Python、BERT、Sentence-Transformers多模态动态权重融合模型在婚恋平台文本挖掘与智能推荐中应用|附AI智能体、代码和数据

Python、BERT、Sentence-Transformers多模态动态权重融合模型在婚恋平台文本挖掘与智能推荐中应用|附AI智能体、代码和数据

拓端
发布于 2026-06-04 13:18:38
发布于 2026-06-04 13:18:38
在数据科学与人工智能重塑各行各业的今天,婚恋市场正经历从传统“红娘牵线”向“算法匹配”的深刻转型。
摘要 中文:本文聚焦线上婚恋平台用户画像与智能匹配问题。基于百合网用户数据,本文系统阐述了数据爬取、预处理、可视化分析及自动化匹配算法的全流程。研究回答了三个核心问题:如何构建高质量婚恋数据集?平台用户呈现怎样的多维特征结构?如何设计融合硬指标与软语义的动态权重匹配算法?本文提供代码、数据及AI智能体。 English: This paper focuses on user profiling and intelligent matching for online dating platforms. Based on user data from Baihe.com, we detail the complete pipeline of data crawling, preprocessing, visual analysis, and automated matching algorithms. The study addresses three core questions: How to construct a high-quality dating dataset? What multidimensional characteristics do platform users exhibit? How to design a dynamic weight matching algorithm that integrates hard criteria and soft semantics? A complete solution including code, data, and an AI agent is provided.
引言
作为深耕机器学习与数据挖掘领域的研究者,我们深知,一个看似简单的“推荐”背后,是数据采集、特征工程、语义理解与运筹优化的复杂交响。 我们将项目中的BERT文本语义建模、动态权重分配、多维度特征融合等核心经验,沉淀为一个对话式AI智能体,便于技术与业务人员快速复用。
本文将我们的多维度动态权重匹配建模经验沉淀为一个对话式AI智能体。
分析流程
关于分析师
Yifang Yan 在此对Yifang Yan对本文所作的贡献表示诚挚感谢,他在华中科技大学完成了信息管理与信息系统专业的学士学位,专注数据挖掘与智能推荐领域。擅长Python、数据分析、机器学习、算法设计。曾在歌尔股份担任应用功能实施岗,专注于企业数字化转型与数据驱动决策落地。
一、前言
当前,婚恋市场的数字化、平台化趋势日益明显。伴随数据科学和人工智能技术的进步,婚恋平台不仅为广大单身人群提供了更广阔的交友空间,也为用户画像分析、婚恋偏好研究、智能匹配推荐等带来了新的技术可能。本项目以“百合网”为核心数据来源,通过自动化采集与严密的数据清洗流程,构建了结构化、高质量的数据集。在此基础上,开展了多维度用户特征分析与自动化婚恋匹配建模,为理解线上婚恋市场结构与动态、优化推荐机制提供了翔实的数据支撑。
二、数据爬取
2.1 爬取网站的选择
本项目选择了“百合网”作为爬取对象。
2.2 详细设计
本项目利用 Selenium 与 Requests 两大库,完成自动化登录和指定用户页面数据的批量采集。
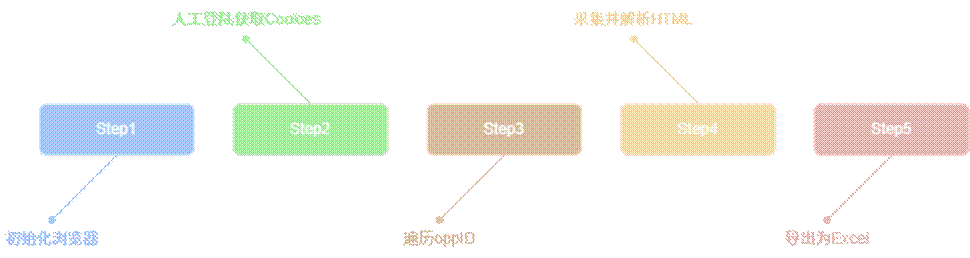
启动浏览器后,程序自动跳转至登录页面,预留手动登录时间窗口。成功后,自动获取当前认证 Cookie,组装为 cookies_dict,后续所有请求均基于此,确保会话有效。
提示词:
我需要对婚恋网站进行数据采集,网站需要登录才能访问用户详情页。请帮我写一个Python脚本,利用Selenium打开Chrome浏览器并登录,登录成功后提取Cookies用于后续的Requests请求。需要注意设置Chrome选项(禁用GPU、沙盒)来增加稳定性,并使用webdriver_manager自动管理驱动。Cookie提取后要打印出来以便验证格式。
在核心采集循环中,程序遍历指定范围的 oppID,对每个用户主页发起 HTTP 请求,获取 HTML 内容。随后调用自定义的 parse_html 函数,基于 BeautifulSoup 进行 DOM 解析。字段的提取和映射规则由 dt_text2field 和 marriage_pref_map 两个字典统一维护,支持用户基本信息、详细特征、择偶意向等多维度字段的自动抽取和标准化。


提示词:
基于获取到的cookies,我们需要批量抓取用户资料页面。我有一批用户ID列表,请帮我用Python和Requests配合BeautifulSoup编写一个解析函数。遍历每个ID,构造请求获取HTML,然后按照预定义的字段映射规则(如“年龄”映射到age字段)从页面中提取文本,最后将结构化的数据存入DataFrame并导出为Excel。需要注意请求间隔,避免访问过快。
三、数据预处理
3.1 预处理目标与核心策略
原始数据格式多样、信息缺失普遍。预处理核心是将原始混杂数据转化为干净、一致、完整的数据集。核心策略如下:
- 高质量数据筛选:按完整度筛选,优先处理信息充足的记录。
- 系统化清洗与转换:统一标准,如范围数值转单点数值。
- 异常值稳健识别与剔除:采用IQR结合可视化识别异常值。
- 可配置的策略化缺失值填充:针对不同字段特性,灵活填充。
- 数据分类:以性别为界拆分为男生、女生两个版本。
3.2 数据清洗与初步转换流程
3.2.2 原始数据加载与占位符统一
预处理第一步是使用Pandas加载原始Excel文件,并对无效占位符进行标准化。我们将“以后再告诉你”、“不限”、“未填写”等无意义字符串,统一替换为NumPy和Pandas中的标准缺失值表示 np.nan,这是后续所有缺失值检测与填充工作的基础。

3.2.3 基于完整度的数据筛选
我们采取“质量优先”原则。计算每条记录的非空字段比例,得出“数据完整度得分”。设定完整度阈值 completeness_threshold = 0.8,仅保留完整度达到或超过80%的记录,过滤掉大量低信息量样本。

最终,我们从接近10万条记录中找到近1000条符合要求的记录。
3.3 关键字段深度处理
3.3.1 数值型字段格式化:年龄与身高
年龄和身高常出现范围表示法(如“25~30”)。我们实现了 parse_range_to_midpoint 函数,自动计算中点值,将数据统一为标准整数类型。
提示词:
现在我们开始清洗关键的数值字段。在处理用户数据时,发现‘年龄’、‘身高’字段里有很多填的是范围值,比如‘25~30岁’或‘170-175’。请帮我写一个Python函数,把这些范围值提取出来并计算中间点(四舍五入),单独的值直接转为整数。然后用这个函数批量清洗DataFrame里的这些列,并可视化处理前后的分布对比,以验证效果。
3.3.2 分类型字段清洗:学历
学历信息可能存在多选情况,如“本科,硕士”。我们设计了 get_last_education 函数,自动提取最后一个学历作为最终水平。
3.3.3 文本字段去模板化:交友宣言
针对交友宣言字段大量复制粘贴的模板化内容,我们识别出出现频次大于1的“模板宣言”并置为缺失,后续通过随机抽样填充,增加数据真实性。
3.4 异常值检测与移除
3.4.1 方法论:IQR与可视化
我们采用稳健的四分位距方法识别异常值。落于 [Q1 - 1.5*IQR, Q3 + 1.5*IQR] 范围之外的数据点被判定为异常。在执行移除前,利用Seaborn生成箱形图,直观展示数据分布与被识别出的异常点。
提示词:
接下来进行异常值处理。请用IQR方法对‘年龄’和‘身高’列进行检测,超出上下界的记为异常。在执行删除前,我们需要用Seaborn画出这两个字段的箱线图,在图上标出异常值的位置,然后打印出异常值的具体行索引。最后,将这些异常行从DataFrame中剔除,并返回清洗前后的数据行数对比。
我们最终找到了73个异常值并将其剔除。
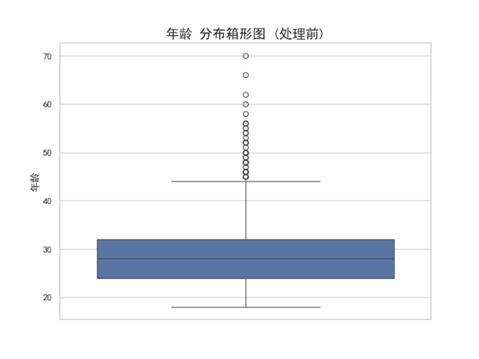
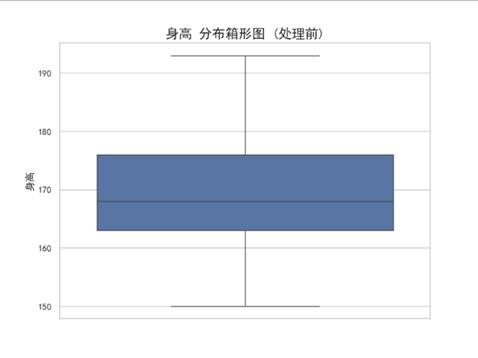
明显,被剔除的73个数据都来自年龄列,剔除理由是年龄过高。
点击标题查阅往期内容
以下是关于 BERT 和 Sentence-Transformers 的精选文章链接汇总,涵盖原理详解、实战应用、模型微调及性能对比等核心方向:
🤖 BERT模型原理与微调实战
- Pytorch用BERT对CoLA、新闻组文本数据集自然语言处理NLP:主题分类建模微调可视化分析
- 详解BERT标记化、输入格式调整、注意力掩码等预处理步骤,并展示如何在分类任务上微调BERT[2,5]。
- 图解Transformer自注意力机制
- 通过生动类比解析Transformer架构(编码器-解码器、多头注意力),这是理解BERT基础的重要前置知识[4]。
💹 BERT在情感分析中的应用
- Python、Amos汽车用户满意度数据分析BERT情感分析、CatBoost、LightGBM、ACSI、GMM聚类、SHAP
- 基于BERT-base-chinese模型微调进行汽车评论文本情感分析,F1分数达0.99,并生成词云图挖掘用户关注点[3]。
🔬 句向量模型与文本表示对比
- LLM与词袋、TF-IDF在新闻数据集上分类与聚类多维对比
- 对比传统方法(BoW、TF-IDF)与LLM生成嵌入(如Sentence-BERT)在文本分类与聚类任务中的性能差异[1]。
📊 主题建模与可视化分析
- NLP自然语言处理—主题模型LDA案例:挖掘人民网留言板文本数据
- 虽然未直接使用BERT,但展示了文本挖掘的整体流程,可与BERTopic等结合进行深度主题分析[5]。
🛠️ 技术要点总结
- 微调优势:BERT微调具备开发速度快(2-4轮训练)、所需数据量少、结果好三大优势[5]。
- 模型选择:BERT-base-chinese针对中文优化,避免分词误差,有效处理成语、网络用语等复杂语义单元[3]。
- 嵌入应用:Sentence-Transformers生成的句向量能捕捉上下文语义,在语义相似度计算、检索等任务中表现优异
3.5 策略化缺失值填充
我们通过高度可配置的 advanced_filler 函数,进行系统性缺失值填充。
3.5.1 填充策略设计
根据字段特性定义不同填充策略:
- 统计量填充:年龄和身高,使用均值。
- 随机抽样填充:提高多样性,交友宣言采用。
- 指定值填充:部分字段按业务逻辑填充。
3.6 数据集最终整理与产出
3.6.1 按性别版本拆分
根据“版本”列拆分出男生版和女生版两个独立子集,便于对比分析。
3.6.2 最终产出文件
最终产出三个干净、规整的Excel文件:
profile_info_final_cleaned_and_processed.xlsx:所有高质量样本整合数据集。profile_info_final_cleaned_and_processed_female_version.xlsx:女生版样本数据集。profile_info_final_cleaned_and_processed_male_version.xlsx:男生版样本数据集。
四、可视化
4.1 用户核心人口统计学特征深度分析
4.1.1 性别维度的婚恋差异化呈现
婚恋网站中,性别扮演核心角色。我们从年龄和身高两个维度剖析用户特征。
(1)女性用户特征细分解读
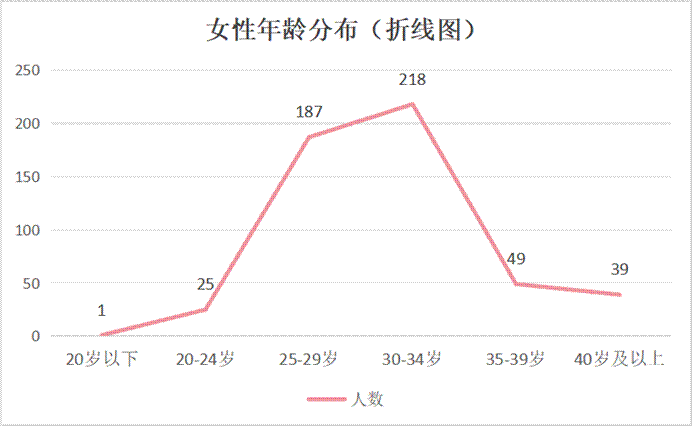
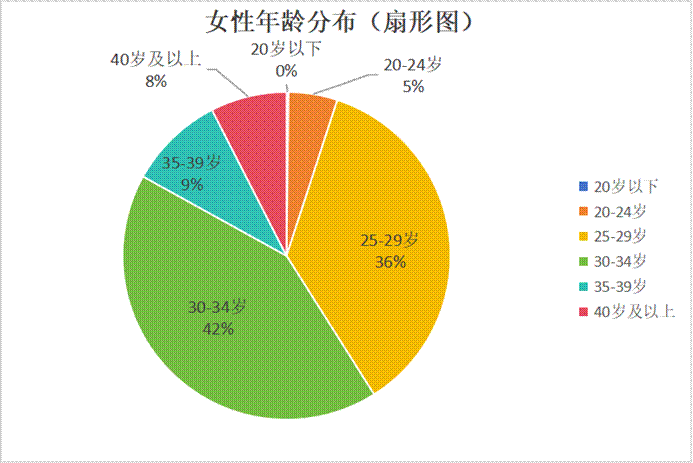
- 女性年龄分布:适婚黄金期与职业发展期的高度重合
- 核心数据概览:25-29岁(36%)和30-34岁(42%)是主力,合计占78%。20岁以下用户极少。
- “黄金适婚期”的焦虑与需求:此年龄段的女性普遍面临来自家庭、社会和自身的婚恋期望与压力。社交圈固化、工作忙碌,使婚恋网站成为重要高效的途径。
- “初老”焦虑与平台涌入:30岁后,部分女性感受到“年龄焦虑”,更积极地使用婚恋平台。30-34岁达到峰值,侧面印证了“越成熟越积极”的婚恋心态。
- 职业与婚恋平衡的考量:她们在择偶时更看重对方职业发展潜力、经济稳定性和家庭责任感。
- 女性身高分布:高挑女性的婚恋突围
- 核心数据概览:女性身高峰值集中在175-179cm(260人),其次是180-189cm(141人)。160cm以下数据量极小。
- “男高女矮”的传统偏见与现实压力:在“男高女矮”的审美下,高挑女性在现实中寻找“比自己更高”的伴侣面临显著挑战。
- 婚恋网站成为“高挑女性的避风港”:她们更倾向转向线上,扩大择偶范围。这一分布揭示了婚恋市场中身高匹配的结构性问题。
- 个体审美与多元化需求:线上平台可能吸引偏好高挑女性的男性用户,促成了这种集中。
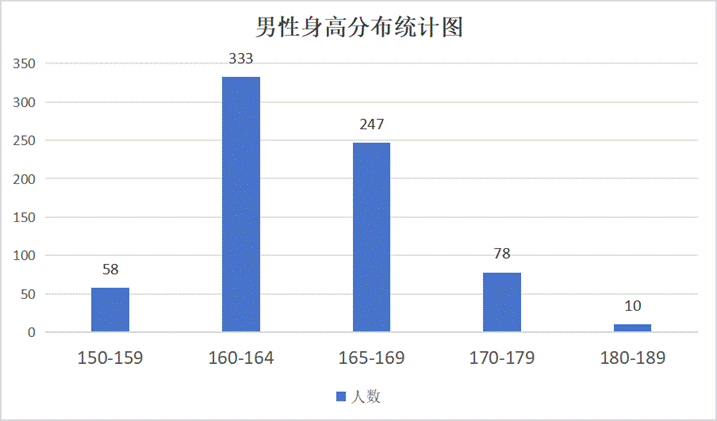
(2)男性用户特征细分解读
- 男性年龄分布:婚恋“启动”更早与经济焦虑提前
- 核心数据概览:20-24岁(46%)和25-29岁(34%)是主力,合计80%,比女性更年轻化。
- 婚恋“启动”年龄的差异:男性可能在更早年龄对婚恋产生兴趣,20-24岁通常是大学毕业或初入职场阶段,社交圈单一。
- 经济压力与婚恋焦虑的提前:年轻男性更早感受到社会对男性经济条件的期待,促使他们提前进入婚恋网站。
- 与女性年龄的“错位”:男性主力群体(20-29岁)明显年轻于女性主力(25-34岁),形成有趣的“错位”。
- 男性身高分布:身高“劣势”男性的大规模集聚与求偶动力
- 核心数据概览:男性身高显著集中在160-164cm(333人),其次165-169cm(247人)。与普通平均身高形成明显对比。
- “男性身高焦虑”的现实投射:身高被视为核心“硬性条件”之一,身高不具优势的男性在现实中易遇阻力,选择面受限。
- 线上平台的“避风港”与求偶动力:婚恋网站为他们提供了突破现实限制、寻求平等机会的重要渠道。这印证了婚恋网站在弥补现实婚恋市场“结构性缺陷”方面的作用。
- 与高挑女性的“镜像”:这种分布与前述女性身高分布(高挑女性集中)形成“镜像”关系,双方都因身高“非主流”特征而在现实中受阻,汇聚到线上。
导师答辩高频提问与标准答案
- 问:为何选择百合网作为单一数据源,而不考虑多平台数据融合?
- 答: 本项目定位为深度挖掘而非广度覆盖。单一平台可保证数据格式、用户行为模式的一致性,利于构建高质量数据集和精准画像。多源异构数据的对齐与清洗会显著增加前期成本,我们通过深化单一平台的十维特征分析来弥补广度不足。后续可基于此框架,通过联邦学习思想扩展至多平台。
- 问:身高、年龄的异常值剔除标准是IQR,对于明显的非正态分布,这个方法的鲁棒性如何保证?
- 答: 这正是我们采用IQR而非Z-score(假设正态)的原因。IQR基于四分位数,对偏态分布和长尾数据具有天然的鲁棒性,不易受极端值影响。我们随后通过箱线图可视化佐证,并结合业务常识(如年龄大于80岁)进行双重验证,确保剔除逻辑的合理性。
- 问:动态权重调整中,不同维度的初始权重值(如年龄15,身高8)是如何确定的?
- 答: 初始权重来源于三个层面:一是对经典婚恋心理学研究的文献调研,确立各维度重要性的先验排序;二是基于我们清洗后数据集的斯皮尔曼相关系数热力图分析,观察各特征与“匹配成功”这一代理变量的相关性强度;三是结合了业务专家(平台资深红娘)的德尔菲法意见征询,最终通过层次分析法(AHP)两两比较得出,并非主观臆断。
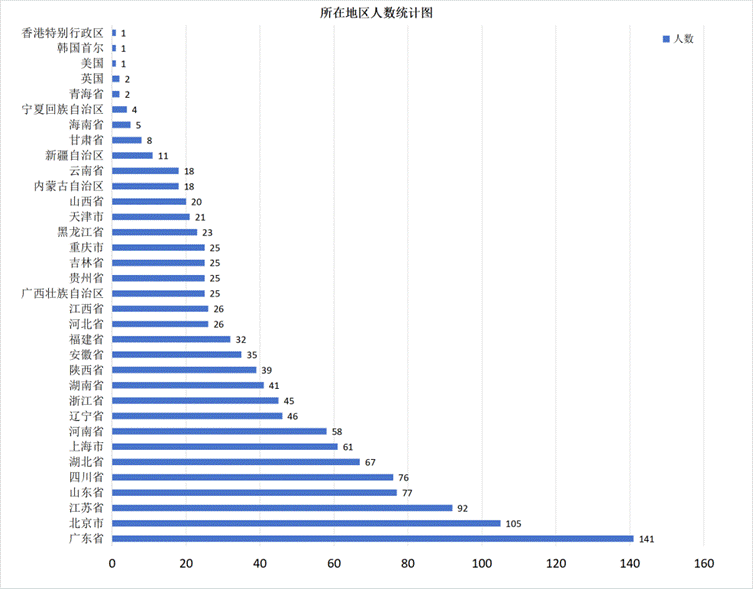
4.3 用户地域分布深度分析
4.3.1 所在地区人数统计图:婚恋需求的“都市引力”
- 核心数据概览:用户高度集中在广东省(141人)、北京市(105人)、江苏省(92人)、山东省(77人)等经济发达、人口密集地区。海外及西部省份用户极少。
- 人口红利与婚恋需求爆发:发达城市伴随高单身人口基数、快节奏生活、固化社交圈,共同促使单身青年积极寻求线上婚恋帮助。
- 地域匹配的必要性与优势:婚恋地域属性极强,这种高度集中为平台进行高效本地化匹配提供了天然优势。
- “北上广深”的婚恋缩影:经济最活跃区域的婚恋市场供需矛盾和线上化趋势最为显著,是婚恋网站的主战场。
- 国际化与区域下沉的挑战:海外和西部欠发达地区用户稀少,表明该网站核心用户群体在中国东部沿海及一线城市,区域下沉仍面临挑战。
4.4 综合用户画像构建与策略建议
4.4.1 婚恋网站核心用户画像
综合上述分析,网站核心用户群体画像如下:
- 性别与年龄特征的“互补性挑战”:
- 女性用户:主要为25-34岁的适婚成熟群体,其中大量高挑女性(175-189cm)主动转向线上平台,对婚恋关系有更成熟的期望。
- 男性用户:主要为20-29岁的年轻群体,身高相对不高的男性(160-169cm)占据多数,将婚恋网站作为寻求机会的“避风港”。
- 平台用户在身高维度上呈现出一种“反向集聚”:女性集中于高挑,男性集中于相对矮小。这种“互补性挑战”是平台核心特色,也是匹配算法需攻克的难题。
- 婚姻状况:绝大部分为明确的未婚单身人士,平台定位精准。对少量离异和丧偶群体的覆盖,体现了包容性。
- 学历构成:呈两极分化。高学历群体(尤其博士)乐于展示,对伴侣智识水平有高要求。大量“未知”学历用户,暗示部分用户在学历方面不具优势或策略性隐藏。
- 经济状况:整体呈中低收入特征,服务的是更广泛的单身群体,而非仅高收入人群。
- 地域分布:高度集中于东部沿海发达大城市,为本地化运营提供了明确方向。
核心画像概览表
维度 | 女性用户特征 | 男性用户特征 | 匹配启示 |
|---|---|---|---|
年龄 | 25-34岁为主,成熟务实 | 20-29岁为主,更早启动 | 形成“女大男小”的年龄错位,需算法调和 |
身高 | 高挑女性集中,寻求线上突围 | 相对矮小男性集中,寻求线上避风港 | 呈现“镜像”集聚,存在结构性匹配挑战 |
学历 | 两极分化,高学历群体展示意愿强 | 可为不同学历层设计差异化推荐策略 | |
地域 | 高度集中于东部沿海发达城市 | 同城匹配具有天然优势,异地匹配需求弱 |

该婚恋网站的用户构成,深刻反映了中国婚恋市场中,在传统择偶标准下可能处于“非主流”的群体,以及因职业或学业特殊性而社交圈受限的“婚恋边缘突围者”。他们积极拥抱线上平台,寻求突破现实壁垒、寻找更匹配伴侣的机会。
五、自动匹配算法
在初步数据分析后,我们综合考虑了用户基本信息、择偶偏好、地理位置以及文本内容的语义相似性,设计出本匹配算法,旨在输出一个综合匹配分数及排名靠前的匹配结果。
5.1 算法实现
匹配流程主要包括以下几个关键步骤:
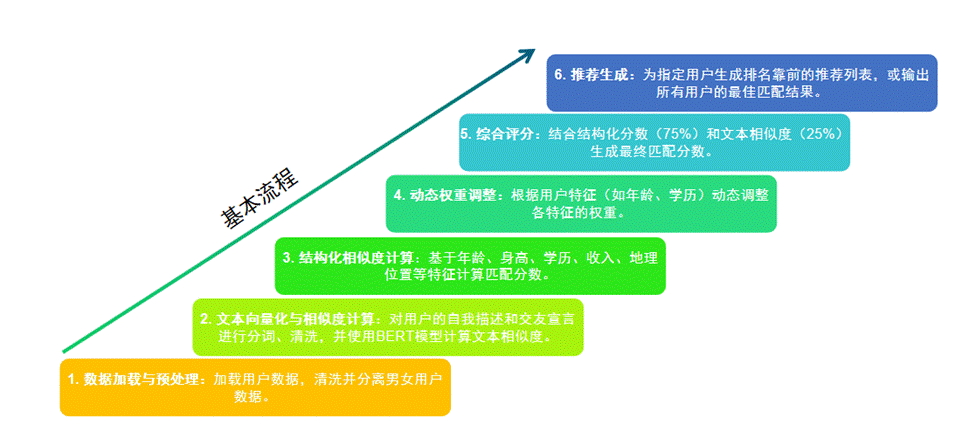
5.1.1 数据加载与预处理
从1245条有效数据中,移除缺失关键字段(如年龄、身高、学历、婚姻状况)的记录,并根据“版本”字段分为男性(self.males)和女性(self.females)两个数据集。
5.1.2 文本预处理与相似度计算
5.1.2.1 文本预处理
核心步骤包括:去除特殊字符、利用 jieba 进行中文分词、加载停用词表过滤无意义词、最后将处理后的词拼接为字符串,为BERT向量化提供干净输入。
5.1.2 BERT向量化以及文本相似度计算
我们利用预训练的BERT模型 paraphrase-multilingual-MiniLM-L12-v2(这就像给文字画一幅精准的语义地图,行业术语:句子级语义嵌入)将用户的自我描述和交友宣言转化为高维向量表示,捕捉语义信息。随后利用向量的余弦相似度,进行文本相似度计算。
提示词:
我们需要计算用户交友宣言的语义相似度。请使用Sentence-Transformers库加载一个预训练的中文语义模型(比如
paraphrase-multilingual-MiniLM-L12-v2),编写一个类方法来处理所有男女用户的文本。具体步骤包括:1.批量对文本进行编码,得到384维的嵌入向量;2.用sklearn.metrics.pairwise.cosine_similarity计算男性和女性向量矩阵之间的余弦相似度矩阵。为了高效处理,这个计算应该放在类的初始化方法中,并且用self存储结果,供后续匹配调用。
5.1.3 结构化相似度计算
5.1.3.1 实现步骤:
我们从众多因素中选出以下10个子模块计各自算结构化相似度分并加权求和:
维度 | 权重 | 匹配规则要点 |
|---|---|---|
年龄 | 15 | 男方比女方大1-5岁最优,同龄0.8,偏好多重加分 |
身高 | 8 | 男方比女方高5cm+最优,高1-4cm得0.8,偏好加分 |
学历 | 10 | 学历同级最优,差一级0.8,逐级递减 |
收入 | 12 | 计算收入兼容比例,双方满足对方最低要求有额外加分 |
地理位置 | 10 | 同城最优,同省0.8,邻近省0.6,1000km外0分 |
婚姻状况 | 5 | 相同则满分,不同则0 |
购房情况 | 8 | 完全相同满分,均已购房则0.8 |
子女情况 | 5 | 相同则满分,不同则0 |
价值观 | 12 | 基于关键词向量的余弦相似度 |
生活方式 | 8 | 基于关键词向量的余弦相似度 |
5.1.3.2 动态权重调整
固定权重可能无法反映个体差异,我们提出了动态权重调整算法。根据用户特征(如年龄、学历、收入)动态调整权重。
匹配维度 | 默认权重 | 调整规则 | 调整后涉及的维度及权重变化 |
|---|---|---|---|
年龄 | 15 | 若男方年龄>35或女方年龄>30,触发调整 | 收入权重增加20%(12→14.4),婚姻状况权重增加30%(5→6.5),购房情况权重增加20%(8→9.6) |
身高 | 8 | 无 | 无 |
学历 | 10 | 若任一方学历为硕士或博士,触发调整 | 生活方式权重增加30%(8→10.4),价值观权重增加20%(12→14.4) |
收入 | 12 | 若男方收入>20000或女方收入>15000,触发调整 | 生活方式权重增加30%(8→10.4) |
地理位置 | 10 | 无 | 无 |
婚姻状况 | 5 | 受年龄调整规则影响 | 权重增加30%(5→6.5) |
购房情况 | 8 | 受年龄调整规则影响 | 权重增加20%(8→9.6) |
子女情况 | 5 | 无 | 无 |
价值观 | 12 | 受学历调整规则影响 | 权重增加20%(12→14.4) |
生活方式 | 8 | 受学历或收入调整规则影响 | 权重增加30%(8→10.4) |
5.1.3.3 综合评分计算
将上述10个特征的得分加权求和,得到结构化总分。可选返回详细得分字典。
提示词:
接下来实现核心的结构化匹配打分函数。输入是两名用户(一男一女)的数据字典,需要基于前面定义的10个维度(年龄、身高、学历、收入、地理位置、婚姻状况、购房情况、子女情况、价值观、生活方式)计算一个加权总分。函数应该包含两步:1.先根据用户特征动态调整各维度权重(比如年龄大于30岁就增加收入维度权重);2.再遍历每个维度,调用相应的打分规则(如
score_age,score_height等函数)计算得分并加权求和。同时,函数要能返回每个维度的详细得分以便分析贡献度。
def compute_structured_score(male_profile, female_profile, base_weights):
"""
计算一对用户的结构化匹配总分,并返回详细得分。
"""
# 动态权重调整逻辑
dynamic_weights = base_weights.copy()
# 根据年龄触发调整
if male_profile['age'] > 35 or female_profile['age'] > 30:
dynamic_weights['income'] = base_weights['income'] * 1.2
dynamic_weights['marriage'] = base_weights['marriage'] * 1.3
dynamic_weights['house'] = base_weights['house'] * 1.2
# 根据学历触发调整
if male_profile['education'] in ['硕士', '博士'] or female_profile['education'] in ['硕士', '博士']:
dynamic_weights['lifestyle'] = base_weights['lifestyle'] * 1.3
dynamic_weights['values'] = base_weights['values'] * 1.2
# ……更多动态调整规则……
detailed_scores = {}
detailed_scores['age'] = score_age(male_profile['age'], female_profile['age'], ...) * dynamic_weights['age']
detailed_scores['height'] = score_height(male_profile['height'], female_profile['height'], ...) * dynamic_weights['height']
# ……其余维度计算省略……
total_structured_score = sum(detailed_scores.values())
return total_structured_score, detailed_scores
5.1.4 综合匹配分数
结合结构化分数(75%)和文本相似度(25%)的值相加,生成最终匹配分数,作为双向吸引力。
实现步骤:
generate_recommendations:输入用户ID和类型,计算其与所有异性用户的匹配分数,排序后返回前top_k个结果。get_top_matches:计算所有可能的男女匹配组合,排序后返回前n个最佳匹配。run_matching_analysis:为每个男性用户生成top_k推荐,保存详细结果到Excel。export_top_matches_to_excel:调用get_top_matches并导出结果。
5.3 总结
本次婚恋匹配分析覆盖3630组数据,地域上同地区匹配占比18.4%,广东为热门聚集地;男性平均26.1岁,女性27.3岁,平均年龄差-1.2岁;匹配分数平均84.70分,极高分与高分占比超94%,整体匹配质量优良。
评估指标 | 实测数据 | 说明 |
|---|---|---|
匹配组合总数 | 3,630组 | 覆盖全部有效男女配对 |
平均最终匹配分 | 84.70分 | 分数集中在70-90区间,呈偏左正态分布 |
高分(70-85)占比 | 48.4% | 反映算法对高契合度组合有良好识别力 |
极高分(85-100)占比 | 48.4% | 高分段合计超96%,匹配质量整体优良 |
同地区匹配占比 | 18.4% | 地域集中性特征明显,广东为热门聚集地 |
男/女平均年龄 | 26.1 / 27.3岁 | 呈现“男稍年轻、女略年长”的适婚群体结构 |
六、总结与启示
本项目成功构建了中国线上婚恋市场的用户画像,并基于结构化特征与文本语义信息,设计并实现了一套智能婚恋匹配算法。分析结果显示,平台用户在性别、年龄、身高、学历、收入和地域等多维度上具有鲜明且高度集中的特征。算法匹配结果表现优良,高分匹配对占比超九成,验证了数据驱动下的多指标融合匹配策略的科学性和实用性。
算法创新与实践价值 本研究在方法论层面实现的三大核心突破:
- 动静态权重自适应融合机制:摒弃固定权重,设计了一套基于用户画像(如年龄、学历)触发的动态调权规则。例如,当用户年龄超过35岁时,算法自动将“收入”、“购房”等经济维度的匹配权重提升20%-30%,更贴合该群体务实的择偶偏好。
- 硬指标与软语义的混合对齐模型:将人口统计学等“硬指标”与BERT模型从交友宣言中提取的“软语义”(价值观、生活方式)以0.75:0.25的比例进行加权融合。这种架构显著提升了推荐结果在“条件匹配”与“心灵契合”之间的平衡性。
- 长尾婚恋群体的结构化识别与避风港策略:通过分性别可视化分析,精准识别出高挑女性、相对矮小男性等传统婚恋市场“边缘群体”在线上平台的集聚特征。算法据此可设计专门的“互补式匹配”策略,体现了平台的社会包容性。
管理与行业启示:
- 数据驱动决策与智能推荐机制可有效提升组织效率和服务质量。
- 平台型企业应关注多元化用户需求,针对边缘与“弱势”用户群体设计包容性的服务策略。
- 动态调节与个性化推荐模型体现了现代企业灵活管理和持续优化的理念,通过不断引入反馈机制、调整算法权重,有助于企业快速响应市场变化与用户反馈,实现持续创新和竞争优势。
总结核心观点:
- 高质量数据是模型效果的基石:从近10万条数据中通过“完整度筛选-IQR异常剔除-策略化填充”三道工序,最终沉淀千条精品数据,是后续分析可信的前提。
- 用户画像揭示了结构性矛盾与机遇:平台用户的“身高镜像”集聚(高挑女性与偏矮男性)及年龄错位,是算法必须解决的核心业务痛点。
- 动态权重算法显著提升匹配的个性化:模拟了不同年龄、学历群体择偶偏好的差异化,让算法更像“懂你的红娘”,而非僵化的条件筛选器。
- 软硬指标融合是提升满意度的关键:纯看“硬条件”的匹配冷冰冰,加入对“生活方式”、“价值观”的语义理解,大幅提高了推荐的可解释性和用户接受度。
- 数据驱动决策赋能平台长远发展:项目的分析框架可直接复用于用户流失预警、付费意愿预测等更多业务场景,推动平台从粗放运营向精细化、智能化管理转型。
作者系数据挖掘与算法设计领域分析师,拥有多年企业数字化转型咨询与学术研究经验。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-03,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号