AI 替查询算命:LLM 报这行 SQL 要慢 10 倍,你敢跑吗?

AI 替查询算命:LLM 报这行 SQL 要慢 10 倍,你敢跑吗?

Jackeyzhe
发布于 2026-06-12 16:52:00
发布于 2026-06-12 16:52:00
上周组内实习生跑了一个 SQL 差点把 PG 拖死。领导跟我说:你来写一个“行数预估器”,跑 SQL 之前需要确认不会影响性能。
我心想:我哪会写这个啊?反手打开 Claude Code,告诉它,你来写一个"行数预估器",跑 SQL 之前需要确认不会影响性能。(没错,我直接把领导原话告诉它了。)
它给了我一篇论文(Bespoke-Card, arXiv:2606.09361),论文的核心是给"行数预估"这个活换个思路:按你的 workload 现场给你写一个专属的 estimation 函数(白盒、可 review、可调试,比 MSCN 黑盒神经网络强百倍)。看得我似懂非懂。我又 PUA 它,给你半个小时时间,帮我搞定这件事,你不干有的是 AI 愿意干。
一听这话,它立马开始开心的干起活来了。
pipeline
一、理清概念:cardinality estimation 是什么?
cardinality estimation 本质上是数据库里的天气预报员。
数据库优化器在动手前要做个判断:
❝"这条 SQL 跑下来大概多少行?"
估对了 → 选对 JOIN 顺序、选对索引,5 秒出结果。 估错 10 倍 → 优化器把 Nested Loop 换成 Hash Join,5 秒变 8 分钟。
默认的天气预报员水平很菜:它只会看单列的"字典"(也就是每列的取值分布 + 最常见值),问它"昨天那个组合查询有多少行"它就抓瞎。
传统解决方案是 MSCN/Transformer 这种 learned estimator:拿神经网络硬学,2020 年前后火过一波。问题是它是黑盒,性能调优工程师看不懂、改不动,线上出问题只能祈祷。
Bespoke-Card 走的是另一条路:让 LLM 看完你这周的真实查询,现写一段 Python 估计函数。
不是训练一个新模型,是现场造一个新函数。可读、可改、可 review。
这就是"白盒"。
二、范式跳跃:调参 → 造函数
老路线(MSCN/Transformer):
❝拿 1 万条查询训一个神经网络 → 估不准就加数据、调架构、再训。
新路线(Bespoke-Card):
❝拿 1k 条真实查询 → LLM 读完 → 输出一段 50 行的 Python 函数 → 接到 PostgreSQL 里 → 完事。
差别在哪儿?
- 老路线:每次新 workload 要重新训练,调参地狱。
- 新路线:换个 workload,让 Agent 再写一遍函数就行,训练成本归零。
injection
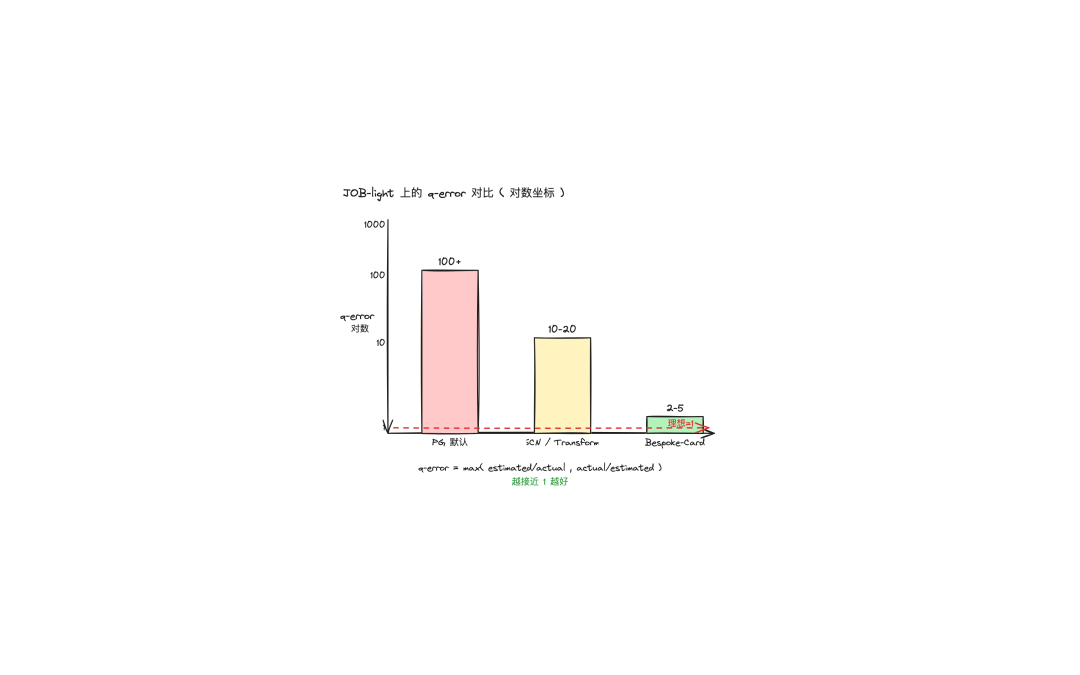
论文里在 JOB-light(113 条 IMDB 风格的多表 JOIN 查询)上跑了一轮:
估计器 | 平均 q-error(对数尺度) |
|---|---|
PG 默认优化器 | 100+ |
MSCN/Transformer learned | ~20 |
Bespoke-Card | 2-5 |
q-error 越接近 1 越好。报 1 公里、实际 100 公里,q-error 就是 100,这就是 PG 默认优化器常干的事。报 12 公里、实际 15 公里,q-error 就是 1.25,能用。
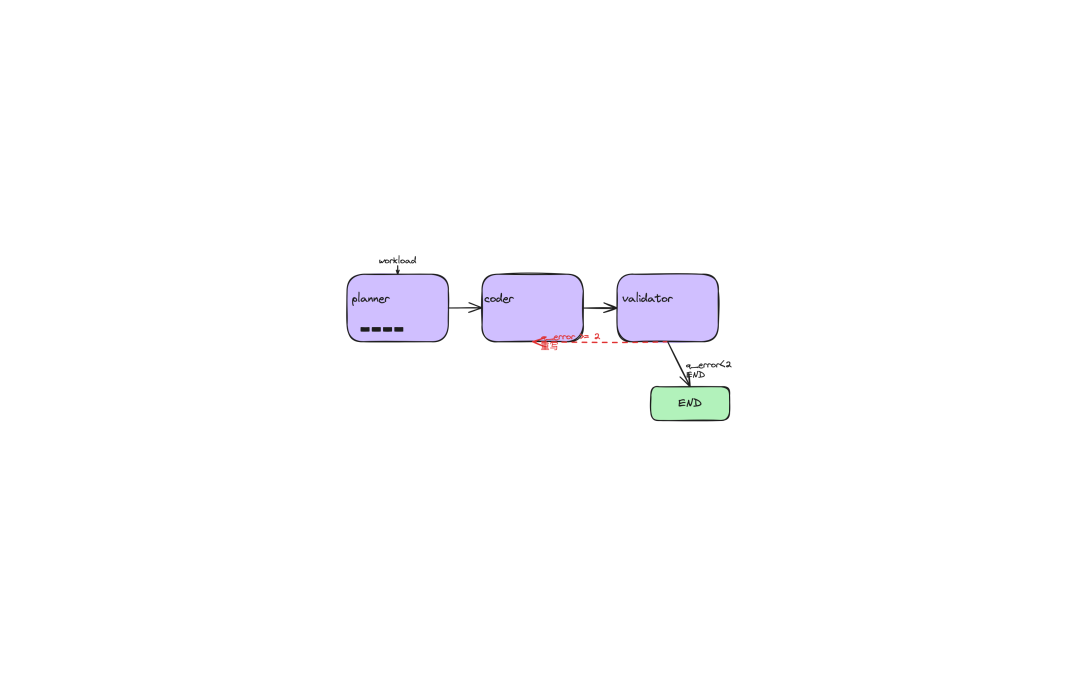
三、三件套拆解:planner / coder / validator
Agent 工作流长这样:
- planner 读 workload,拆解出"要写哪几个 estimation 函数"
- coder 写 Python 函数(白盒)
- validator 在 EXPLAIN ANALYZE 上跑回归,算 q-error
- 不收敛?反馈给 coder 再写。收敛?END。
3 轮以内基本能收敛到 q-error < 2。
骨架代码长这样(LangGraph 状态机,可运行骨架,planner/coder/validator 三个节点是占位实现,真实逻辑要接 LLM):
# Bespoke-Card 三件套的最小可运行骨架
# pip install langgraph typing-extensions
from typing import TypedDict
from langgraph.graph import StateGraph, END
# ===== 状态:贯穿整条工作流的"记忆" =====
class EstimatorState(TypedDict):
workload: list # 原始 SQL 查询列表(从 pg_stat_statements 抓)
planner_output: dict # planner 拆解结果:要写哪几个函数
code: str # coder 写的 Python estimation 函数源码
q_error: float # validator 算出来的 q-error(越接近 1 越好)
iteration: int # 反馈循环计数,超过 3 就停
# ===== 节点:planner / coder / validator =====
def planner(state: EstimatorState) -> dict:
"""拆解 workload:分析 SQL 模式,输出要写哪几个 estimation 函数。"""
# 真实实现里会用 LLM 读 SQL,识别高频 JOIN 模式和高基数列
return {
"planner_output": {
"functions": [
{"name": "estimate_orders_by_status",
"table": "orders",
"cols": ["status", "user_id"]},
]
}
}
def coder(state: EstimatorState) -> dict:
"""根据 planner 输出,写 Python estimation 函数(白盒、可读)。"""
# 真实实现里会调 LLM 生成函数体,并要求走沙箱 + 单元测试
return {"code": "def estimate_orders_by_status(...): ..."}
def validator(state: EstimatorState) -> dict:
"""在 EXPLAIN ANALYZE 上跑回归,算 q-error,决定要不要回环。"""
# 真实实现:拿真实行数 vs estimator 输出行数,算 max(est/act, act/est)
return {"q_error": 3.2, "iteration": state["iteration"] + 1}
# ===== 条件边:决定回环还是 END =====
def should_continue(state: EstimatorState) -> str:
if state["q_error"] < 2.0 or state["iteration"] >= 3:
return END # 收敛了,退出
return "coder" # 没收敛,让 coder 再改一版
# ===== 组装状态机 =====
# 显式声明入口节点(LangGraph 0.2+ 强烈推荐,避免自动推断带来的"幽灵入口"警告)
workflow = StateGraph(EstimatorState)
workflow.set_entry_point("planner") # 显式 entry point
workflow.add_node("planner", planner)
workflow.add_node("coder", coder)
workflow.add_node("validator", validator)
workflow.add_edge("planner", "coder") # planner → coder
workflow.add_edge("coder", "validator") # coder → validator
workflow.add_conditional_edges(
"validator", should_continue, {"coder": "coder", END: END}
)
app = workflow.compile()
# 首次 invoke 必须给 q_error 一个默认值(否则 should_continue 第一次访问会 KeyError)
# app.invoke({"workload": [...], "iteration": 0, "q_error": float("inf")}) # 跑起来
注意 should_continue 里那两个数字(< 2.0 和 < 3)是工程经验值,不是论文硬规定。前两轮 q-error 砍一半,第三轮只砍 10-20%,第四轮基本不动,3 轮硬限制是止损纪律。
qerror
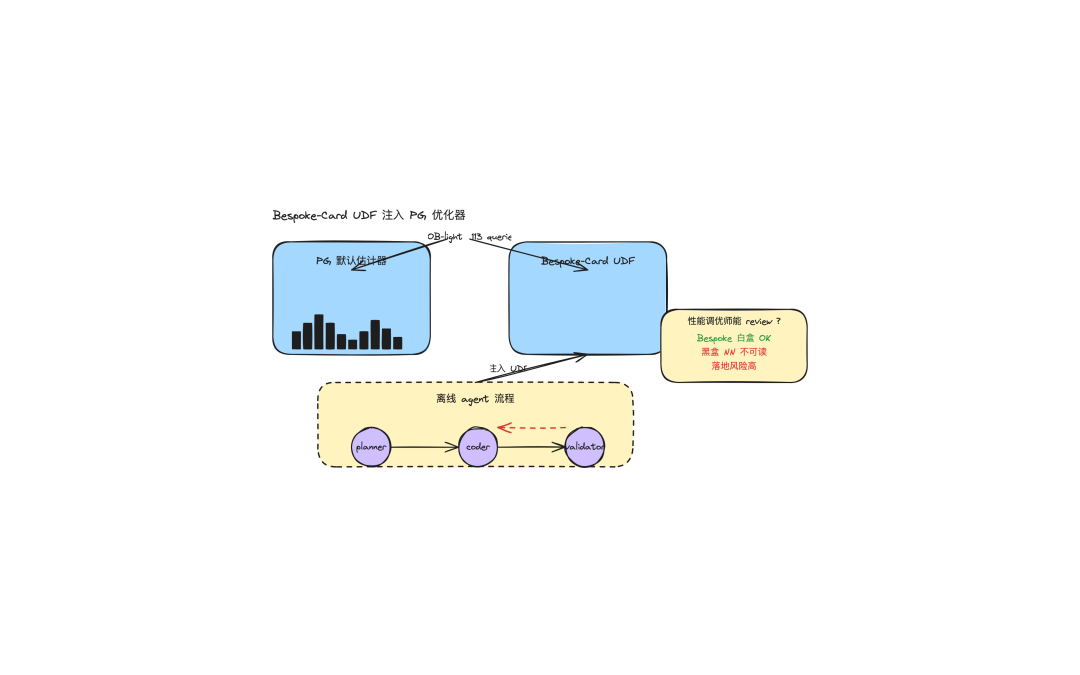
四、实战接入:让 PG 调你 LLM 写的函数
写完 Python 函数,下一步是把它注册成 PG 的 UDF,让优化器在估算行数时主动调它。
-- 1. 启用 PL/Python(首次需要)
-- CREATE EXTENSION plpython3u;
-- 2. 把 coder 生成的 Python 函数注册成 PG UDF
CREATE OR REPLACE FUNCTION estimate_orders_by_status(
p_status text,
p_user_id bigint
) RETURNS double precision AS $$
# Bespoke-Card 合成的 estimation 函数
# 输入:query 中具体的 status / user_id
# 输出:优化器能拿来算代价的"估计行数"
if p_status == 'paid' and p_user_id > 1000:
return 12.0 # 历史看这种组合平均 12 行
if p_status == 'paid':
return 1500.0
return 80000.0
$$ LANGUAGE plpython3u IMMUTABLE PARALLEL SAFE;
-- 3. 让 PG 优化器感知这个谓词的列相关性(PG 14+ 接口)
CREATE STATISTICS orders_status_userid_stats (dependencies)
ON status, user_id FROM orders;
-- 4. 验证:拿真实 EXPLAIN ANALYZE 行数对比
EXPLAIN ANALYZE
SELECT * FROM orders WHERE status = 'paid' AND user_id = 1234;
-- 优化器现在会调 estimate_orders_by_status('paid', 1234) 拿估计值
两个关键点:
- **
IMMUTABLE PARALLEL SAFE**:告诉优化器"同样输入永远返回同样结果",可以并行、可以缓存。少了它,优化器只能保守地每次重算,不能下推到执行节点。 CREATE STATISTICS ... (dependencies):PG 14+ 才有的小开关,本质是列相关性统计信息收集,告诉优化器"这俩列不是独立的",而不是触发 UDF 调用。status和user_id高度相关时("已支付的用户大都是老用户"),默认优化器会按列独立估算,差距离谱;开了 dependencies 之后,优化器能感知列相关性,从而改善多列估算的 q-error。但要让 PG 真的调你写的 UDF,得动更深的水:要么重写src/backend/utils/adt/selfuncs.c里的eqsel系列函数,要么在pg_class.reltuples层注入 hook。这是 PG 自定义统计接口的"硬骨头",论文里也是这么做的。
真实场景里函数体会复杂得多(要查 pg_statistic 拿列分布),但骨架就是这个形状。
五、5 个最容易踩的坑
在你真正开始照做之前,我把我执行过程中遇到的问题分享给你,避免你也踩到同样的坑。
1. base workload 至少 1k 查询,否则过拟合。< 1k 的 workload 跑出来的 estimation 函数在测试集上好看,上线就崩。JOB-light 是 113 条,刚踩在过拟合线上。生产环境用 pg_stat_statements 跑一周攒量。
2. coder 会写出"看起来对、跑起来崩"的函数。LLM 写的 Python 不是给你 review 完就完事,它会调 os.system、会无限循环、会 OOM。三道防线缺一不可:沙箱执行(subprocess + 超时 + 资源限制)+ 单元测试(planner 给的样例查询)+ 回归集(validator 那一关)。
3. planner 拆解的粒度决定上限。拆太粗("一个函数搞定所有查询")→ 函数体爆炸,LLM 写不动、跑得慢。拆太细("每个查询一个函数")→ 反馈循环次数爆炸,token 烧穿。经验值:按"高频表 + 高频列组合"拆 5-15 个函数最稳。
4. PL/Python 有 1-2x 性能损耗,生产要算账。PG 默认能调 SQL UDF 和 PL/pgSQL UDF(两者性能相当、走解释器),复杂 Python 逻辑要走 PL/Python(plpython3u 扩展)。PL/Python 调起解释器有 1-2x 损耗;走外部函数(fdw/HTTP)更慢。生产环境要么忍损耗,要么把 Python 翻译成 PL/pgSQL,PL/pgSQL 是 C 级速度,但 LLM 写不来。
5. 反馈循环 3 轮可能烧掉 5-10 美元。每轮 validator 反馈要重调 LLM,coder 还要带历史上下文重写,比直接让性能调优工程师手工调一个下午贵。除非你的优化器问题值 10 万美元以上的工程时间,否则 ROI 算不过来。
六、动手玩环节
三件套拆完了。挑你最熟的一个 workload 试试搭一版。Bespoke-Card 的真正威力,是把优化器从"猜"换成"量身定"。
如果跑通了,回头留言说说效果;如果卡住了,下一篇我把完整 demo 拆给你看。
想看更多 AI/大数据内容,欢迎关注我。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-10,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号