自适应压缩:情景与语义记忆的统一框架

自适应压缩:情景与语义记忆的统一框架

CreateAMind
发布于 2026-06-12 14:01:30
发布于 2026-06-12 14:01:30
自适应压缩:情景与语义记忆的统一框架
Adaptive compression as a unifying framework for episodic and semantic memory
https://charleywu.github.io/downloads/nagy2025adaptive.pdf


摘要
感官体验被编码为记忆,并非作为逐字复制的副本,而是通过解释和转化。率失真理论将这一过程框架化为一种压缩,其中无关细节被丢弃。尽管基于率失真理论的方法在与实证发现相吻合方面取得了成功,但这些方法假设环境规律是已知且不变的,并且令人惊讶的经验被剔除。然而,大脑对环境规律的模型(语义记忆)是持续学习和完善的,且令人惊讶的事件在这一学习中起着关键作用。在这篇观点文章中,我们提供了一个规范性框架,旨在解决这一计算问题背景下语义记忆与情景记忆之间的相互作用,该问题涵盖了记忆扭曲、课程效应和优先重放。我们提议将记忆视为解决一个在线结构学习问题,其中语义记忆和情景记忆各自发挥作用。我们主张,语义记忆必须学习那些能够实现经验高效编码的规律,而情景记忆则通过以相对原始的格式保存令人惊讶的经验以供后续解释来支持这一过程。该框架为理解自适应压缩和惊讶如何塑造学习与记忆扭曲的轨迹开辟了途径。
引言
人类记忆并不存储感官体验的逐字副本,而是容易发生扭曲,甚至创造出完全虚假的回忆。即使是对于经常遇到的刺激,如硬币、交通标志、企业标志或流行文化中的图标,记忆也可能出现惊人的不准确。这些记忆扭曲和偏差并非随机的,而是系统性的且极为普遍。一个特别突出的例子是“曼德拉效应”,它得名于一种广泛的虚假记忆,即认为纳尔逊·曼德拉在20世纪80年代死于狱中,而事实上他被释放并后来成为了南非总统。这种效应的一个视觉类比是,大多数参与者错误地识别了视觉文化图标的操纵版本,例如戴着单片眼镜的大富翁先生版本,即使它们与原版一起呈现。
这些记忆不准确的程度可能看起来令人惊讶,并可能被视为人类记忆的根本缺陷。然而,记忆的主要目的通常被认为不仅仅是准确回忆过去的经验,而是支持其他认知功能,如预测、泛化、决策和创造力(图1a)。例如,这些错误中有许多属于基于要点的扭曲,其中保留了经验的基本意义(或“要点”),而不是表面细节。这种要点提取过程可以被认为是优先考虑与预测未来事件和指导行为最相关的信息,方法是结合先前的知识和期望来解释经验。然而,目前尚不清楚哪些计算原理构成了多个记忆系统(包括语义记忆和情景记忆)服务于这些认知目标而对过去经验进行编码的方式的基础。
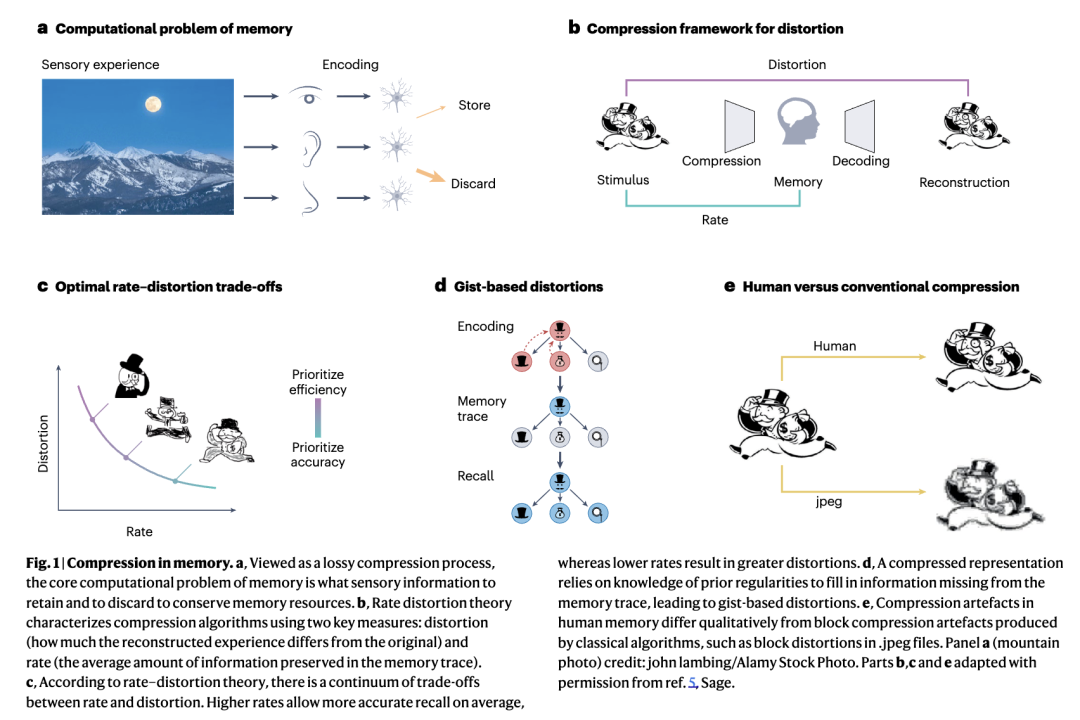
最近在记忆研究中获得关注的一个关于这个问题的规范性视角强调了压缩的重要性。具体而言,率失真理论的数学框架起源于20世纪50年代,作为信息论的扩展,它提出了如何对输入进行最优编码,使其适应可用的容量预算(即率),同时考虑到系统的目标(框1和图1b)。如果有足够大的预算,完美的重建(无损压缩)是可能的,但该理论扩展到了更一般的情况,即即使是最好的可能编码也会导致重建输入中的失真(有损压缩)。率失真理论推导出了一个基本的权衡,表明率的降低会导致可实现的最小失真相应增加(图1c)。例如,当在网络连接不佳的情况下流式传输视频时,会降低视频质量以保持流畅播放。用率失真理论的术语来说,系统降低了编码的率以匹配可用的预算,这增加了失真(在这种情况下,是图像的视觉退化)。
率失真理论的一个关键见解是,编码器可以利用环境中的规律性来从编码中去除冗余信息。这种冗余减少即使在无损情况下也能实现压缩,启发了神经科学中的高效编码假说。当资源不足以进行完美重建时,率失真理论通过策略性地丢弃非基本信息并随后尝试基于已知规律对其进行重建来实现进一步的压缩。然而,这种重建过程通常会引入失真,使回忆起的刺激更好地与先前观察到的规律对齐。
将率失真理论作为人类记忆的规范性框架应用时,先前观察到的规律是一种通常被认为属于语义记忆领域的知识形式。这些规律可以被形式化为环境的内部生成模型,从而能够解释和预测正在进行的经验。使用语义记忆中维持的生成模型进行压缩的过程会在编码-解码过程中引入失真——例如给大富翁先生加上单片眼镜(图1d)。这种解释与基于要点的扭曲以及早期关于记忆扭曲的理论相一致,这些理论将类似的错误归因于先验知识结构(记忆图式)的影响。尽管经典压缩算法产生的记忆扭曲在性质上与人类记忆不同(图1e),但机器学习的进展——特别是将深度生成模型应用于压缩——使得基于率失真理论的模型能够捕捉复杂领域中的记忆现象,如人类绘画、文本和自然图像。这些发现已被用来证明率失真理论可以作为一种统一框架,简洁地解释先验知识(维持在语义记忆中)如何影响感官经验,并产生具有特征模式的记忆扭曲(框1)。

框 1 | 率失真理论与人类记忆
尽管率失真理论为人类记忆提供了一个有吸引力的框架,但由于学习自然刺激准确生成模型的困难,对其一致性的研究受到了阻碍。因此,工程化的压缩算法通常会产生压缩伪影或“记忆扭曲”,这在性质上与人类实验中观察到的结果不同。现代机器学习方法,特别是将深度生成模型(如变分自编码器)应用于压缩,极大地改变了这一局面。变分自编码器使得基于率失真理论的记忆动态模型能够直接应用于复杂的自然领域,如人类绘画、文本甚至自然图像。
生成模型(如变分自编码器)可以学习生成与其训练数据一致的新刺激,通常通过将刺激“编码”为潜在表征,然后“解码”以产生原始刺激的(通常不完美的)重建。直观上,这个过程类似于记忆痕迹的编码和解码。事实上,变分自编码器——具体来说,是一个称为beta-变分自编码器的扩展版本——可以被解释为率失真理论的近似实现。这些自编码器也可以被视为大脑中内部生成模型的类比,要么明确地置于率失真理论的规范性框架中,要么依赖于与人类数据的定性匹配。总而言之,率失真理论为记忆提供了三个原则,我们在此详细说明:先验知识、容量限制和任务依赖性。
率失真理论在人类记忆背景下最直接的应用涉及先验知识对回忆的影响。如果学习到的环境规律模型为记忆痕迹的有效编码提供了基础,那么领域专家比新手具有更准确的回忆,因为他们拥有更准确的领域模型。然而,这种对领域专家的好处仅适用于与模型一致的刺激。这种模式已在关于合成词和棋局配置的记忆研究中得到证明。使用学习到的生成模型来压缩经验,不仅解释了回忆准确性随专业知识的不同变化,还解释了引入的错误类型。编码刺激的过程可以被视为根据生成模型的内部变量对其进行解释;这种高层次的解释构成了“要点”。当经验的特定细节从记忆痕迹中被丢弃时,它们是从模型的潜在表征中生成的。由此产生的扭曲,例如大富翁先生戴上单片眼镜,在记忆文献中被称为基于要点的扭曲。一个著名的例子是Deese-Roediger-McDermott效应,其中回忆语义相关单词列表通常会导致以与呈现项目几乎相同的概率回忆出强烈相关但未呈现的项目。基于率失真理论的方法使用变分自编码器学习自然语言的生成模型,已被用来表明未呈现项目的侵入可以通过从模型的潜在表征重建单词列表来解释。基于要点的扭曲的影响还意味着,当对模糊刺激的解释被操纵时(例如通过上下文线索),回忆准确性和扭曲的性质都应该受到影响,并且这种效应也可以使用率失真理论来重现。
率失真理论还自然地解释了变化资源约束的影响。记忆的理论分析表明,需要某条信息的可能性随时间推移而降低。与这种模式一致,人类遗忘曲线似乎适应了这种下降的需求概率,随着回忆前延迟的增加,回忆的刺激显示出增加的基于要点的扭曲。在率失真理论中,分配给记忆痕迹的资源量对应于率失真曲线上的目标点(图1c),这也调节了重建刺激中与模型一致的扭曲量。
最后,率失真理论还解释了记忆如何受任务需求和行为目标的影响。人类记忆和感知始终表现出对给定任务中混淆刺激成本的敏感性。例如,在类别学习任务中,人类记忆对与学习类别相关的特征变得越来越准确,而对不相关特征的准确性下降。率失真理论可以通过失真函数纳入这些因素,例如,通过过度加权与危险或奖励相关的错误。率失真理论中的这种自由度也可以被利用来优化预测目标,这可以表明需要更新参数而不是精确重建刺激。
与保留一般知识的语义记忆相反,情景记忆是一种不同的表征格式,它以相对原始的形式保留特定事件和感官经验的痕迹。然而,情景记忆的规范性作用——具体而言,相对于与行为目标直接相关的内容,其保持丰富细节的倾向——一直是众多提议的主题。将率失真理论应用于记忆扭曲的工作建立在记忆系统之间的区别之上,认为语义记忆为情景的高效压缩提供了编码框架。
通过描述先验知识如何影响感官经验的编码和重建,基于率失真理论的方法成功地解释了大量不同的记忆扭曲和偏差。然而,我们认为率失真理论忽视了记忆的一个关键挑战:需要基于不断积累的经验来学习和更新内部生成模型。
在这篇观点文章中,我们提出了对记忆计算问题的增强框架,将其视为通过语义和情景记忆系统的结合而实现的迭代学习压缩。我们认为情景记忆的相对丰富性是由于它们在资源约束下支持因果结构的在线学习中的作用。然后,我们回顾了关于人类学习中课程敏感性的文献,并将我们的预测与互补学习系统理论的预测进行了对比,后者是对情景记忆和语义记忆之间相互作用的另一种解释。接下来,我们转向情景记忆中存储了什么的问题,并根据我们的框架解释关于记忆优先级和经验重放的理论和经验结果。最后,我们为未来的研究绘制了轨迹,特别关注大脑如何平衡节省记忆资源和维持学习能力这两个对立的目标。
记忆的计算问题
将率失真理论作为人类记忆的统一解释的一个根本问题是,它假设了一组已知且不变的环境规律,并将其抽象为一个内部生成模型。在现实中,大脑必须在一生中构建这个生成模型(语义记忆),并根据新经验不断对其进行调整。值得注意的是,这种关于已知且不变规律的假设后来被其提出者承认为高效编码框架的一个局限性,他观察到今天冗余的东西不一定昨天也是冗余的。这一假设还导致了对人类记忆的预测出现偏差。因为假设生成模型是正确的,所以对经验中令人惊讶的方面的唯一可用解释是,它们是巧合或噪声的结果,并且不太可能再次发生。因此,当资源有限时,这些令人惊讶的方面是最先被遗忘的。与这一预测形成鲜明对比的是,人类倾向于以高度的情景准确性回忆令人惊讶的、新颖的和不一致的信息。
为了解决这个问题,我们提议在已知生成模型下如何有效压缩经验之外,考虑两个额外的因素。首先,内部生成模型需要被学习。其次,生成模型的学习必须以在线、迭代的方式进行,其中该模型被用于编码那些同时也作为更新其基础的经验。这些约束给压缩视角带来了一个棘手的问题,因为当它在优化率失真权衡时,一个不正确的模型会丢弃恰恰是更新它所需的信息。
为了看清这个扩充后的计算问题中固有的挑战,请考虑以下例子。想象一下,使用试错法学习如何用一台不熟悉的机器(如炉灶摩卡壶)煮出好咖啡,方法是弄清楚不同的变量如何影响咖啡的味道。煮一杯咖啡的每个“情景”(图2a)都涉及相关变量(如咖啡豆的种类或数量)和无关变量(如天气或背景音乐)。在这种情况下,可以通过观察相关输入变量如何影响咖啡的味道,并将这些关系捕捉到生成模型的参数中,来创建一个咖啡冲泡的生成模型。根据规范性学习理论,可以在不特别记住任何单个情景的情况下获得咖啡冲泡的生成模型。相反,所有相关信息都可以通过迭代更新生成模型的参数并丢弃原始经验来捕捉(图2b)。
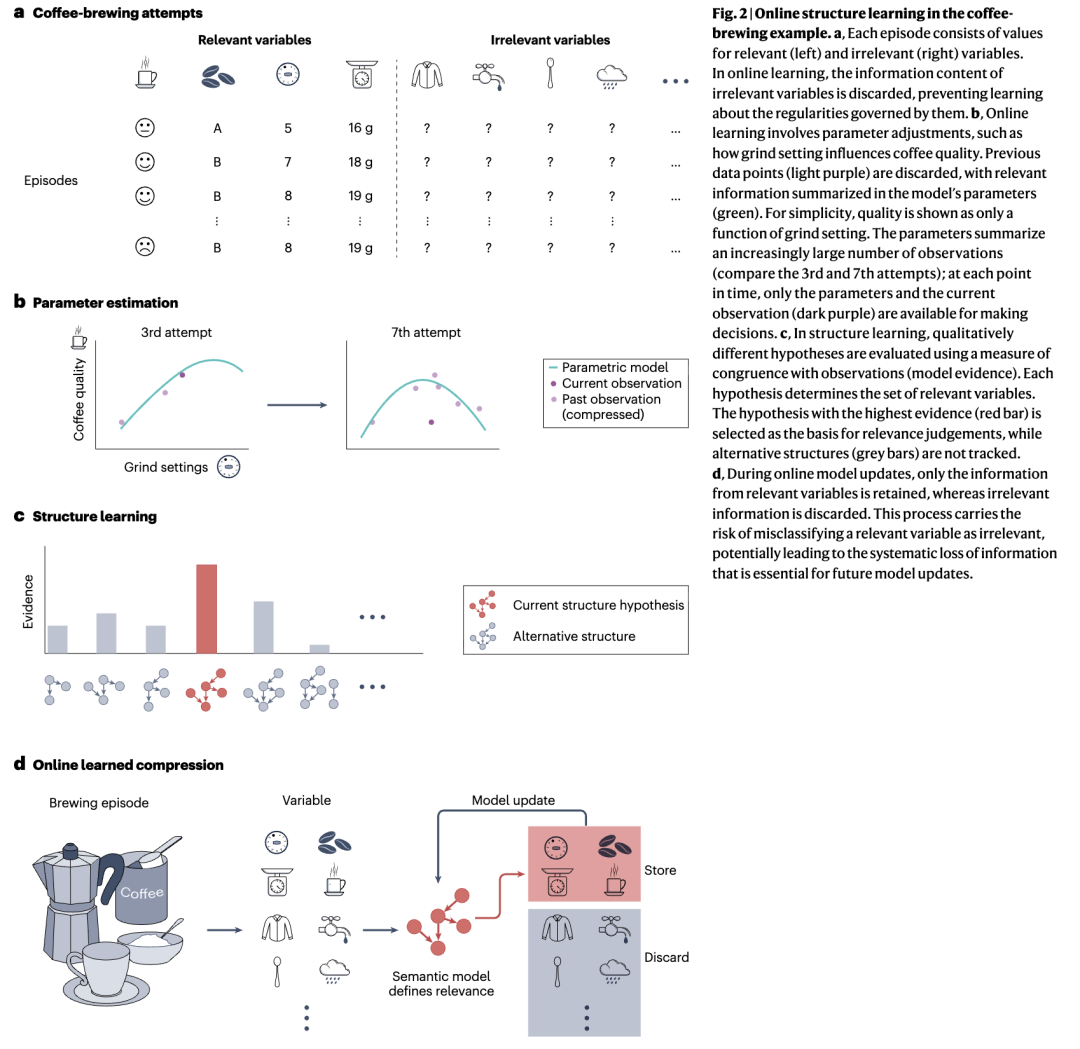
想象一下,在许多次冲泡情景之后,你已经弄清楚了一个能稳定煮出美味咖啡的变量配置。然而今天,它尝起来却莫名其妙地难喝。如果你能直接获取所有过去的情景,你就能轻易确定原因:尽管所有被认为相关的特征都与过去成功时相同,但这次加入壶中的水太冷了,导致在水被加热至沸腾的过程中咖啡粉被烧焦了。然而,由于初始水温之前被认为是不相关的,它在过去情景中的值已经被丢弃了。因此,你感到惊讶,并且没有明确的线索表明哪里出了问题,或者下次尝试该如何调整。
上述学习过程失败背后的一个关键属性是,除了参数估计(完善已知变量之间已知的参数关系)之外,它还具有一个额外的结构学习问题(框2)。结构学习涉及识别给定环境中的因果变量(例如,咖啡豆类型、天气或背景音乐)以及它们如何相互影响(例如,天气可能影响情绪,但不影响咖啡豆类型)(图2c)。就压缩而言,已知的模型结构通过仅编码与参数相关的信息,能够实现记忆资源的高效利用,并且通常能够实现参数的在线估计。相比之下,对于结构学习,在线更新要求并行跟踪和更新每一个可能的假设。在线跟踪和更新很快就会变得不切实际,因为即使对于只有四个变量的玩具问题,也有543种关于因果结构的可能假设(而增加一个变量后就变成了29,000种)。这种假设空间的组合爆炸是结构学习问题的典型特征。这种结构性假设的激增意味着,为每个候选结构维护相关信息与直接存储所有过去的情景一样具有挑战性。

框 2 | 结构学习与纽拉特之船
结构学习指的是一类学习问题,其中竞争模型不仅在模型参数的精确数值(参数估计)上有所不同,而且在参数的数量、变量的选择、关系的形式,甚至用于指定模型的基本构建块上也有所不同。结构学习的规范性理论通常将学习问题分解为确定模型的高级结构(结构假设)和在保持结构固定的同时微调参数。一些方法进一步区分了结构和形式,其中形式指的是图的一般类别(如树或网格),而结构定义了边和节点的确切集合。结构的改变意味着局部修改(如添加或删除一条边),而模型形式的转变则是罕见但根本性的转变,例如一个孩子决定将动物物种组织成树状结构而不是分离的簇。为简单起见,我们在这里在更广泛的意义上使用“结构学习”,它涵盖了结构和形式。
结构学习的两个属性使其从根本上比参数估计更具挑战性。首先,结构学习问题通常通过指定基本组件及其组合规则来定义(例如,因果图由节点和有向边构建)。这些组合规则通常是开放式的,使得任意复杂的结构能够在学习过程中被“生长”出来。尽管组合性使这些模型能够构建真正新颖的解释,但它也导致了难以想象的巨大假设空间。其次,在假设空间中导航相当困难。为了说明这一点,想象一个“学习景观”,其地平线由模型的可能配置跨越,地形的高度由该配置的拟合优度定义(如图3c所示)。在参数估计中,这种景观通常是平滑和连续的,参数的微小变化会导致模型预测的微小变化。然而,在结构学习中,可能的配置通常是离散的,相邻的点有时可能对应于截然不同的预测,使得地形崎岖且危险。
纽拉特之船的类比最初是在修改科学理论时遇到的困难的背景下提出的。然而,这些困难与学习过程中遇到的困难相呼应,使得纽拉特之船的类比也适用于这种语境。纽拉特之船的迭代重建可以被精确地形式化为层次贝叶斯推断框架内的一种特定类型的近似结构学习。针对不确定性的贝叶斯解决方案涉及跟踪所有可能性,并将它们总结在后验分布中。理想情况下,层次贝叶斯推断规定计算所有结构假设的后验分布,并随着新观察的到来并行更新它们。在实践中,通常使用蒙特卡洛近似,其中在层次结构的最高层,只跟踪一组受限的假设(甚至只有一个)。为这个受限集维护参数的后验分布比维护完整集所需的资源要少得多。在这类蒙特卡洛算法中,更新模型结构的过程被编码在提议分布中,该分布指定了在每次更新中可以考虑哪些替代假设。遵循纽拉特之船的原则,这种提议分布倾向于局部改变,例如,仅允许添加或删除单个因果边。
因果学习是结构学习的一个典型例子。然而,结构学习问题在自然环境中无处不在,包括情境学习、识别数据中潜在的结构形式以及学习视觉或抽象概念。结构学习也被认为与事件分割有关,其中需要发现视觉或听觉信息流的时间结构。在最一般的层面上,理论的可组合构建块可以定义编程语言的组件,使学习类似于程序归纳。
一方面,有限的人类记忆资源要求以压缩格式存储经验,这由学习到的环境生成模型支持。另一方面,学习和维护生成模型需要访问先前情景的细节,而这些细节在当前模型结构下可能被认为是不相关的。因此,必须在结构性假设的组合爆炸(考虑所有可能的模型结构)与丢弃关键信息的风险(仅考虑单一结构下的解释)之间取得平衡(图2d)。
我们提出,大脑使用一种依赖于两个相互关联的记忆系统相结合的近似方法(图3)。语义记忆构建一个生成模型,该模型捕捉环境规律并促进压缩。由于计算和记忆约束,语义记忆仅跟踪关于环境总体因果结构的单一工作假设。尽管我们的论点可以扩展到在受限局部领域内跟踪多个结构假设的情况,但为简单起见,我们假设只有一个假设。我们将基于这个单一结构假设、存储在语义记忆中的生成模型称为语义模型。然而,限制所跟踪的假设集存在陷入死胡同的风险,即进一步改进语义模型所需的信息已经被选择性地丢弃了(如上面的咖啡例子)。因此,情景记忆保留了新颖和令人惊讶的情景(即在当前假设下最可能被误解的情景)的相对原始且未压缩的编码,为错误的结构假设提供了一定的保障。
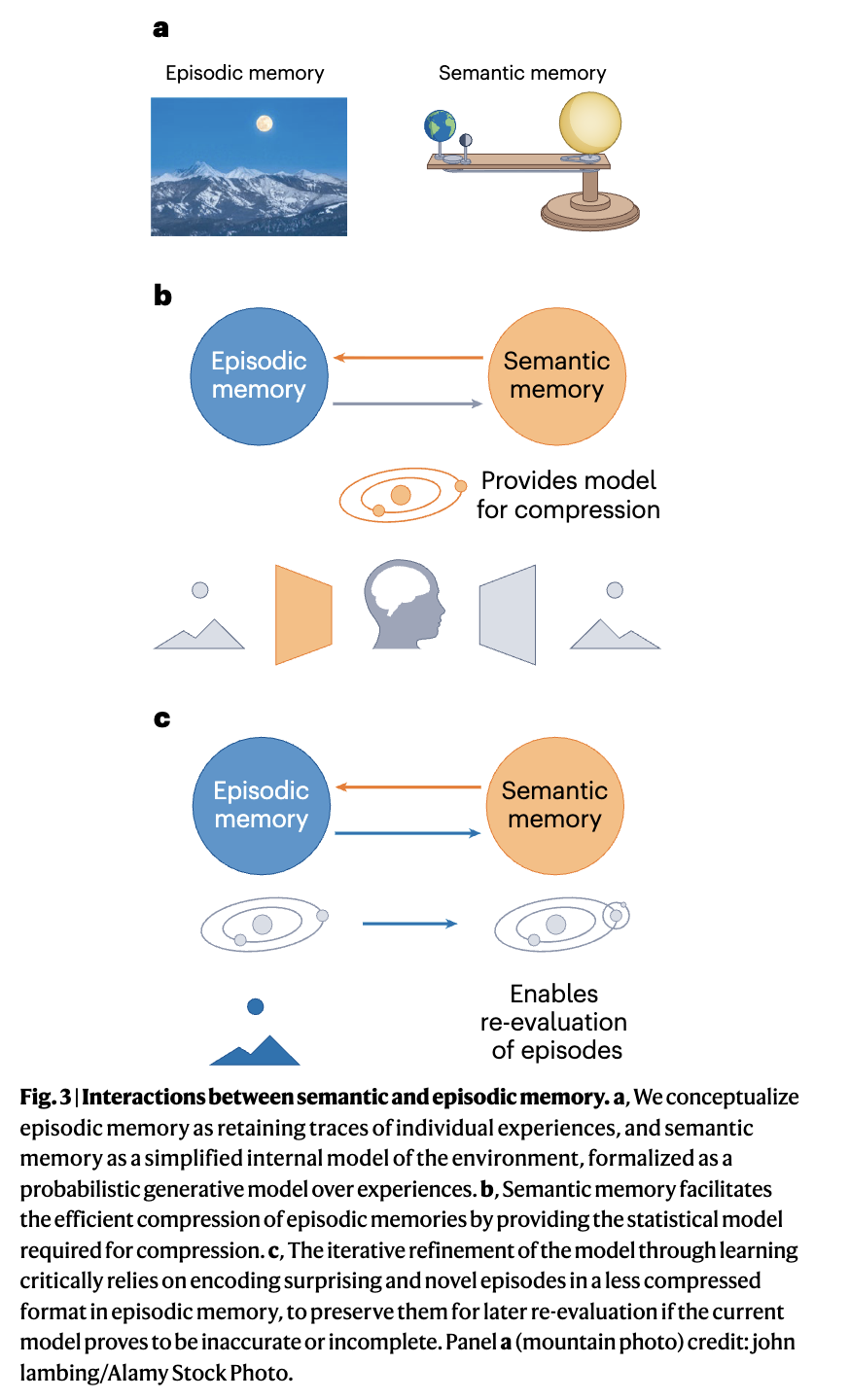
这种提出的语义记忆和情景记忆的整合解决了学习以记忆(构建能够实现压缩的语义模型)和记忆以学习(存储相关情景以供未来模型更新)这两个理论问题。它还解释了一系列关于人类行为的实证发现,包括记忆扭曲和学习中的课程效应。
学习以记忆
记忆资源的有效分配需要基于观察构建并持续更新环境的生成模型,我们认为这是语义记忆的作用。由于环境的因果结构未知,可用于此类模型的假设空间巨大且难以导航,使得近似方法成为必要。一种常用的近似结构学习方法是跟踪一组选定的假设而不是完整的分布,这被称为蒙特卡洛抽样。来自多种学习范式的汇聚证据表明,大脑可能也仅限于跟踪一组受限的假设,甚至单一的结构假设。一种提议将这种学习过程比作纽拉特之船的隐喻,该隐喻最初在科学哲学中被引入,用以说明科学理论的渐进和连续发展。纽拉特之船的隐喻将理论家比作试图在航行时重建船只的水手,逐渐更换船只的部件,但从未完全从头开始(因为那样船会沉没)。
应用于大脑时,隐喻中的船代表了个体在语义记忆中对世界结构的不断演化的理解。在我们的提议中,语义记忆维持着一个动态且不断演化的结构假设,该假设为感知和决策提供信息。纽拉特的隐喻强调了对船只所做改变的局部性,反映了大脑对世界模型的更新并非全面替换,而是渐进式修改的观点。因此,可以在不损害其在环境中有效运作能力的情况下对模型结构进行局部改变(图4a)。
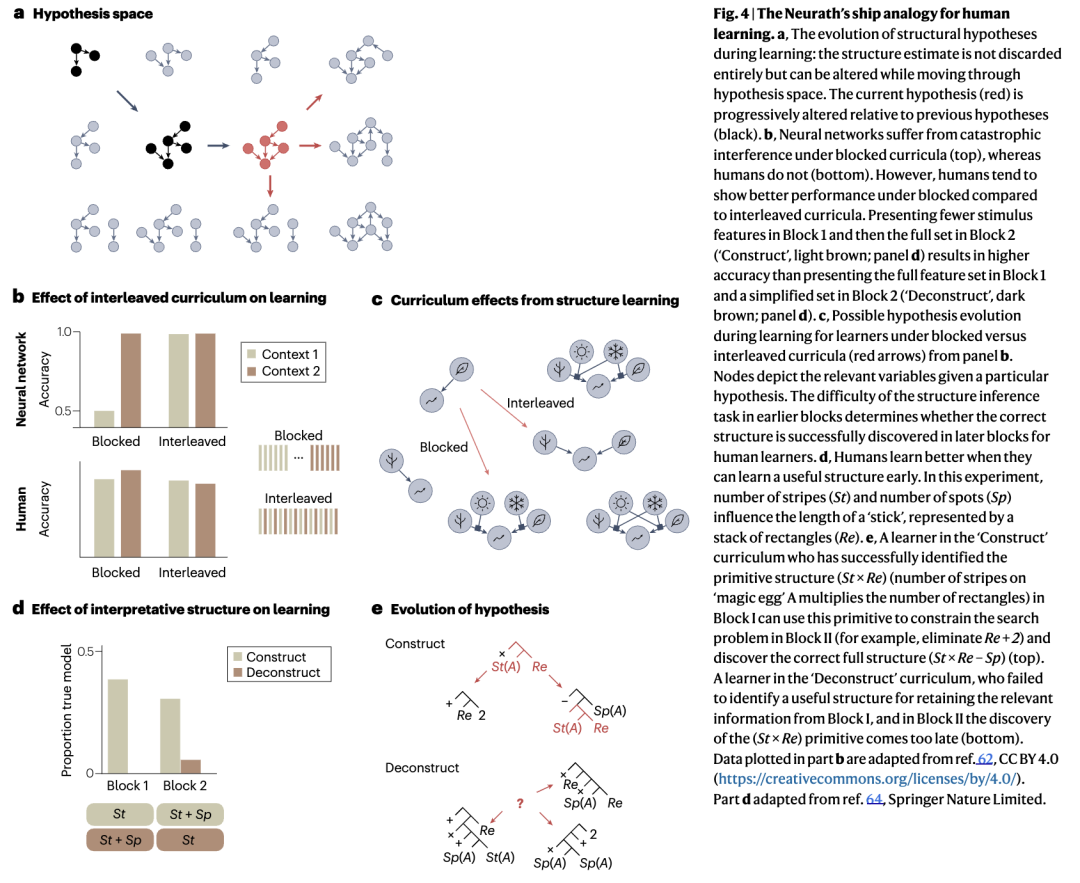
根据我们的压缩视角,这艘船代表了语义记忆中的单一结构假设,决定了如何解释新经验,从而决定了保留什么信息。在实验环境中,参与者基于早期观察形成这种结构假设。如果他们成功地发现了正确的结构,那么进一步的同构观察可以被快速且高效地整合,语义记忆决定了观察的哪些方面可以安全地丢弃。然而,不正确的结构假设可能导致学习中的两个关键失败模式:首先,它可能损害对未来观察的解释,导致错误的参数更新。其次,即使参与者意识到他们的假设存在缺陷,替代方案也是基于过去的数据进行评估的,而这些数据是基于不正确的假设压缩的。因此,支持正确结构的证据可能被误认为是噪声并被系统性地丢弃,使学习者被困在一个死胡同假设中。纽拉特之船近似中学习和压缩的这种纠缠导致了对刺激遭遇顺序的明显敏感性,通常被称为课程效应。这些效应包括首因效应,即在实验早期经历的刺激决定了后期经历内容的影响。这些效应已在人类行为中通过奖励学习和因果学习等任务观察到。
这些人类学习模式与使用人工神经网络的语义学习替代方案所特征性的学习动态不同。人工神经网络也表现出稳健的课程效应,但通常呈现与人类倾向于表现出的相反模式。例如,在一项研究中,人类和人工神经网络被给予相同的语境依赖性决策任务(图4b)。当人工神经网络以分块的方式呈现不同的任务或学习语境时,不同的分块倾向于相互覆盖并导致表现不佳,这是一个被充分研究的现象,被称为"灾难性遗忘"。但是,当训练数据交错呈现时,人工神经网络可以可靠地学习。与人工神经网络相反,人类在分块设置中表现更好,并受到交错课程的阻碍,且随着任务复杂性的增加(每个语境有更多特征),这种效应更强。其他实证研究也发现了类似的分块课程效应,导致人类在具有结构不确定性的任务中表现更好。我们注意到,一些关于人类学习的研究也在不同情境下发现了交错课程的好处,特别是当刺激之间的泛化有利于任务表现时,或者在辨别任务中,不同类别范例的直接并置似乎突出了它们之间的差异。
互补学习系统理论是关于为何需要情景记忆系统的最有影响力的提议之一,它关注的正是减轻灾难性遗忘的挑战。互补学习系统理论将语义模型的获取视为人工神经网络的逐渐更新,随时间整合多次经验的信息。根据这一观点,情景记忆的效用在于,将较旧的情景与当前观察交错呈现可以保护旧知识不被覆盖。
从在线结构学习的角度来看,分块数据是理想的,因为来自单一语境的连续试验使学习者能够专注于完整结构的一个子集,从而创建一个更易于管理的假设空间以供搜索。一旦结构被发现,语义记忆就可以被用来有效地压缩来自同一语境的进一步观察,使学习者能够微调参数。这种情况类似于上面描述的咖啡例子。相比之下,在交错训练中,需要考虑的初始假设空间要大得多,这使得形成初始假设变得困难。此外,如果没有有效假设提供的解释性结构,观察中的有用信息就无法被选择性地保留,从而阻碍了正确结构证据的积累。这种情况的一个可能结果是,某些学习者可能无法准确地保留语境,或者得出一个将语境合并在一起的过度简化的结构。在互补学习系统中,语义记忆依赖于交错训练,而情景记忆则减轻了分块的不利影响。相比之下,我们的方法表明,语义记忆在分块训练下学习最有效,而情景记忆对于抵消由交错训练引起的失败模式至关重要。
人类学习中的课程依赖性与结构发现问题之间更直接的联系,是在一项使用分块课程并操纵分块内容的研究中建立的。参与者学习了“魔法蛋”的特征与“棍子”长度之间的因果关系(图4c)。在“构建”课程下,第一个分块仅包含存在一种特征的示例(条纹或斑点),而第二个分块引入了第二种特征。相比之下,“解构”课程在第一个分块中呈现了两种特征(一个更具挑战性的结构推理问题)。参与者被允许在同一分块内重新访问先前的示例,从而减轻了对他们记忆的需求。在构建课程下,比在解构课程下有更多的参与者发现了正确的结构——这里被概念化为一个程序。在构建课程中,可以从第一个分块轻松推断出正确的部分规则(仅结合一种特征),然后将其扩展以结合第二种特征。相比之下,解构课程中的顺序颠倒使得初始假设空间变得更加复杂。尽管更简单的第二个分块允许相当大比例的参与者识别出正确的结构基元(条纹数量对棍子长度具有乘法效应的规则),但他们无法将这一知识追溯性地应用于来自第一个分块的观察,这与以下假设一致:由于缺乏合适的解释性结构,他们无法有效地压缩其信息内容。
总而言之,我们认为有效的压缩需要大脑在语义记忆中迭代地构建环境的生成模型,同时应用相同的模型来压缩观察。我们提出,大脑依赖于这个在线结构学习问题的近似解决方案,这导致学习中出现特征性的路径依赖性:压缩能力关键地依赖于结构发现的成功。由此产生的课程效应与经验数据一致,但与在人工神经网络中观察到的动态形成对比。我们框架的一个关键见解是,通过近似推断进行的在线结构学习意味着有效压缩与稳健的结构学习之间的权衡。有效的压缩涉及使用语义记忆来丢弃无关信息,而学习潜在结构则需要将经验中看似无关的方面保留在情景记忆中,以便评估替代假设。接下来,我们将重点放在我们提出的框架的后一个组成部分上,探讨情景记忆如何支持语义知识的获取。
记忆以学习
在本节中,我们探讨了使用记忆来创建对先前经验的丰富重建,包括特质性的和可能无关的细节。我们的框架基于这样一个见解:为了缓解当前结构假设有缺陷时发生的语义学习失败模式,唯一普遍适用的方法是保留在当前假设的语境下看似无关但对评估潜在替代方案相关的信息。因此,记忆的能力对于确保未来的学习保持可能至关重要。
在我们的煮咖啡例子中,水温从相关变量集中的遗漏意味着在出现意外的糟糕结果后,不清楚如何更新模型。如果该情景被编码在情景记忆中,它可能包含在当前结构假设的语境下无关的细节,例如水是从冷水龙头接的。随后的一个情景中,水来自预热的壶并产生了味道好得多的结果,这可以追溯性地揭示水温是一个相关的语境变量。更一般地说,我们假设学习者以细节丰富且相对未提炼的格式保留经验,这使他们能够对模型结构进行更彻底的修改。延伸上一节的纽拉特之船隐喻,我们将记忆的这一方面称为“情景救生筏”(图5a)。
一个简单的类别学习任务的结果证明了情景救生筏的价值。在这项研究中,人工学习者必须通过顺序观察迭代地学习类别,类似于仅基于可见特征发现未知动物的物种(无监督聚类,图5a)。在这种语境下,结构学习要求学习者确定类别的数量,而参数估计要求细化每个类别的特征分布(图5b)。研究发现,仅语义记忆的学习者(使用纽拉特之船近似来迭代更新其语义模型的结构估计和参数,但不保留单个情景的明确表征)通常在结构学习任务中失败。具体而言,仅语义记忆的学习者倾向于系统性地低估类别的数量,除非观察被仔细排序(使用分块课程)。然而,拥有语义和情景记忆的学习者,即使情景容量严重受限,也极大地改善了结构学习(图5c)。学习者的情景记忆存储了一小部分过去的经验,这些经验在考虑替代结构时可以被重放,从而增强了当前假设参数中包含的信息。这个重放过程可以被视为记忆巩固重放的类比,其中情景记忆与语义记忆中维持的知识相结合。
尽管情景救生筏对结构学习明显有利,但情景记忆是一种昂贵的记忆格式。情景记忆的成本源于其效用的来源:保留特质性细节是昂贵的。记忆成本与学习收益之间的权衡提出了将稀缺资源分配到哪里以及优先记住哪些情景的问题。为了回答这个问题,我们首先考虑一个简化的语境,其中唯一的存储限制是可以存储的情景数量,但每个情景都可以被完美回忆。
与由于成本而需要选择性应用情景记忆的推理一致,具有有限情景记忆容量的模拟学习者在在线结构学习中,当他们选择性地优先处理具有高贝叶斯惊讶的经验时,与不加区分地应用相同容量的学习者相比表现更好(图5c)。这种方法类似于早期类别学习中向一般规则添加例外的提议,共享存储异常事件的需求。贝叶斯惊讶的一个优点是它区分了单纯的噪声和值得模型改变的惊讶,尽管未来可以探索惊讶或新颖性的替代形式化。惊讶还可以发出环境变化的信号,并成为检测新类型事件的基础,从而有助于事件分割。
不一致和新颖信息在记忆中被选择性优先处理的想法在心理学中有着悠久的历史,并得到了大量实证发现的支持。同样,在神经科学中,海马结构(与情景记忆相关)保留新颖信息的想法已被广泛探索,特别是在经验重放和记忆巩固的背景下。
情景应如何被优先处理的问题通常被称为优先重放。然而,由于在这些方法中记忆资源的约束不是主要关注点,优先化指的不是应该保留哪些情景,而是它们应该被多频繁地重放。(我们注意到,在极限情况下,降低重放情景的概率对应于丢弃它。)根据相关的奖励预测误差对情景进行优先处理在机器学习进步中发挥了重要作用,例如通过强化学习在Atari游戏中实现人类水平的表现。与优先处理新颖信息的想法一致,有人认为在强化学习环境中保留情景的效用在遇到新环境的早期阶段最大,即在建立足够准确的语义模型之前。然而,这一论点强调了情景对决策的直接效用,而不是它们在支持语义模型构建中的潜在作用。
我们现在转向更现实的场景,其中记忆资源更加有限,且情景无法被完美回忆。率失真理论视角表明,如果情景被有损压缩,由语义记忆中维持的生成模型填补缺失细节,则可以减少记忆资源(框1)。生成重放(在人工神经网络训练期间重放本质上是压缩的情景)已被证明与精确重放(无细节丢失地重放情景)相比,对记忆资源的需求低得多,同时仍能防止灾难性遗忘。
虽然使用语义记忆压缩情景相比于精确重放所需的逐字存储能够大幅节省记忆资源,但这似乎与我们提出的情景记忆的作用直接矛盾。如果存储情景是为了保留看似无关的细节,以便在当前模型不正确时进行重新解释,那么不清楚如何依赖当前模型来压缩这些经验。率失真理论的一个关键见解对于解决这种紧张关系可能至关重要:情景可以以不同的细节级别进行压缩,反映分配的资源(率)和失真之间的不同权衡。与在情景记忆中存储事件的精确副本或仅仅更新模型参数之间的二元选择不同,这种结构提出了变速率编码的可能性,在重建所需保真度方面有一系列选择。
我们提出,感官经验的变速率编码是大脑平衡节省资源和保持对新颖性的鲁棒性这两个竞争目标的基础(框3)。具体而言,我们建议编码率——或等效地,期望的回忆准确性——应由与每个观察相关的惊讶或新颖性度量来决定(图5d)。在这种方法下,大多数经验会在情景记忆中留下痕迹,但预测良好的情景会以高度压缩的形式存储,而令人惊讶的情景则较少压缩。预测良好的情景的高度压缩会使它们容易出现越来越大的基于要点的扭曲,正如之前关于人类记忆的工作所证明的那样。然而,当语义记忆对其解释的信心较低时,由于预测被违反或新情况,可以分配额外的记忆资源以较少的压缩来编码情景,从而导致对情景细节更准确的回忆。这种机制可以以分级的方式优先处理情景中的信息,并解释为什么令人惊讶的经验通常比预期的经验被回忆起更多的情景细节。
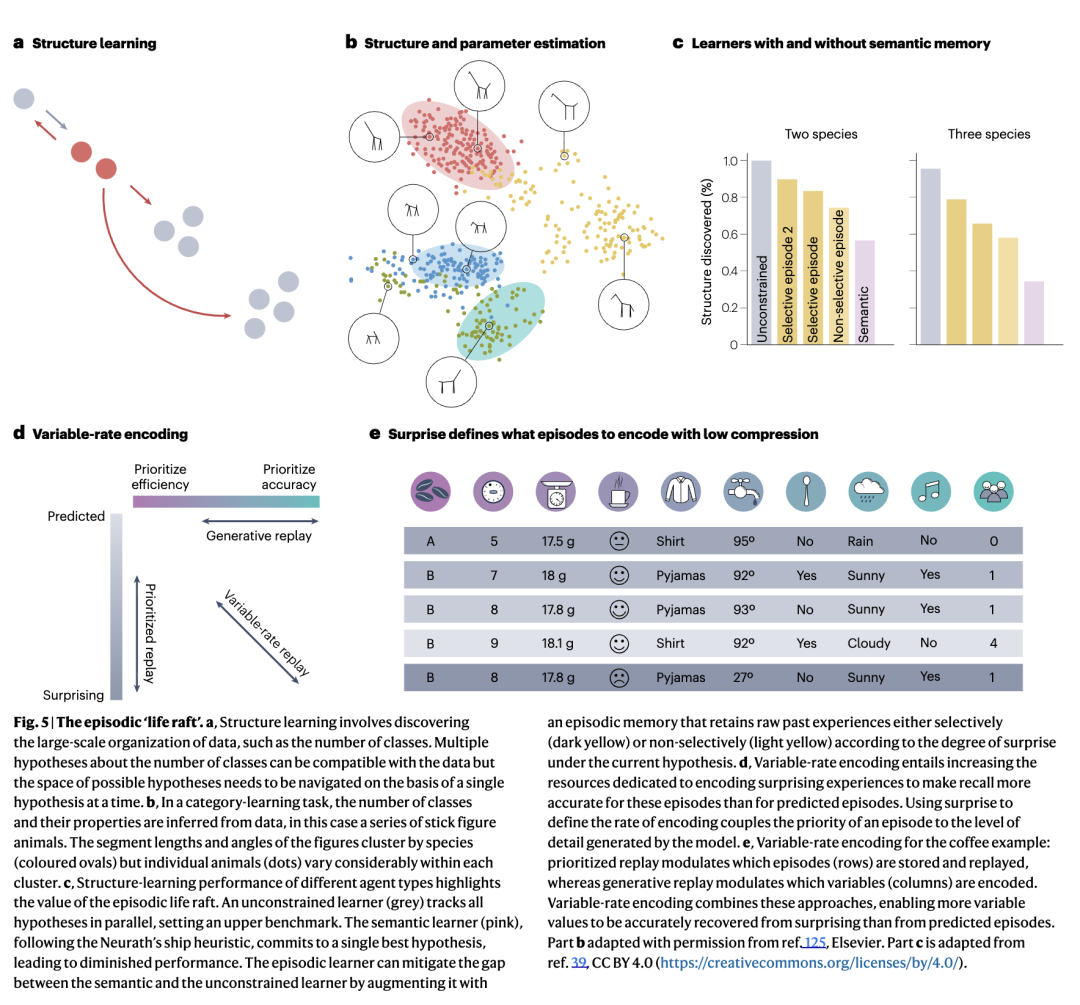

总而言之,我们的提议通过情景记忆和语义记忆之间的相互作用提供了对记忆扭曲的计算解释。然而,变速率压缩对情景记忆防止结构学习失败的能力的影响在理论上仍未被探索,有待实证验证。
结论
人类记忆容易出现系统性偏差和扭曲,这被广泛解释为其适应性功能和固有资源限制的反映;记忆受到从经验中解释和学习的需要的塑造。然而,这种设置提出了双重挑战:在学习如何决定什么是有用的同时保留有用的信息。我们认为,就其当前形式而言,率失真理论作为人类记忆的规范性框架是有欠缺的。尽管基于率失真理论的方法为谜题的第一部分(如何使用语义模型压缩情景)提供了规范性解决方案,但它们忽略了语义知识最初是如何从模型解释和压缩的相同经验中获取的。我们强调了这种遗漏如何导致与人类记忆经验现象的定性差异,并认为解决这些现象需要我们重新思考率失真理论的基本假设。
因此,我们提出了一个修正的规范性框架,其中语义记忆跟踪环境结构的有限近似。在这个框架中,语义模型的在线构建和更新类似于纽拉特之船在海上重建的方式。然而,因为在单一结构假设下解释观察会导致基本信息的系统性丢失,我们主张调用额外的情景记忆资源,以相对未压缩的格式编码新颖和令人惊讶的观察。因此,在重建语义记忆之船时,情景记忆充当了救生筏。
最终,我们对情景和语义记忆系统之间相互作用的视角为人类学习和记忆中的广泛现象提供了简约的解释,同时也为该领域的一些持续挑战提供了见解。通过解释情景记忆在防止学习错误语义模型中的作用,我们得出了一个规范性解释,说明为什么令人惊讶的刺激通常比熟悉或预期的刺激以更高的保真度被记住。相比之下,我们的框架预测,对于与当前结构假设一致的经验,会出现典型的类似率失真理论的扭曲。
我们观点的一个关键焦点是语义模型的演变对记忆扭曲的后果。标准的率失真理论方法已经作为经典基于要点的记忆扭曲的统一框架,例如语义相关项目的侵入或素描记忆中与标签一致的扭曲。然而,如果我们允许压缩模型随时间演变,由新观察驱动的更新将影响后续观察的编码——这是课程效应的定义属性。相反,在新经验之后更新模型(例如在事后误导信息或后见之明偏差中)会改变解码器,从而改变过去经验的重建方式,这也有可能解释联想记忆错误。
在人类和机器学习中,刺激通常以随机方式呈现,试验之间具有简单或不存在的依赖关系。这种呈现顺序对于消除实验混淆因素具有明显的好处。然而,它与自然环境的特征——丰富的、多尺度的序列结构——形成了鲜明的对比。在这里,我们关注粗粒度结构,忽略了情景的时间广度,因此也忽略了如何分割连续感官输入的问题。这种细粒度的时间结构及其与结构学习的交互,对于更细致地理解课程效应可能很重要,整合这些方法可能会在统一框架下解释更多种类的课程效应。对学习中的路径依赖性的更精细理解——这对教育应用也至关重要——将需要改进关于语义知识如何表征和组织的理论。一个有趣的方法是将语义记忆视为一个概念库,通常在程序归纳框架中形式化,其中课程设计的目标是诱导广泛适用且可组合的概念模块,以便进一步学习可以在此基础上构建。
尽管在现有的率失真理论解释中缺失,但情感显著性在经验上是影响记忆的最强因素之一。我们的框架提供了两种有前途的方式来考虑这个因素。首先,经验的情感相关方面可以通过率失真理论的失真函数被优先处理。这种优先化与奖励如何在强化学习环境中与生成模型相结合相一致,其中情感调节与奖励相关的计算。其次,我们提出新颖性和惊讶决定了变速率编码中的资源分配。因为情感显著性表明该情景是否预计在未来被检索,高显著性意味着更高的编码率。因此,创伤经历可以被理解为一种极端情况,即主要编码未解释的感官特征,这与创伤后应激障碍的定性特征相一致。更广泛地说,纽拉特之船与情景救生筏的结合可能被证明是更深入、从计算角度理解记忆中的创伤事件及其对发展的长期影响的肥沃土壤。
尽管我们的观点关注情景和语义记忆的组合如何支持学习环境的有效模型,但这不太可能是智能体所需的唯一学习系统,就像存在多个记忆系统一样。率失真理论有助于阐明其中一些差异,但额外的计算考虑——例如计算成本的权衡以及这些系统的路径依赖共同进化——也可能发挥关键作用。
原文链接:https://charleywu.github.io/downloads/nagy2025adaptive.pdf
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-10,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号