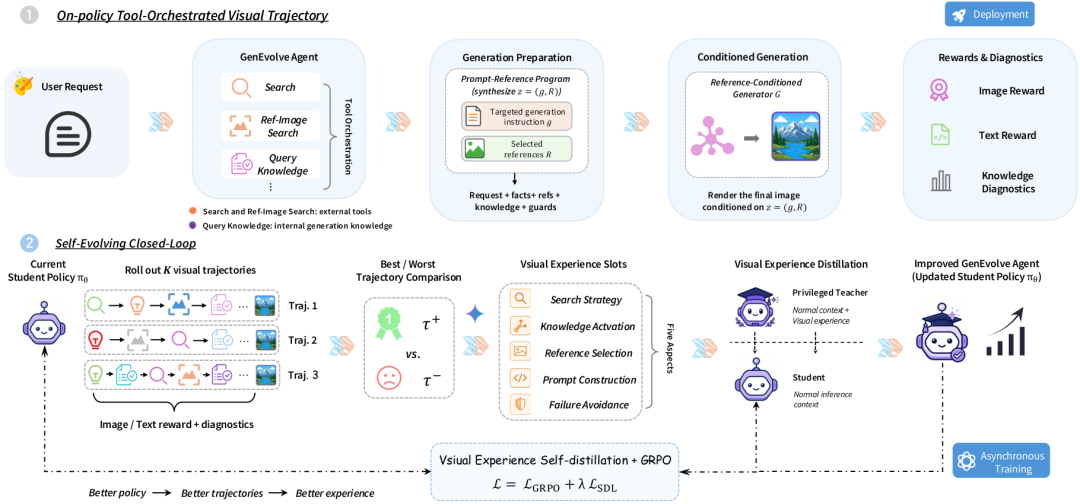
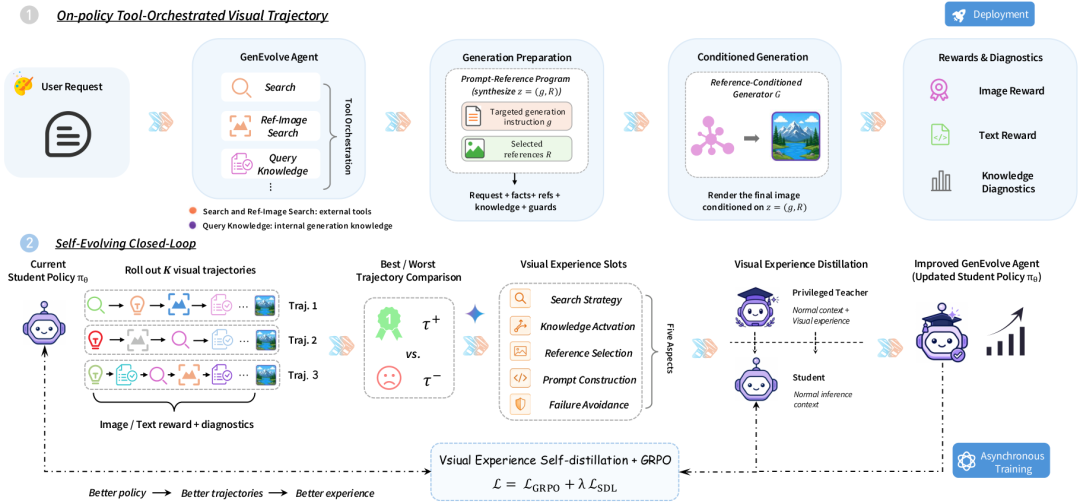
AI 画图终于不再瞎蒙!GenEvolve把开放图像生成变成可训练自进化智能体!

AI 画图终于不再瞎蒙!GenEvolve把开放图像生成变成可训练自进化智能体!

AI生成未来
发布于 2026-06-01 19:22:50
发布于 2026-06-01 19:22:50
作者:Sixiang Chen等
解读:AI生成未来
很多图像生成任务,表面上只是让模型画一张图;真正做起来才会发现,难点往往发生在生成之前。 举个例子:用户想要某个真实地标,就不能只画出一个“差不多的建筑”;用户给了参考图,就不能只借一点风格,而要保住身份、形态和关键材质;用户要求海报文字、空间关系或者各种模糊的信息,就需要精准的执行所有的信息。
这些问题放在一起,会形成一种很典型的开放生成场景:模型需要先补信息、选参考、拆约束,再把这些内容组织成底层生成器能执行的指令。GenEvolve 关注的正是这一步。它不是把图像生成看成单次 prompt rewriting,而是把生成前的决策过程建模成一条工具轨迹。
- 项目主页:https://ephemeral182.github.io/GenEvolve/
- arXiv:https://arxiv.org/abs/2605.21605
- GitHub:https://github.com/MeiGen-AI/GenEvolve
- 模型权重:https://huggingface.co/MeiGen-AI/GenEvolve
- 数据与评测:https://huggingface.co/datasets/MeiGen-AI/GenEvolve-Data-Bench
GenEvolve 作为生成前的智能体策略,可以与 Qwen-Image-Edit、Nano Banana Pro 等不同渲染器组合。
GenEvolve 作为生成前的智能体策略,可以与 Qwen-Image-Edit、Nano Banana Pro 等不同渲染器组合。
生成之前,Agent 需要先做三类判断
开放图像生成里,用户请求缺失的信息并不总是同一种。
第一类缺的是事实依据。真实建筑、产品、公众人物、历史事件、科学概念等任务,都需要先把外部知识补齐,否则画面可能“看起来合理”,但关键事实是错的。
第二类缺的是可用参考。参考图并不只是给模型看一下风格,它可能承载人物身份、商品结构、局部形态、服饰材质等约束。Agent 要判断哪张图值得用,以及参考应该以什么方式进入最终程序。
第三类缺的是生成控制能力。文字渲染、计数、布局、属性绑定、解剖和材质一致性,经常是开放生成中最容易失手的部分。它们需要被明确成可检查的约束,而不是只停留在自然语言愿望里。
围绕这三类需求,GenEvolve 为 Agent 准备了三个入口:search(q) 用来查外部证据,image_search(q) 用来检索视觉参考,query_knowledge(skill) 用来调取文字、空间、数量、材质等生成知识。Agent 的目标不是“多调用几个工具”,而是把工具结果整理成 prompt-reference program,再交给底层图像生成器执行。
GenEvolve 将一次开放生成拆解为工具调用、参考绑定、技能激活和最终程序生成。
GenEvolve 将一次开放生成拆解为工具调用、参考绑定、技能激活和最终程序生成。
1)统一"工具编排"范式:单一智能体覆盖开放生成中的多类需求
GenEvolve 并不是把开放图像生成拆成若干独立模块或工具来分别处理, 而是将开放生成场景中最常见的需求整理为两大轨道,并统一交给 一个智能体 来完成:
- 外部知识依赖类:Knowledge-Anchored — 实体识别、事件、地标、商品、可视事实;
- 质量约束依赖类:Quality-Anchored — 文字渲染、空间布局、数量、属性绑定、解剖、材质一致性、美学、创意转化。
这里更重要的其实不是"任务名称本身", 而是这些能力共同对应了一个真实的设计流程:
接到用户请求 → 搜外部证据 → 找视觉参考 → 激活合适的生成知识 → 写出可执行的 prompt-reference program → 交给生成器渲染 → 输出最终成品图
以往不少方法更像是把"搜索增强"和"图像生成模块"简单拼接在一起,虽然功能上能覆盖,但整体体验往往不够连贯;
而 GenEvolve 更接近一个 "基于工具与经验工作的智能生成助手":只要给它一条开放请求,它既能调用外部工具收集证据、寻找参考图,也能根据请求类型激活相应技能,并把所有信息编排成一段 generator-agnostic 的最终程序。
2)"数据—进化—蒸馏"闭环:让一个 Agent 同时学会用工具与做创作,缓解多约束冲突
要训练一个真正面向开放图像生成的 Agent,第一步不是直接把各种任务混在一起做微调,而是先回答一个更基础的问题:
什么样的数据,才能教会模型完整地走完"理解请求—查找证据—选择参考—激活生成知识—写出最终程序"这一整条链路?
GenEvolve-Data 因此不是普通的 prompt-rewriting 数据集,也不是单纯的图文配对数据集。 每个样本都被设计成一个完整的开放生成问题:有的缺少外部事实,有的依赖视觉参考,有的要求精确文字、数量、布局、材质或解剖结构。 这些请求先由结构化 recipe 控制覆盖范围,再交给 Teacher Agent 生成真实的多轮工具轨迹,最后经过 VLM 审计、GT 图像渲染和视觉过滤,形成可以用于 SFT、自我进化和评测的三种视图。
在这个数据基础上,才进入第二个问题:如何让同一个 Agent 同时处理 Knowledge-Anchored 与 Quality-Anchored 两类需求? 这里确实会出现任务之间的相互牵制:知识型约束更强调事实正确性与参考一致性,质量型约束更关注像素级可校验细节。 所以 GenEvolve 没有把所有信号直接压进一次训练,而是采用了一条分阶段的路径:
- 先在筛选过的工具编排轨迹上做监督微调(SFT 冷启动),让 Agent 学会"什么时候该搜、什么时候该看图、什么时候该激活技能、最后该输出什么样的程序";
- 再通过 GRPO + 视觉经验自蒸馏(SDL) 在带反馈的 RL 阶段做自我进化,把"轨迹级是哪条更好"和"token 级好在哪里"两层信号同时优化;
- 最后把"经验"完全烧进权重,部署的 Student 模型 不需要任何 runtime memory —— 检索库和特权 Teacher 只在训练时存在。
3)GenEvolve-Bench:用统一基准系统评估开放图像生成的常见需求
为了更完整地评测这类任务,我们构建了 GenEvolve-Bench, 这是一个面向开放图像生成的统一测试基准,覆盖 Knowledge-Anchored / Quality-Anchored 两条主轨,并据此进行了系统化评估。
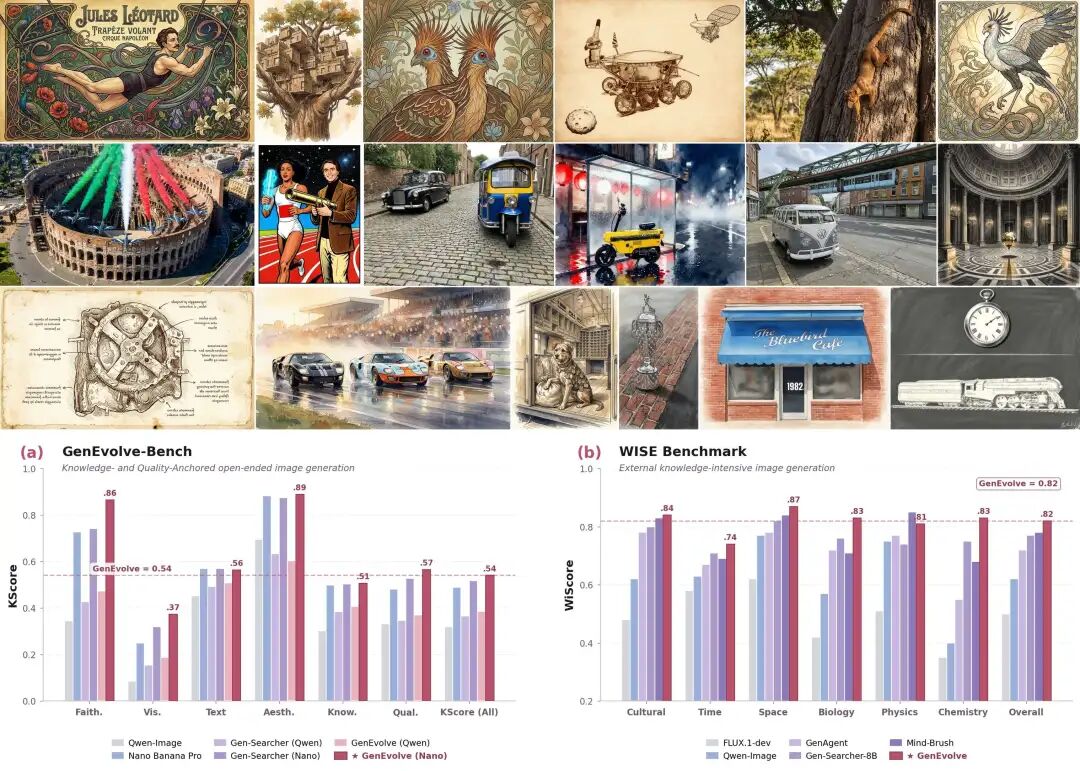
实验结果表明,GenEvolve 在两条轨道上的表现更加均衡。 尤其是在对外部世界知识要求更高的 Knowledge-Anchored 任务上,优势更加明显; 而在文字、数量、版式、材质等可校验细节的 Quality-Anchored 任务上,也展现出更好的稳定性。
在统一且公平的评测方式下(KScore:Faithfulness 0.1 / Visual 0.4 / Text 0.4 / Aesthetic 0.1,由 Gemini 3.1 Pro Preview 作为视觉判分器),GenEvolve 的整体效果已经超过当前主流的开源直生成器与 agentic 工作流,并在搭配强生成器时取得当前最高的 KScore。
我们额外在公开的 WISE 知识密集型基准上做外推:用 8B 开源策略 + 开源 Qwen-Image-Edit 渲染器,整体 WiScore 达到 0.82,超过 GPT-4o(0.80) 与所有 agentic baseline。
方法论
GenEvolve 的核心目标,是把真实开放图像生成场景中常见的
"一句开放请求 + 多种硬约束"
统一建模为 one self-evolving agent for tool-orchestrated open-ended image generation。
换句话说,它希望一个智能体同时具备两类能力:
一方面能完成对世界知识的检索、参考图选取与绑定、外部证据到生成程序的转写; 另一方面也能在程序级别准确表达数量、文字、版式、解剖、材质等硬约束; 并且在同一个框架下兼顾"事实是否正确"和"画面是否符合所有要求"。
为了实现这一点,我们设计了一套完整的 数据—专家—进化—蒸馏 的训练流程, 并在最后结合 视觉经验自蒸馏,将"最佳/最差轨迹的差异"显式蒸馏到部署模型, 从而尽可能减轻多约束训练中的相互牵制问题。
GenEvolve 方法总览:student 采样多条工具编排轨迹;最优/最差对蒸馏成结构化 Decision Guide,只交给特权 Teacher,再用 token 级反向 KL 蒸馏回部署的 Student。
GenEvolve 方法总览:student 采样多条工具编排轨迹;最优/最差对蒸馏成结构化 Decision Guide,只交给特权 Teacher,再用 token 级反向 KL 蒸馏回部署的 Student。
阶段 1:自动化数据构建与 GenEvolve-Data
统一智能体要真正具备泛化能力,前提是拥有高质量、可控、覆盖多类约束的 工具编排轨迹 数据。
为此,GenEvolve 首先搭建了一套自动化数据生产流程,构建出 GenEvolve-Data,并同步建立评测集 GenEvolve-Bench。
整个流程可以理解为一个完整的数据闭环:
结构化 Recipe → 自然请求 prompt → Teacher Agent 多轮工具轨迹 → VLM 审计 → GT 图像渲染 → 视觉过滤 → 训练/RL/Bench 三套切分

GenEvolve-Data 与 GenEvolve-Bench 的数据闭环:从结构化 recipe 到 Teacher 工具轨迹、VLM 审计、GT 图像渲染、视觉过滤,再切分为 SFT / 自我进化 / 评测三视图。
GenEvolve-Data 与 GenEvolve-Bench 的数据闭环:从结构化 recipe 到 Teacher 工具轨迹、VLM 审计、GT 图像渲染、视觉过滤,再切分为 SFT / 自我进化 / 评测三视图。
也就是说,我们不是简单拼接现成样本,而是先生成更贴近真实开放生成需求的请求,再经过严格过滤和任务化改造,最终沉淀为可训练、可评测的数据体系。
从类别分布上看,GenEvolve-Data 被组织成两条主轨:Knowledge-Anchored 与 Quality-Anchored。 前者覆盖建筑、街景、公众人物、产品、交通工具、事件、科学、文物等外部知识相关场景; 后者覆盖文字/版式、空间关系、计数、解剖、属性绑定、材质、美学和创意转化等可见质量约束。 这样的设计让 benchmark 不只测试"画得好不好看",而是测试 Agent 是否能根据请求类型选择合适的证据、参考图和生成技能。
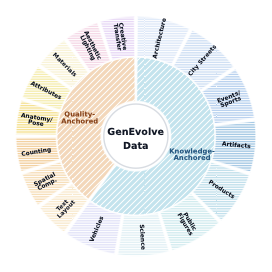
GenEvolve-Data 的类别层级:两条主轨各覆盖 8 类诊断场景,用于控制数据覆盖、分层切分与 benchmark 分析。
GenEvolve-Data 的类别层级:两条主轨各覆盖 8 类诊断场景,用于控制数据覆盖、分层切分与 benchmark 分析。
从构建统计上看,数据也经历了比较强的过滤:
- prompt pool 保留 19,990 个有效请求;
- 其中 19,320 条通过结构检查进入轨迹阶段,最终保留 13,379 条高质量过滤轨迹;
- SFT 轨迹为 8,800 条;
- GT 图像生成成功 4,321 张,视觉过滤后保留 3,175 个视觉反馈 case;
- 自我进化训练池为 2,575 个 case,held-out benchmark 为 594 个 case。
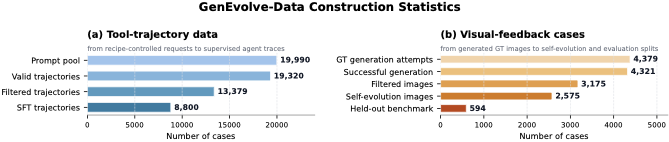
GenEvolve-Data 构建统计:左侧是 prompt 到 SFT 轨迹的过滤过程;右侧是 GT 图像、视觉过滤、自我进化样本与 held-out benchmark 的切分。
GenEvolve-Data 构建统计:左侧是 prompt 到 SFT 轨迹的过滤过程;右侧是 GT 图像、视觉过滤、自我进化样本与 held-out benchmark 的切分。
(1)请求与基础轨迹生成:更贴近真实开放生成需求
GenEvolve 所使用的请求并不是普通的 caption, 而是先组合 任务族 / 缺失外部证据 / 视觉锚点 / 主导生成要求 / 难度 等信息, 再借助 VLM 把它们扩展成自然但带有硬约束的开放式请求; 随后让 Teacher Agent(Seed 2.0 / Gemini 3 Pro)走一次真实的多轮工具循环:发起文本搜索、拉视觉参考、激活生成知识,最终输出 prompt-reference program。
工具调用顺序是请求驱动的:知识密集型请求往往先做事实查找;参考敏感型请求更早依赖图像搜索;质量驱动型请求会更早激活内部生成知识。
(2)多模态过滤:保证数据既能训练,也能评测
对于合成数据而言,真正的瓶颈往往不在数量,而在 噪声控制。 因此,我们设计了一套分层过滤机制,用来保证训练集和评测集的可靠性。
- 轨迹过滤:程序化检查清除不完整的工具循环、无效参考、URL/ID 泄露、缺少 ordinal binding、过分简化的最终程序;再由 VLM 判分器审核"参考是否真支持画面"、"证据是否被采用"、"程序是否覆盖所有硬约束"。
- GT 图像过滤:高质量的 Teacher 程序由 Nano Banana Pro 渲染成 GT 图像,再经第二道视觉过滤检查 prompt 一致性、参考使用率、视觉连贯性、生成质量。
- 三视图切分:最终保留的样本切为 SFT 视图(保留完整工具循环、不暴露 GT 图像)、自我进化视图(保留请求 + GT 图像 + 元数据)、GenEvolve-Bench 评测集,覆盖 Knowledge / Quality 两条轨道。
阶段 2:SFT 冷启动(先教 Agent 如何"会用工具")
如果直接把模型甩进 RL 里采轨迹,最容易出现的问题就是 早期采样的工具调用极度不稳定:什么时候该搜、参考要不要替换、技能要不要调、最终程序怎么写……都需要先有一套合格的"会用工具"的初值。
为此 GenEvolve 先在筛选后的 Teacher 轨迹上做一次冷启动 SFT。
- 训练对象:Qwen3-VL-8B-Instruct 的语言策略部分(视觉编码器冻结,仅优化 assistant 端 token,含/ <tool_call> /);
- 训练栈:LLaMA-Factory 长上下文(cutoff 32K)、bf16 + FlashAttention-2、ZeRO-3、AdamW 优化器 + 余弦学习率;
- 退出准则:以 held-out 轨迹 loss 而非 benchmark 性能选 ckpt,避免在 SFT 阶段过早过拟合到判分器。
冷启动结束后得到的 GenEvolve-SFT,可以理解为"一个学生学会了 Teacher 那一整套工具调用 + 程序写法 的范式",但还没有学到"什么样的轨迹真正会得到高分图"。
阶段 3:GRPO + 视觉经验自蒸馏(SDL)
监督微调能让模型学会"会用",但很难进一步让模型学会"用得更好、更像高水准设计师"。
我们在 RL 阶段引入两层信号同时优化:
(1)轨迹级:GRPO + 混合奖励
对每个用户请求,智能体采 6 条 rollout,每条产生一个程序 z,再交给生成器渲染图像。我们用两个判分器同时打分:
- KScore 视觉判分:四维 Faithfulness / Visual / Text / Aesthetic(权重 0.1 / 0.4 / 0.4 / 0.1);
- 程序充分性文本判分:5 档评分
{0, 0.25, 0.5, 0.75, 1},看程序是否承载了足够的事实、ordinal 引用、技能激活与可执行的硬约束。
最终奖励 R = 0.5 R_img + 0.5 R_text,作为 GRPO 的 group-relative 优势信号。
(2)Token 级:视觉经验自蒸馏
仅有 trajectory-level 的奖励还不够 —— 它告诉你"哪条轨迹更好",但不告诉模型"为什么这条更好"。GenEvolve 的关键贡献,是把"为什么"这件事变成可学习的 token-level 信号:
- 对每个 prompt 的 6 条 rollout,挑出最优/最差对(要求奖励差距 ≥ δ_min),让 Gemini 3.1 Pro Preview 把这对差异蒸馏成一段结构化的Decision Guide:
- retrieval_key:trigger 短语 + source-prompt summary;
- decision_guidance:6 类祈使式 bullet(推荐工具计划 / 搜索查询 / 技能路由 / 参考选择 / 程序写法 / 失败防御)。
- 这些 Decision Guide 进入 prompt-keyed 滚动 buffer(容量 500),按 embed(trigger + summary) 用 Qwen3-Embedding-0.6B 建立检索索引。
- 训练时按 cosine 相似度(gate ≥ 0.84)拉回 top-1 Guide,只把它注入 Teacher 视角;Student 始终只看普通 system prompt。
- SDL 用 importance-weighted 反向 KL,让 Student 在同一批 on-policy token 上向 Teacher 分布对齐 —— 但只在决策关键的 token 上做:
- Decision-only mask:只保留 <tool_call> /块内的 token;
- Top-K 过滤:每条序列内只保留 |log π_E − log π_S| 最大的前 10%。
一句话总结:在最关键的几十个决策 token 上,让 Student 学会"看到了 Decision Guide 的人会怎么做",但部署时 Student 不需要任何检索库。这正是 GenEvolve 把"经验"完全烧进权重的关键。
这张图展示了 SDL 在 token 层面到底学到了什么。左边是 Teacher 反对 Student 的情况:Student 原本倾向于输出一些泛化或填充式 token,但 Teacher 在 Decision Guide 的帮助下,会把概率质量重新分配到更关键的动作上,比如先调用工具、明确空间布局、锚定事实身份、选择参考图。右边是 Teacher 支持 Student 的情况:当 Student 已经朝正确方向走时,Teacher 进一步提高正确决策 token 的概率,让模型在后续训练中更坚定地复用这些策略。
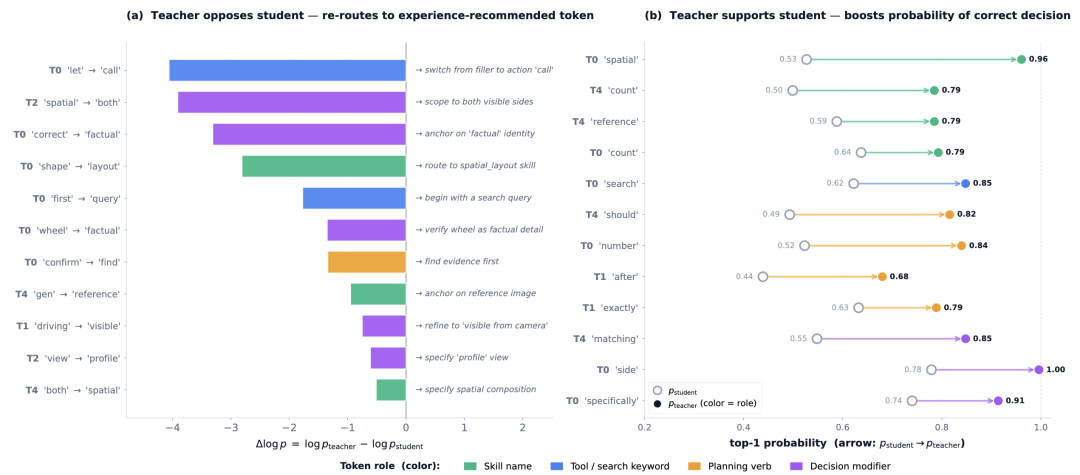
SDL 的 token-level 证据:Teacher 一方面会纠正 Student 的错误决策 token,另一方面会放大已有正确决策的概率,使视觉经验最终沉淀到部署模型权重中。
SDL 的 token-level 证据:Teacher 一方面会纠正 Student 的错误决策 token,另一方面会放大已有正确决策的概率,使视觉经验最终沉淀到部署模型权重中。
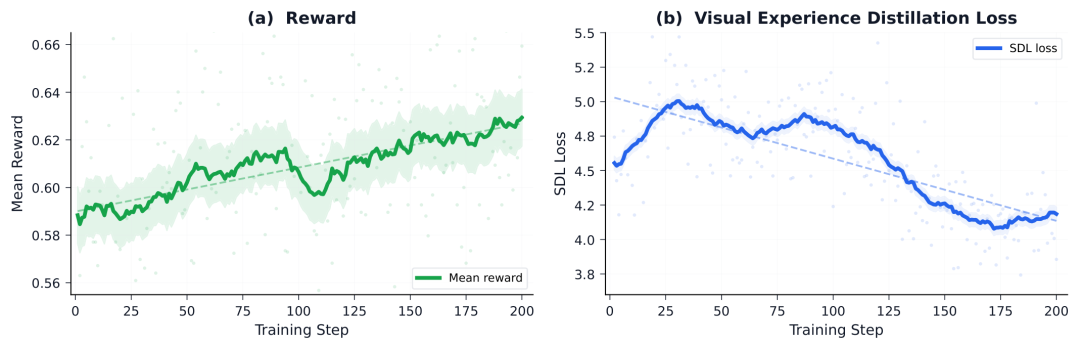
(a) 混合奖励曲线随训练步数稳定上升;(b) SDL 反向 KL 损失逐步下降。两条信号同时改善,说明 GRPO 提供"哪条更好"的轨迹级信号,SDL 提供"为什么更好"的 token 级信号。
(a) 混合奖励曲线随训练步数稳定上升;(b) SDL 反向 KL 损失逐步下降。两条信号同时改善,说明 GRPO 提供"哪条更好"的轨迹级信号,SDL 提供"为什么更好"的 token 级信号。
实验:GenEvolve 到底强在哪里?
我们把评测拆成四块:统一基准(GenEvolve-Bench) → 主结果 → 消融实验 → 跨基准外推(WISE)与定性对比。
1)GenEvolve-Bench:把"开放图像生成的常见需求"整理成统一评测基准
我们首先构建了一个面向开放图像生成的统一评测基准 GenEvolve-Bench,覆盖两大轨道:Knowledge-Anchored / Quality-Anchored。 为了尽量贴近真实使用场景,Bench 同时包含两类输入形式(仅文本请求 / 文本请求 + 用户参考图),并在多个主题(实体、地标、商品、事件、文字、布局、计数、属性、解剖、材质、美学、创意)上保持均衡分布。
在评测方式上,我们采用强 VLM(Gemini 3.1 Pro Preview)对结果进行打分:
- 既评价 视觉细节正确性(事实接地、参考一致、可校验细节);
- 也评价 整体质量(构图、文字、美学);
并最终在四个维度上给出 KScore,加权汇总为最终指标。
更直观地说,这个 benchmark 测的不是"能不能生成一张图",而是"能不能像一个合格的 agent 一样,把世界知识、参考图、生成知识全部编排好"。
2)定量结果:开源最强,搭配强生成器拿下当前最高
在 GenEvolve-Bench 上,我们对比了主流的 直生成 baseline(Lumina-Image 2.0 / BAGEL / SD-3.5 / FLUX.1-dev / FLUX.2 Klein / Z-Image / Qwen-Image / Nano Banana Pro 等)和 agentic baseline(Gen-Searcher 等)。结果非常清晰:
- 同样接 Qwen-Image-Edit-2511 这类开源生成器:GenEvolve 在 Knowledge / Quality 两条轨道上都有明显提升,KScore 从 Gen-Searcher 的 0.3493 提升到 0.3663(Visual 维度由 0.1050 提升到 0.1338),尤其在 Knowledge-Anchored 这类更依赖事实接地的任务上增幅更大;
- 搭配更强的 Nano Banana Pro:GenEvolve 的 KScore 直接抬到 0.5739,四个 judge 维度和两条 benchmark 轨道均达到最高。即便是 Nano Banana Pro 自己的"裸"直生成(KScore 0.5298),也明显落后于"裸 Nano + GenEvolve 编排",说明 agent 端的工具编排带来的提升是生成器无关的。
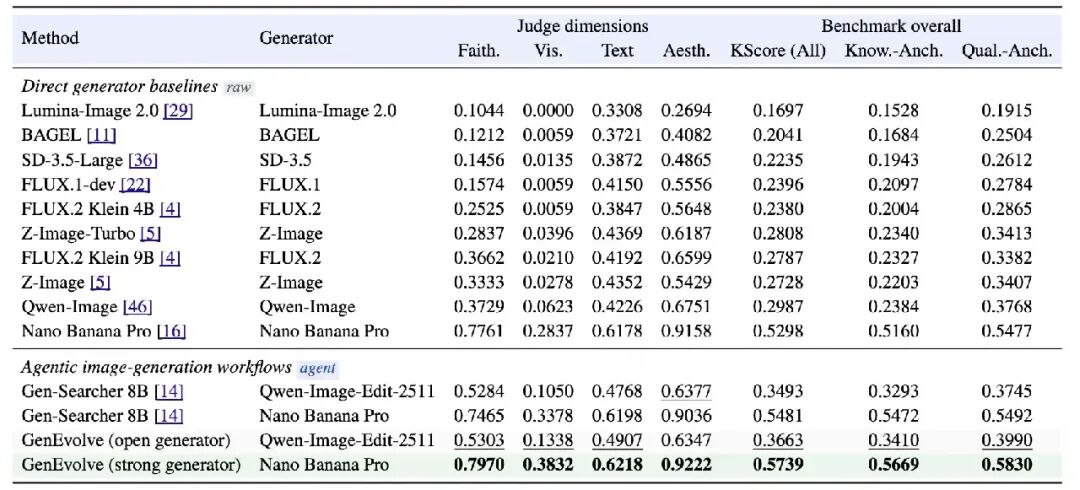
GenEvolve-Bench 主结果。GenEvolve + Qwen-Image-Edit-2511 是最佳开源生成器设置;GenEvolve + Nano Banana Pro 在整体 KScore、Knowledge-Anchored 和 Quality-Anchored 上均取得最高分。
GenEvolve-Bench 主结果。GenEvolve + Qwen-Image-Edit-2511 是最佳开源生成器设置;GenEvolve + Nano Banana Pro 在整体 KScore、Knowledge-Anchored 和 Quality-Anchored 上均取得最高分。
从完整表格可以看到几个更细的趋势:
- 直接生成器的整体审美分通常不差,但在需要事实接地、参考一致或精确布局时,Visual correctness 容易成为短板;
- 当底层生成器固定为 Qwen-Image-Edit-2511 时,GenEvolve 比 Gen-Searcher 更擅长把搜索证据、参考图和生成技能写进最终程序;
- 当底层生成器换成 Nano Banana Pro 时,同一套 Agent 策略还能继续放大强生成器的上限,说明 GenEvolve 学到的是可迁移的编排策略,而不是某个渲染器上的 prompt trick。
3)消融实验:每个训练阶段到底贡献了什么?
为了确认提升来自哪里,我们进一步做了 component ablation。结果显示,单纯把 Qwen3-VL 接上同一套工具接口,已经能比裸 Qwen-Image 更好;SFT 冷启动能继续提高工具调用和最终程序质量;GRPO 提供轨迹级奖励后再往上推一截;而完整的 GRPO + SDL 取得最高 KScore。
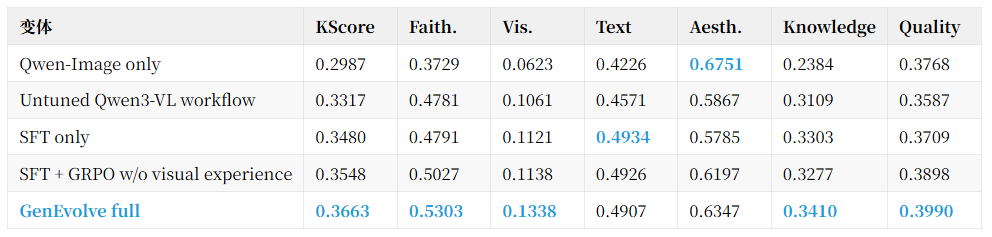
这组结果说明两点:
第一,会用工具 和 用工具用得好 是两件事。Untuned workflow 已经具备工具入口,但没有经过轨迹监督和视觉反馈,很难稳定写出高质量 prompt-reference program。
第二,GRPO 的 scalar reward 能告诉模型"哪条轨迹更好",但 SDL 提供的是更细的 token-level credit assignment:它把最佳/最差轨迹之间可复用的经验蒸馏到关键动作 token 上,因此最终在 Visual correctness、Knowledge-Anchored 和 Quality-Anchored 三个最关键维度上都继续提升。
4)跨基准外推:WISE 上超过 GPT-4o
我们额外在 WISE 这一公开的知识密集型图像生成基准 上做外推:
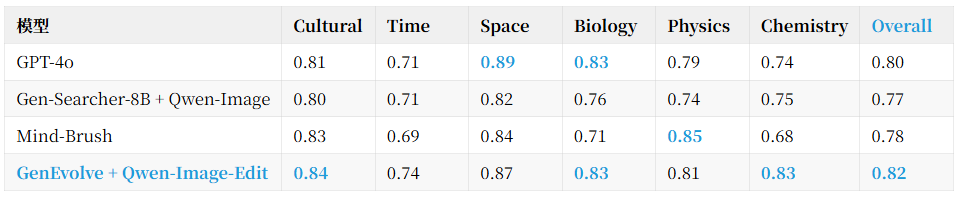
注意:GenEvolve 在 WISE 上 不做任何 in-domain 微调,纯靠跨任务转移:用一个 8B 开源策略 + 开源 Qwen-Image-Edit 渲染器,在 WiScore Overall 上 超过 GPT-4o;化学一项更是甩开 GPT-4o 9 个百分点。
5)定性对比:为什么说它"在编排"而不是"在炫工具"?
定性结果里最典型的两类失败,我们在很多 baseline(包括部分商业系统)上都能反复看到:
- Knowledge-Anchored 失败:模型要么没去搜,要么搜回来的事实没真正进
gen_prompt,导致 身份错位、年代错乱、结构比例失真。GenEvolve 更偏向去抽取关键事实,再把它显式写进最终程序里的 ordinal binding 与硬约束,使"被采用的事实"真的进画面。 - Quality-Anchored 失败:很多系统在文字、计数、版式上"看起来像,但拼写错"或"数对了但布局塌"。GenEvolve 通过
query_knowledge主动激活专门技能(text_rendering/quantity_counting/spatial_layout/material_consistency等),并在程序里写出可校验的硬约束,使得这些维度更稳。

在 GenEvolve-Bench 上的定性对比。橙色:依赖外部知识;蓝色:依赖内部生成技能。
在 GenEvolve-Bench 上的定性对比。橙色:依赖外部知识;蓝色:依赖内部生成技能。

GenEvolve + Nano Banana Pro 的扩展画廊。
GenEvolve + Nano Banana Pro 的扩展画廊。

GenEvolve + Qwen-Image-Edit 的扩展画廊(与上一张使用同一套 GenEvolve 程序,仅切换底层渲染器)。
GenEvolve + Qwen-Image-Edit 的扩展画廊(与上一张使用同一套 GenEvolve 程序,仅切换底层渲染器)。
参考文献
[1] GenEvolve: Self-Evolving Image Generation Agents via Tool-Orchestrated Visual Experience Distillation
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-01,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号