高速公路企业AI落地的第一步不是建大模型,而是把资料先管起来

高速公路企业AI落地的第一步不是建大模型,而是把资料先管起来

高速公路那点事儿
发布于 2026-06-11 20:19:40
发布于 2026-06-11 20:19:40
在以前的文章中提到了,高速公路大模型需要加入大模型语料与知识库管理体系,这是大模型的粮仓,他包含了高速公路的行业法规、应急预案手册、运营数据标准,是用来防止大模型瞎编出现幻觉的保障。
所以对于大多数高速公路企业来说,这甚至不是第一步,而是AI落地的前提条件。
如何将看似枯燥的数据变成有价值、可利用、可预测的数据指标,真正做到“用数据说话、用数据管理、用数据决策、用数据创新”一直是高速公路运营管理单位解决的问题和工作目标。
我们今天就探讨一下如何将资料/数据管起来。
高速公路数据现状
高速公路行业数据有一个非常典型的特点,就是数据特别多,知识很杂,但是分散严重。
例如运营管理类的资料,就包括了规章制度、应急预案、业务流程、收费政策、稽核规则、服务标准等,这些资料往往散落在OA系统、文件服务器、微信群、 员工电脑、PDF文件等,很多资料甚至找不到最新版。
再例如工程建设类资料,包括设计图纸、BIM模型、施工日志、竣工文件、检测报告等,有的存档在档案系统,有的在项目公司,有的在监理单位。
AI落地真正需要的是什么?
目前我们自己知道,就是大模型+企业知识。
如果企业知识是混乱的,文档资料找不到,数据不统一,编码格式不一致,信息就不完整,那么再强的大模型也只能回答一些简单的通用问题。
所以,从目前行业实践看,知识管理往往比训练模型更重要。
知识治理
目前来说,整个路径是从数据治理开始,到知识治理,再建立知识库,实现RAG(检索增强生成)模式。
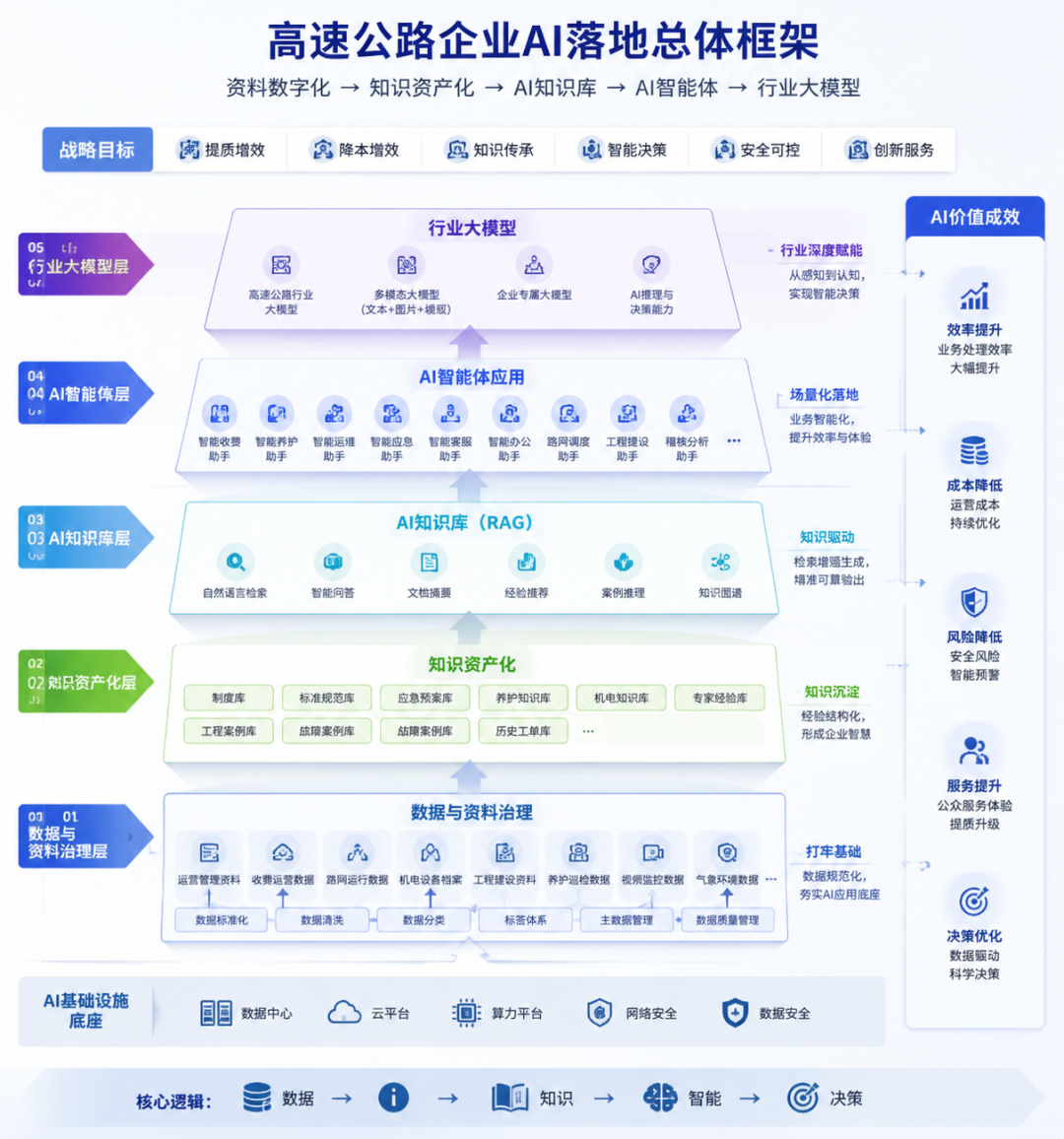
这种路径模式往往比训练行业大模型成本低一个数量级,但效果反而更好。
所以,我们需要完成对公司各部门、各分中心、下辖收费站、养护工区等部门的资料和数据调研工作。
数据调研的内容包括:对部门主要职责、各项规章制度及管理办法、运营指标要求的收集、梳理;对各软件系统的建设及使用情况、系统中结构化及非结构化数据、运营管理数据、路网相关数据、基础统计数据的归集、汇总;对手工上报数据或加工数据的来源、颗粒度等进行走访调研及情况摸底,拿到一手详实数据及资料。
通过对数据的汇总、抽取、清洗,结合高速公司管理运营的指标要求,梳理各相关系统数据资源的关联性,编制数据资源目录,建立信息资源交换管理标准体系。
从大量的、不完全的、有噪声的、模糊的、随机的实际应用数据中,提取隐含其中的、潜在有用的信息和知识。
其中侧重于挖掘为提升管理部门动态监测水平和科学决策提供哪些关键性数据指标。
最宝贵资产
我们甚至认为高速公路企业未来最大的AI资产不是模型,而是知识。
因为大模型越来越便宜,算力成本也越来越低。
但是企业几十年积累的运营经验、养护经验、应急处置经验、工程建设经验等是别人复制不了的。
谁先把这些资料和数据变成结构化、可检索、可推理的知识资产,谁的AI应用就会率先产生价值。
目前来说,大家基本也是如此实现的,做行业大模型钱,先做智慧知识库、智能运维知识助手、智能养护助手等等。
所以对于高速公路企业而言,可以把AI建设路径概括为资料数字化、知识资产化、AI知识库、AI智能体、行业大模型。
只有按以上经验或知识大家的大模型才是落地的大模型。
例如某收费站发生入口拥堵时应该执行什么处置流程?
如果企业没有整理应急预案,AI只能回答互联网通用流程。
但如果接入企业知识库,AI可以回答第几号应急预案启动,哪个岗位负责,联系哪些单位,处置时限要求,相关的上报流程等。
本文只是简单探讨,不设计技术底层。
如有侵权,请联系本人删除。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-10,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号