腾讯云大数据:从 AI-Ready 到 Agent-Ready,AI 原生数据底座全栈升级

腾讯云大数据:从 AI-Ready 到 Agent-Ready,AI 原生数据底座全栈升级

腾讯QQ大数据
发布于 2026-06-12 12:02:06
发布于 2026-06-12 12:02:06
点击蓝字 关注我们

本文共计4660字 预计阅读时长14分钟
在 2026 腾讯云 AI 产业应用峰会 Data+AI 产品专场,腾讯云大数据宣布面向 Agent 升级全栈数据平台能力。在通过 智能入口DataBuddy和 统一控制面WeData重塑用户与 Agent 协同方式之外,腾讯云对底层数据平台进行了系统性重构——从存储、计算、数据到系统四个层面全面智能化升级,构建支撑 Agent 运行的 AI 原生数据底座,让平台既能服务 Agent,也能逐步演进为 Agent。
数据平台正在经历一次罕见的系统性重构。过去十年,大数据平台围绕"能存、能算、能查"持续迭代,服务对象始终是有限数量的工程师和分析师。但在 AI 落地的关键年,这一假设正在失效:使用者从人扩展为"人 + Agent",数据形态从结构化表扩展到文本、图片、音频、视频、向量并存,计算负载也从离线 ETL 扩展到训练、推理、RAG、Agent 编排等 AI Workload。Agent 7×24 小时高频并发地做分析、调度和实验,对底层平台的弹性、调度、检索和治理提出了前所未有的要求。
行业研究普遍指向同一判断。Gartner 在最新研究中指出,Lakehouse 架构虽已进入主流,但 Agent 驱动的数据使用模式正在倒逼平台具备更原生的智能化能力;中国信通院在 2026 年发布的《智能原生研究报告》中也明确,智能原生不是简单的"AI+",而是从产品与系统设计之初就将 AI 作为核心驱动力。
面对这一趋势,腾讯云大数据的 AI 原生数据底座遵循两条主线展开。
第一条是 As Agent——让平台自身具备 Agent 能力,能自主感知、自主诊断、自主处置、自我演进,完成数据平台自动运维、智能调优等工作,实现整体平台智能化;
第二条是 Agent Efficiency——面对海量数据场景,提供新的计算和存储范式,让 Agent 更高效地原生运行。围绕这两条主线,平台在系统、计算、数据、存储四个智能维度同步升级。


计算智能:从结构化SQL到多模态AI Workload的融合范式
在过去,传统数据平台的计算范式主要面向SQL语义的传统数据工程。但随着AI应用在不断扩展企业内可被计算的数据边界,数据平台的计算范式将延伸到支撑训练、推理、RAG 以及 Agent 等多样化 AI 工作负载,同时数据平台可智能化地将CPU+GPU资源在各自计算范式下灵活调度与切换,满足人类用户和AI Agent的多元化计算需求,适配这种范式的新一代计算体系我们成为计算智能。

腾讯云数据智能,具体由以下几部分关键引擎能力组成:
自研高性能计算引擎 Meson 基于向量化执行和 Pipeline 模型对 Spark SQL 深度优化,今年重点发布三项能力:Spark Rapids(将 Shuffle、Join 等重计算算子下推到 GPU 加速)、增量计算(只计算每天变化的部分,大幅节省资源和时间)和全面支持 Spark 4.0。TPC-DS(1TB 数据集)测试中整体性能提升 3.6 倍,计算密集型场景最高提升 5 倍,CPU 资源消耗降低 50%。目前,Meson 已吸引超过 100 家企业客户使用,是腾讯云自研计算引擎中增速最快的产品。
针对多模态数据处理,自研跨模态计算引擎 Xpark 将原本需要 Spark、OpenCV、Librosa 等多种工具串联的处理流程统一到一套 API 中,从读取、预处理、Embedding 生成到写入向量库全程链式调用、零中间落盘,推理吞吐相比开源方案提升 3倍,GPU 利用率接近 100%。Xpark 同步推出 SQL-First AI Function 能力——用户直接在 SQL 里调用各类LLM和ML函数,快速完成多模态数据做处理、传统机器学习训练、情感分析等 AI 应用。
底层 TCRay 作为 CPU+GPU 统一调度底座,对 Ray Core、Ray Data、Ray Train、Ray Serve 四大模块做了深度优化,并在开源Ray基础上增强作业调度/任务恢复/资源弹性/大规模作业稳定性,把数据处理(Data)、模型训练(Train)、在线服务(Serve)三类 AI Workload 统一到同一套基础设施上,多租户 LoRA 架构带来 30% 至 70% 的成本下降。ES 提供一站式 RAG 和混合检索服务,今年新增 RAG 效果评估功能和 Ray Serve 推理,存储底层直接打通 TCLake,构建 Agent 知识库的最短路径。
智能计算引擎通过 SQL、Python、MCP、Skill、CLI 多种接口对外开放,可被 DataBuddy、WorkBuddy、CodeBuddy 以及第三方 Agent 平台直接调用,呈现"用户与 Agent 平权"的新一代计算范式。

存储智能:让"Agent用得起"
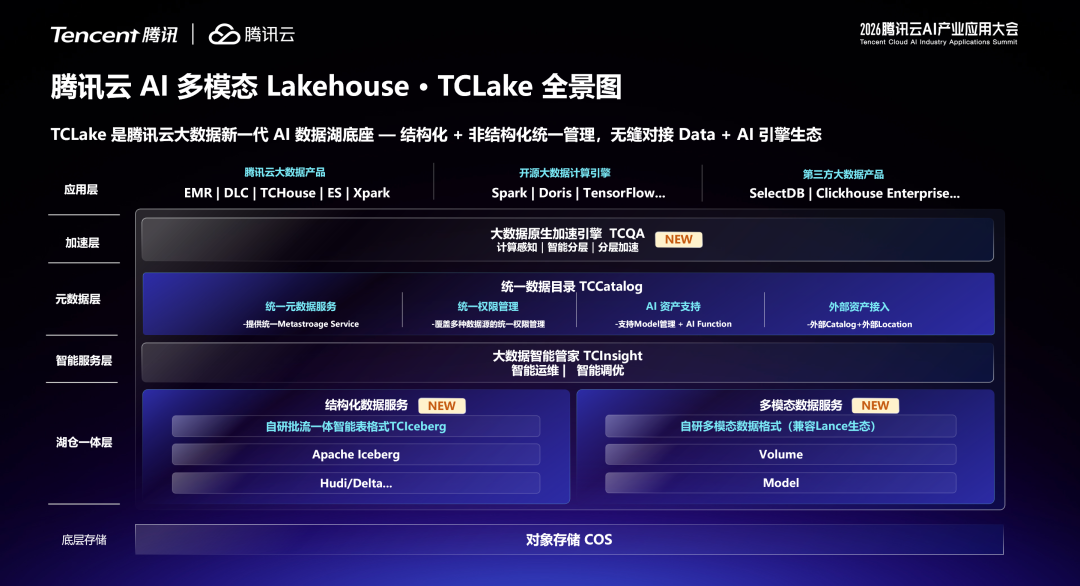
围绕多模态 LakeHouse,腾讯云大数据持续升级统一数据底座,把向量、图、全文检索与智能管理一并收敛进 LakeHouse,支持结构化、非结构化与 AI 资产同一套底座管理。
TCIceberg 基于 Apache Iceberg,在对原 Iceberg 无任何入侵前提下实现了批流一体与部分列更新等开源增强能力,同时 TCLance 支持音视频、图片、文档、Embedding 等非结构化数据,实现了结构化和非结构化数据的融合——同一张表可以同时存储数字字段、字符串字段、图片字节、音频引用和向量 Embedding,用同一套权限和查询接口。
TCQA 原生加速引擎通过计算感知与传输路径优化,让存储层主动感知上层计算任务的逻辑和资源状态,实现存储与计算高效协同。在 TPC-DS 基准测试中,开启 TCQA 后计算耗时降低 22%,数据传输量大幅减少。
TCCatalog 多模态统一目录覆盖结构化、半结构化、非结构化和 AI 模型,实现跨源、跨平台、跨引擎的统一数据资产管理——并支持 Spark、Doris、TCHouse、PyTorch、Xpark 等多种计算引擎的统一访问与权限管理,大幅降低 Data+AI 多模态企业私域数据资产的管理难度。
向量存储、TCBase 全文检索、图存储构成"检索三剑客"——向量找相似(亿级向量毫秒查询)、全文找精确(Agent 记忆存储)、图找关系(百亿边深度遍历)——三者在 TCLake 上原生集成,Agent 可以并行调用三条路径、融合排序,得到更完整、更准确的答案。在企业知识库场景中,新一代存储架构可将存储成本降低至传统方案的十分之一,检索性能提升 4.5 倍。

数据智能:让"Agent替你查"

当前企业 80% 的数据分析需求是一次性灵活分析,但有限的数据分析师远不能匹配上百倍规模的业务侧需求,分析响应周期长达周级甚至月级。腾讯云大数据推出的多Agent协作体系 由 SQL Agent、Code Agent、RAG Agent、报告 Agent 等多类专家 Agent 协同构成,覆盖数据工程、数据分析与数据科学三大方向,把数据团队的工作流搬进了一支可调度、会进化的 Agent 团队。
多Agent协作体系具备三大核心能力:
多 Agent 协作——用户用日常对话下一道指令,系统自动组织 Agent 团队,有人清洗数据、有人分析趋势、有人生成报告,企业还可以自定义专属工作流;
自我进化——Agent 能够根据历史执行经验、用户反馈和技能调用结果,持续复盘和成长,像一位不断沉淀经验的专家;
统一集成框架——不管是用开源框架自研的 Agent,还是采购的第三方 Agent,都可以接入框架实现统一控制。
在 NL2SQL 准确率这一业界最头疼的指标上,腾讯云通过对元数据的自动语义增强、智能选表、语法自动匹配和多轮修正的闭环,将准确率从行业平均水平约 70% 提升到 90% 以上。
某报业客户的舆情分析场景中,TCDataAgent 用 Document AI 解析文本、Planner 拆解任务并多路并行、RAG Agent 向量召回、SQL Agent 统计归因、报告 Agent 生成稿件素材,原本 1 天的工作量被压缩到分钟级,每条结论自动附带数据来源;
某游戏客户的付费用户流失分析场景中,业务人员一句自然语言提问即可触发 TCDataAgent 自动完成用户画像、归因建模与报告生成,识别出"版本更新后核心玩法平衡问题"这一主因,置信度达 87%;
某金融客户从自建 CDH 迁移到腾讯云 EMR 和 DLC 的过程中,Data Agent 自动扫描 Schema 和依赖、智能翻译 SQL(准确率 90%+)、自动并行对账并输出切流建议,迁移周期缩短 50%,实现零业务中断的平稳迁移。

系统智能:让平台实现"自动驾驶"

腾讯云大数据将自研大数据智能管家 TCInsight 嵌入用户与平台交互的全生命周期。选型阶段,智能管控 Agent 按业务场景智能推荐规格与资源规划——用户只需提供数据规模、任务规模和时效要求,系统即可自动推算出所需资源和成本;上云阶段,智能迁移 Agent 自动完成评估、SQL 翻译、数据搬迁与回归验证,迁移周期缩短 50%;日常使用阶段,自然语言取代菜单和表单,用户用一句话完成查询、配置和管理。
在最消耗人力的运维调优环节,平台进入"自动驾驶"——自主调优 Agent 持续优化任务执行,让原本需要五年十年经验专家才能完成的 Spark 参数调优变成了对话式交互,资源浪费降低 15%;自主运维 Agent 7×24 小时值守,每天自动巡检集群健康度,故障根因定位时间从 4.5 小时压缩至 30 分钟;预测治理 Agent 实时监测资源增长趋势,提前预警容量风险,避免因资源规划疏忽导致的生产事故。截至 2025 年,TCInsight 已累计处置超过 10 万次系统事件,覆盖 EMR、DLC、ES、TCHouse 等核心产品,相关技术成果入选数据库领域顶级会议 VLDB 2025。

全栈落地与未来方向
四大智能体系并非孤立的能力堆叠,这是腾讯云大数据 AI 原生数据底座在"平台自治、计算融合、分析自动化、存储统一"四个维度的同步落地。截至目前,腾讯云大数据平台已在金融、政务、零售、互联网等行业实现规模化落地,服务数千家头部客户,具备千万核算力规模、日处理数据数百 PB 的产业能力。
AI Native 数据底座不是终点,而是平台自身持续演进的起点。下一步,存储、计算、数据、系统四个层面将进一步从"被动响应"走向"主动 Agent"——计算引擎具备自我调整、自我修复、自我进化的能力,让 Agent 内生于数据底座的每一层,与开发者、客户、合作伙伴共建 Agent 时代的数据基础设施。
END
关注腾讯云大数据╳探索数据的无限可能
往期精彩



求点赞

求分享

求喜欢

本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-11,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号