Scientific Data|5.8万条治疗性多肽:给多肽AI补上一张序列-结构-功能地图

Scientific Data|5.8万条治疗性多肽:给多肽AI补上一张序列-结构-功能地图

MindDance
发布于 2026-06-01 18:18:30
发布于 2026-06-01 18:18:30

Scientific Data. 2025. A comprehensive dataset of therapeutic peptides on multifunction property and structure information
这两年医药圈最热的赛道,没有之一,就是多肽。司美格鲁肽、替尔泊肽这两个GLP-1类药物,2024年全球销售额已经把整个多肽药物市场推到518亿美元,2025年破600亿基本是板上钉钉,业内普遍把它叫做超级风口。资本、产能、管线一窝蜂涌进来,光是处于临床阶段的GLP-1管线就有近180个。但风口越热,一个尴尬的现实越扎眼:当大家都想用AI来加速下一个多肽明星药的发现时,喂给模型的数据,其实是一地碎片。北京航空航天大学团队联合北京石油化工学院、武汉大学,在Scientific Data上放出了一份新数据集——58583条经过实验验证的治疗性多肽,47个功能类别,其中21130条是多功能肽,54722条带有结构信息。一句话概括:这是目前公开可得的、规模最大、维度最全的治疗性多肽数据集,尤其在多功能标注和结构信息这两块上,把之前的最好成绩甩开了一大截。
如果你只有一分钟,记住三个对比就够了:多功能肽的数量从过去最好的9986条翻到21130条,结构文件从16131个涨到54722个,功能类别从22类扩到47类。后面我们慢慢聊,这三个数字背后,各自踩中了多肽AI落地的一个痛点。
数据库明明一大堆,为什么还是喂不饱模型?
先把背景铺开。多肽这东西,本质是小号的蛋白质,所以它老老实实遵循那条经典的序列—结构—功能 教条:氨基酸序列决定三维结构,三维结构决定干什么活。但多肽还有个让人头疼的特性,叫moonlighting,说白了就是一条肽往往不止一个功能。一段序列既能抗菌、又能调节免疫、还顺带能穿膜,这种事在多肽世界里太常见了。
问题恰恰出在这。要让AI真正吃透多肽,理想的数据应该同时具备序列、结构、功能三个维度,而且功能最好是多标签的——因为只有功能信息足够完整、足够多样,模型才能把序列—结构—功能 这条链路学明白,甚至反过来做老药新用。
但现实是什么样?过去十几年,全世界建了一堆多肽数据库,可基本都是各扫门前雪。抗菌肽有抗菌肽的库(比如APD、DRAMP),抗病毒肽有抗病毒肽的库(AVPdb、DRAVP),降糖肽、肽激素也各有各的小仓库。综合性的库不是没有,像SATPdb、EROP-Moscow、BIOPEP-UWM,但它们对两件事始终不上心:一是多功能标注,二是结构信息。
数字最能说明问题。在这份新数据集出来之前,收录多功能肽最多的库是SATPdb,也才9986条;结构标注做得最好的同样是SATPdb,16131条。更要命的是,这些库里仅有的那点结构数据,大多还是用老一代结构预测工具算出来的,精度上先天打了折扣。
把这些痛点串起来看,结论很直接:不是没有数据,而是数据散、维度缺、标准乱。模型训练讲究 garbage in garbage out,当你的训练集是从几十个口径不一的小库里东拼西凑来的,标签还互相打架,再花哨的网络结构也救不回来。这也是为什么这两年抗菌肽预测、抗癌肽预测的深度学习论文层出不穷,但真正能跨功能泛化、能落到湿实验里产出新分子的,凤毛麟角。底座没打好,楼盖不高。
散落在33个库里的肽,他们是怎么拼成一张完整的牌的?
这份工作的思路其实很工程化,没有去卷模型,而是老老实实做了一件又脏又累、但价值极高的活:把全网的多肽数据归拢、清洗、对齐,再补上结构。
第一步是定靶。团队没有上来就漫无目的地抓数据,而是先从PepTherDia里把120个已获批上市的多肽药物拎出来,按治疗属性归成14个类别——神经肽、抗菌、抗癌、降压、免疫活性、降糖、抗病毒、成骨、镇痛、溶栓、生长调节、脂代谢、抗氧化、皮肤再生。这14类是临床上真金白银验证过的刚需方向,等于先用上市药把数据集的骨架立住,再往外扩。这个起手式很聪明,避免了为了凑数量去收一堆没有临床意义的肽。
第二步是撒网。围绕这些类别关键词,团队在Google Scholar上用 类别词 AND peptide AND database 这样的组合去检索,又顺着高被引的综述和方法论文去捞大家常用的库,最后锁定了UniProt加上32个公开数据库,一共33个数据源。
第三步是搭分类骨架。最终的体系是15个大类、47个子类。15个大类是抗菌、抗真菌、抗寄生虫、抗病毒、抗微生物、免疫活性、抗癌、抗高血压、溶栓、神经肽、抗氧化、代谢调节、生长再生、细胞通讯、药物递送。这里有个细节值得点一下:抗菌、抗真菌、抗寄生虫、抗病毒理论上都该归在抗微生物名下,但因为各自子类太多,团队干脆把它们拎出来单列,剩下的抗微生物大类只装那些归不进上述四类的肽。47个子类里,32个是明确的具体功能(比如抗革兰氏阳性、抗HIV、抗乳腺癌、穿膜、肿瘤归巢),另外15个是unknown label,专门兜底那些归不进具体子类的肽。这种设计的好处是分类既细又不漏。
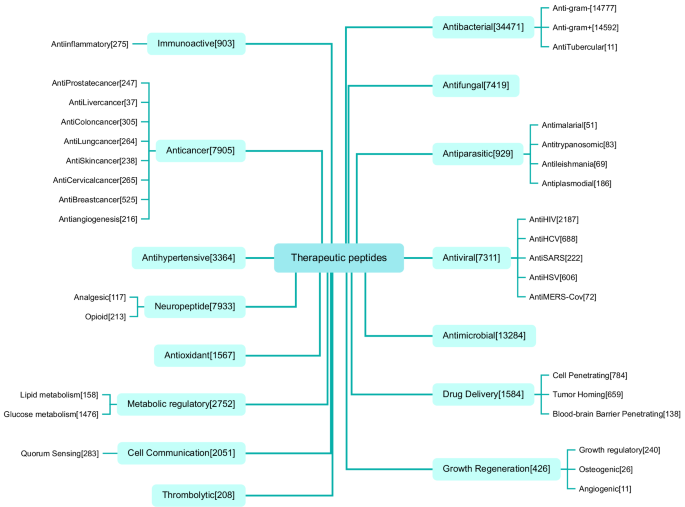
治疗性多肽的15个大类与47个子类分类体系,括号内为各类别收录的肽数量
治疗性多肽的15个大类与47个子类分类体系,括号内为各类别收录的肽数量
至于多功能怎么定义,团队给了条清晰的硬规则:一条肽要同时挂着至少两个互相之间没有从属关系的功能标签,才算多功能。比如既标抗菌又标抗细菌,不算,因为抗细菌本来就在抗菌的范畴里;但既抗革兰氏阳性又抗血管生成,就算,因为这俩八竿子打不着。这个定义看着简单,实际是在帮模型剔除掉伪多功能的噪声。
最硬核的一块是结构补全。这里团队搭了一条混合流水线,按肽的特性分流:先从PDB里把实验测定的三维结构捞出来,但说实话只有179条肽有;剩下的天然肽按长度分流,序列长于16个氨基酸的丢给AlphaFold2,短于16的交给ESMFold——因为AlphaFold2对超短序列并不友好;带简单修饰的肽则用PEPstrMOD来预测。最后再用DSSP从三维结构里算出二级结构。
工程上的硬约束在这里体现得淋漓尽致。跑AlphaFold2时,考虑到肽本来就短,团队把模型数设成1、循环数设成1,关掉模板引导,也不做AMBER能量最小化,还设了个pLDDT超过90就提前停的开关,纯粹是在精度和算力之间找平衡。这一通操作下来,AlphaFold2产出24746条结构,ESMFold产出29162条,PEPstrMOD补了635条,加上PDB那179条,凑齐了54722个结构文件。

数据编译技术流程,依次为适应症范围界定、33个数据源整合、数据编译与结构预测、质量控制与归一化
数据编译技术流程,依次为适应症范围界定、33个数据源整合、数据编译与结构预测、质量控制与归一化
收尾的清洗和归一化同样不含糊。所有序列统一用单字母氨基酸缩写,L型用大写、D型用小写来区分;复杂的结构信息用HELM这套大分子编辑语言来编码;只保留长度在2到50个氨基酸之间的肽;每个功能类别内部做去重;去重后只留下序列数超过50的类别,唯独那14个临床刚需类别不设这个门槛。整套流程全靠自己写的Python脚本跑下来,没依赖外部工具。这种把脏活做到底的态度,恰恰是数据集质量的命根子。
数字摆出来:到底比第二名强在哪?
回到那张对比表。这份数据集58583条肽、47个类别、21130条多功能肽、54722个结构文件;而各项指标上表现最好的其他库分别是30260条、22类、9986条多功能、16131个结构。注意,对比表里每一列取的都是别人家在该指标上的最好成绩,不是同一个库——也就是说,这份数据集是用一己之力,在四个维度上同时压过了各路最强对手。
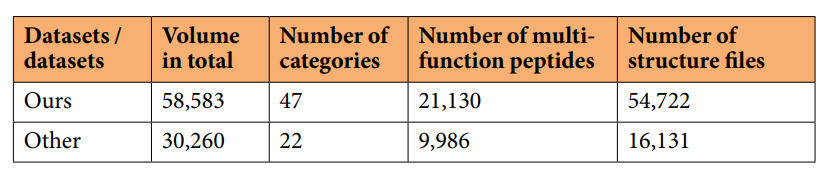
本数据集与现有最优数据库的对比,每列均取其他库在该指标上的最佳值
本数据集与现有最优数据库的对比,每列均取其他库在该指标上的最佳值
多功能肽翻倍、结构文件涨到三倍多,这两个数字含金量最高。它们正好补的就是前面说的两块短板。多功能标签多了,模型才有机会学到一条序列同时承担多种功能的内在规律,这对老药新用是直接利好;结构文件多了,那条序列—结构—功能的链路才算真正接上了中间那一环。
完整性这块也交代得很诚实。所有肽都有序列和功能信息,93%的肽有结构信息,剩下那7%主要是修饰太复杂、三维结构实在预测不出来;75%的肽带有来源信息。来源覆盖了4500多个物种,长度分布从2到50每一个数值都不缺。47个功能类别里,42个的肽数过50,38个过100。这些数字摞在一起,说明它不是某几个类别撑场面、其他类别空壳子,而是相当均衡的一份家底。
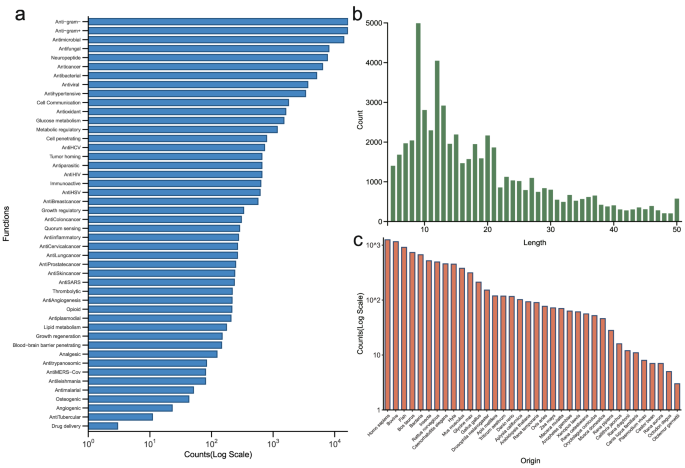
治疗性多肽的功能类别、序列长度与来源分布
治疗性多肽的功能类别、序列长度与来源分布
不过有一个细节,我得替读者把它从原文里抠出来说清楚,因为这关系到你拿它训模型时心里要不要打个鼓。摘要里写的是从PDB获得了54722条肽的实验测定结构,但翻到方法部分会发现,真正来自PDB的实验结构只有179条,其余五万多条全是AlphaFold2、ESMFold、PEPstrMOD算出来的预测结构。这不是说预测结构没用——恰恰相反,在实验结构稀缺的多肽领域,预测结构就是当下最现实的解。但用的时候得有数:这是一份以AI预测结构为主体的结构数据集,做下游分析、尤其是涉及结合位点、构象细节这类对结构精度敏感的任务时,最好把这层不确定性纳入考量。把话说在前头,比事后踩坑强。
数据一致性的处理也藏着功夫。33个库整合到一起,光是同一个东西叫法不同就够喝一壶——anti-inflammatory和anti-inflammation、anti-cancer和anti-tumor、同一种芋螺有好几个写法。团队的做法是以序列为唯一标识先对齐,再把同一类别下所有可能的标签归拢,按出现频率定最终用哪个,频率打平时就看哪个更常出现在高影响力期刊的库里。标注层级不一致时,原则上取更精细的那个,比如来源能定到Bacillus pumilus就不写笼统的bacteria,功能能定到抗细菌就不写笼统的抗微生物。这种近乎手工绣花的归一化,正是综合数据库最容易翻车、也最见功底的地方。
一份数据集的野心,其实不止于多肽
读完最直接的感受是,这类工作在AIDD的叙事里长期被低估了。大家追逐的是模型、是榜单、是参数量,但真正决定一个垂直领域能不能跑通AI范式的,往往是有没有人愿意沉下心把数据这块基建做扎实。这份数据集本身不产出任何新算法,作者也明说了没有用于生成数据的自定义代码,它的价值就在于把分散十几年的多肽家底归拢成了一个标准、干净、多维度的底座。
往下游看,它能直接支撑的事情很具体:抗菌肽预测、多功能肽预测、多肽老药新用,这些计算流水线现在都能在一个统一的数据基础上重新搭建。更有想象空间的是序列—结构—功能关系的系统性挖掘——当你手里同时握着五万多条带结构、两万多条带多功能标签的肽,去训练一个多肽专属的表征模型或者基础模型,第一次有了像样的语料。这正好接上了当下蛋白质语言模型、序列预测功能这一波技术浪潮的接口。
再往远处想,这件事的意义会溢出多肽本身。结构这块全靠AlphaFold2、ESMFold这类工具批量产出,本身就说明AI预测正在成为科学数据的标准生产方式之一;而这种动辄五万条序列的批量结构预测,背后是实打实的算力消耗,天然要往HPC、大规模并行模拟那个方向去对接。换句话说,未来的科研数据集,越来越像是算法、算力和人工策展三者咬合的产物,这份多肽数据集只是其中一个很典型的切片。
当然,边界也得划清楚。预测结构终究替代不了实验测定,五万多条结构里有多少经得起湿实验的检验,仍是个待验证的开放问题;数据集是起点而非终点,真正的考验在于有多少下游研究愿意在它之上长出东西来。但至少,当下一个想做多肽AI的团队不必再从零去拼那一地碎片时,这份工作的价值就已经兑现了大半。风口上的多肽很热闹,而把地基悄悄夯实的人,往往要过一阵子才被看见。
参考文献
Xiao, B., Zhou, Y., Zhao, L. et al. A comprehensive dataset of therapeutic peptides on multi-function property and structure information. Sci Data 12, 1213 (2025).
https://doi.org/10.1038/s41597-025-05528-1
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-01,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号