全市一套公式估不准房价——GWR和随机森林怎么选

全市一套公式估不准房价——GWR和随机森林怎么选

renhai
发布于 2026-06-02 13:19:42
发布于 2026-06-02 13:19:42
这篇是 ArcGIS Pro「使用回归分析和机器学习预测房价」系列的第二篇。第一篇[1]用 GLR 给金县房价建了个模型,R²=0.69。
上一篇用 GLR 给金县房价建模,R²=0.69,整体还行。但打开残差地图一看——湖边那一片全是深色。

残差空间模式示意图
看到成片的颜色扎堆,说明模型漏了空间信息。
模型系统性低估了湖边的房价。不是偶尔猜错,是一直往一个方向错。为什么会这样?
因为 GLR 给全城用一套公式——面积每多 100 平方英尺,全市统一涨同样的钱。但市中心的 100 平和湖边的 100 平,含金量完全不一样。这就好比你开了 10 家奶茶店,全城同一套菜单同一套定价。写字楼旁边卖爆了,老城区根本没人来——不是奶茶的问题,是不同地方的人要的东西不一样。
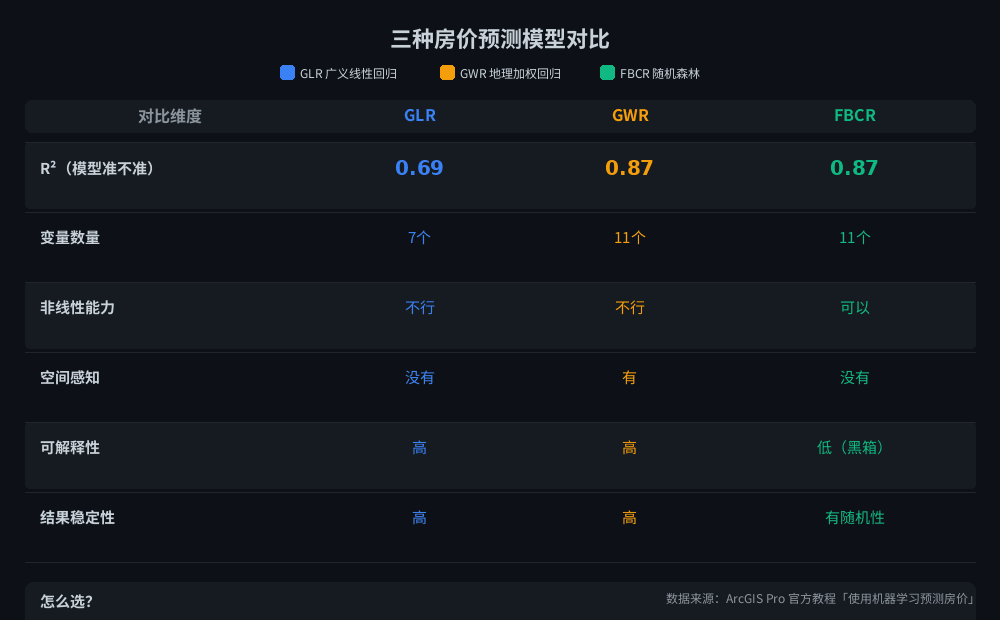
GLR/GWR/FBCR 三模型对比图
三种方法的核心差异。
教程二要解决的就是这个问题。ArcGIS Pro 提供了两种新方法:GWR 和 FBCR。
1. GWR:每个地方画自己的线
GWR 的思路很简单:既然全市一套公式不准,那就每个位置单独算一套系数。
预测某个位置的房价时,只看附近的样本——离得近的权重大、离得远的权重小。这样市中心算出来「面积系数高、湖景系数低」,湖边反过来——「面积没那么重要,湖景才是大哥」。
打个比方:你在全城开了 100 家水果店。普通回归的做法是「全城统一定价:西瓜 8 块/斤」,算一个平均数,所有店照搬。GWR 的做法是让每家店自己定价:老城区消费力低,定 6 块;CBD 白领不在乎,定 10 块;景区游客更不看价,定 12 块。因为它看的不是全城平均,而是自己附近那几家店的销售数据。
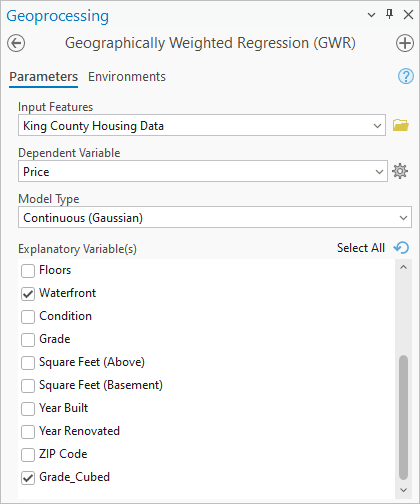
GWR 工具参数(官方教程截图)
GWR 的变量与参数设置。
金县这个案例,GWR 拿到的校正 R² 是 0.87——比 GLR 的 0.69 高了一大截(看起来只多了 0.18,但房价预测里这是质变)。
而且它可解释:你能打开结果,看到每个变量在每个地方的系数是多少。老板问「为什么这套房估 700 万」,你能回答「面积贡献了 30 万,学区 20 万,离地铁近 15 万……」。
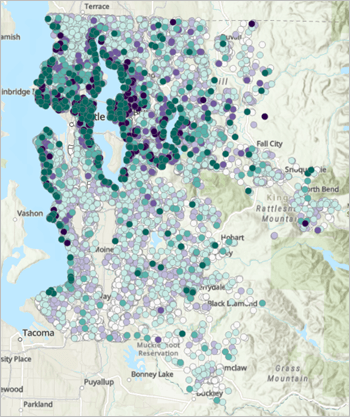
GWR 结果地图(官方教程截图)
GWR 输出结果的空间分布。颜色越深,预测值越高。
但 GWR 有两个硬伤。
第一个硬伤:每条局部回归线还是直的。 现实里面积和房价的关系不是一条直线——小房子单价高,大房子单价低,关系是弯的。GWR 在每个局部都假设直线,画不出这种弯弯绕绕。
第二个硬伤更隐蔽:GWR 对所有变量用同一把尺子。 什么叫「尺子」?就是「看多大范围的邻居来算系数」。地铁站的影响能跨好几个街区,街道绿化只在附近几百米有用。但 GWR 用一把尺子量所有变量——在老城区,地铁的信号太强了,绿化那点微弱的信号直接被淹没了。
MGWR 就是来解决这个问题的。
2. MGWR:每个变量选自己的尺子
GWR[2] 用一把尺子量所有变量,MGWR(多尺度地理加权回归)[3] 让每个变量自己选范围。地铁站用 5 公里,绿化用 300 米,互不干扰。
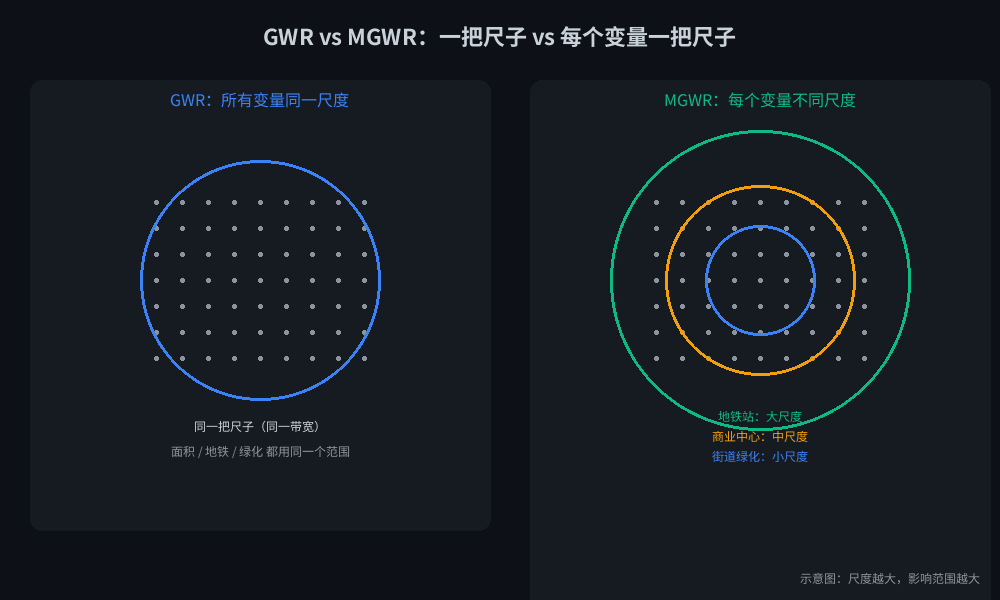
GWR vs MGWR 尺度示意图
GWR 一把尺子量所有变量;MGWR 每个变量有自己的尺子。
广州有篇论文《建成环境对共享单车周末出行的影响》[4]用 MGWR 分析周末骑行数据,发现了一个有意思的现象:道路密度在城中村影响最大——城中村路密,人们更爱骑车。但城市绿地在公园附近反而抑制骑行——可能是政府管制。同一个变量在不同地方效果完全相反,只有 MGWR 能抓住这种差异。
MGWR 是更理想的方向。但说句实话,目前 mgwr 库[3]的文档和社区支持还不够成熟,踩坑成本高。GWR 的「一把尺子量所有变量」确实粗糙,但胜在工具链稳定,ArcGIS Pro 里直接能用。
3. FBCR:不画线,问 250 棵树
FBCR 是另一条路——ArcGIS Pro 里的叫法(Forest-based and Boosted Classification and Regression)[5],底层就是随机森林。它的思路完全不同:不画任何回归线,而是训练 250 棵决策树,每棵树独立预测,最后取平均。
你问 250 个房产中介「这套房值多少钱?」中介 A 看面积,中介 B 看学区,中介 C 看装修。每个人判断依据不一样,但 250 个人取平均,通常比问一个人靠谱。
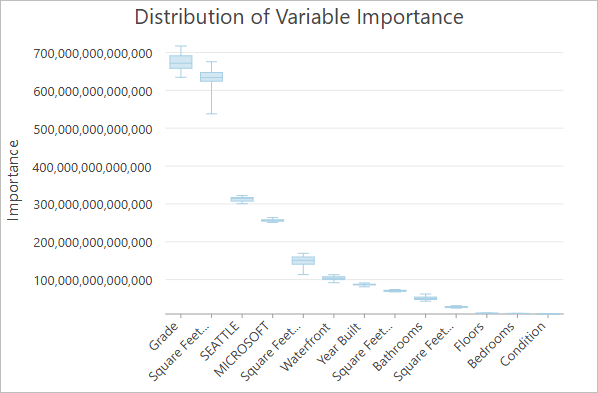
FBCR 变量重要性(官方教程截图)
模型眼里,哪些变量最重要。
FBCR 在金县数据上的测试 R² 也是 0.87,跟 GWR 一样。但它的训练 R² 是 0.97——说明它在训练数据上几乎完美拟合,换了新数据精度会掉一些。
它最大的优势是能处理非线性关系。面积和房价之间的弯弯绕绕,它不在乎——决策树天然就是一刀一刀切出来的,不需要假设直线。变量多也不怕,你塞 50 个变量进去它也不会崩。
代价是什么?你不知道它为什么这么算。 它告诉你「这套房值 650 万」,但你说不清「为什么不是 700 万」。做学术论文,审稿人问「系数空间分布呢」,你答不上来。做房产估值报告,业主问「凭什么比邻居低 50 万」,你只能说「模型说的」。另外结果有随机性,同一模型多跑几次,每次略有差别。
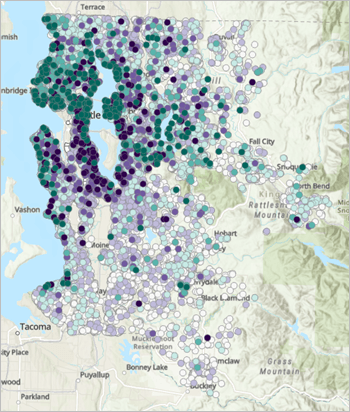
FBCR 结果地图(官方教程截图)
FBCR 预测结果的空间分布。
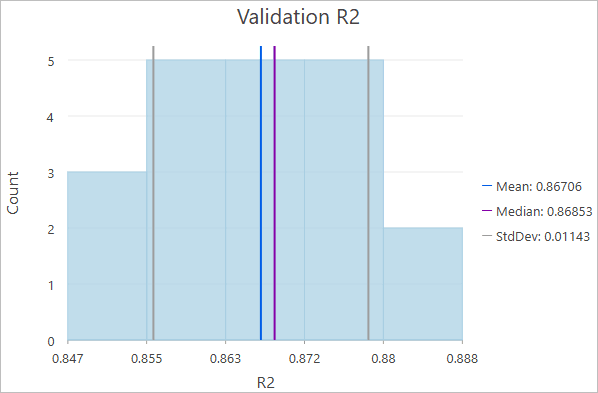
FBCR 验证 R2 图表(官方教程截图)
FBCR 的验证 R² 图表。
4. 怎么选?看你要解决什么问题
R² 都是 0.87,不是「哪个更准」的问题,而是你的场景适合哪个。
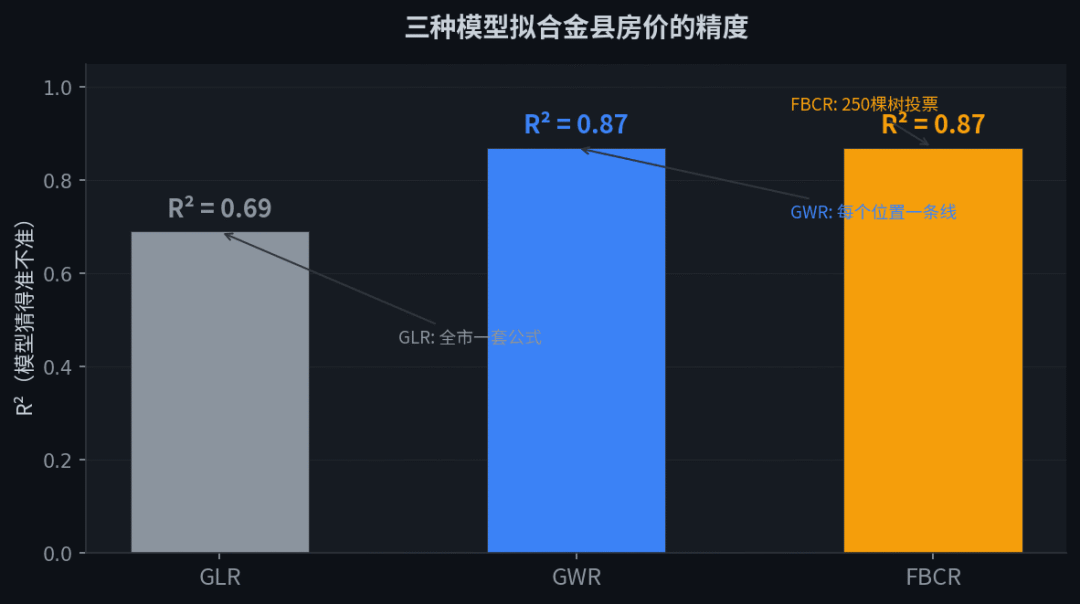
三种模型拟合金县房价的精度
三种模型 R² 对比。GWR 和 FBCR 精度一样,但原理完全不同。
要跟别人解释「为什么」→ 选 GWR。 做房产估值报告或写学术论文,审稿人一定会问「你的系数在空间上怎么分布」。GWR 每个变量在每个地方的系数都能看到,解释力最强。
只要「更准」,不需要解释 → 选 FBCR。 做房价预测 APP,用户输入地址和面积就出估价,没人关心「为什么是 650 万」。FBCR 能处理非线性关系,变量多也不怕。
发现变量影响范围差很多 → 选 MGWR。 做城市规划研究或交通分析,发现「地铁站影响跨 5 公里,绿化只影响 500 米」,GWR 的一把尺子会把小信号淹没。
4.1 速查表
你的情况 | 选哪个 | 为什么 |
|---|---|---|
要向别人解释「为什么」 | GWR | 每个变量的系数看得见 |
只要「更准」 | FBCR | 非线性 + 变量多 |
变量影响范围差很多 | MGWR | 每个变量自己的尺子 |
变量少(少于10个) | GWR | 够用了,还能解释 |
变量多(超过20个) | FBCR | 变量太多 GWR 会乱 |
学术论文 | GWR 或 MGWR | 审稿人要看到系数分布 |
做产品/APP | FBCR | 用户不需要解释,只要准 |
金县这个案例,我选了 GWR。R² 都是 0.87,精度没差别,但 GWR 能告诉我每个变量在每个地方的系数。写论文、做报告,这个比「模型说的」值钱。如果你做的是产品——用户只看数字不看解释——FBCR 更省心。
MGWR 是更理想的方向。GWR 的「一把尺子量所有变量」确实粗糙,只是目前 mgwr 库的文档和社区支持还不够成熟,踩坑成本高。半年后再看。
参考链接
[1] https://www.renhai.online/blog/arcpy-tutorial/regression-study-notes
[2] https://mgwr.readthedocs.io/en/latest/
[3] https://github.com/pysal/mgwr
[4] https://doi.org/10.1080/15568318.2023.2299018
[5] https://pro.arcgis.com/en/pro-app/latest/tool-reference/spatial-statistics/forestbasedandboostedclassificationregression.htm
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-02,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号