Opus 蒸馏 Qwen3.5 Coder 来了,工具调用卷到满分,MTP加速,上下文拉到128K,消费级显卡轻松部署

Opus 蒸馏 Qwen3.5 Coder 来了,工具调用卷到满分,MTP加速,上下文拉到128K,消费级显卡轻松部署

Ai学习的老章
发布于 2026-06-02 14:34:57
发布于 2026-06-02 14:34:57
大家好,我是 Ai 学习的老章
老朋友Jackrong又出新活儿了
这次带来的是 Qwopus3.5-4B-Coder-MTP-GGUF,一个只有 4B 参数的 Agent 编程模型,在工具调用测试中直接拿了满分。你没看错,100/100,一分没丢
它真的很小巧,8G的小卡都能随便选了
简介
Qwopus3.5-4B-Coder-MTP-GGUF 是 Jackrong 基于 Qwen3.5 4B 微调出来的,专门针对三个场景优化:代码调试、工具调用、结构化推理
说白了就是一个为本地跑 Agent 工作流设计的小模型。4B 参数意味着 8 GB 内存的笔记本就能跑起来,不需要 A100 也不需要上云
训练方法比较有意思,用了三板斧:
- Trace Inversion:从执行轨迹反向学习
- 高质量 Agent 轨迹数据:直接学优秀 Agent 的行为模式
- Curriculum SFT:课程式微调,循序渐进
最关键的技术亮点是 MTP(Multi-Token Prediction),设置 n=2,实测推理速度可以达到普通推理的 1.4-2.2 倍,精度不变。这对本地部署来说太重要了,小模型本来就不快,能加速一倍多等于白捡的性能
MTP 加速原理
MTP 的核心思路很简单:传统自回归每一步只预测 1 个 token,而 MTP 让模型同时预测当前 token 和下一个 token。相当于模型每走一步就能"看到"两步远的结果
这跟投机解码(Speculative Decoding)思路类似,区别在于 MTP 是训练时就内置的能力,不需要额外的 draft model。实际加速效果取决于预测命中率——代码场景因为模式重复性强,命中率天然更高,所以在编程任务上加速效果最明显
下图直观展示了传统方式和 MTP 的区别:
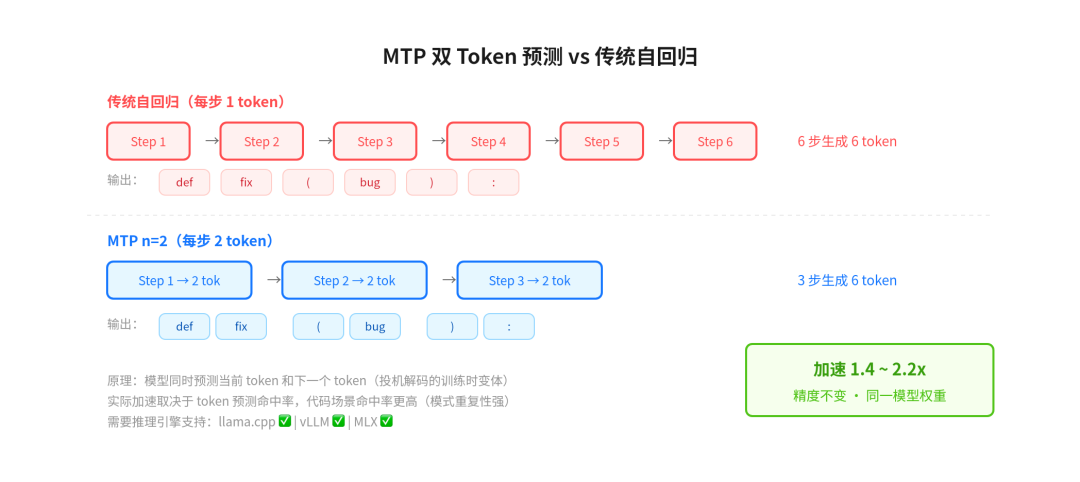
MTP 双 Token 预测 vs 传统自回归
MTP 双 Token 预测 vs 传统自回归
需要注意的是,MTP 需要推理引擎支持。目前 llama.cpp、vLLM、MLX 都已支持 MTP 推理,所以主流本地部署方案都能用上这个加速
下面这张图展示了从基座模型到训练再到量化部署的全流程:
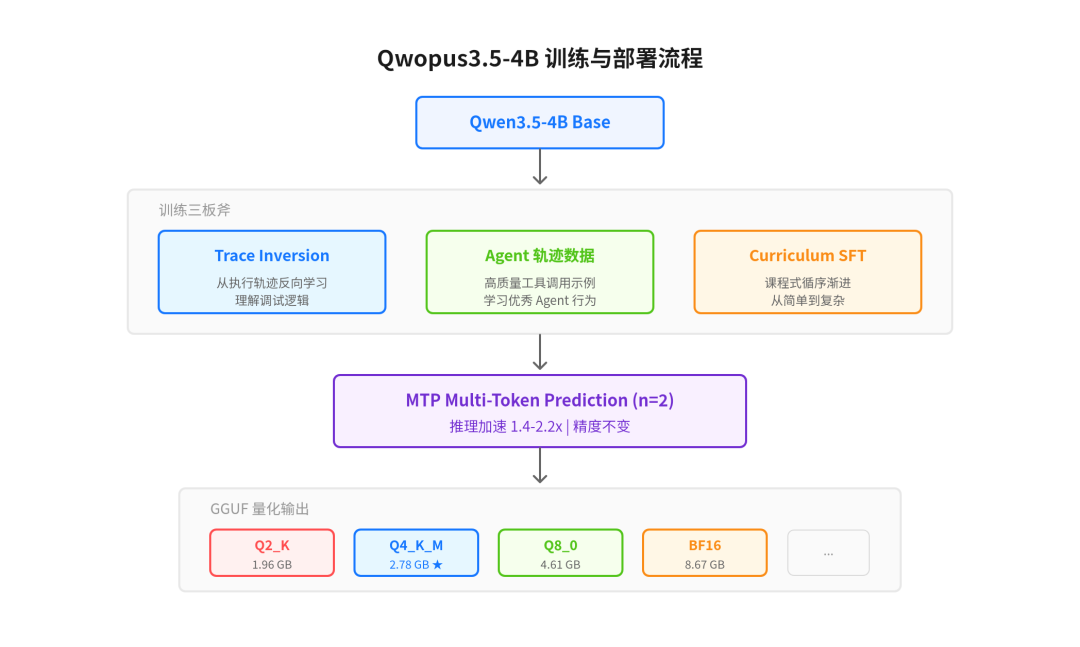
Qwopus3.5-4B 训练与部署流程
Qwopus3.5-4B 训练与部署流程
跑分
先看跑分,用的是 benchlocal 评测框架(专门为本地 MTP 模型设计的):
测试项 | 得分 | 比基线高 | 说明 |
|---|---|---|---|
BugFind-15 | 71/100 | +19 | 找 Bug 能力遥遥领先 |
HermesAgent-20 | 64/100 | +3 | 记忆和工作区管理更好 |
ToolCall-15 | 100/100 | +10 | 工具调用满分 |
InstructFollow-15 | 93/100 | 0 | 指令遵循与基线持平 |
用柱状图看更直观——蓝色是 Qwopus,橙色是 Qwen3.5-4B 基线:
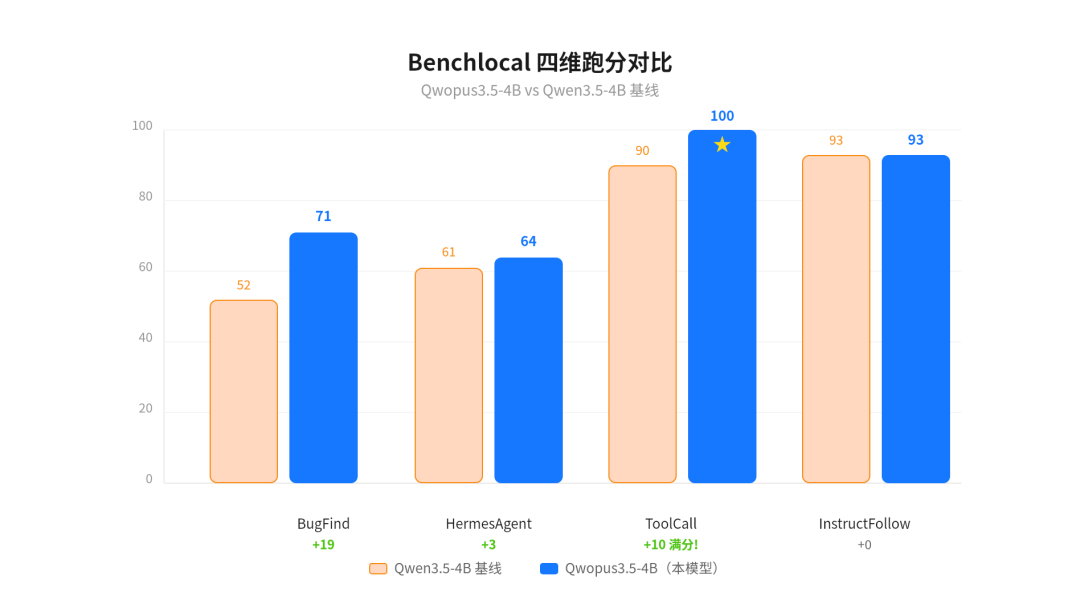
Benchlocal 四维跑分对比
Benchlocal 四维跑分对比
几个关键结论拆开说说:
BugFind +19 是最大亮点。找 Bug 这个能力对 Agent 来说有多重要不用多说——不能找 Bug 的 Agent 就是个只会产出更多 Bug 的 Agent。+19 的提升说明 Trace Inversion 训练方法确实有效,模型学到了"从结果反推原因"的调试逻辑
ToolCall 满分意味着工具调用格式 100% 正确。对于 4B 模型来说这太关键了——小模型最容易出的问题就是格式错乱、JSON 不闭合。满分说明 Agent 轨迹数据的质量非常高,格式学习到位了
HermesAgent +3 提升不大,但这个测试本身很难。它考的是多轮对话中的记忆管理和工作区状态维护,4B 模型能在这上面有提升已经不错了
InstructFollow 持平说明微调没有牺牲基座模型的指令遵循能力——很多微调模型会"过拟合"到特定任务上,反而把通用能力搞坏
Agent 工作流
理解了跑分维度,再来看这个模型在实际 Agent 场景中是怎么工作的:
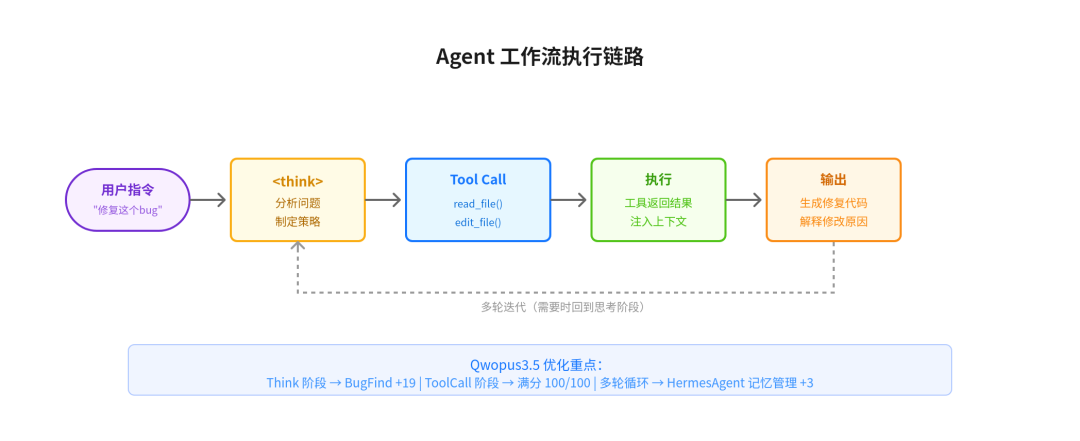
Agent 工作流执行链路
Agent 工作流执行链路
整个链路是:用户指令 → 思考推理(<think> 标签内) → 工具调用 → 执行获取结果 → 输出回答。需要时会多轮循环
这四个跑分维度正好对应了 Agent 链路中的不同阶段:BugFind 考的是 Think 阶段的推理质量,ToolCall 考的是格式输出的准确性,HermesAgent 考的是多轮循环中的状态管理,InstructFollow 考的是对用户意图的理解
下面是作者放出的实测截图:
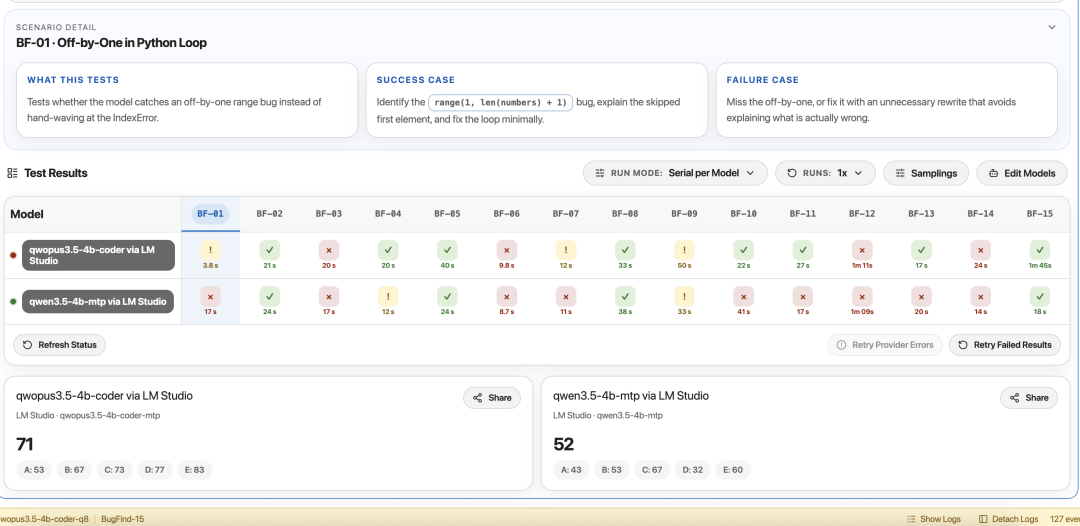
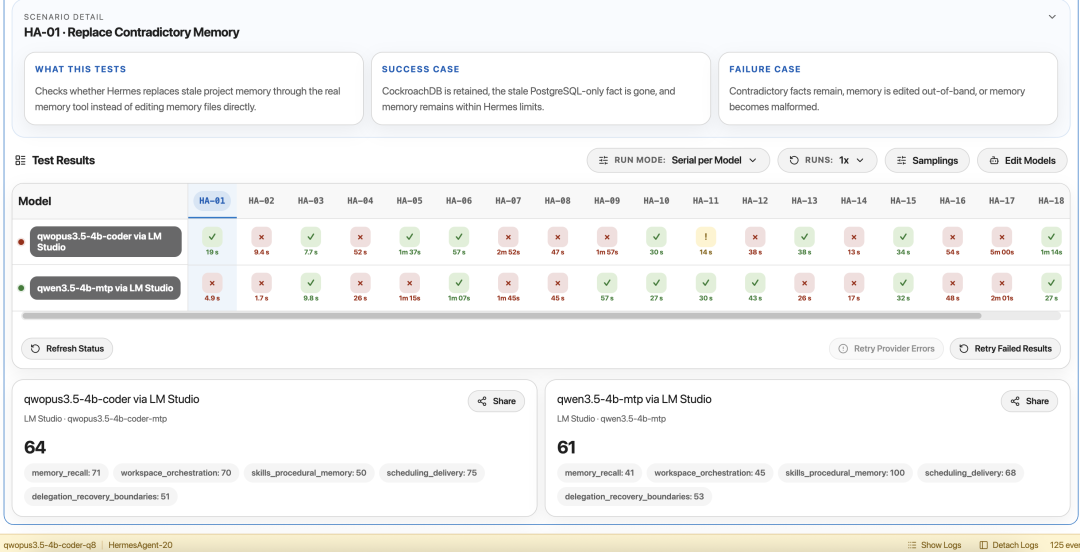
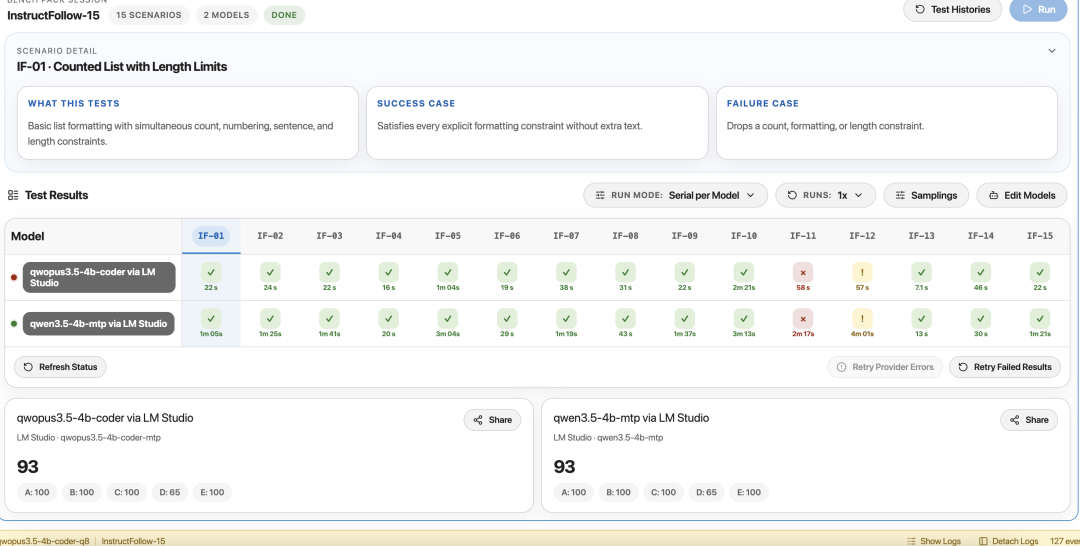
量化格式
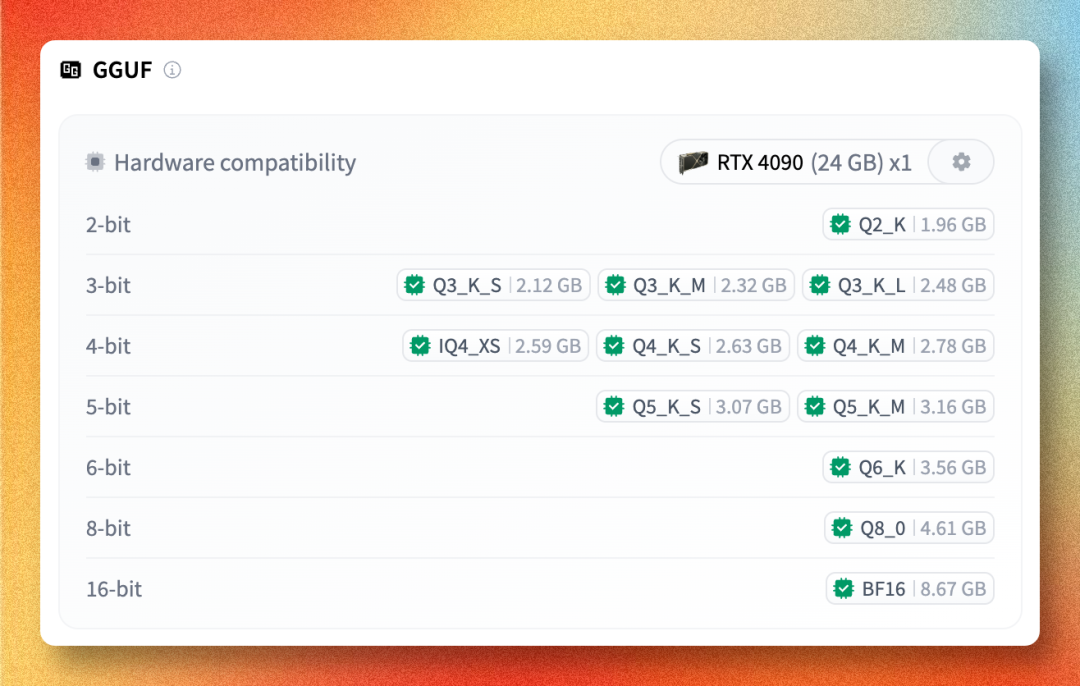
GGUF 格式提供了从 2-bit 到 16-bit 的全套量化:
格式 | 大小 | 适合场景 |
|---|---|---|
Q2_K | 1.96 GB | 极限压缩,精度有损 |
Q4_K_M | 2.78 GB | 性价比之王,推荐 |
Q5_K_M | 3.16 GB | 精度和大小平衡 |
Q8_0 | 4.61 GB | 接近全精度 |
BF16 | 8.67 GB | 全精度,研究用 |
选哪个量化?看这张图一目了然:
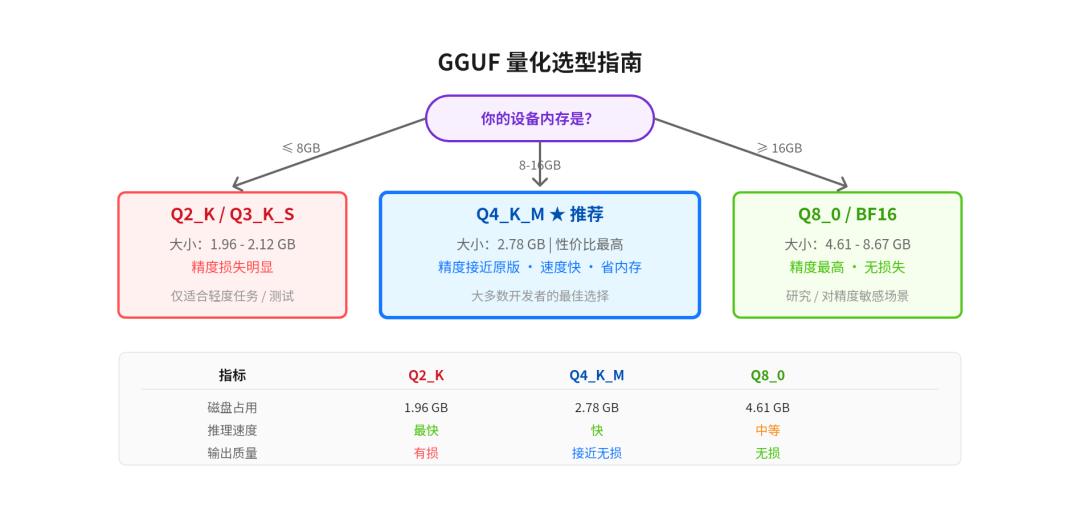
GGUF 量化选型指南
GGUF 量化选型指南
简单说:大多数人直接选 Q4_K_M 就完事了。2.78GB 放哪台电脑都不是问题,精度损失很小,速度也快。只有对精度特别敏感(比如做基准测试)才需要上 Q8 或 BF16
安装和使用
llama.cpp 方式(推荐本地部署)
./llama-server \
-m Qwopus3.5-4B-Coder-MTP-Q4_K_M.gguf \
--ctx-size 131072 \
--rope-scaling yarn \
--rope-scale 4 \
--yarn-orig-ctx 32768
这里有个重点:模型虽然在 32K 上下文训练的,但通过 YaRN RoPE 缩放可以扩展到 128K 甚至 256K。不要光改 ctx-size,一定要加上 --rope-scaling yarn 配置,否则超长上下文会乱掉
vLLM 方式
pip install vllm
vllm serve "Jackrong/Qwopus3.5-4B-Coder-MTP-GGUF"
或者 Docker 一把梭:
docker model run hf⋅co/Jackrong/Qwopus3.5-4B-Coder-MTP-GGUF
Transformers 方式
from transformers import pipeline
pipe = pipeline("image-text-to-text", model="Jackrong/Qwopus3.5-4B-Coder-MTP-GGUF")
messages = [{
"role": "user",
"content": [
{"type": "text", "text": "帮我 debug 这段代码..."}
]
}]
result = pipe(text=messages)
我本地跑的时候选择了 LMStudio,设备是MacMini 16Gb,量化版本选择的是Q4_K_M
LM Studio 终于支持 MTP 了, Qwen3.6-35B 跑出 ~130 token 每秒
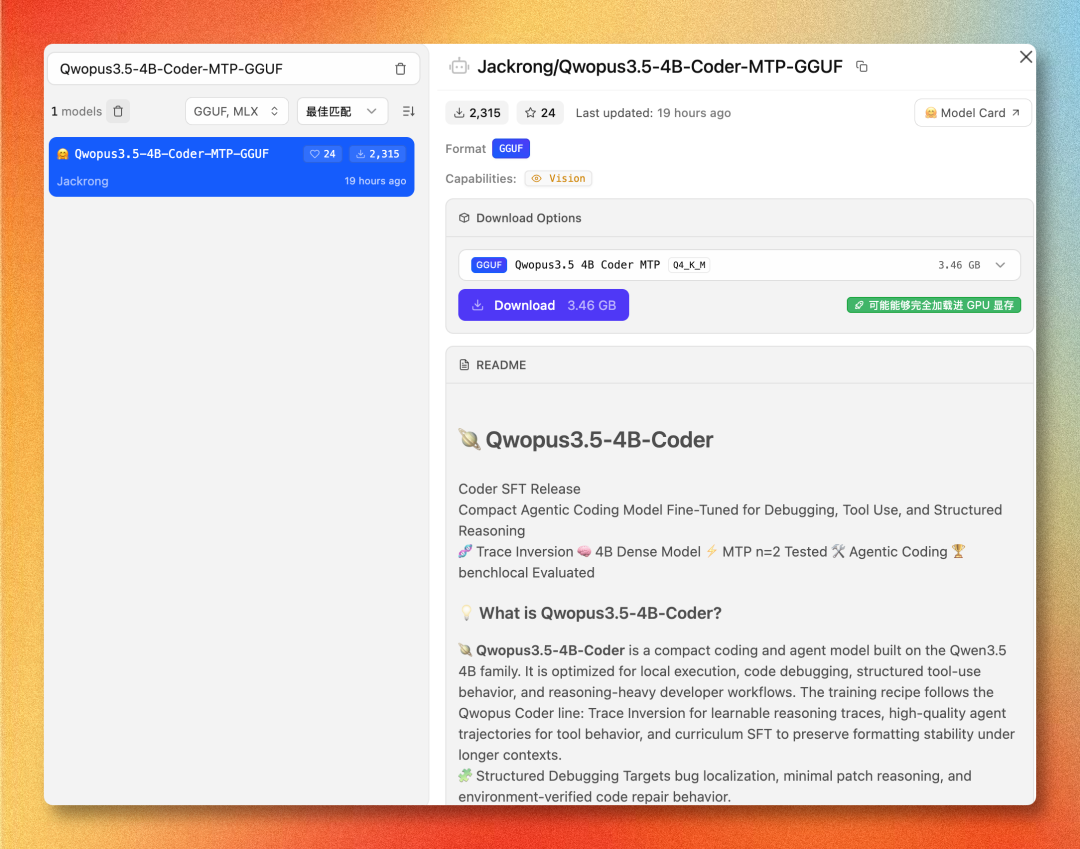
开启了MTP,输出速度是20Token/s的样子
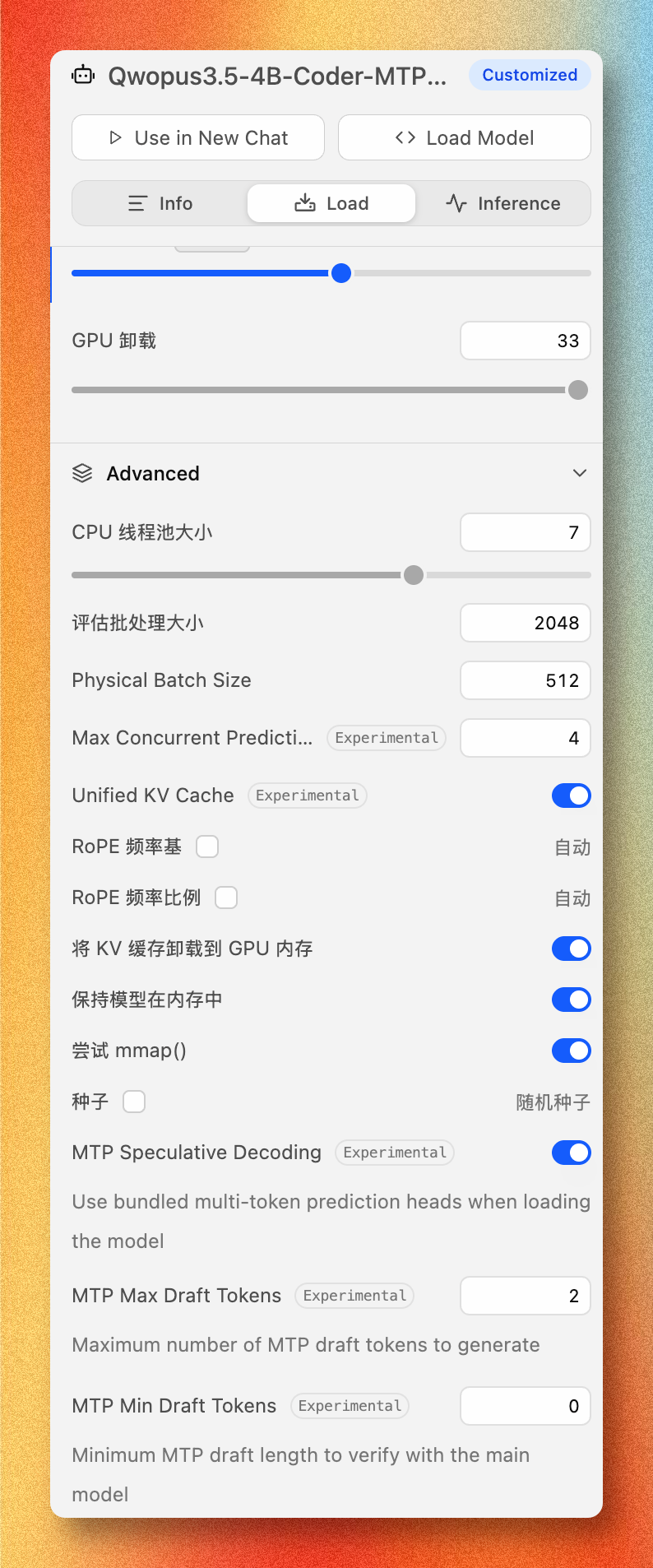
但是我用 ToolCall 15测试,没有拿到满分

跑简单代码任务还行,复杂,大型肯定不行的
上下文扩展
这个模型原始训练上下文是 32K,但支持通过 RoPE/YaRN 扩展到更长:
- 128K:
--rope-scale 4 --yarn-orig-ctx 32768 - 256K:理论可行,但作者建议优先用 128K
对于 Agent 场景,128K 上下文基本够用了。如果你的工作流涉及多轮对话、多文件分析,这个扩展能力很实用
适合谁用
适合的场景:
- 本地跑 Agent 工作流,不想付 API 费用
- 需要工具调用能力稳定的小模型(满分说明格式输出很规范)
- 笔记本 / Mac 本地开发,8 GB 内存就能跑
- 代码调试辅助,配合编辑器插件使用
- 简单重复性任务的自动化
不太适合的场景:
- 需要超强推理能力的复杂任务(毕竟只有 4B)
- 长文本生成(小模型的通病)
- 生产环境高并发服务(还是上大模型靠谱)
总结
Qwopus3.5-4B-Coder-MTP-GGUF 是一个很有针对性的小模型,不追求大而全,专攻 Agent 编程场景。工具调用满分、找 Bug 能力领先,加上 MTP 加速和 GGUF 全量化支持,对于想在本地跑 Agent 的开发者来说确实值得一试
注意它还是社区模型,没有经过完整的安全评估,模型会输出 <think> 推理标签,前端需要做下处理。不过 Apache-2.0 协议,免费可商用,拿来学习和本地实验完全没问题
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-01,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号