别再凭感觉调Prompt了:Eval驱动开发,AI工程化的TDD时刻

别再凭感觉调Prompt了:Eval驱动开发,AI工程化的TDD时刻

老周聊架构
发布于 2026-06-05 20:23:28
发布于 2026-06-05 20:23:28
你改了一版Prompt,跑了一个Case,输出看起来不错,于是你上线了。三天后用户投诉,你又改了一版,跑了同一个Case,"嗯这次好多了",又上线了。一周后另一批用户投诉。你在做工程吗?不,你在扔骰子。
先问一个灵魂拷问:
你的LLM应用,有"测试套件"吗?
不是那种跑一个Case看看输出"感觉对"的人肉验证,而是一个可以自动运行、自动打分、每次Prompt改动都跑一遍的评测集?
如果没有——你和2005年那些不写单测、靠手动点点点验证的程序员,本质上没有区别。
今天聊一个我认为是AI工程化里最重要、也最被低估的实践——Eval驱动开发(Eval-Driven Development)。
用人话说:传统软件的质量保障是TDD(测试驱动开发),AI应用的质量保障是EDD(评测驱动开发)。没有评测集就优化Prompt,跟没有地基就盖楼一样——迟早塌。
一、为什么LLM应用不能用传统测试?
1.1 确定性 vs 概率性
传统软件测试的核心假设是确定性——同样的输入,必须产生同样的输出。
1 // 传统单测:确定性
2 assert(add(1, 2) === 3); // 永远为真LLM的输出是概率性的——同样的Prompt,十次可能给你八种不同的回答。
1 // LLM__STR0__:概率性
2 assert(llm("法国的首都是哪里?") === "巴黎");
3 // 可能通过,也可能回答__STR0__"跑通一次"在传统软件里能说明问题,在LLM应用里毫无意义。
1.2 失败模式完全不同
维度 | 传统软件 | LLM应用 |
|---|---|---|
输出类型 | 确定性 | 概率性 |
失败模式 | 崩溃/报错(显性) | 胡说八道(隐性) |
回归检测 | 单测自动发现 | 不跑评测根本不知道 |
改动影响 | 局部可控 | 改一个词全局雪崩 |
"通过"标准 | 对/错二值 | 好/坏连续谱 |
最后一条是关键:传统测试的结果是布尔值——通过或不通过。LLM评测的结果是分数——4.2分还是3.8分。
这就好比你以前考试是"对勾或叉",现在变成了"主观题打分"。评卷标准不统一,你连自己是进步还是退步都不知道。
二、Eval驱动开发:AI时代的TDD
2.1 什么是Eval驱动开发?
一句话:先建评测集,再迭代Prompt/模型/检索,每次改动都拿评测集回归。

环节 | TDD(传统软件) | EDD(AI应用) |
|---|---|---|
第一步 | 先写测试用例 | 先建评测数据集 |
第二步 | 写代码让测试通过 | 写Prompt/调模型让评测分数上升 |
第三步 | 重构,确保测试仍通过 | 优化,确保评测不回归 |
核心纪律 | 不写测试不写代码 | 不建评测集不优化Prompt |
度量方式 | 通过率100% | 评测分数≥阈值 |
回归保护 | CI/CD自动跑测试 | CI/CD自动跑评测 |
这个类比非常精确。TDD的核心不是"测试"本身,而是用测试驱动设计决策。EDD的核心也不是"评测"本身,而是用评测驱动Prompt/架构决策。
用人话说:TDD是"红灯→绿灯→重构",EDD是"低分→高分→优化"。都是同一个思想——先定义"什么是对的",再去做。
2.2 没有评测集的Prompt优化长什么样?
这是一个真实的反模式,我见过太多团队在干这件事:
1 Day 1: "嗯这个Prompt回答得不太好,加一句'请详细回答'"
2 Day 2: "太长了,改成'请简洁回答'"
3 Day 3: "漏了关键信息,加一句'请确保包含所有要点'"
4 Day 4: "又太长了..."
5 Day 5: "算了,回退到Day 1的版本"
6 Day 6: "咦Day 1的版本好像也不行了?"你在做布朗运动——看起来一直在动,实际上哪儿也没去。
没有评测集的Prompt优化,本质上就是凭感觉来回改。你不知道改完是变好还是变坏,因为你连"好"和"坏"的定义都没有。
2.3 EDD的核心纪律
只有一条,但必须刻在脑子里:
没有评测集,就不要动Prompt。
这条纪律之所以反直觉,是因为改Prompt太容易了——改一个词就行,几秒钟的事。但正是因为太容易改,才必须有评测兜底。
这就好比开车——正是因为方向盘太容易打,所以才需要导航。不然你每个路口都"感觉应该左转",最后发现自己在原地绕圈。
三、分层评测架构:像搭积木一样设计
优秀的评测体系不是"一套评测跑所有场景",而是分层设计。

3.1 离线评测:抓回归
要素 | 说明 |
|---|---|
数据 | 固定的评测数据集,覆盖核心场景 |
触发 | 每次Prompt/模型/检索改动 |
目标 | 确保改动不让已有能力变差 |
类比 | 传统软件的回归测试套件 |
离线评测的关键是固定数据集。这个数据集不需要很大——50-200条高质量的Case,覆盖核心场景和边界情况,就够了。
1 评测集结构:
2 ├── 基础能力(20%):能不能正确回答核心问题
3 ├── 边界情况(30%):模糊输入、对抗性输入、多语言
4 ├── 格式要求(20%):输出格式是否符合要求
5 ├── 安全性(15%):拒绝不当请求、不泄露敏感信息
6 └── 业务场景(15%):真实用户的高频问题离线评测的铁律:每次Prompt改动,先跑评测,分数不降才能合并。 这和"每次代码改动先跑单测"完全一样。
3.2 在线评测:抓漂移
离线评测有一个天然的缺陷:评测数据集是人造的,不等于真实用户的分布。
用户的提问方式千奇百怪,你的评测集永远无法100%覆盖。所以你还需要在线评测:
要素 | 说明 |
|---|---|
数据 | 生产流量采样(如采样5%的真实请求) |
触发 | 持续运行 |
目标 | 发现真实分布漂移和新的失败模式 |
类比 | 传统软件的生产监控 + 告警 |
在线评测的核心动作是采样+自动打分+告警。当线上平均分数下降超过阈值时,触发告警——可能是用户提问的分布变了,可能是上游数据变了,也可能是模型提供商偷偷更新了模型。
是的,你没看错。模型提供商会在不通知你的情况下更新模型。 你的Prompt在旧模型上跑得好好的,某天突然质量下降——不是你改了什么,是模型变了。
这就好比你租了一辆车,每天开同样的路线。突然有一天车子总是跑偏——不是路变了,是租车公司偷偷换了一台方向盘有点歪的车。 没有在线评测,你根本不知道这件事发生了。
3.3 两层配合
1 离线评测(门禁) → 拦住已知的退化
2 +
3 在线评测(监控) → 发现未知的退化
4 =
5 完整的质量保障单独用任何一层都不够。离线评测抓不住真实分布变化,在线评测来不及阻止有问题的改动上线。
四、打分策略:谁来当裁判?
评测的核心问题是:谁来判断"好"还是"不好"?
这个问题比你想象的复杂得多。
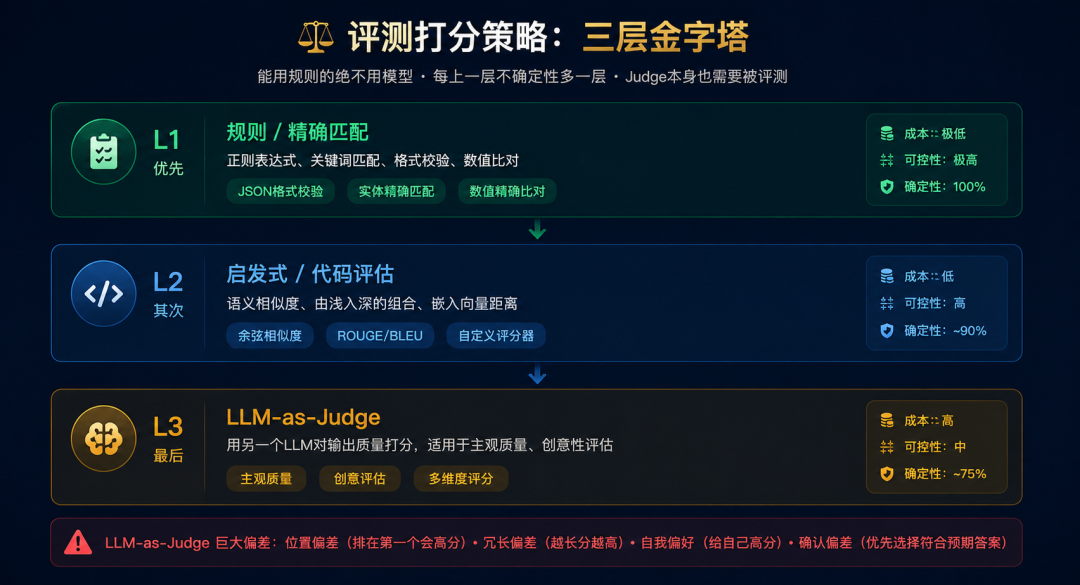
4.1 三层打分策略
层级 | 打分方式 | 适用场景 | 成本 | 可靠性 |
|---|---|---|---|---|
L1: 规则/精确匹配 | 正则、关键词、格式校验 | 有标准答案的题 | 极低 | 极高 |
L2: 启发式/代码评估 | 自定义函数、语义相似度 | 半结构化输出 | 低 | 高 |
L3: LLM-as-Judge | 用另一个LLM打分 | 主观质量、创意性 | 高 | 中 |
核心原则:能用L1的绝不用L2,能用L2的绝不用L3。
为什么?因为每上一层,引入的不确定性就多一层。
L1示例:能用精确匹配解决的
1 # 判断是否正确提取了实体
2 def eval_entity_extraction(output, expected):
3 return expected_entity in output # 简单但可靠
4
5 # 判断输出格式是否正确
6 def eval_json_format(output):
7 try:
8 json.loads(output)
9 returnTrue
10 except:
11 returnFalseL2示例:需要语义理解的
1 # 语义相似度
2 from sentence_transformers import SentenceTransformer
3 model = SentenceTransformer('all-MiniLM-L6-v2')
4
5 def eval_semantic_similarity(output, reference):
6 emb1 = model.encode(output)
7 emb2 = model.encode(reference)
8 return cosine_similarity(emb1, emb2)L3示例:主观质量必须用LLM判
1 # LLM-as-Judge
2 judge_prompt = """
3 请评估以下回答的质量(1-5分):
4 问题:{question}
5 回答:{answer}
6 评分标准:准确性、完整性、清晰度
7 请直接输出分数和理由。
8 """4.2 LLM-as-Judge的陷阱
用LLM给LLM打分,听起来很优雅,但有一个致命问题:
裁判本身也不可靠。
已知的偏差包括:
偏差类型 | 表现 | 应对 |
|---|---|---|
位置偏差 | 倾向于给列表中第一个选项更高分 | 随机打乱顺序,多次评判取平均 |
冗长偏差 | 更长的回答倾向于获得更高分 | 在评分标准中明确"简洁不扣分" |
自我偏好 | 同一模型倾向于给自己的输出更高分 | 用不同模型做Judge |
确认偏差 | 流畅但错误的回答可能得高分 | 加入事实校验层 |
所以Judge本身也需要被评测。 怎么评测Judge?用人工标注的"金标准"数据集,计算Judge的打分和人工打分的一致性。
用人话说:你请了一个AI当裁判,但你得先考试确认这个裁判合格。裁判不合格,比赛结果毫无意义。
这就是评测工程里最套娃的部分——评测的评测。
五、实战:一个完整的EDD工作流
把上面说的串成一个完整的工作流:
5.1 开发阶段
1 Step 1: 定义任务 → 明确LLM要完成什么
2 Step 2: 建评测集 → 50-200条Case,覆盖核心场景
3 Step 3: 选打分策略 → L1/L2/L3分层设计
4 Step 4: 跑基线 → 用最简单的Prompt跑一遍,记录基线分数
5 Step 5: 迭代优化 → 改Prompt/模型/检索,每次改动跑评测
6 Step 6: 合并标准 → 评测分数 ≥ 基线 才能合并5.2 上线阶段
1 Step 7: 在线评测 → 生产流量采样 + 自动打分
2 Step 8: 告警规则 → 平均分下降 > 阈值 → 触发告警
3 Step 9: 反馈闭环 → 线上Bad Case → 补充到离线评测集
4 Step 10: 持续迭代 → 回到Step 55.3 关键指标
指标 | 定义 | 健康值 |
|---|---|---|
离线评测通过率 | 评测分数 ≥ 阈值的Case占比 | ≥ 90% |
在线评测均分 | 生产流量采样的平均分 | ≥ 4.0/5.0 |
回归率 | 新改动导致已有Case变差的比例 | ≤ 5% |
Judge一致性 | Judge打分与人工打分的相关系数 | ≥ 0.85 |
评测覆盖率 | 评测集覆盖的场景占总场景的比例 | ≥ 80% |
六、常见误区:这些坑我替你踩了
6.1 误区一:"评测集越大越好"
不是。50条高质量、覆盖核心场景的Case,比500条随手造的垃圾Case有用得多。
评测集的质量 > 数量。 每条Case都应该有明确的考察目的——它在测什么能力?失败了说明什么问题?
6.2 误区二:"评测分数高就能上线"
评测分数只是必要条件,不是充分条件。
你的评测集覆盖不了所有真实场景。分数高只能说明"在已知场景上表现不错",不能保证"在所有场景上都行"。
所以离线评测 + 在线评测缺一不可。
6.3 误区三:"用GPT-4打分就够了"
LLM-as-Judge不是银弹。前面说了,它有位置偏差、冗长偏差、自我偏好等问题。
能用规则判的用规则,能用代码判的用代码。LLM打分是最后的手段,不是第一选择。
6.4 误区四:"评测集建好就不用管了"
评测集需要持续维护。随着产品迭代和用户变化,你的评测集也要更新:
- 线上发现的新Bad Case要补充进去
- 过时的Case要淘汰
- 新功能上线要增加对应Case
评测集是活的,不是死的。它是你对"什么是好的输出"的持续理解。
七、工具链速览
当前主流的Eval工具/框架:
工具 | 定位 | 核心特点 |
|---|---|---|
Braintrust | 企业级Eval平台 | 全链路追踪+评测+数据集管理 |
Langsmith | LangChain生态 | 与LangChain深度集成,可视化好 |
Promptfoo | 开源Eval框架 | 轻量、CLI驱动、CI/CD友好 |
Ragas | RAG专用评测 | 针对检索增强生成的专用指标 |
DeepEval | 开源Eval框架 | 内置多种LLM评测指标 |
OpenAI Evals | OpenAI官方 | 标准化评测协议 |
选择建议:
- 个人/小团队:Promptfoo(开源、轻量、上手快)
- RAG场景:Ragas(专用指标更精准)
- 企业级:Braintrust 或 Langsmith(功能全面、可视化好)
但工具永远是次要的。最重要的是那条纪律——没有评测集,不动Prompt。
写在最后
Eval驱动开发不是一个高大上的新概念,它就是TDD在AI时代的翻版。
2005年,很多程序员觉得写单测是浪费时间——"我手动跑一遍不就行了?" 后来他们发现,不写测试的代码就像没有刹车的车——开着倒也不是不能开,但迟早翻车。
2026年,很多AI工程师觉得建评测集是浪费时间——"我改完Prompt跑一个Case看看不就行了?"
历史不会重复,但会押韵。
把"质量"从玄学变成可度量、可回归的工程指标——这不是锦上添花,而是AI应用从"Demo阶段"走向"生产级"的分水岭。
如果你的团队还在凭感觉调Prompt,今天开始做一件事:
停下来,先建20条评测Case。
不需要很多,不需要很完美。但从这20条开始,你的每一次改动都有了方向,你的每一次优化都有了度量。
从"我觉得好像变好了"到"评测分数从3.8涨到4.2"——这个转变,就是AI工程化的成人礼。
— 完 —
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-03,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号