Claude Coding 翻车,82% 的锅都在任务描述的开头,加了这几行,首次成功率从 23% 涨到 70%+

Claude Coding 翻车,82% 的锅都在任务描述的开头,加了这几行,首次成功率从 23% 涨到 70%+

码哥字节
发布于 2026-06-03 19:18:06
发布于 2026-06-03 19:18:06
用了 Coding Agent 一段时间,你大概遇到过这种情况:
任务交下去,Agent 跑了七八分钟,打开一看——方向错了。它写了一套认为「对」的实现,但就是和你想要的差了两三个关键决策。你开始改需求、补说明、再跑一遍,又是十分钟出去了。
这个循环我经历过很多次,直到我意识到:问题不在 Agent,在我自己的任务描述。
Anthropic 最新发布的 2026 年 Agentic Coding Trends 报告揭示了一个让人有点难受的数字——开发者使用 AI 完成约 60% 的工作量,但只能「完全委托」0-20% 的任务。大量时间被浪费在反复修正和重新跑 Agent 上。而更扎心的研究数据来自对 Coding Agent 失败案例的分析:82% 的 agent 任务失败,根源在规划阶段,不是执行阶段。
换句话说,Agent 跑偏,大多数时候是任务描述出了问题,不是模型能力不够。
做了十年服务端和架构,我最近把写任务描述这件事认真想了一遍,发现它和传统的需求分析有着高度的相似性——都是「先定约束,再谈实现」。摸了几个月下来,总结出一套 5 段式开头模板,今天系统写一下。
你的任务描述,可能少了这些东西
有个反直觉的现象:越是有经验的工程师,越容易在给 Coding Agent 布置任务时出问题。
原因是:我们已经习惯了隐式传递信息。和同事沟通时,「加个用户登录功能」这几个字背后有大量你们共享的上下文——你们用同一套技术栈,你知道他知道代码规范,他知道数据库的表结构……这些东西你不用说,他自然懂。
但 Coding Agent 不是你的同事,它在没有你告诉它的情况下,对这些上下文一无所知。
研究人员对 Coding Agent 失败案例做了归因分析,最常见的三个原因是:
- 上下文不足:Agent 看不到既有架构和系统约束,只能「合理猜测」,猜测结果可能与你的期待相差甚远
- 边界模糊:任务范围没有清晰定义,Agent 不知道「做完了」是什么样子
- 没有验收标准:缺少「什么情况算成功」的明确定义,Agent 无法自我校验
你可能觉得这三条都是废话,但我最近回顾自己写过的任务描述,发现这三条几乎没有同时满足过。
真正有趣的是数据:没有结构化规划时,复杂 agent 任务的首次成功率大约是 **23%**。加上结构化的任务说明文档后,这个数字升到了 **61%**——接近 3 倍的提升,靠的不是换更好的模型,是换更好的任务描述。
先定约束,再说实现——10 年经验给我的底层逻辑
做了十年架构,有一件事我越来越笃定:好的需求文档和烂的需求文档,最大的差距不在「写了什么功能」,而在「定义了哪些约束」。
传统软件工程里,做需求分析有一套经典流程:先明确现有系统边界 → 定义非功能性需求(性能、安全、兼容性)→ 梳理隐式约束 → 最后才写功能实现。功能是最容易变的,约束才是最难改的。
我第一次把这个逻辑套在 Coding Agent 任务描述上,效果出奇的好。
把 Coding Agent 想象成一个新来的外包工程师——水平很强,执行力极高,但对你的系统完全陌生。你会怎么给他布置任务?你一定会先给他讲现有架构,告诉他哪些地方动不得,哪些是历史包袱,哪些是团队规范……然后才开始说这次要做什么。
这就是 5 段式开头模板的底层逻辑:不是把任务说清楚,而是把约束交代清楚。
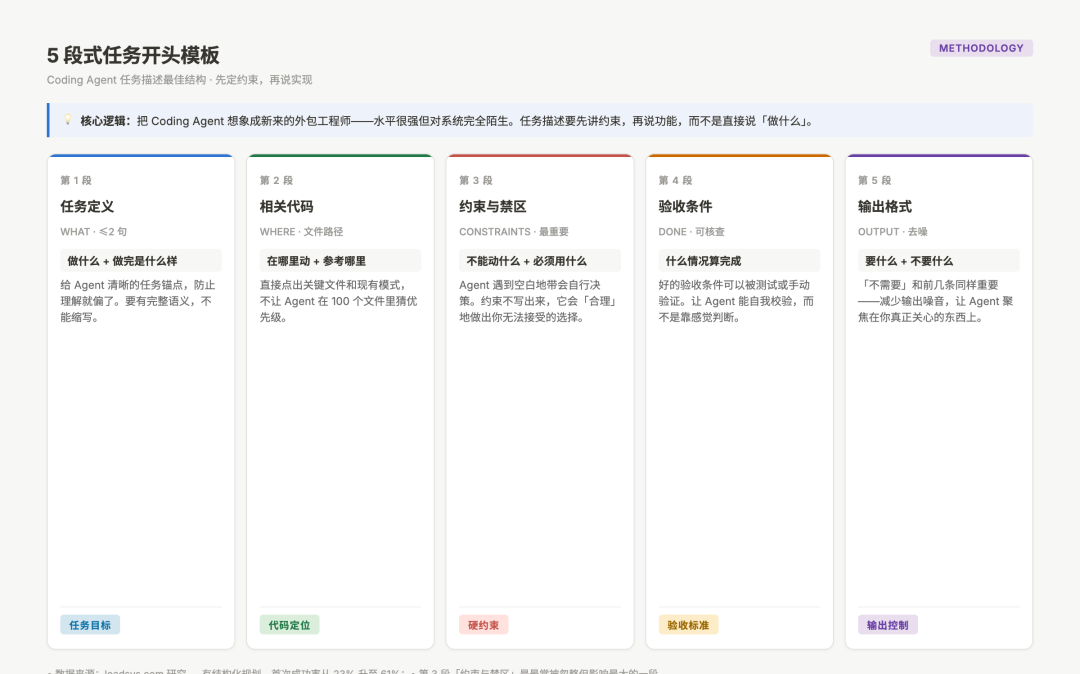
5段式任务开头模板结构图
图:5 段式开头模板的结构与每段核心内容
5 段式任务开头模板
这套模板不是让你把任务写长,而是让你把关键信息写在开头。每段都有它不可替代的作用。
第一段:一句话任务定义(What,≤ 2 句)
目的:给 Agent 一个清晰的任务锚点,防止它在理解上就偏了。
这段要做到两件事:说清楚做什么,以及做完是什么样子。不要用动词 + 名词的缩写形式(「加登录」「改接口」),要给出完整语义。
# 任务:为用户中心服务新增 OAuth 2.0 Google 登录功能
# 预期结果:用户点击「Google 登录」后,完成 OAuth 授权流程,在数据库中创建或关联用户记录,
# 返回 JWT token,整个流程无需重定向到外部页面(使用 Popup 模式)。
踩坑提醒:如果你说「加个 OAuth 登录」,Agent 可能会问你用哪个 OAuth,也可能直接选一种去实现,选的不一定是你想要的。「一句话」的标准是:另一个工程师看完,不需要追问就能开始干。
第二段:相关代码 & 现有结构(Where,文件路径 + 模式说明)
目的:告诉 Agent 在哪里动、参考什么已有实现。
这是最被忽视的一段。很多工程师以为 Agent 会自己扫代码——它会,但它会「猜」优先级,可能读了 100 个不相关文件,漏了 2 个最关键的文件。与其让它猜,不如你直接点出来。
# 相关文件:
# - src/auth/auth.service.ts(现有的 JWT 认证逻辑,新功能应遵循同样的 token 生成方式)
# - src/user/user.entity.ts(用户实体,Google 登录需要新增 googleId 字段)
# - src/auth/strategies/(现有的 Passport.js strategy 目录,新的 Google strategy 放这里)
# 现有模式:项目使用 NestJS + Passport.js,JWT token 结构见 auth.service.ts:generateToken()
# 已有 GitHub OAuth 实现作为参考:src/auth/strategies/github.strategy.ts
这段还有一个隐藏价值:你在给 Agent 看参考实现的同时,也在告诉它「这里有个已有的模式,沿用它,不要自己重新发明」。
第三段:约束与禁区(Constraints,必须明确列出)
目的:防止 Agent 在「空白地带」做出你无法接受的决策。
这是最重要的一段。Coding Agent 遇到没有说明的情况,默认行为是「做一个它认为合理的决定」。而它认为合理的,可能和你的架构要求、团队规范、或者历史包袱完全不一致。
约束有几类,都要写:
# 技术约束:
# - 不能引入新的 OAuth 库(项目已用 passport-oauth2,扩展它)
# - 不修改现有的 JWT token 结构(其他服务依赖当前格式)
# - Google Client ID/Secret 已在环境变量 GOOGLE_CLIENT_ID / GOOGLE_CLIENT_SECRET 中
# 边界约束:
# - 本次只做 Google 登录,不做 Apple、GitHub 的统一 OAuth 抽象(留给下一个 PR)
# - 不改动用户表的其他字段,只新增 googleId(可为 null)
# 测试约束:
# - 需要写单元测试,不需要 e2e 测试(e2e 环境需要真实 Google 账户)
我见过太多 Agent 任务跑偏,原因是 Agent 发现「这里可以做得更好」就顺手做了——引入了一个更好的库、重构了一段看起来混乱的代码、把几个相关功能打包一起改了。这些「顺手」在没有约束说明的情况下是合理的,但可能把你的 PR 范围撑大三倍。
第四段:验收条件(Done,可以核查的标准)
目的:让 Agent 有自我校验的能力,减少「以为做完了但没做完」的情况。
好的验收条件是可以被代码测试或手动验证的,不是「功能正常工作」这种模糊描述。
# 完成标准:
# 1. POST /auth/google/callback 接口正确处理 Google OAuth 回调,返回 { accessToken, user }
# 2. 首次登录:在 users 表创建新记录,googleId 字段有值
# 3. 二次登录同一 Google 账号:关联到已有用户,不创建重复记录
# 4. 用 googleId 已存在但 email 不同的情况:返回明确错误(Google 账号切换场景)
# 5. 单元测试:google.strategy.spec.ts 覆盖上述 3 个场景,全部通过
这段写好的另一个好处是:当 Agent 做完说「我完成了」,你可以逐条核对,不需要靠感觉判断。
第五段:输出格式(Output,告诉 Agent 你要看什么)
目的:减少输出噪音,让 Agent 把注意力放在核心实现上。
# 完成后输出:
# 1. 改动的文件清单(路径 + 改了什么)
# 2. 新增的数据库迁移 SQL(googleId 字段)
# 3. 本地测试命令(怎么验证这个功能工作)
# 4. 已知局限(如果有什么没实现或有风险的,主动告知)
# 不需要:完整代码解释、架构分析、「下一步可以做」的建议
最后一行「不需要」和前面几行同样重要——它告诉 Agent 不要生成你用不到的内容,减少上下文噪音,让输出聚焦在你真正关心的东西上。
Before / After:同一个任务,不同描述的差距
说再多理论,不如看一个对比。
同样是「给项目加速率限制功能」,两种写法:
Before(常见写法):
给这个 API 服务加上 rate limiting,防止被恶意调用。
After(5 段式写法):
# 任务:为 API 服务新增请求速率限制,保护服务不被恶意请求打垮
# 预期结果:每个 IP 每分钟最多 100 次请求,超出返回 429 Too Many Requests,
# 带 Retry-After 响应头
# 相关文件:
# - src/main.ts(NestJS 入口,中间件在这里注册)
# - src/app.module.ts(模块配置)
# 参考:项目 README 中提到「我们使用 Redis 存储会话状态,rate limiting 应使用同一个 Redis 实例」
# 约束:
# - 使用 @nestjs/throttler(项目已安装),不引入新依赖
# - 速率限制配置走环境变量 RATE_LIMIT_TTL / RATE_LIMIT_LIMIT,不硬编码
# - /health 和 /metrics 端点排除在速率限制之外
# - 不影响现有的认证中间件顺序
# 验收:
# 1. 连续发 101 次请求,第 101 次返回 429
# 2. 429 响应头包含 Retry-After
# 3. /health 不受限制
# 4. throttler 配置可通过环境变量覆盖
# 输出:改动文件 + 如何本地测试(curl 命令)
差距在哪:Before 版本给了 Agent 极大的自由度,它可能:选择用 Redis 也可能用内存存储、可能全局生效也可能只给部分路由加、可能硬编码配置也可能走配置文件——每个决策都是合理的,但可能都不是你想要的。
After 版本把这些决策提前做了,Agent 只需要执行,不需要猜你的想法。
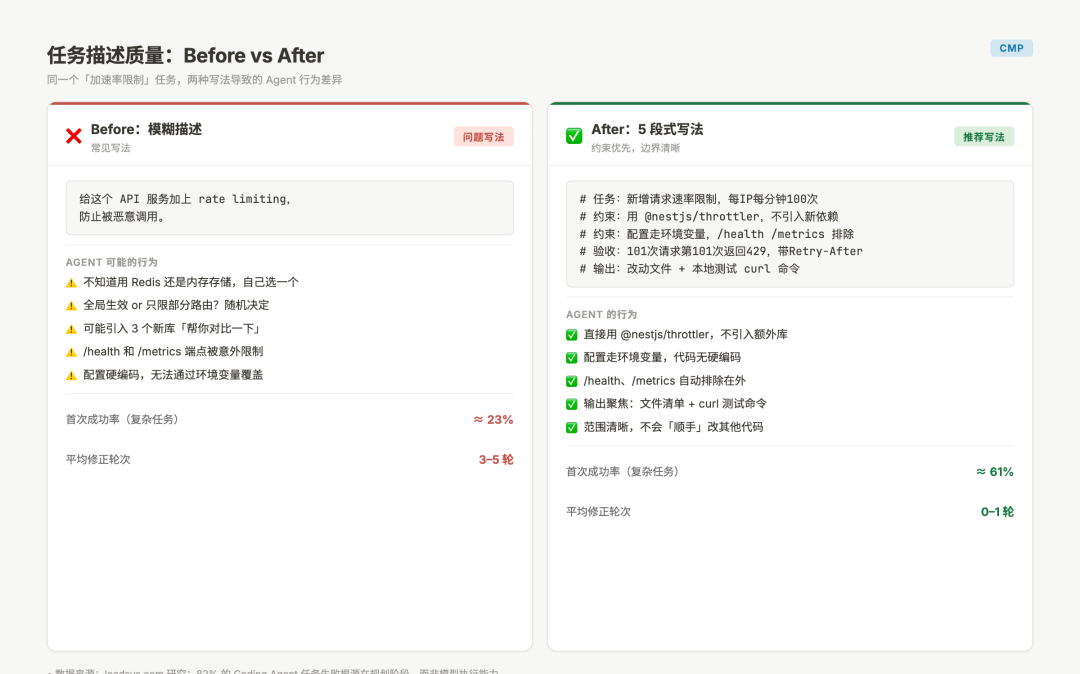
Before After 任务描述对比
图:同一任务的两种描述方式对比,以及各自导致的 Agent 行为差异
CLAUDE.md:把项目级约束「一次说清楚」
上面的 5 段式模板解决的是「单次任务」的问题。但有些约束是整个项目层面的——你不可能在每个任务里都重复一遍「不要用 any 类型」「代码注释用中文」「测试覆盖率不低于 80%」。
这就是 CLAUDE.md 的价值所在:把项目级别的约束沉淀下来,不占用每次任务的上下文空间。
一个设计良好的 CLAUDE.md 结构是三层:
第一层 WHAT(是什么):技术栈、架构、关键目录结构
## 技术栈
- NestJS + TypeScript,严格模式
- PostgreSQL(通过 TypeORM 访问),Redis(会话 + 缓存)
- 单元测试用 Jest,e2e 测试用 Supertest
## 目录结构
src/
auth/ # 认证模块,JWT + OAuth
user/ # 用户模块
common/ # 共享工具(拦截器、守卫、装饰器)
第二层 WHY(为什么):不明显的决策背景,代码里看不出来的
## 架构决策记录
- 使用 UUID 而非自增 ID:防止枚举攻击(2024年安全审计要求)
- 不使用 Prisma:团队已有 TypeORM 经验,迁移成本高于收益
- 统一用 Result 类型返回错误:内部服务调用需要区分业务错误和系统错误
第三层 HOW(怎么做):命令、工作流、团队规范
## 开发命令
npm run start:dev # 开发模式
npm run test:unit # 单元测试
npm run migration:run # 跑数据库迁移
## 代码规范
- 函数命名:动词 + 名词(getUserById,createOrder)
- 不要在 Controller 层写业务逻辑,必须在 Service 层
- 每个新功能必须有对应的 DTO 和 Swagger 注解
有一条经验:CLAUDE.md 控制在 300 行以内。有研究表明,超过这个量级,边际信息开始被 Agent 忽视——上下文窗口里装的东西太多,后半部分的权重会降低。把 CLAUDE.md 当成一份「精选约束清单」,不是「什么都往里塞的配置文件」。
子目录可以有自己的 CLAUDE.md,覆盖父目录的部分规则。比如 src/auth/CLAUDE.md 只写认证模块的特定约束,不用重复全局规则。
常见问题
Q:5 段式模板这么写,任务描述是不是太长了?每次都要写这么多?
A:不是每次都写满。简单的单文件改动(改一个函数的逻辑、加一个字段)第二、五段可以省略。5 段式模板是提醒你「这几类信息都考虑到了吗」,不是强制每段都写。复杂任务(涉及多个模块、有数据库变更、会影响其他服务)全段写完是值得的——节省的修正时间远超写描述的时间。
Q:CLAUDE.md 里的内容 Agent 真的会读吗?
A:Claude Code 会在每次对话开始时自动加载项目根目录和相关子目录的 CLAUDE.md。但要注意两点:第一,内容太多会被「稀释」,重要约束放前面;第二,在任务描述里显式提到 CLAUDE.md 里的某条规则(「注意 CLAUDE.md 里关于 UUID 的规范」),效果优于只靠 CLAUDE.md 被动加载。
Q:给 Agent 加了这么多约束,会不会让它「太受限」反而发挥不出来?
A:约束针对的是「架构决策」和「边界范围」,不是「实现细节」。告诉 Agent「用 passport-oauth2,不引入新库」不会限制它;不告诉它这个,它可能引入三个不同的 OAuth 库帮你「比较一下」。让 Agent 在对的边界内自由发挥,比让它在全空间里随机漫步效果好得多。
Q:任务跑到一半,发现 Agent 跑偏了,怎么办?
A:及时打断比等它跑完再重来更好。Claude Code 允许在任务执行中途输入新指令修正方向。如果偏差大,直接 Escape 中断,修改任务描述重跑,比在已经跑偏的基础上继续修要省时间。下次同类任务时,把这次的修正点补进任务模板。
Q:这套方法对 Cursor 也适用吗?
A:核心逻辑完全适用,5 段式模板可以直接用在 Cursor 的 Chat 输入里。Cursor 的 .cursorrules 文件对应 CLAUDE.md 的功能,结构设计思路一样——三层 WHAT/WHY/HOW,控制在合理行数以内。工具换了,但「先定约束,再说实现」的逻辑不会变。
总结
写完这篇,码哥自己也对照着重新审了一遍最近的几个任务描述——发现漏了约束的地方比想象的多。
写任务描述这件事,说到底是一种工程师的训练:你对系统架构理解越深,就越知道哪些约束是 Agent 必须提前知道的。
下一篇打算聊 Coding Agent 的「尾」——任务完成后的 review 和验收怎么做才不吃亏,感兴趣的关注一下。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-31,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号