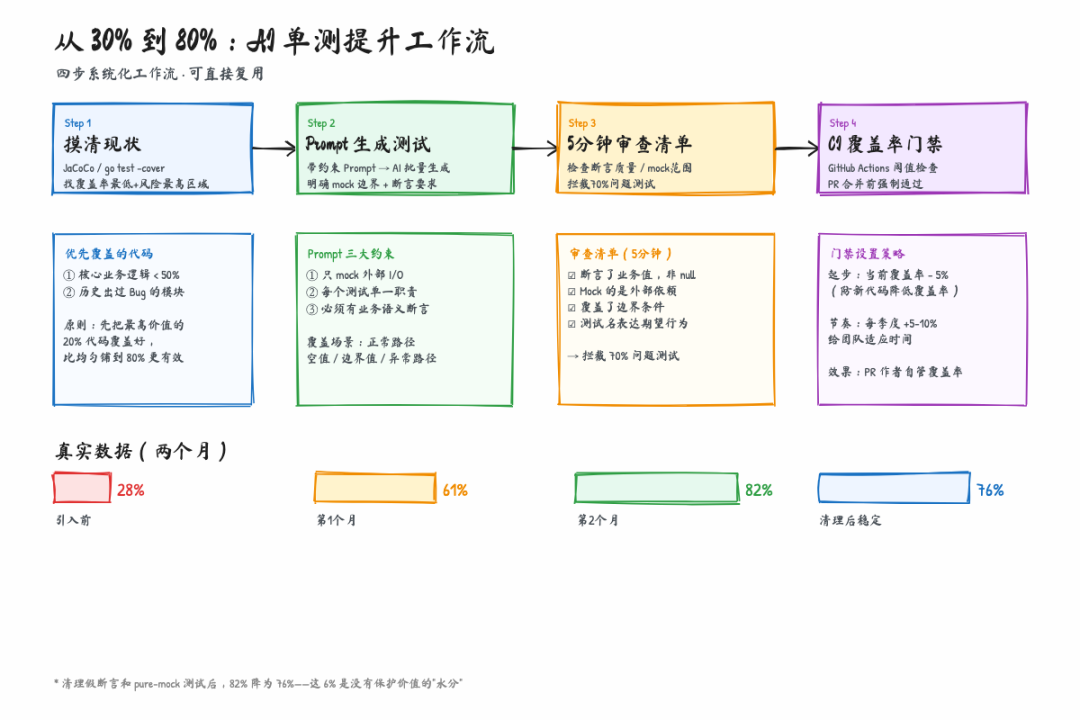
从30%到80%的AI单测提升工作流:四步系统化流程与真实数据
图:四步工作流全貌——从摸清现状到CI门禁,以及真实的覆盖率提升数据
第一步:摸清现状,确定目标区域
先用JaCoCo(Java)或go test -cover(Go)生成覆盖率报告,找到覆盖率最低、风险最高的区域。
# Java: 生成JaCoCo报告
mvn test jacoco:report
# 报告在 target/site/jacoco/index.html
# Go: 生成覆盖率报告
go test ./... -coverprofile=coverage.out
go tool cover -html=coverage.out -o coverage.html
重点关注两类区域:
- 核心业务逻辑覆盖率低于50%的类(风险最高)
- 曾经出过Bug的模块(历史告诉你这里容易出问题)
不要一开始就全量跑,先把最高价值的20%代码覆盖好,比均匀铺到80%更有实际价值。
第二步:用这个Prompt模板生成测试
这是我们反复调整之后的生产版本:
角色:你是一个有10年经验的Java/Go测试工程师。
任务:为以下方法生成完整的JUnit 5 + Mockito单元测试。
约束(严格遵守):
1. 只mock外部I/O依赖(Repository、HTTP Client、消息队列),纯业务逻辑使用真实对象
2. 每个@Test方法只验证一件事(单一职责)
3. 每个测试必须有对返回值或状态的业务语义断言,不能只断言assertNotNull或assertDoesNotThrow
4. 不断言private方法调用次数
5. 覆盖以下场景:正常路径、空值输入、边界值(0、最大值、最小值)、异常路径
6. 测试方法命名:methodName_condition_expectedBehavior(如:calculateDiscount_VipUser_ShouldReturnTenPercentOff)
待测代码:
[粘贴代码]
已有测试(参考风格,避免重复):
[粘贴现有测试文件或写"无"]
Go项目把JUnit 5改成testing包 + testify/assert,Mockito改成gomock或moq,其余约束不变。
第三步:审查生成的测试
AI生成之后,不要直接合进去。用这个清单快速过一遍:
- [ ] 所有
assert断言的是业务值,而不是assertNotNull或只验证方法调用 - [ ] Mock的对象是外部依赖,不是业务逻辑所在的service
- [ ] 边界条件(null、空集合、负数)至少覆盖了一个
- [ ] 测试名字能表达"什么情况下期望什么结果"
这个清单review一个类大概需要5分钟,但能拦住70%的问题测试。
第四步:CI集成,让覆盖率成为门禁
测试补上了,但如果不进CI,三个月后又会回到原点。
# .github/workflows/test-coverage.yml
name:TestCoverageGate
on:[pull_request]
jobs:
coverage:
runs-on:ubuntu-latest
steps:
-uses:actions/checkout@v4
-name:Runtestswithcoverage
run:mvntestjacoco:report
-name:Checkcoveragethreshold
run: |
COVERAGE=$(python3 -c "
import xml.etree.ElementTree as ET
tree = ET.parse('target/site/jacoco/jacoco.xml')
root = tree.getroot()
counter = root.find('.//counter[@type=\"LINE\"]')
covered = int(counter.get('covered'))
missed = int(counter.get('missed'))
print(f'{covered/(covered+missed)*100:.1f}')
")
echo "Coverage: $COVERAGE%"
python3 -c "assert float('$COVERAGE') >= 70, f'Coverage {$COVERAGE}% is below 70% threshold'"
门槛设置建议:不要一上来就设80%,先设成当前覆盖率减5%(比如现在30%,设25%),防止新代码降低覆盖率。每季度往上调5-10%,给团队适应时间。
这个门禁设立之后,我们团队PR合并前的覆盖率压力从"没有"变成了"每个PR作者自己管",三个月后整体覆盖率自然上了台阶。
真实数据:两个月的效果
分享一下我们的真实数字,不是为了炫,是为了给你一个参考锚点:
时间节点 | 覆盖率 | 备注 |
|---|---|---|
引入AI工具前 | 28% | 全靠手写,主要是老代码 |
第一个月末 | 61% | 主要靠Claude Code批量生成 |
第二个月末 | 82% | 清理假断言、补边界用例后 |
清理后稳定值 | 76% | 去掉无价值测试后的真实水位 |
注意最后一行:清理前是82%,清理掉假断言和pure-mock测试之后变成了76%。这6个点的差距,代表的是那些覆盖率贡献了数字但没有保护价值的测试。
76%的有效覆盖率,比82%的水分覆盖率实际上有价值得多。
另一个数据:用了Airwallex的思路(Claude Code Subagent多角色协作),他们做集成测试时把时间从2周压到了2小时,生成了4000+集成测试。这是多agent协作的路子,比单文件生成更系统。对于大型项目,这个方向值得研究。
常见问题
Q: 覆盖率应该定多少才合理?80%还是90%?
A: 看代码类型,不是一刀切。核心业务逻辑(订单、支付、权限)90%合理。工具类、配置类、DTO,50-60%就够了。统一要求所有代码80%以上,会逼人写大量低价值测试来凑数字,反而浪费时间。更好的做法是按包分层设定阈值。
Q: AI生成的测试,命名和编码风格跟我们团队不一致,每次都要手动改,麻烦吗?
A: Prompt里加"参考已有测试"这一项能解决80%的风格问题。给AI看几个你们团队的真实测试文件,它会自动学习命名约定、注释风格、断言偏好。剩下的20%用代码格式化工具(Checkstyle/golangci-lint)在CI里统一处理。
Q: 生成的测试跑不起来,报各种依赖注入错误,怎么办?
A: 这个最常见,通常是两个原因:一是Prompt里没有把测试上下文给清楚(Spring Boot项目要告诉AI这是Spring环境,需要加哪些注解);二是AI选错了Mock方式(有时会混用@Mock和@InjectMocks的层次)。解决方法:把报错直接粘给AI,让它修复,通常1-2轮能解决。Go项目还要注意interface层级,AI有时会mock错误的interface实现。
Q: 测试写完了,但维护成本很高,每次改代码测试就大批报红,怎么处理?
A: 这是前面说的"坑二"的典型症状——AI对实现细节过度断言。解决方案分两步:一是用本文的Prompt约束来约束新生成的测试;二是对存量的脆化测试,让AI帮你重构(把verify调用改成对结果的assertEquals,删掉对调用顺序的断言)。这个重构过程我们花了大约两天,之后维护成本降了很多。
总结
说到底,AI生成单测能解决的是"没有测试"的问题,解决不了"测试没有价值"的问题——后者需要你理解测试在保护什么。覆盖率从30%到80%确实不难,但从80%的数字到80%的真实保护,中间隔着那三个坑。
写完这篇码哥自己也回头看了一遍我们当时的测试,还有几个假断言没清。如果觉得这篇有用,点个「在看」帮我推一推。下一篇打算聊Claude Code在处理遗留系统重构时的具体用法,那才是真正麻烦的场景——感兴趣的关注一下。你身边有被覆盖率数字困扰的同事,这篇可以直接甩给他。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-09,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号