漫谈AI推理与存储


AI存储核心需求
模型权重
LLM模型权重是AI推理最基础的持久化存储数据,核心特征为一次写入、多次读取。模型权重文件从网络下载完成后,几乎不会修改,后续无论是业务服务启动、日常推理运行,还是工程人员调试测试,都是读取操作。
在推理引擎启动阶段,系统需要将完整的模型权重读取加载至GPU显存,GPU才能开展后续的运算推理工作。这一加载过程会直接影响业务可用性,若读取速度过慢,会产生严重的业务启动延迟,行业典型场景中延迟甚至可达二三十分钟;同时,多实例、多服务同时启动时,大规模的权重加载请求会引发启动风暴,挤占系统IO与网络资源,导致整体服务启动效率大幅下降。
LLM模型权重文件具备典型的超大文件特性,存储量级极高。以DeepSeek-V4-Pro模型为例,其单份safetensors权重文件大小为14GB,整体模型包含64个这样的文件,整体存储体量巨大,对存储的吞吐能力与稳定性要求很高。
为优化启动加载效率,当前推理引擎采用mmap机制进行优化。多TP工作进程(TP worker)可通过mmap共享映射模式,将权重文件仅一次加载至内核的Page Cache中,各工作进程按需将自身所需的权重片段复制到对应GPU显存,规避了传统模式下单机器多显卡重复读取完整文件的问题(如8卡机器最差场景需重复读取8次完整文件)。但该优化方式存在局限性,FUSE文件系统会对mmap机制产生限制,无法适配该优化方案。
KV Cache存储布局与特性
KV Cache是大模型推理过程中产生的核心临时数据,用于存储上下文的键值对信息,避免重复计算,大幅提升推理效率。其在GPU中的分配遵循Paged Attention布局,整体分布较为离散。
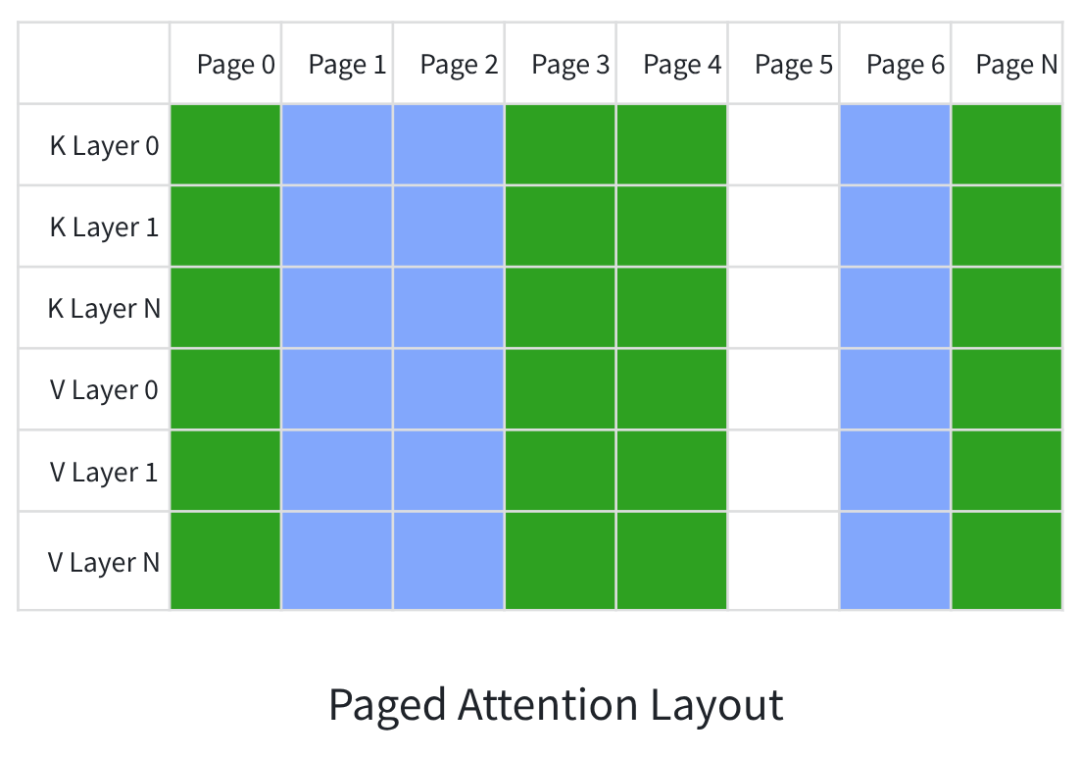
从结构来看,大模型包含数十层网络Layer,分为K Layer 0、K Layer 1到K Layer N与V Layer 0、V Layer 1到V Layer N;同时显存被划分为多个独立Page(Page 0、Page 1至Page N)。不同会话可能共享使用相同的Page,也可能单独使用不同的Page,绿色代表一个会话占用显存、蓝色代表另一个会话占用显存、白色为空闲显存,整体呈现随机离散分配特征,概率性出现连续分布。就实际的测试来看,推理引擎启动的早期阶段,比较容易分配到比较连续的Page,运行一段时间之后,就低概率分配到连续的Page,这里和Linux内核的内存分配上有一定的相似性,这也是分页式的内存管理方法的常见问题。
KV Cache两种主流外部存储布局
将GPU内的Paged Attention数据搬运至外部存储时,主要采用两种布局方式,且两种方式均需进行额外的数据复制(优化的方向之一也是通过技术优化规避数据拷贝,实现数据高效迁移),以上图的绿色会话为例:

一是Layer First Layout(层优先布局),完全对齐GPU内部数据维度,将所有网络Layer的同层数据连续存放,贴合GPU原生运算逻辑:不需要做shape变化,但是需要将离散的数据块和连续的文件之间进行数据的搬运。
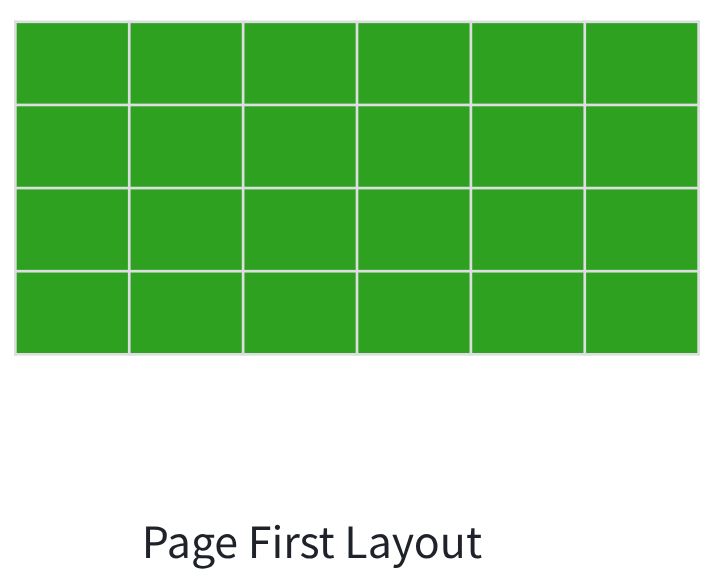
二是Page First Layout(页优先布局),将一个(或者多个)Page的所有数据连续存放。由于Page数据可支持多会话共享,这个布局是多会话共享场景下的更优选择:需要做shape变化,仍然需要将离散的数据块和连续的文件之间进行数据的搬运。
KV Cache核心特性
首先是数据形态离散,以大量小块数据为主,数据块数量极其庞大。单Page可存放一定数量的Token(常见16个或64个,受共享效率约束),目前主流旗舰模型普遍支持1M上下文长度,结合Page尺寸与模型层数计算,数据块的数量会增长到相当庞大的规模;另外,KV Cache具备可重计算特性,数据丢失后可通过上下文重新生成,无需永久持久化(至少经典的三副本强一致性不再是必选项)。
KV Cache哈希管理方案
基于哈希的KV Cache管理
这个方案是当前业界通用主流方案,示意图如下:
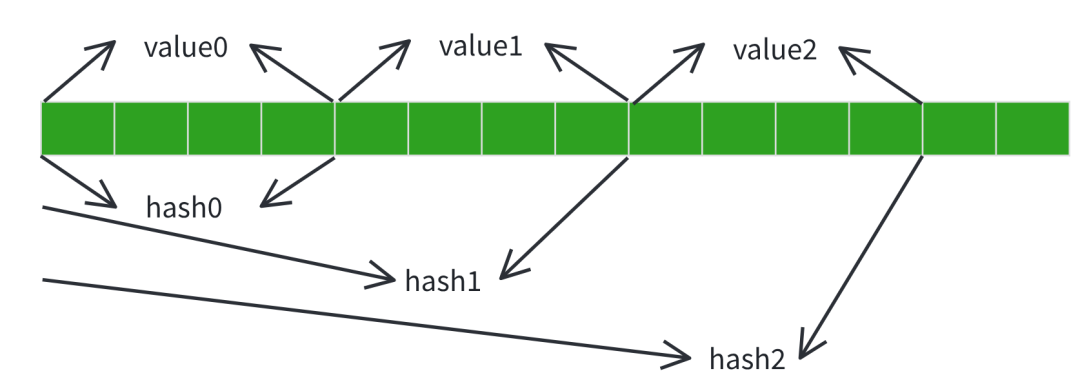
核心逻辑为按固定长度截取Token序列,示例图中每4个Token为一组,计算每组Token序列的哈希值作为唯一Key,对应的KV Cache数据作为Value,形成键值映射关系。即token0~3对应hash0-value0、token4~7对应hash1-value1,以此类推。
该方式下,KV Cache存储数量与Token序列长度成正比,超长上下文场景会消耗大量存储资源。方案优势是逻辑简单、落地便捷,推理引擎仅需通过哈希计算即可完成缓存匹配调用;但核心短板在于性能与成本不可预期。Prompt中的缓存Key处于隐藏状态,请求未到达推理引擎前,无法精准判断缓存命中率与资源消耗成本,仅SGLang Gateway等少数工具可实现部分预测,无法覆盖全场景。
KV Cache显式共享管理方案
显式共享管理是我们(张量跃迁)提出来的创新方案,目前处于开发迭代阶段并持续向vllm/sglang社区推送。

该方式以文件为单位管理会话数据,单轮完整会话(Token 0至Token N)对应存储文件,N轮会话最少仅需1个文件(支持文件追加写入),最多对应N个独立文件。一个例子如下,"stored_kv_cache"记录了已经缓存的KV Cache对应的Token位置、长度和对应的文件路径、位置和长度,"fresh_kv_cache"是即将生成的KV Cache需要写到的文件路径、位置和长度:
"stored_kv_cache": [{
"token_start": 0,
"token_length": 8192,
"kv_uri": "gd2fs://cluster-01/session-97f1226c-..."
"kv_start": 0,
"kv_length": 134217728
}],
"fresh_kv_cache": [{
"token_start": 8192,
"token_length": 8192,
"kv_uri": "gd2fs://cluster-01/session-97f1226c-..."
"kv_start": 134217728,
"kv_length": 134217728
}]
相较于哈希管理方式,显式共享管理的使用复杂度更高,需要分布式调度器统一管理会话与存储文件的映射关系,天生适配分布式部署场景,可实现KV Cache精准显式共享。例如多个会话复用同一系统提示词文件file0,后续各自独立生成file1、file2,即可完成公共缓存数据的高效共享。值得说明的是,存储用户的会话ID、时间、KV Cache信息等格式化数据,对于当前的关系型数据库来说并不算困难。
其核心优势是实现Prompt与KV Cache元信息分离,请求到达分布式调度器时,即可精准预判缓存命中率、to prefill的Token数量、to decode的Token数量,实现推理性能与资源成本的可预期、可管控。
KV Cache存储诉求、延迟与成本痛点
综合两种KV Cache管理方式,AI推理场景对存储的核心诉求可总结为三点:容量大、数量多、分布式高效调度。两种组织方式均会生成大量KV存储与存储文件(尽管文件会比KV存储少,但是依然量级很大),依托分布式架构可大幅提升缓存共享效率与GPU调度利用率。同时KV Cache单实例容量可达GB级甚至更大,对读写延迟极其敏感:
读取延迟过高会产生GPU计算气泡(GPU空闲等待数据),打断推理连续性,直接降低用户体验;写入延迟过高会导致缓存数据无法快速从GPU导出,显存长期被占用,大幅降低整体推理吞吐能力。
成本层面存在显著的存储介质价差:单位容量DDR内存成本是NVMe固态硬盘的30-100倍,行业普遍价差约50倍。结合KV Cache可重计算的特性,其数据无需强制持久化存储,但存储分层架构具备极高必要性,可借助NVMe的大容量优势降低整体存储成本。同时,传统存储的三副本强一致性机制对于KV Cache场景不再必要,反而会增加存储开销、成为性能负担。
熟悉存储和FIO的朋友们可能会有经验,执行FIO测试的时候,bs(单个请求的块大小)和IO depth(inflight IO请求的数量,即IO最大并发数)在测试IOPS和bandwidth的场景下是不同的参数,测试IOPS时使用4K,测试bandwidth时使用256K或者更大。然而在LLM的KV Cache场景下,是bs较小、IO depth很深的条件下,还需要保证bandwidth很高。因此我们就需要面对整个存储/分布式存储历史上最难解决的问题之一:大量的、离散的小块数据组成了GB级的数据,又要求很低的延迟。
存储栈与单机、分布式优化
单机存储优化方案
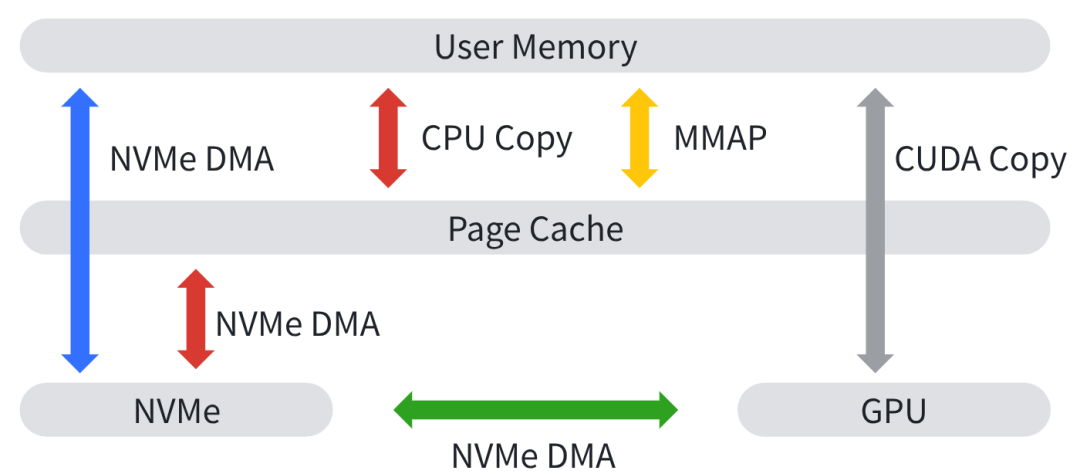
在单机本地存储场景中,NVMe与GPU之间的数据传输存在多条路径,不同路径的性能、适配场景与限制差异极大,整体优化核心思路为缩短数据传输路径、减少数据拷贝次数,路径越精简,性能越优异,但通用性越弱、限制条件越多。各传输路径特性如下:
1. 绿色(GPU Direct Storage,GDS):理论性能最优路径。实现NVMe与GPU之间的PCIe P2P直接传输,无需CPU中转。需安装NVIDIA的驱动,通过ioctl接口触发传输,适配大块数据场景,有一些性能优势;但限制条件较多,要求数据Block Size严格对齐,小块数据场景依赖IOPS性能,且ioctl是同步调用,在小块IO场景下会产生负优化。GDS在实际的工程实现上(参考https://github.com/NVIDIA/gds-nvidia-fs),既Hack又Trick(工程师真的很天才,去Hook内核块层的DMA操作,能够把GPU的MEM正确设置到NVMe的驱动中,NVMe设备直接完成数据和GPU MEM之间的DMA),难以发挥的地方就在于存储设备太慢的同时使用要求又多,在已知的范围内,并没有听说太多的实际业务应用。尤其是在LLM场景下(见上文数据从GPU Memory中的Paged attention布局到Layer First/Page First都需要做数据的变换),GDS只能发生在per Layer级别的小块数据上,这对NVMe的性能来说是很乏力的,Linux 6.17开始支持Block Layer的P2P,理论上可以更好地支持这个场景,具体效果还要看整业界的尝试和演进;最有潜力的场景是模型权重从NVMe加载到GPU,遗憾的是,safetensors格式并没有block size对齐的保证,就目前的情况来看,是不能直接使用的。这里的观点仅适用于LLM推理场景,其他场景不在讨论的范围内。
2. 蓝色(Direct IO):NVMe直接IO传输,无需经过系统缓存,要求数据Block Size对齐,不支持跨进程数据共享,适配固定块大小的批量数据传输场景。
3. 黄色(Page Cache + mmap):通过文件映射实现数据传输,支持跨进程共享数据,通用性较强。但在KV Cache场景下适配性并不理想。KV Cache数据线性增长,需要频繁调用mremap调整内存映射空间。抛开性能开销不谈,这种使用方式本身也不够自然。
4. 红色(传统拷贝):性能最差,需经过多次用户态、内核态数据拷贝,但通用性最强,适配所有场景,这一点在Python主导的AI推理生态中尤其重要。大内存服务器(典型如2TB)场景下,内存回收的效率是一个很大的问题:内核线程在大范围内扫描内存页面的效率是一个比较大的问题。
分布式存储性能层级
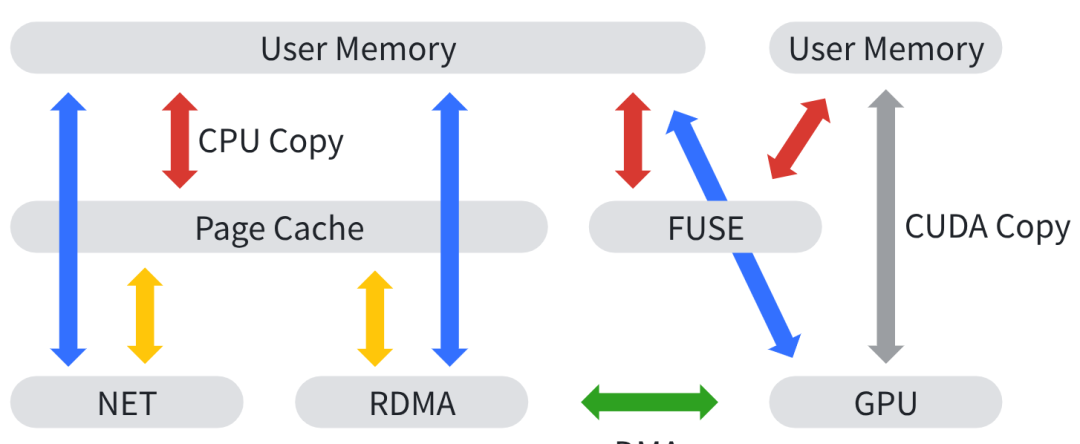
分布式场景下,数据传输依托以太网或RDMA网络实现,从存储设备到GPU的数据路径分为四个层级,优化逻辑与单机一致,核心是精简IO路径、减少数据拷贝,差异仅在于数据操作发生在用户态或内核态:
1. 绿色(GPU Direct RDMA):分布式场景理论最优性能路径,以GDR为核心,数据在GPU显存和网卡之间直接传输,无需CPU侧内存中转。同样都是GPU Direct技术,但是GDR对比GDS有一些几个比较的差异点:存储栈有状态,涉及Page Cache、文件系统的元数据组织和Block Size对齐IO等,Direct技术在越复杂的约束下发挥的空间越小;而RDMA仅仅一块空间通过网络进行发送和读取。另外就是块设备和VFS工作在内核态,一般都是用户的Read/Write/Ioctl请求通过内核转义成“issue IO”和“wait completion”的块层语义,但是RDMA的verbs请求则可以在内核态用用户态都能触发,也就是说GDR比GDS更容易在用户态使用、并完成更加复杂的语义。目前GDS在内核态已部分支持该能力(例如NFS、WEKAFS等),也有在用户态实现的存储方案(例如下文的GD2FS)。
2. 蓝色(用户态文件系统):以libnfs、libcephfs为代表,数据通过网络读取至用户态内存后,再拷贝至GPU显存,规避了内核态数据拷贝开销,性能居中。
3. 黄色(内核态文件系统):以NFS、SMB为代表,支持Page Cache,再拷贝至用户态内存,最终传输至GPU,多级拷贝导致性能损耗较大。
4. 红色(FUSE文件系统):性能最差,用户态的Daemon进程与内核态频繁交互产生大量开销,但具备极强的通用性,适配各类分布式存储场景。
分布式存储协议与主流软件对比
分布式块协议(iSCSI和NVMe-oF)
iSCSI和NVMe-oF是最流行的分布式块存储协议,它们的主要对比如下:
维度 | iSCSI | NVMe-oF |
|---|---|---|
Queue | 单队列,多核性能受限 | 1个 ADMIN Queue + 多个 IO Queue,充分发挥多核多队列能力 |
Target(服务端) | LIO (kernel)TGT (user)SPDK (user) | NVMe Target (kernel)SPDK (user) |
Initiator(客户端) | iSCSI drv (kernel)libiscsi (user) | NVMe drv (kernel)libnvmf (user) |
这两种协议在生态上比较接近,都得到了Linux内核、用户态库和SPDK的支持,它们的主要差异体现在多队列的并发能力上:
- iSCSI为传统单队列设计,多核场景下性能受限,TCP环境下单核仅能实现50-60K IOPS。SCSI/iSCSI的设计受限于其诞生年代的硬件条件和并发规模,这些限制更多是历史背景的映射。但是在今天性能要求不那么高的场景下,依然有不错的发挥空间。例如QEMU提供Virtio Block块设备服务给虚拟机使用,并绑定一个IO线程,结合后端驱动libiscsi,则可以在单一的IO线程下跑出来不错的性能,也非常容易实现IO线程和虚拟化线程之间的性能隔离。
- NVMe-oF为现代化架构,采用「1个管理队列(ADMIN Queue)+ 多个IO队列」设计,可充分发挥多核、多队列硬件性能,吞吐与并发能力更强。即使使用TCP,也依然可以发挥多核并行的能力,完全发挥块设备的性能。
在Target实现上,LIO和SPDK,以及NVMe Target和SPDK对比,存在一定的性能上的差异,但是用法上没有态大差异。TGT虽然性能最差,但是由于后端支持glusterfs这样的分布式存储,那么的使用场景上就多了一种可能。
整体来看,分布式块协议存在天然短板:
- 块协议本身过于原始,仅仅提供了一个固定大小的IO地址的随机访问能力,且需要block size对齐。高级的文件管理能力需额外搭配文件系统完成数据组织
- 虽支持Persistent Reservations持久化预留机制,但数据共享能力薄弱(如GFS2存在严格的共享数量限制)
- 无原生集群模式,单卷存储容量存在上限,无法适配大模型大量数据存储需求
如果需要使用libiscsi的iSER(iSCSI Extensions for RDMA,即iSCSI的RDMA支持)的话,推荐自主编译最新的libiscsi源代码
https://github.com/sahlberg/libiscsi我(皮振伟)和字节跳动的同事在2019-2023年陆续修复了约50个Patch,其中部分会影响业务的正确运行,修复过的代码经历过实际的业务验证。同时,libnvmf
https://github.com/bytedance/libnvmf是我和同事在字节跳动工作期间开发,在虚拟化场景下,QEMU的单盘使用TCP性能突破200K IOPS,也经历过业务验证。
NVMe-oF/RDMA I/O传输机制
iSER协议和NVMe-oF协议在数据传输机制上比较接近,但是NVMe-oF协议更加现代化,这里以NVMe-oF协议为例子:
- Initiator和Target在Admin Queue连接成功后,Initiator执行Identify命令查询Target支持的最大的In Capsule Data Length
- 小于In Capsule Data Length的小块数据场景:Initiator通过RDMA Send一次性发送NVMe命令和In Capsule Data,仅需1次网络RTT
- 大于In Capsule Data Length的大块数据场景:Initiator仅发送NVMe命令。对于写命令通,Target通过RDMA Read从Initiator读取数据;对于读命令,Target通过RDMA Write向Initiator写入数据。
- 数据传输完成后,Target通过RDMA Send发送完成NVMe Completion,IO完成。
在整个数据传输的过程中,传输效率发挥到极致;同时,RDMA的Read/Write是在Target端发起,而非让Target暴露地址空间给Initiator,完全避免了安全问题:Initiator写错了呢?Initiator恶意访问?
有幸参与过NVMe-oF的内核贡献,在这个过程中逐渐熟悉了这个协议。从个人视角而言,NVMe-oF协议是存储系统与网络技术深度融合的杰出范例,极具美感,是计算机发展历程中的宝藏。
部署模式

直连模式为Initiator与Target直接通信,链路最短、性能最优;
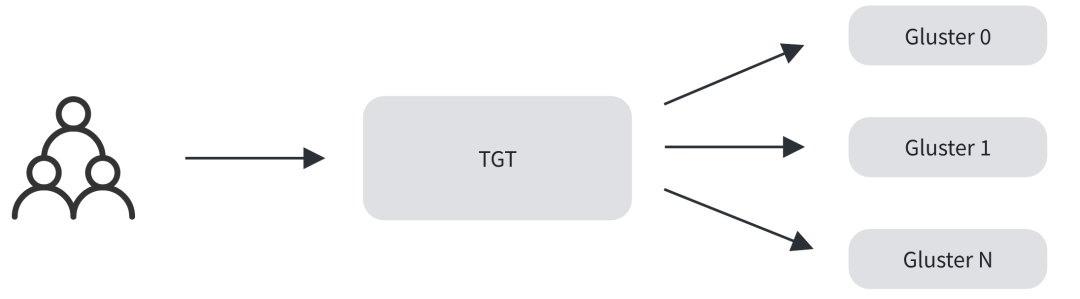
网关模式通过TGT后端对接GlusterFS等集群,由TGT完成协议转换,适配集群存储,但延迟较高,不适合对延迟敏感的KV Cache推理场景。
Redis/Valkey Over RDMA
RESP3协议
流式协议,Hello World报文示例:
*3\r\n3\r\nSET\r\n5\r\nHello\r\n
\r\n是分隔符,*3是3个参数,$3是后续的参数长度是3个字符。很容易知道,要想解释这段协议,需要CPU解析出来全部的内容;同时,这个报文是不定长度的,尤其是Key和Value,都是可长可短的。
基于RESP3流式协议,对TCP非常友好,但对于RDMA协议并不友好,因为RDMA协议是面向消息的,在数据传输之前需要提前注册内存,那么:
- 如果使用Receive buffer来接收消息,那么多大比较合适?例如GET KEY,无法预测即将返回的VALUE长度,必然不希望在RDMA场景下对消息的长度带来任何限制。
- 如果使用Receive buffer来接收消息,那么多少个Receive buffer比较合适呢?例如INFO命令可能会返回多个数据片段,COMMAND命令可能返回数百个数据片段。
- 如果使用一个Receive buffer接收消息,在接收到消息后回复ACK,并请求接下来的数据,可以节省Receive buffer,但是带来了额外的RTT开销。例如:Redis/Valkey一次传输*1\r\n4\r\nPING\r\n,或者分成3次传输*1\r\n,4\r\n,PING\r\n是等价的,但是在RDMA需要3次完整的RTT。

因此使用一块稍大的内存模拟Stream Buffer,用来传输网络数据;因此网络层与业务层之间仍存在数据的复制开销。性能测试显示:1K小报文场景下QPS可提升250%,64K大报文场景性能与原生TCP基本持平。
同时,Redis/Valkey为纯内存存储,仅支持基础持久化,不支持存储分层架构,无法借助NVMe扩展大容量存储。Redis/Valkey的设计哲学是纯内存极速访问,分层存储本不在其原始目标内,社区中关于分层的讨论也有过,基本都是没太多下文,参考
https://github.com/valkey-io/valkey/issues/83在经典的数据中心业务中,Redis/Valkey是最流行的KV存储,还扮演着重要角色。Valkey Over RDMA在电商秒杀等高并发场景下还有一定的业务价值,我是Valkey Over RDMA的作者,遇到问题请在社区联系我(Github ID:pizhenwei)。
集群模式
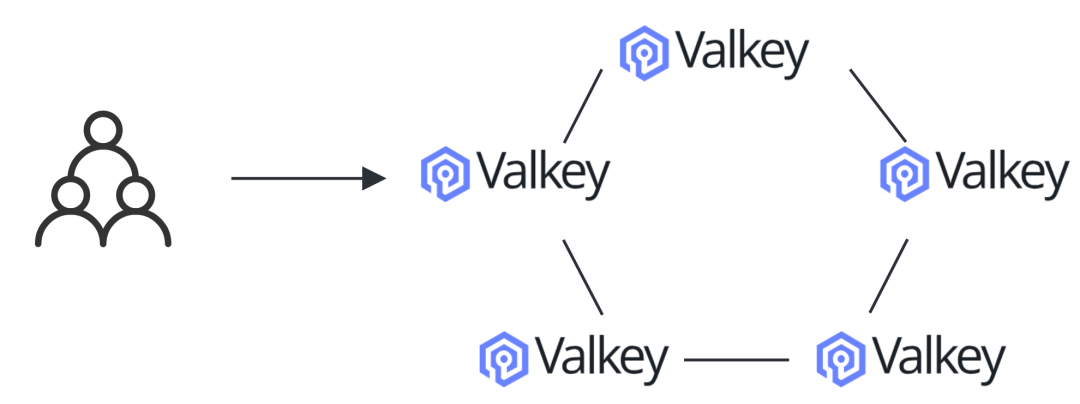
基于一致性哈希管理slot与节点,网络可实现一跳直达,但节点间依赖GOSSIP协议同步信息,大规模集群场景下协议收敛速度慢。在2025年底,国内第一次举办的Valkey Keyspace上,来自字节的同学分享了去GOSSIP的中心化集群控制,阿里云的同学也做了问题的确认。
对象存储协议(S3)
S3是主流对象存储协议,基于流式架构设计,TCP网络适配性极佳,具备显著的成本优势,适合海量冷数据、模型权重归档存储。一个S3请求、响应的例子:
S3协议示例,请求:
GET /my-data HTTP/1.1
...
响应:
HTTP/1.1 200 OK
...
Content-Length: 32768
[BINARY DATA]业界多数的对象存储产品不支持RDMA,仅有少数企业级产品尝试适配。核心问题和Vakley Over RDMA类似:不定长数据在定长的RDMA的消息语义下需要做出一定的性能牺牲,或者在内存使用率上做出牺牲。同时也不再是标准的HTTP协议,做了适用性的牺牲。
Mooncake Store存储方案
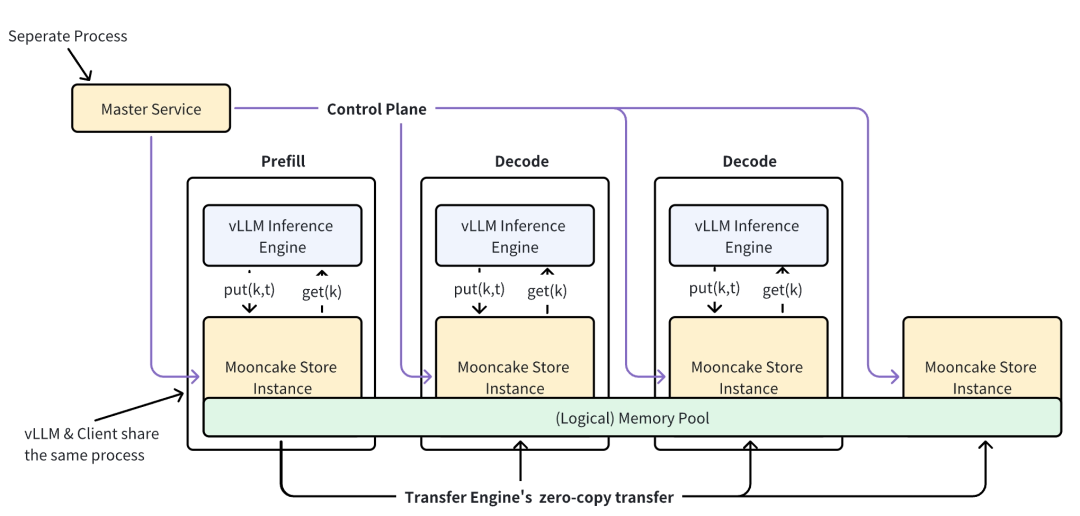
Mooncake Store采用分布式内存池架构,集群内所有节点同时作为内存使用方与资源提供方,构建统一共享存储池。架构上通过Master Service统一管理元信息,支持高可用(HA)部署;数据访问采用「先RPC查询元信息、再RDMA直连访问数据」的模式,Data Plane的性能优异,但是Master Service可能会成为性能短板。支持数据持久化,但同样不支持存储分层,无法适配低成本大容量存储场景。
在Mooncake Store传输协议上,也值得去探讨。例如PUT操作,需要执行RPC请求Master Service为各个Replica分配内存空间,分配成功后RPC返回相应的endpoint、地址和长度,client执行RDMA WRITE写入对象。在这个过程中,被写入数据的节点不感知,也无法校验参数的准确性:地址和长度都是符合预期的吗?协议上允许内存池中的各个节点有写入权限,如果程序出现逻辑BUG呢?和iSER/NVMe-OF的协议设计对比,这里有明显的不同。
Mooncake Store对KV的支持也是一个值得讨论的地方,在上文我们提到,KV存储语义上不定长,这是在RDMA上表现最挣扎的地方。Mooncake Store执行GET的过程中,执行RPC请求从Master Service获取对象对应的长度,如果用户提供的Buffer长度小于对象的长度,直接返回失败,不会进行网络IO。这个方法相对简单、粗暴,在KV Cache场景下的KV大小是可预期的固定长度,因此在当前的用法下是可以工作的。从个人视角而言,Mooncake Store并非是传统意义上的KV存储,GET/SET在语义上是不完整的。但就hash based KV Cache管理方案而言,它能够满足需求,所以它是现阶段合适的。
GD2FS分布式文件系统与推理实践
基于上述的LLM KV Cache的需求和一些流行的存储服务的特点,我们尝试面向GPU为中心的系统架构设计全新的分布式存储服务,探索更多的可能。在此抛砖引玉,欢迎探讨。
GD2FS核心设计理念
GD2FS全称为GPU Direct Distributed File System,是适配AI推理场景自研的专属分布式文件系统,核心设计理念为深度融合GPU加速技术与高速网络能力,最大化精简数据传输路径。GD2FS原生支持GPU Direct RDMA高速传输,在实际的实现中,客户端实现了上文中分布式存储性能层级的最佳路径(即前文《分布式存储性能层级》中的绿色方案 -- 用户态的GDR方案);同时,在服务端也实现了完全的zero copy。同时兼容TCP多网卡、多流并发传输,用于兼容一些老旧的GPU和网络环境。
部署架构采用分层存储设计,区分高可用存储池(3副本)与高性能存储池(1副本),将副本策略与缓存机制解耦,兼顾可用性与性能、成本平衡;采用中心化管理架构,摒弃GOSSIP协议,解决大规模集群收敛慢、稳定性差的问题。
GD2FS性能实测数据
测试环境:INTEL(R) PLATINUM 8563C CPU、NVIDIA H20 96GB GPU、Mellanox CX7 400Gbps网卡、INTEL企业级SSD,实测性能如下:
传输方式 | 读写类型 | 64M(平均us) | 256M(平均us) | 1G(平均us) |
|---|---|---|---|---|
RDMA-GPU直连 | 读 | 1529 | 5938 | 23601 |
写 | 4400 | 9975 | 35774 | |
TCP-DDR传输 | 读 | 4249 | 16673 | 67280 |
写 | 10654 | 36757 | 123187 |
从实测数据可明显看出,RDMA+GPU直连模式的读写性能和400G网卡的理论性能接近,这也验证了存储栈上最短路径无数据复制的性能。TCP传输上,1G文件读写延迟约为RDMA模式的3倍左右,但是绝对值依然可观,在百毫秒这个量级上实现了GB级数据的传输。
基于GD2FS的AI推理架构
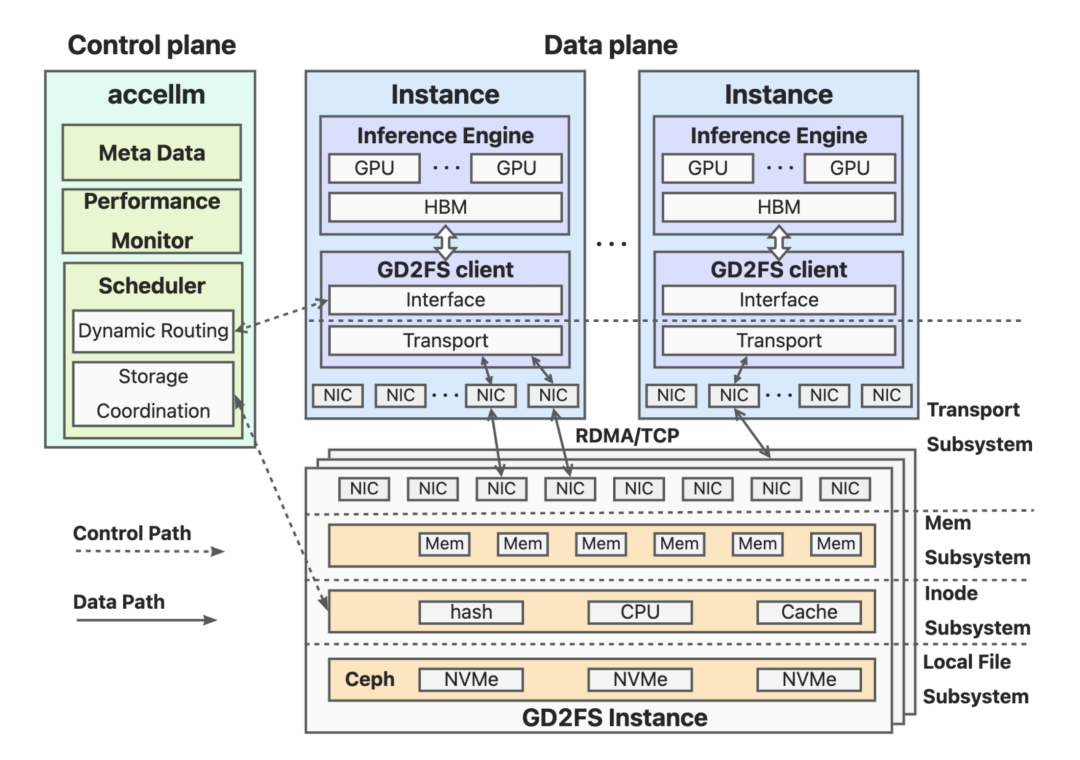
基于GD2FS构建的LLM推理协同架构,核心是重塑端到端的AI推理链路,打破传统推理引擎、存储、调度系统的割裂状态。AI推理是典型的系统性工程,性能优化不能局限于单一模块,需实现存储、推理、调度的全局协同。
该架构的核心革新点为:打通GPU与分布式存储的直连通道,实现GPU直接访问远端存储数据,彻底规避CPU、内存的中转拷贝开销,结合GD2FS的高速分布式传输能力、灵活的存储分层与副本策略,全面解决大模型推理的启动延迟、缓存吞吐、存储成本、资源调度等核心痛点,为超长上下文、高并发、大规模AI推理场景提供底层支撑。进一步完整支持GPU的无状态化推理,大幅提升GPU的利用率和推理效率。
联系我们:support@tensorfer.com
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-05,如有侵权请联系 cloudcommunity@tencent.com 删除
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号