2026年Claude Code Skill生态,哪些是噱头,这20个是真的在帮我干活

2026年Claude Code Skill生态,哪些是噱头,这20个是真的在帮我干活

码哥字节
发布于 2026-06-04 12:27:43
发布于 2026-06-04 12:27:43
Skill 生态上线六个月,我经历了三个阶段。
第一个月:看到什么装什么,光 awesome-skills.com 首页挂的就装了一半,感觉自己马上就要起飞。第二个月:发现 .claude/skills/ 目录塞了 50 多个文件夹,但 Claude 实际上每天在用的不超过 5 个。第三个月:开始清库存,留下真正在帮我干活的,把剩下的全卸载。
这篇文章是清库存之后的账单。
不是推荐列表,是淘汰赛——写的是哪些留下来了,更重要的是,为什么其他的被踢出去了。
Skill 是什么,它解决的是什么摩擦
在进入名单之前,有一个判断视角值得先说清楚:Skill 不是更好的 prompt,是带阶段门槛的工作流模块。
一个 prompt 级别的指令是建议——Claude 可以参考,也可以忽略。一个结构良好的 Skill,如果里面定义了明确的阶段门槛(「红灯测试必须失败之后才能进下一步」「计划必须输出 Markdown 文件后才能开始编码」),Claude 更倾向于照执行。
这个差别是真实的,不是概念游戏。
但这也意味着:Skill 的质量参差不齐。150+ 个 Skill 里,有一批是用来展示可能性的,有一批是解决真实工程痛点的。装了 50 个之后我发现,后者大概占三分之一。
判断一个 Skill 留不留,我用的标准是:没有它,这件事会让我多花多少时间? 答案是「5 分钟以内」的,大概率是噱头。答案是「每次都要手动处理、很烦」的,就值得装。
安装命令格式上,大部分走 npx skills add,少数需要 git clone 到 ~/.claude/skills/ 目录,官方维护的走 /plugin install 路径。
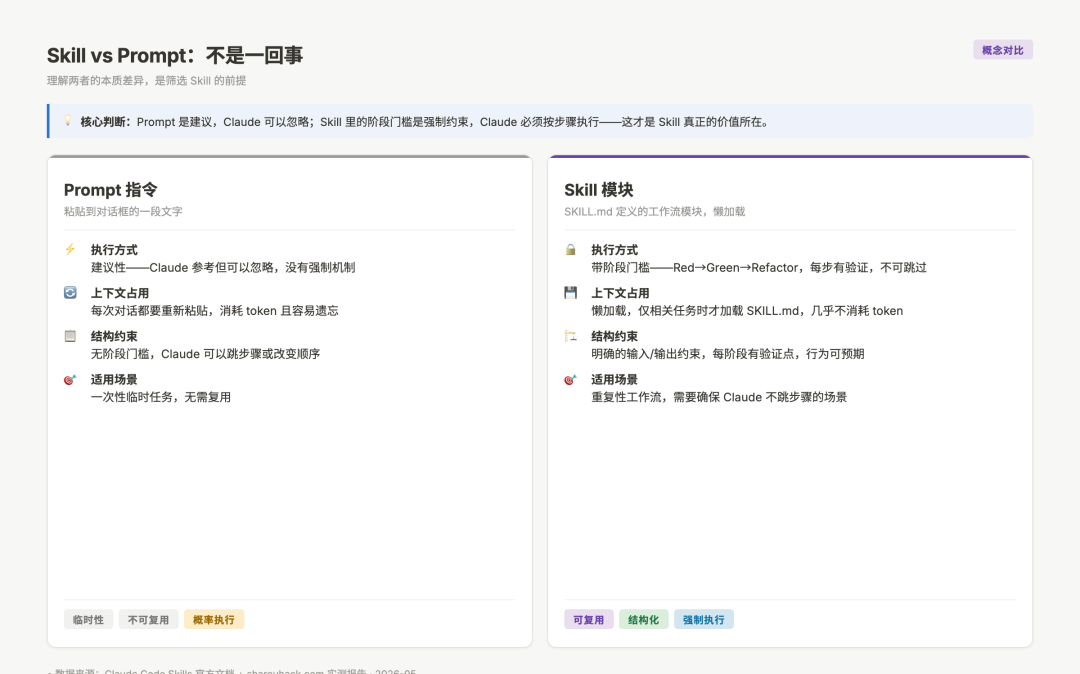
Skill vs Prompt:本质差异对比
图:Skill 的阶段门槛机制 vs Prompt 的建议性执行,两者执行方式的本质差异
第一类:工程提效(6个)
这几个是日常编码频率最高、留下来最理所当然的。
Superpowers(obra/superpowers,213,000★)
这个生态里星数最高的项目,名字有点大,但内容是真实的。它不是一个单独的 Skill,是一个包含 20+ 个子模块的工作流框架:TDD、系统化调试、计划编写、代码评审、并行 Agent 分发、Git Worktree 管理……每个都是独立的、可以单独触发的 Skill。
安装命令:npx skills add obra/superpowers
我实际留下的子模块是:test-driven-development(强制红灯先行,不允许跳)、systematic-debugging(先推理根因再改代码)、writing-plans(多步骤任务先出文件再动手)。剩下的模块按需用,不强制。
为什么有 213K 星?因为它真正解决了 Claude 最常见的问题:直接动手改代码,不思考,不测试,改了再说。Superpowers 把这个坏习惯用结构强制打断了。
Karpathy Guidelines(forrestchang/andrej-karpathy-skills,125,436★)
Andrej Karpathy 总结的 AI 编码规则,被人整理成了 Skill。核心规则四条:读代码前先思考(不是直接开始 grep)、修改要精准(不是「重写这个文件」)、优先简洁(不是「加功能」)、始终核对原始需求。
安装:/install forrestchang/andrej-karpathy-skills
这个 Skill 的价值在于它改变的是 Claude 的行为模式,而不是提供某个工具。新起一个项目的时候特别有效——Claude 会更倾向于先理解再动手,而不是信心满满地直接开始重构。
gstack(garrytan/gstack,93,947★)
Garry Tan(YC CEO)维护的 Skill,名字来源是「Gut Stack」——他自己实际在用的技术栈配置。主要覆盖全栈项目脚手架(TypeScript、React、Supabase、Vercel)、最佳实践检查、部署流程自动化。
安装:git clone https://github.com/garrytan/gstack.git ~/.claude/skills/gstack
坦白说我没有完整用到它所有功能,但它的 TypeScript 类型检查和 Supabase Schema 验证我开了——每次新建接口或者改表结构的时候,Claude 会主动跑一遍再提交。这个减少了我代码评审时的低级错误。
Frontend Design(anthropics/skills,277,000+ 周安装)
官方维护的前端 UI Skill,目标是解决一个真实问题:AI 生成的 UI 都长一个样,一眼就能认出来是 AI 写的——按钮颜色、spacing、字体选择全都是默认值加 Tailwind。
安装:npx skills add https://github.com/anthropics/skills --skill frontend-design
它的核心是提供了一套视觉决策框架,让 Claude 在生成 UI 时会主动挑选对比色、考虑层级关系、避免过度对称。我在做内部工具的时候感觉最明显——同样的需求,装了 Skill 之后的结果明显比没装的更「像是人设计过的」。
Document Skills(anthropics,DOCX/PDF/PPTX/XLSX 套件,132,393★)
官方出的文档生成套件,装一次可以处理四种格式。核心价值:让 Claude 直接输出带格式的二进制文件,而不是输出 Markdown 然后自己再转。
安装:npx skills add https://github.com/anthropics/skills --skill pdf(其他格式类似)
这个 Skill 的适用场景比较窄,但很实在:需要频繁生成报告、内部文档、数据导出的工程师。如果你每天只写代码,它可能用不上;如果你要写技术文档或者给非技术人发报告,它会节省大量时间。
Trail of Bits Security(trailofbits/skills)
Trail of Bits 是业内顶级安全审计公司,这个 Skill 把他们的安全审查清单封装了进来。会针对代码主动检查注入攻击路径、权限提升风险、加密实现错误等。
安装:npx skills add trailofbits/skills
这个 Skill 在我做接口层代码评审时留下的。之前 Claude 默认的代码建议不会主动提安全问题,装了之后遇到用户输入处理的代码,它会补充提示可能的 SQLi 或 CSRF 路径。不是说 Claude 变成了安全专家,但至少多了一层提醒。
第二类:多 Agent 编排(5个)
这类 Skill 是 2026 年生态里增长最快的方向,也是噱头最多的地方。多 Agent 叙事很吸引人,但真正能在日常工程里落地的,没几个。
TDD(superpowers 子模块,186,724★)
单独拎出来说,因为它是 Superpowers 里我用得最高频的部分。核心机制是三个强制阶段:Red(必须先写一个失败的测试)→ Green(写最少的代码让测试通过)→ Refactor(再整理)。每个阶段之间有明确的验证点,Claude 不能跳过。
这不是新东西,TDD 大家都知道。但 Claude 没有约束的时候天然倾向于直接写实现代码,测试留到最后或者干脆不写。这个 Skill 把流程锁住了。
Ruflo(ruvnet,49,143★)
Ruflo 是一个多 Agent 编排平台的 Skill 集成,让你可以在 Claude Code 里设计 Agent 流水线——一个 Agent 负责研究,一个负责写代码,一个负责验证,结果传递下去。
安装要先搭 Ruflo 服务:npx create-ruflo-app my-project
坦白说,我装了两周后卸载了。原因是:我大部分项目的复杂度根本不需要多 Agent 流水线。Ruflo 解决的是 100+ 步骤的大型 AI 工作流问题,如果你在做的是普通业务开发,它给你的工程复杂度比节省的时间更多。
它不是噱头,它解决真实问题——只不过不是我的问题。
Superpowers: Dispatching Parallel Agents(superpowers 子模块)
多个独立子任务真正并行跑,每个任务一个 Agent,最慢的那个完成了整体才完成。这个在大型重构里有用:前端改造、后端接口更新、测试补全可以同时跑。
我在做一次跨模块重构时用过,节省了大约 40% 的等待时间。但前提是任务之间真的独立,如果有依赖关系,并行变串行还容易出错。
Awesome Claude Code Subagents(19,580★)
社区维护的子 Agent 配方库,里面有各种预设好的「特化 Agent」——数据库 Agent、文档 Agent、测试 Agent……思路是好的,执行质量参差不齐。
装了但只用了数据库 Agent,其他的我自己写了更符合项目约束的版本。这类 Skill 更像是模板库而不是即插即用的工具,适合有定制需求的团队,不适合直接拿来就用。
Loki Mode(loki-mode)
37 个 AI Agent 组成的自主系统,宣称可以「完全自主完成复杂工程任务」。
我装了三天卸载了。不是因为它不能跑,是因为它太自主了——修改了我没想改的文件,在没确认的情况下提交了代码,把一个正在运行的函数重构成了「更好的版本」。可能在沙箱环境里很有用,在生产代码库里我不敢放开。
留个印象,等它再成熟一些。
第三类:记忆与上下文(4个)
上下文窗口是 Claude Code 的真实瓶颈,这类 Skill 在解决一个具体问题:怎么让 Claude 记住更多的项目知识。
Claude Mem(74,903★)
这个数字靠谱,这个 Skill 也靠谱。核心功能:自动提取每次会话里出现的重要决策、约束、架构选择,存到结构化的记忆文件里,下次会话自动加载相关部分。
安装:npx skills add claude-mem/claude-mem
实测效果:在一个 3 个月的项目里,它帮我省掉了每次开新 Session 都要重新解释「这个字段为什么这样设计」的时间。不是完美的,会有噪声记忆,但整体值得。
Claude Context(10,955★)
比 Claude Mem 轻量,只做一件事:把当前项目的核心上下文(CLAUDE.md + 关键决策文件)压缩成最小的 token 量,在每次对话开始时注入。
对话轮次变多之后上下文膨胀是个真实问题,这个 Skill 帮你在精度和 token 消耗之间找平衡。
ccstatusline(9,031★)
不改变 Claude 的行为,只是给你一个终端状态栏,显示当前 Session 用了多少 token、大概还剩多少预算、有没有在跑 tool call。
听起来是小工具,但当你开始关注成本的时候,这个可视化信息很有价值。我接入了它之后才开始意识到,很多会话的 token 消耗集中在哪些环节。
CC Switch(67,412★)
在不同 Claude 模型之间切换的 Skill,核心价值是成本管理:简单任务走 Haiku(便宜),复杂推理走 Opus(强但贵),代码生成走 Sonnet(平衡)。
安装:npx skills add cc-switch/cc-switch
这个 Skill 的实用性在于它让切换模型变成了一个有意识的动作,而不是每次都默认最强的。我开始用它之后,月账单降了大概 35%,同时大部分任务的完成质量没有明显下降。
第四类:文档与办公(3个)
这类 Skill 在纯工程师圈子里存在感低,但其实有几个很实用。
Graphify(safishamsi,46,746★)
从代码库自动生成关系图:函数调用图、模块依赖图、数据流图。对接手一个新项目、做架构评审、或者理解老代码特别有用。
安装:pip install graphifyy && graphify install
我第一次用它时是接手了一个运行了两年的 Python 服务,Graphify 在 3 分钟内给我画出了模块依赖关系,比我自己读代码快了一下午。
Planning with Files(20,925★)
让 Claude 在多步骤任务开始前,先把计划输出成 Markdown 文件,明确每步的目标、依赖、验证标准,再开始执行。
核心价值:计划变成了一个可以检查、可以修改、可以追溯的文件,而不是存在 Claude 上下文里的一堆文字。任务失败了可以看计划,找到偏差在哪里。
Claudian(Obsidian 插件,10,954★)
把 Claude Code 和 Obsidian 笔记库打通的 Skill,让 Claude 可以读写你的知识库文件。
这个对写技术文档、维护设计文档的工程师有用,对大部分纯编码岗位可能感知不强。我装了,主要用来生成和更新 ADR(架构决策记录)文件。
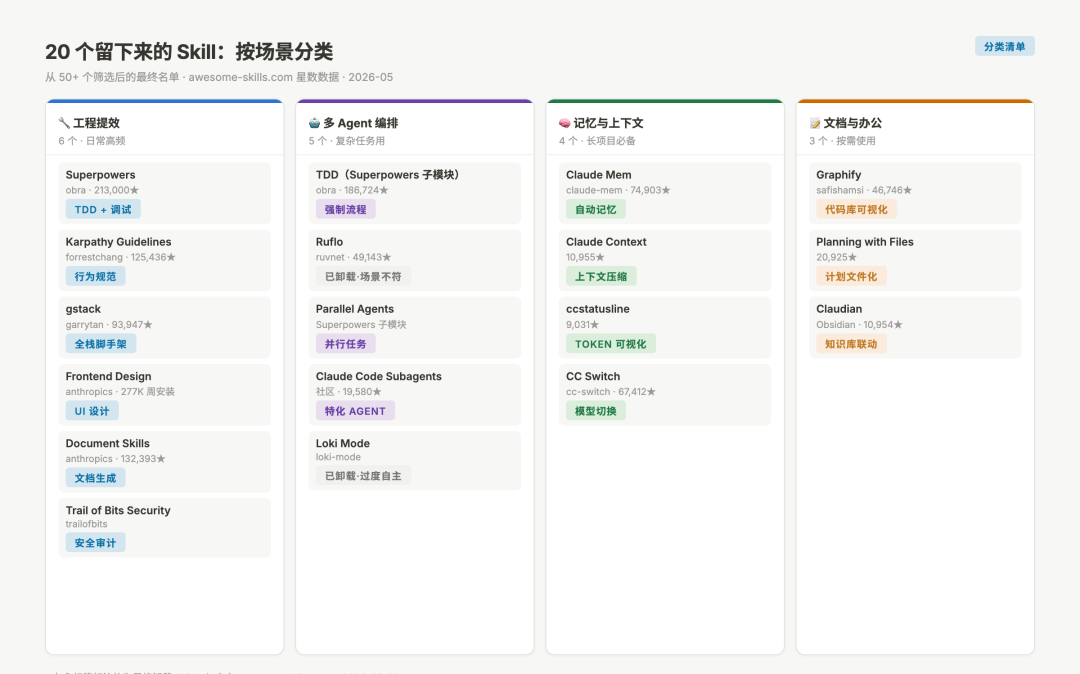
20个留下的 Skill 分类总览
图:按工程提效、多 Agent 编排、记忆与上下文、文档办公四类整理的 Skill 清单,含 awesome-skills.com 星数
那些没留下来的,都是什么问题
说了这么多留下的,简单说几类被踢出去的。这部分可能比留下来的名单更有用——因为它帮你在装之前就过滤掉大部分浪费时间的选择。
功能太窄、场景太特定:比如有个 Skill 专门生成 Kubernetes Helm Chart 的注释,功能没问题,逻辑也清晰,但我们项目不用 K8s,装了等于白装。这类 Skill 的问题不是质量差,是受众太窄。装之前先想清楚:这个 Skill 服务的场景,在你的日常工作里每周出现几次?少于 1 次的,考虑不装。
安装复杂、收益太低:有的 Skill 需要搭本地服务、配置 API Key、设置 Webhook,走完五步安装流程,换来的是「Claude 在回复末尾加了一个 emoji」。安装成本和使用收益不匹配,是很多社区 Skill 的通病。好的 Skill 应该是「一行命令装完,第二天就能感受到差异」——如果装完了一个星期都不确定它有没有在生效,卸载不亏。
过度自主、边界模糊:这类最危险。Skill 描述里写「Claude 会自动处理」,实际上 Claude 会在你没意识到的时候自主决策修改代码。Loki Mode 是典型,我装了三天,它帮我「优化」了一个正在运行的核心函数,提交了代码,然后告诉我「已完成」。在沙箱环境或者测试项目里完全没问题,但在生产代码库里,这种自主性是风险不是优势。判断标准:这个 Skill 有没有在关键操作前问你「是否继续」?没有确认机制的 Skill,在生产代码库里要谨慎。
纯 prompt 包装、没有结构:这是最常见的一类。有一批 Skill 本质上只是把一段 prompt 包装成了 SKILL.md 格式,没有阶段门槛、没有验证机制、没有输入输出约束。Claude 很可能直接忽略——或者在第一次触发时用,之后就不用了。这类 Skill 的 README 写得最好,看起来功能强大,用起来效果和没装差不多。识别方法:打开 SKILL.md,如果全文都是说明性文字、没有任何「步骤 N:验证 X 通过后才能继续」的结构,大概率是纯 prompt 包装。
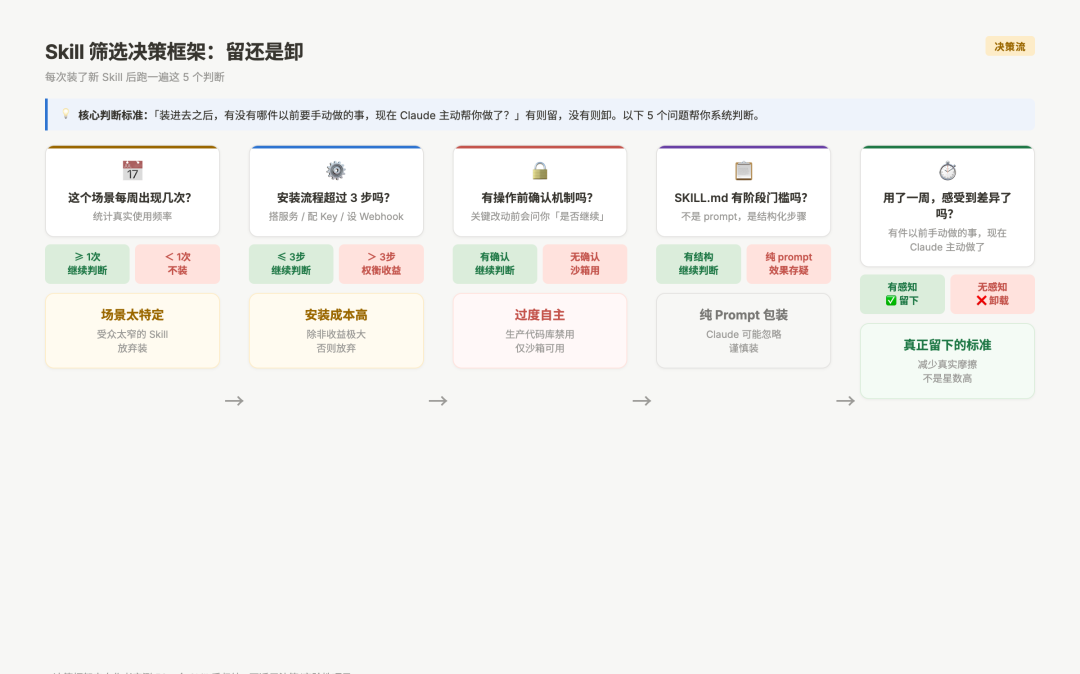
Skill 筛选决策框架
图:5 步筛选决策框架——从使用频率到一周实测,系统判断一个 Skill 留还是卸
常见问题
Q:Skill 装了 Claude 一定会用吗?
不一定。Skill 加载是基于相关性判断的,Claude 会评估当前任务是否和 Skill 的描述匹配。你可以用 /skill-name 手动触发,或者在任务描述里带出 Skill 的关键词。如果发现装了没用,先检查 SKILL.md 里的触发描述写得够不够具体。
Q:这些 Skill 会影响 Claude 的 token 消耗吗?
Skill 文件是懒加载的,不相关的任务里不会加载,所以大部分情况下成本影响很小。但如果你装了大量会在每次对话里自动触发的 Skill,累积起来也会有影响。CC Switch 这类专门管成本的 Skill 能帮你看清楚。
Q:多个 Skill 之间会冲突吗?
会,但不常见。最常见的冲突是两个 Skill 的触发描述太相似,Claude 不确定该用哪个。解决方法:给相互关联的 Skill 做优先级标记(在 frontmatter 里写 priority: high),或者精简触发描述。
Q:怎么知道一个 Skill 值不值得装?
看三个指标:star 数(参考,不是决定因素)、README 里有没有明确的「触发条件」描述(模糊描述的 Skill 通常也会被 Claude 模糊执行)、有没有维护者在 GitHub 持续更新。一个六个月没更新的 Skill 和 Claude Code 最新版本可能已经不兼容。
Q:有没有 Skill 发现目录,不用一个个翻 GitHub?
awesome-skills.com 是目前最全的目录,按 star 数排序,有安装命令。travisvn 维护的 awesome-claude-skills 仓库也值得看,侧重质量筛选而不是数量。
总结
装 Skill 这件事和招人有点像——简历写得漂亮的不一定是好的,平时话不多但每次开口都有用的才是真正的生产力。
这 20 个留下来的,不是星数最多的,是在我实际工作流里真正减少了摩擦的。你的情况可能不一样,但筛选的逻辑应该相通:装进去之后,有没有哪件以前要手动做的事,现在 Claude 主动帮你做了? 有,就留。没有,卸载。
写完这篇码哥自己也重新过了一遍 skills 目录,发现还有两个可以清理的。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-04,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号