Claude Code 多 Agent 编排:4 步选对 Workflows 还是 /goal
原创
Claude Code 多 Agent 编排:4 步选对 Workflows 还是 /goal
原创
运维有术
发布于 2026-06-06 22:45:37
发布于 2026-06-06 22:45:37
🚩 2026 年「术哥无界」系列实战文档 X 篇原创计划 第 130 篇,AI 编程最佳实战「2026」系列第 39 篇
大家好,欢迎来到 术哥无界 | ShugeX | 运维有术。
我是术哥,一名专注于 AI 编程、AI 智能体、Agent Skills、MCP、云原生、AIOps、Milvus 向量数据库的技术实践者与开源布道者!
Talk is cheap, let's explore。无界探索,有术而行。

Claude Code 多 Agent 编排:4 步选对 Workflows 还是 /goal
用 Claude Code 做小任务,体验很丝滑 - 改个函数、修个 bug、重构一段逻辑,几分钟搞定。但任务一大就出问题:上下文越来越长,Claude 开始忘记最初的目标;或者在多个文件之间来回切换,中间状态全靠聊天记录维系,一旦会话崩溃,进度归零。
这两类问题,Claude Code 分别给了两套解法:Dynamic Workflows 解决编排和上下文卸载,/goal 解决目标驱动的自主循环。但社区里一个常见的困惑是:这俩东西到底有什么区别?什么时候该用哪个?能不能一起用?
翻了一圈官方资料和社区讨论之后,我发现答案其实很简单 - 分界线不是任务难不难,而是流程确不确定。下面展开聊聊。
说明:本文基于 Claude Code 官方文档(Workflows、Goal Mode)和社区讨论整理分析而成,部分机制细节和最佳实践来自社区交叉验证,尚未在生产环境中完成全场景验证。文中的配置模板和参数建议仅供参考,实际效果请以你的业务数据和环境测试结果为准。如果有实际使用经验,欢迎在评论区分享交流。
1. 先搞清楚:它们各自解决什么问题
Workflows:把编排逻辑从聊天上下文中卸出去
Dynamic Workflows(随 Claude Opus 4.8 于 2026 年 5 月底推出,目前处于研究预览阶段)解决的核心问题是上下文卸载。
之前做复杂任务,所有的任务拆分、等待、复核、返工都压在主会话上下文里。典型的 ReAct 式循环:Claude 想 → 做 → 看 → 再想 → 再做。上下文越积越多,质量越来越差。
Workflows 的做法是把这个循环从聊天上下文里挪出来,交给一段 JavaScript 脚本去管:
层级 | 干什么 | 不管什么 |
|---|---|---|
Claude(主模型) | 写 workflow 脚本,解释最终结果 | 逐条阅读所有中间结果 |
Workflow runtime | 执行脚本、管理阶段、保存中间状态 | 自己判断业务含义 |
Subagents | 读文件、跑命令、输出结构化结果 | 决定整个流程怎么走 |
换句话说,Claude 不再需要把 20 个 subagent 的中间输出全装进上下文。它只需要写好脚本,最后看一下聚合结果就够了。
一句话:主会话上下文不再爆炸。
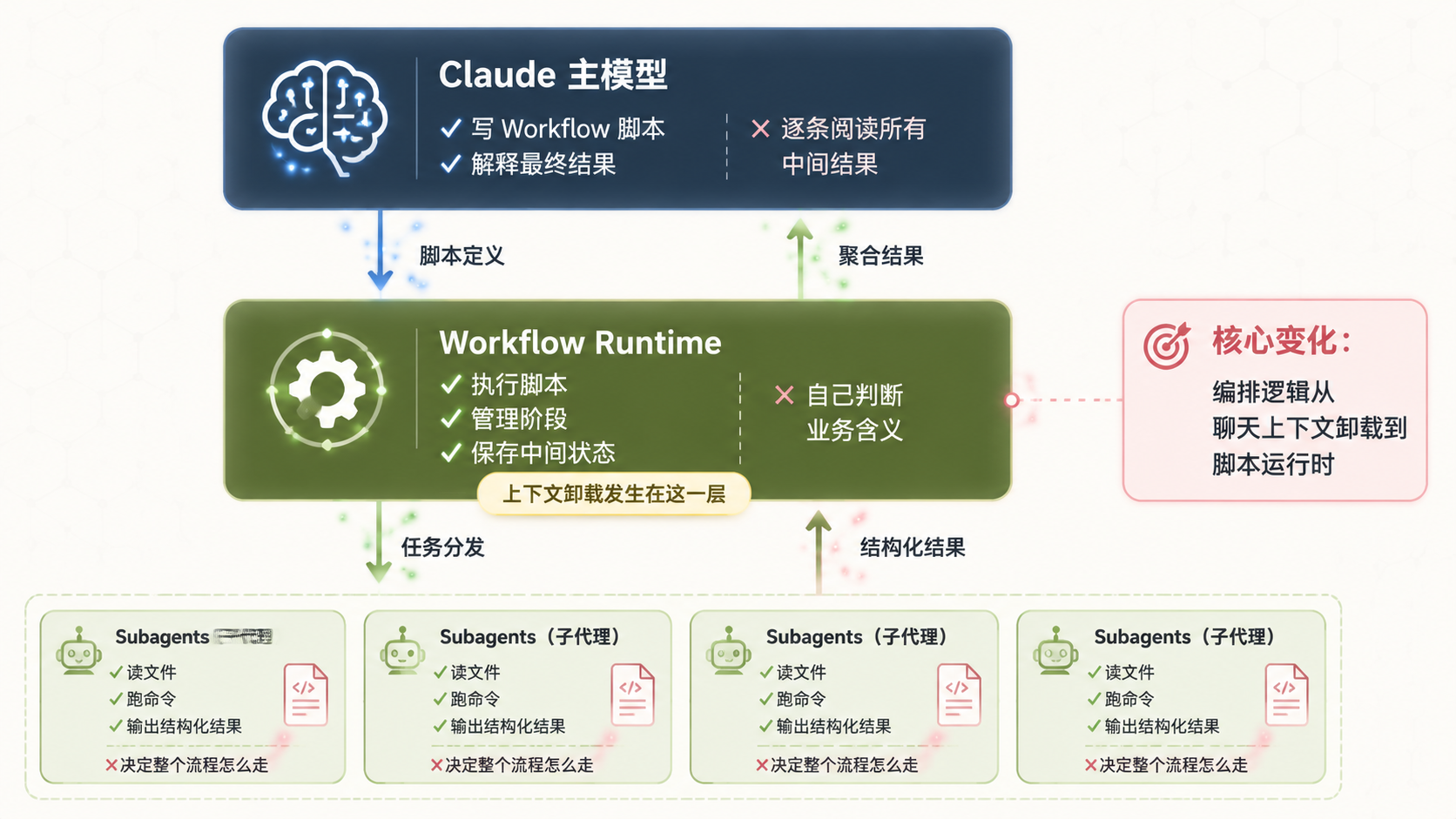
Dynamic Workflows 三层架构示意图
图 1:Dynamic Workflows 三层架构 — 编排逻辑从聊天上下文卸载到脚本运行时
/goal:条件驱动的自主循环
/goal 解决的问题不太一样 - 怎么让 Claude 自己跑下去、跑到你满意为止。
核心机制是双模型循环:
- 你设定一个目标条件(比如:所有 lint 错误已修复,
eslint输出无错误) - 主模型执行一轮操作
- 轻量评估模型(默认 Haiku)独立判定条件是否满足
- 不满足 → 主模型根据原因继续下一轮;满足 → 循环结束
这里面有一个关键的设计原则:执行与评估分离。让 Claude 自己判断做得够不够好是靠不住的,所以专门用一个独立的轻量模型来验收。评估模型只能看到会话中明确输出的内容,不能自己跑命令或读文件,这就保证了评估的独立性。
# 基本用法
/goal 修复 src 目录下所有 lint 错误,直到 eslint 输出无错误信息
# 非交互式
claude -p "/goal 所有测试通过,npm test 退出码为 0"几个硬限制(来自社区交叉验证):
- 条件长度上限 4000 字符
- 单个会话只支持一个激活目标
- 评估模型(Haiku)的 token 消耗远低于主模型
/goal 和 Claude Code 里其他几种循环机制也不一样。/loop 是时间驱动的,按固定间隔执行,适合周期性任务。Stop hook 是配置文件里定义的自动停止条件,支持全会话作用域。Auto mode 只是自动审批工具调用,不启动新的轮次。而 /goal 是条件驱动的 - 上一轮完成后,评估模型判定是否达标,达标了才停。这四种机制的适用场景完全不同:
工具 | 启动下一轮的时机 | 停止条件 |
|---|---|---|
| 上一轮完成后 | 轻量模型确认条件满足 |
| 设定时间间隔到期后 | 手动停止或 Claude 判断完成 |
Stop hook | 上一轮完成后 | 自定义脚本或提示词判断 |
Auto mode | 不启动新轮次 | Claude 判断单轮任务完成 |
2. 核心区别:确定性,不是难度
很多人觉得 Workflows 是给大任务用的,/goal 是给小任务用的。这个理解不够准确。
真正的分界线是流程是否确定。
什么时候用 Workflows?
你能提前画出流程图的任务。比如:
- PR 审查:安全审查 → 性能审查 → 可读性审查 → 架构审查 → 汇总
- 批量迁移:读源文件 → 转换格式 → 写目标文件 → 运行测试 → 验证结果
- 深度研究:并行搜索多来源 → 交叉验证 → 合成报告
这些任务有个共同点:步骤能提前想清楚,每一步做什么大致确定,中间可能有条件分支但不会太多。
Workflows 提供四种调度形态:
调度形态 | 适合场景 | 用错了的后果 |
|---|---|---|
Parallel(批处理屏障) | 全局去重、多路交叉验证 | 慢任务拖住整个阶段 |
Pipeline(流水线) | 文件级迁移、批量转换 | 需要全局视图时漏掉冲突 |
Loop | 反复修复直到无新增、测试失败回滚 | 终止条件不清会空转 |
Fan-out / Fan-in | 大范围搜索后集中汇总 | 汇总 schema 不稳定会污染结论 |
而且 Workflows 的脚本不是静态 DAG - 它用的是命令式 JavaScript。你可以在脚本里写 while、if,根据上一阶段返回了多少结果临时决定下一阶段开几个 agent。流程的形状在运行时长出来。
// 最小化结构示意
{
metadata: {
name: "最小示例",
description: "演示 Workflow 基本结构"
},
agents: [
/* 至少调用一次 agent */
],
return: finalResult // 必须返回结果
}什么时候用 /goal?
你能说清楚最终结果长什么样,但说不清楚中间要经过哪些步骤。
典型场景:
- 自动修复 lint 错误:你知道终点是
eslint输出干净,但不知道要改多少文件、改几次 - 重构遗留代码:你知道终点是所有测试通过,但中间可能需要反复调整
- 质量打磨:你知道终点是性能测试达标,但优化路径不确定
/goal 的价值在于:你只需要描述终点,不需要规划路径。Claude 会自己探索、试错、修正。
什么时候都不用?
社区经验里有一条共识特别重要:
对于小任务,原生 Claude Code 比任何精心设计的工作流都好用。
改一两个文件的事,直接跟 Claude 对话,比设计 workflow 或写 goal 条件快得多。别把简单问题搞复杂了。
3. 多 Agent 编排的能力梯度
把视角拉远一点,Claude Code 的多 Agent 编排其实有一个清晰的能力梯度:
维度 | Subagents | Agent Teams | Workflows |
|---|---|---|---|
编排方式 | 自然语言临时派发 | 多角色并行,人工调度 | JS 脚本显式声明 |
可复用性 | 每次重新描述 | 无法复用 | 脚本保存后直接复用 |
可观测性 | 有限 | 可查看 | 阶段/Agent 状态实时追踪 |
质量门禁 | 无 | 无 | 支持校验阶段 |
版本管理 | 无 | 无 | 脚本可版本控制 |
核心区别:Skills 解决能力问题(什么时候调用什么工具),Workflow 解决流程问题(多个 Agent 怎么协作、调度、验证、聚合)。
有人可能会问:Workflows 和 n8n、Coze 这类自动化平台有什么区别?
定位完全不一样。n8n 是人提前画好流程图让系统跑;Dynamic Workflows 是 Claude 根据当次任务动态生成脚本让 runtime 跑。前者是稳定业务流程的产品化,后者是复杂工程任务的临场拆解。和 LangGraph 也不在一个层面 - LangGraph 是生产级 agent runtime,Workflows 是开发者在代码仓库里自己用的编排工具。
下面是一个深度研究 Workflow 的编排示例,三阶段:并行搜索 → 交叉验证 → 报告合成。
export default {
metadata: {
name: "deep-research",
description: "多来源深度研究 Workflow"
},
stages: [
{
id: "search",
description: "并行搜索官方文档、学术论文和社区讨论",
parallel: true,
agents: [
{
id: "official-docs",
tools: ["web-search"],
prompt: "搜索并整理与主题相关的官方文档"
},
{
id: "academic",
tools: ["web-search"],
prompt: "搜索相关学术论文和技术报告"
},
{
id: "community",
tools: ["web-search"],
prompt: "搜索社区讨论和实战经验"
}
]
},
{
id: "verification",
dependsOn: ["search"],
parallel: false,
agents: [
{
id: "fact-checker",
prompt: "交叉验证搜索结果,标注可信度"
}
]
},
{
id: "synthesis",
dependsOn: ["verification"],
agents: [
{
id: "report-writer",
prompt: "基于验证后的素材合成研究报告"
}
]
}
]
};这个脚本的结构很直观:搜索阶段三个 agent 并行跑,各自负责不同来源;验证阶段串行执行,做交叉核验;合成阶段产出最终报告。每个阶段通过 dependsOn 声明依赖关系,runtime 自动管理执行顺序。
4. 怎么判断该用哪个?
社区总结了一套四步判断法,我觉得挺实用的:
第一步:可拆吗?
任务能不能拆成相对独立的单元?能拆 → 往下看;拆不了 → 直接对话或用 /goal。
第二步:可验吗?
每一步的结果能不能被编译、测试、规则验证?能验 → 适合 Workflows;不能验 → 看看 /goal 行不行。
第三步:可收敛吗?
需不需要通过发现、复核、修正逐步逼近答案?需要 → Workflows 的 Loop 或 /goal 的循环都行。
第四步:值得复用吗?
这个流程以后还会再跑吗?会 → Workflows 写脚本存下来;不会 → /goal 更轻量。
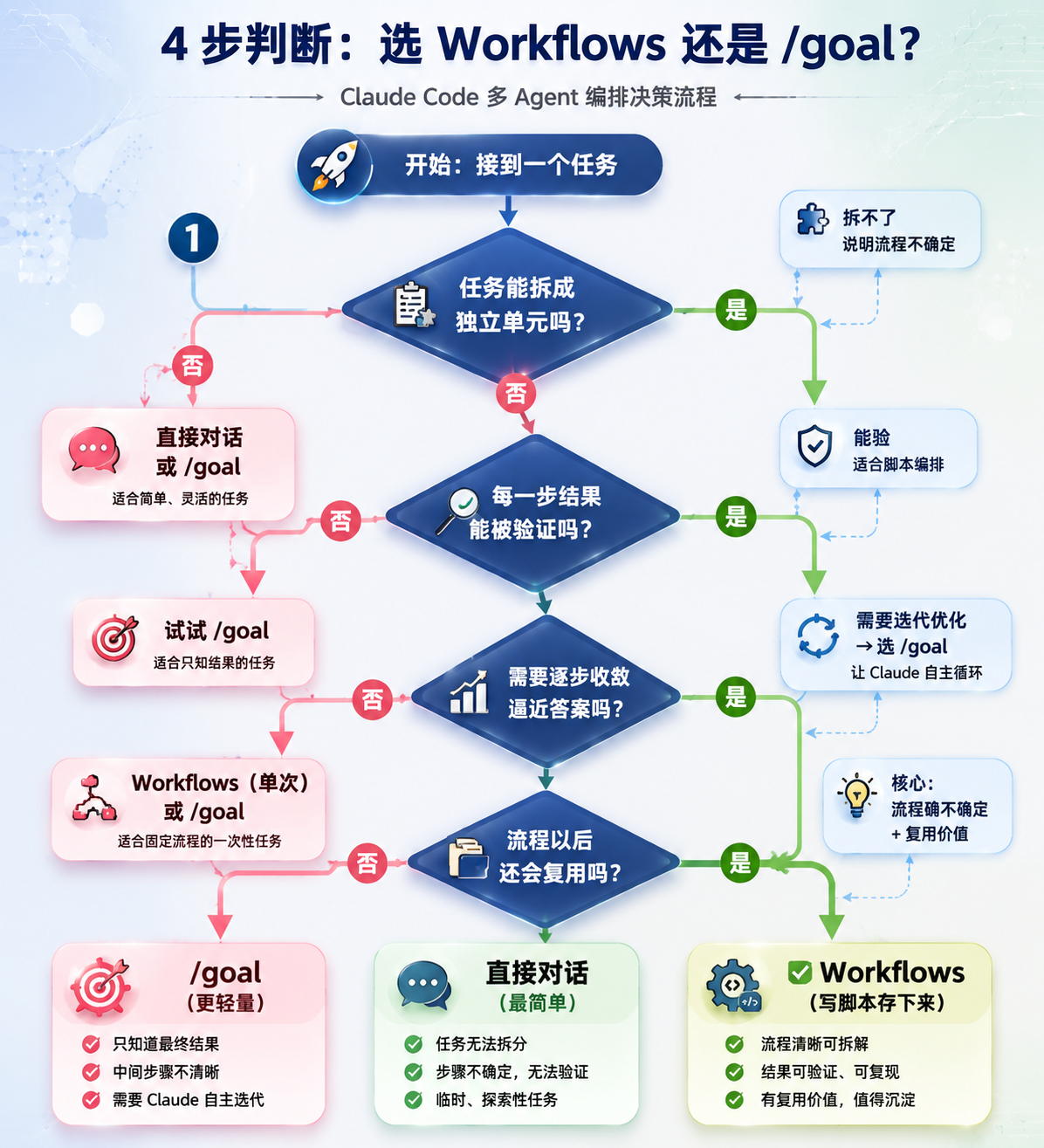
Workflows 与 /goal 场景决策流程图
图 2:四步判断法 — 可拆→可验→可收敛→可复用,三个终点分别对应不同工具
举个具体例子。假设你要把 75 万行代码从 Zig 迁移到 Rust(Bun 项目据说就是这么干的):
- 流程确定:读 Zig → 翻译 → 写 Rust → 跑测试 → 修错误 → 再跑测试
- 结果可验:编译通过、测试通过
- 需要收敛:不可能一次翻译完就全对
- 值得复用:类似的迁移流程以后可能还要用
这就是典型的 Workflows 场景。
但如果你的任务是把某个模块的性能优化到 benchmark 达标,你不知道具体要改什么、改几次,那就更适合 /goal。
5. 协同策略:三个工具怎么搭配用?
实际项目中,Workflows、/goal 和 Auto mode 不需要三选一,完全可以搭配着用。
组合一:Workflows + 内部 /goal
在 Workflow 的某个阶段里用 /goal 式的循环逻辑。比如一个代码巡检 + 自动修复的 Workflow:
- 阶段一(Parallel):多个 subagent 分别扫描安全、性能、可读性问题
- 阶段二(Loop):自动修复发现的问题,直到 lint 和 test 全部通过 ← 这里就是
/goal式的循环 - 阶段三(Pipeline):生成修复报告
组合二:/goal 触发 Workflows
用 /goal 设定一个大目标,让 Claude 自己决定在执行过程中调用 Workflow。适合那种你清楚要什么结果、但实现路径可能很复杂的场景。
组合三:Auto mode 处理审批
Auto mode 的作用是自动审批工具调用(比如允许运行 npm test),它不启动新的轮次,只是让单轮执行更流畅。在长任务的执行过程中开启 Auto mode,可以减少人工介入的频率。
但要注意:Auto mode 不等于无人值守。它只是帮你省掉点同意这一步,不是帮你做判断。
6. 实战最佳实践
写好 /goal 的条件
这是 /goal 能不能跑好的关键。社区总结的三条原则:
- 单一可衡量的最终状态:不要写让代码变好,要写
eslint src/ --max-warnings 0输出无警告 - 明确的验证方式:能用命令输出的就用命令,比如
npm test退出码为 0 - 关键约束条件:加上限制,比如仅修改
test/auth目录下的文件
条件写得越具体,评估模型的判定就越准确。条件写得太模糊,要么提前通过(结果不满意),要么永远不通过(空转烧 token)。
管理好 Workflows 脚本
Workflow 脚本默认存放在临时目录,生命周期只有三天。如果这个流程以后还要用,记得把它复制到 ~/.claude/workflows/ 目录持久化。
脚本也可以纳入版本控制。这一点比纯对话式编排强太多 - 你可以 review、diff、回滚,团队里其他人也能直接复用。
六种编排形态速查
除了前面提到的四种调度形态,社区资料还整理了更完整的六种编排模式:
- 流水线(Pipeline):顺序执行,适合有前后依赖的多步骤任务
- 同步聚合(Parallel Aggregate):并行执行后汇总,适合多源信息收集
- 对抗验证(Adversarial Validation):多个 Agent 互相校验结果,提高准确性
- 提前终止(Early Termination):满足条件就跳过后续阶段,节省资源
- 累积式(Iterative Enhancement):迭代增强,每轮在上一轮基础上改进
- 嵌套式(Nested Workflow):工作流套工作流,适合复杂的多层编排
实际使用中,一个 Workflow 往往不是只用一种形态,而是多个形态组合。比如先 Parallel Aggregate 收集信息,再 Pipeline 逐步处理,最后 Adversarial Validation 交叉验证。
启用和版本要求
# 方式一
export ANTHROPIC_WORKFLOW=1
claude
# 方式二
export CLAUDE_CODE_ENABLE_WORKFLOW=true
claude版本要求:
- 基础 Workflow:Claude Code V2.1.47 或以上
- Dynamic Workflows 完整功能:V2.1.154 或以上
触发关键词是 ultra work。
上下文管理的心法
不管用哪种工具,上下文管理都是核心战场。社区反馈里几条被反复提到的经验:
- CLAUDE.md 不超过 150 行 - 太长反而抓不住重点
- 上下文用了 50% 左右就该执行 compact - 别等到满了再压缩
- 不相关的工作流分开项目 - 避免上下文污染
- 完成一个任务就立刻提交代码 - 别攒着
这些不完全是 Workflows 或 /goal 的专属建议,但用多 Agent 编排时格外重要 - 信息量大了,上下文更容易崩。
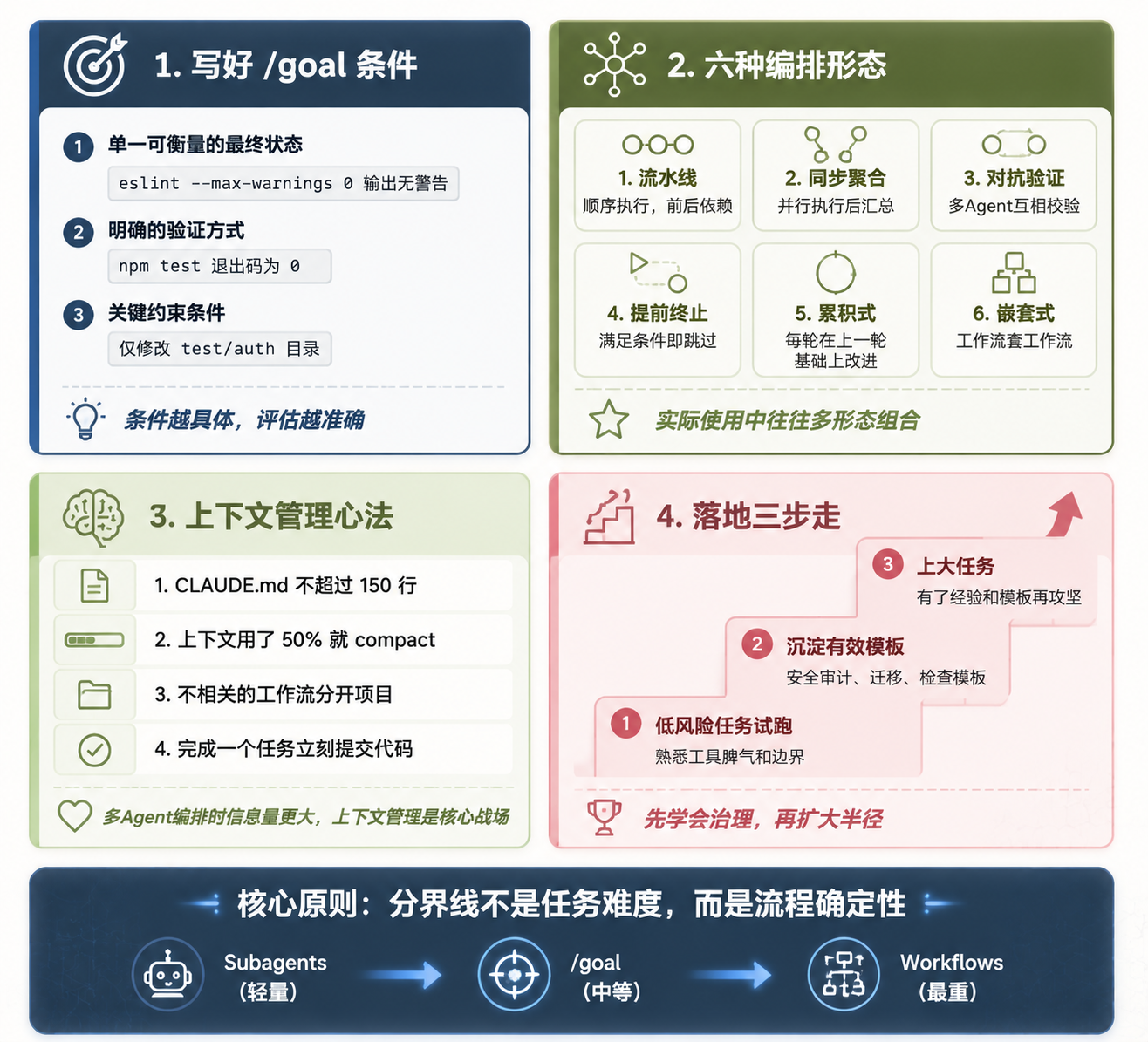
Claude Code 多 Agent 编排最佳实践总结
图 3:多 Agent 编排最佳实践 — /goal 条件三原则、六种编排形态、上下文管理心法、落地三步走
7. 常见误区
整理社区讨论的时候,有几个坑大家踩得比较集中。
误区一:验收条件写不好
这是 /goal 新手常见的坑。条件写得太宽泛,比如代码质量达到生产级别,评估模型根本没法判断。结果要么早早通过,要么无限循环。
解法:条件里一定要有可量化、可验证的终点。命令退出码、测试覆盖率数字、lint 输出内容,这些是好的验收标准。代码看起来不错不是。
误区二:不该自动化时硬上
不是所有任务都适合 Workflows 或 /goal。支付逻辑、安全策略、权限模型这类高风险代码,直接让 Agent 自动改是很危险的。社区也有人提到,需要频繁中途拍板的探索任务也不适合完全自动化。
解法:高风险任务拆成小步,每步人工确认。或者用 Workflows 的校验阶段,关键节点暂停等人审批。注意,Workflow 运行中不接受普通人工输入,所以需要签核的任务应该拆成多个 workflow。
误区三:token 成本失控
多 Agent 编排的 token 消耗会比普通对话明显高出不少。每个 subagent 都是独立的模型调用,16 个并发就是 16 倍的消耗。虽然 Haiku 评估模型的消耗很低,但主模型的消耗是实打实的。
解法:
- 先在低风险任务上试跑,观察实际消耗
- Loop 类任务一定要设好终止条件
- 不是非得 16 并发的就少开几个 agent
- 对于探索性任务,先用普通对话试一轮,确定方向后再上 Workflow
误区四:上下文管理不当
用了 Workflows 就不管上下文了?不是。Workflow 解决的是编排过程中的上下文卸载,但不等于你可以无限堆任务。单次运行最多 1000 个 agent,跨会话不可恢复 - 退出后不能原地续跑。
解法:大任务拆成多个 workflow。每个 workflow 聚焦一个明确的子目标,跑完看结果再决定下一步。
8. 落地建议:先治理,再扩大
如果你准备在项目里开始用 Workflows 和 /goal,社区建议的落地路径是分三步走:
第一步:低风险任务试跑
用 /deep-research 做信息收集,或者用 Workflow 做小范围的代码巡检。这些任务风险低,即使结果不理想也不会破坏什么。主要目的是熟悉工具的脾气和边界。
第二步:沉淀有效模板
跑了几次之后,把确实有效的流程沉淀成 Workflow 模板。安全审计模板、release 检查模板、代码迁移模板 - 这些都是可以在团队里共享的。
第三步:上大任务
有了经验和模板之后,再把大迁移、大审计这类任务交给 Workflow。这时候你对工具的边界、token 消耗、常见坑点都有体感了,出问题的概率小很多。
你在项目中用过 Workflows 或 /goal 吗?体验如何?欢迎在评论区聊聊实际踩过的坑。
总结
说到底,Claude Code 的多 Agent 编排给了开发者三种不同粒度的工具:
- Subagents:最轻量,适合临时派发
/goal:中等,适合我知道终点但不知道路径的自主循环- Workflows:最重,适合流程确定、需要编排和复用的大规模任务
选哪个不取决于任务大小,而取决于你对流程的确定程度。流程确定 → Workflows;终点确定但路径不确定 → /goal;都不确定 → 先用普通对话探索。
别急着把所有任务都自动化。先用好基础能力,再逐步引入编排工具。先学会治理,再扩大半径。
相关资源
Claude Code 官方文档:https://docs.anthropic.com/en/docs/claude-code
Claude Code GitHub 仓库:https://github.com/anthropics/claude-code
好啦,谢谢你观看我的文章,如果喜欢可以点赞转发给需要的朋友,我们下一期再见!敬请期待!
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号