分析一篇AI Coding论文| 基于7156个Pull Request PR接受率深度对比

分析一篇AI Coding论文| 基于7156个Pull Request PR接受率深度对比

用户5602664
发布于 2026-06-01 18:10:07
发布于 2026-06-01 18:10:07
当OpenAI Codex、GitHub Copilot、Devin、Cursor、Claude Code五大AI编码代理同台竞技,谁的PR最容易被接受?答案没有你想的那么简单。
来自UCL和King's College London的研究团队,分析了7,156个真实Pull Request,发表于软件工程顶会MSR 2026,给出了目前最系统的对比研究。
核心发现:没有单一的"最强Agent"。任务类型才是决定PR能否被合并的第一要素——不同任务类型间的接受率差距(29%)远大于不同Agent间的差距。
一、研究概况:规模与方法
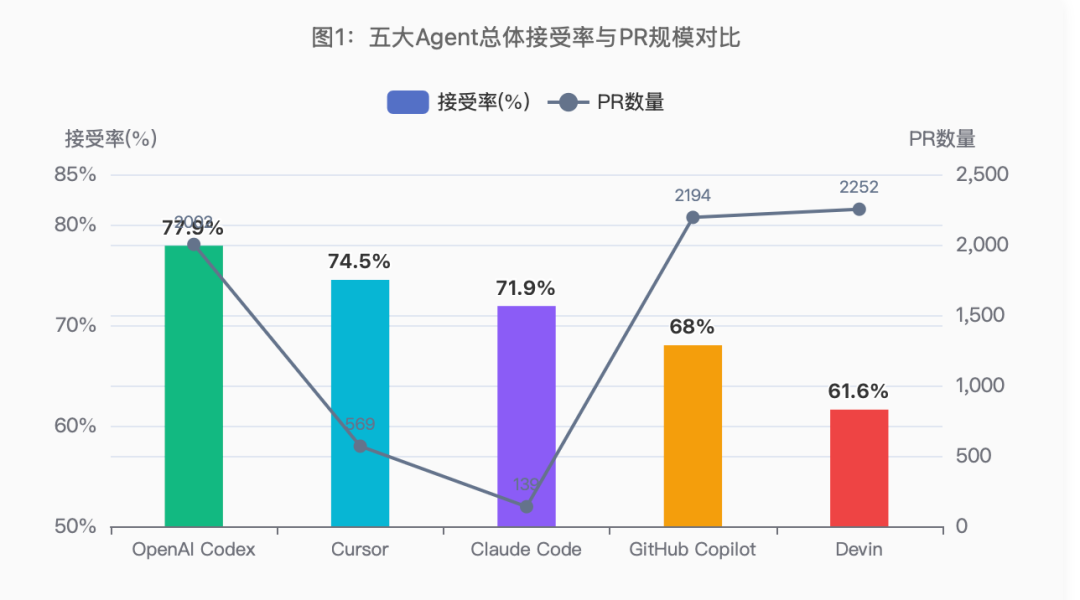
研究基于AIDev数据集,这是目前最大的AI编码代理PR数据集,覆盖GitHub上100+星标仓库。五大Agent的基本画像如下:
Agent | PR数量 | 活跃周数 | 周均PR | 总体接受率 |
|---|---|---|---|---|
Devin | 2,252 | 32 | 70.4 | 61.6% |
OpenAI Codex | 2,002 | 12 | 166.8 | 77.9% |
GitHub Copilot | 2,194 | 11 | 199.5 | 68.0% |
Cursor | 569 | 13 | 43.8 | 74.5% |
Claude Code | 139 | 19 | 7.3 | 71.9% |
图1:五大Agent总体接受率与PR规模对比

二、关键发现1:任务类型是第一决定因素
研究发现了一个反直觉的结论:决定PR能否被合并的第一要素不是你选了哪个Agent,而是你让它做什么任务。
图2:不同任务类型的PR接受率(Mean Acceptance Rate)
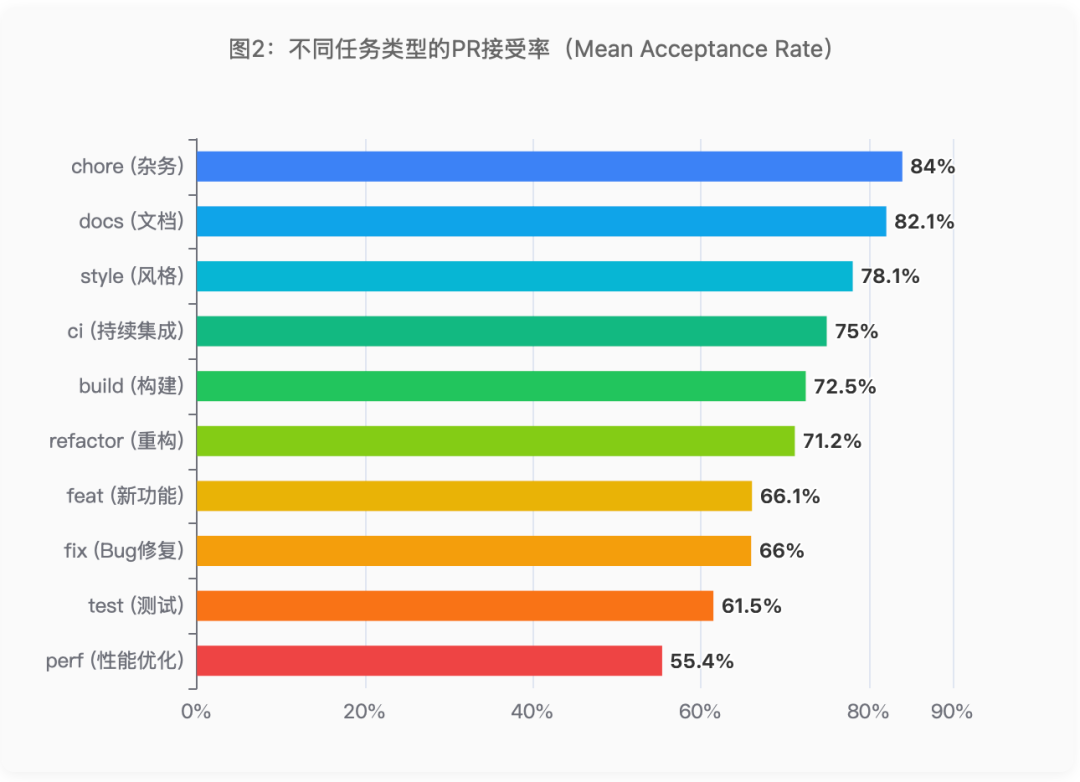
关键数据:chore任务接受率84.0% vs 性能优化任务55.4%,差距达29个百分点。文档任务82.1% vs 新功能66.1%,差距16个百分点——这个差距超过了大多数Agent之间的差异。
这意味着什么?如果你只看全局接受率,一个专做文档任务的Agent会"看起来"比一个专做功能开发的Agent强得多——但这是任务分配的结果,不是能力的体现。
三、关键发现2:Agent各有所长
当控制了任务类型后,研究揭示了各Agent的真实能力分布:
图3:各Agent在不同任务类型中的接受率热力图
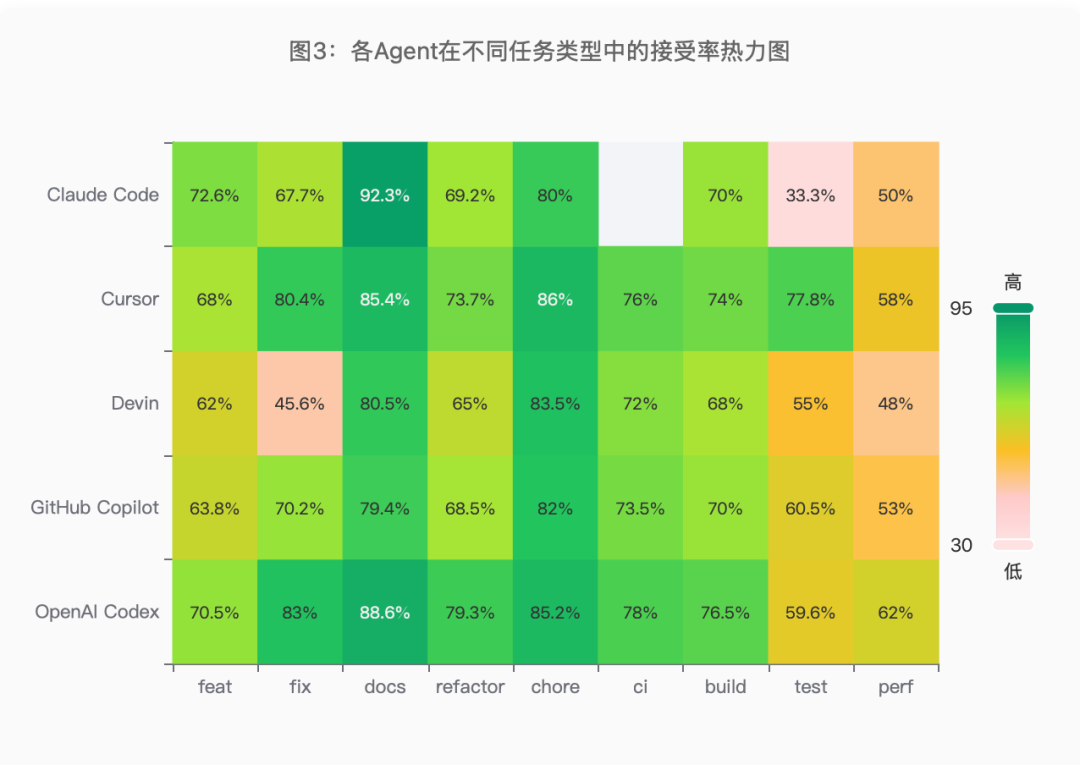
- OpenAI Codex:全能选手,所有9个任务类别中接受率均在59.6%-88.6%之间,fix和refactor任务尤为突出
- Claude Code:文档之王(92.3%)和功能开发最佳(72.6%),但测试任务最弱(33.3%)
- Cursor:Bug修复专家(80.4%),测试任务表现也很好(77.8%)
- Devin:唯一展现持续进步趋势的Agent,但fix任务接受率较低(45.6%)
- GitHub Copilot:产出量最大(周均199.5个PR),但质量中等
最大差异:test任务上Cursor(77.8%)vs Claude Code(33.3%),差距44.4个百分点——说明越复杂的任务,Agent之间的差异越大。
四、关键发现3:Devin是唯一持续进步的Agent
在32周的观察期中,Devin展现了唯一统计显著的正向趋势:每周接受率提升0.77%,从约60%提升至约80%。
图4:各Agent接受率的时间演化趋势
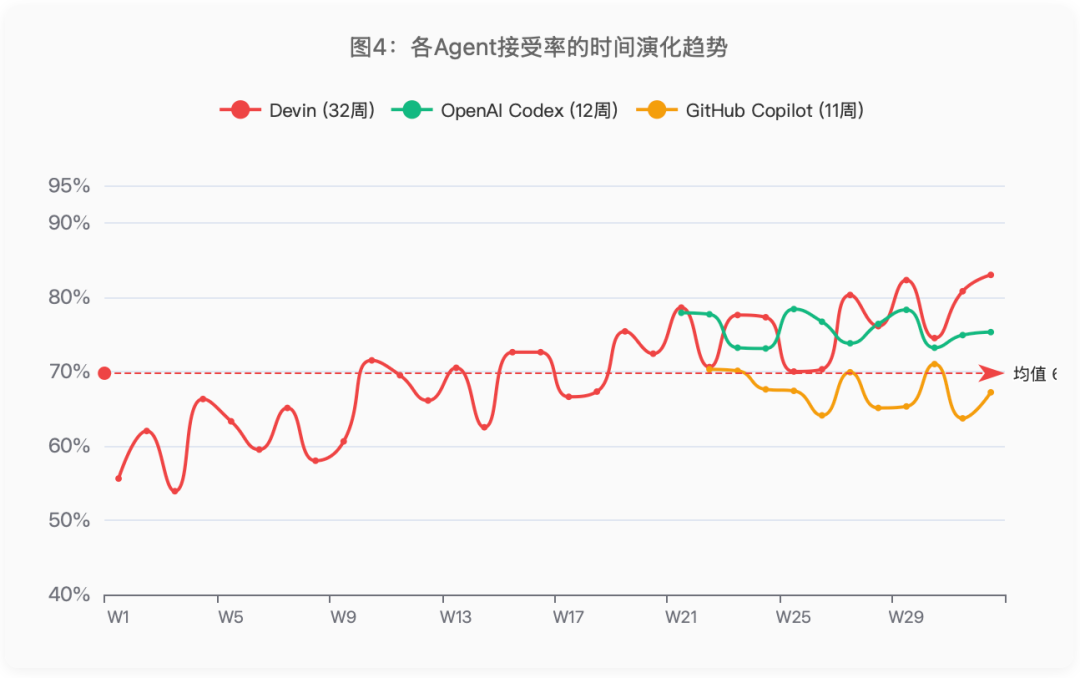
更有意义的是,Devin的进步发生在它同时处理更多复杂任务的背景下——32周内feat任务占比上升了9.8个百分点。这意味着实际能力提升可能比数据显示的还要大。
相比之下,OpenAI Codex和GitHub Copilot从上线第一周就保持高位稳定——这可能意味着它们从一开始就更成熟,也可能意味着它们的提升空间更有限。
五、关键发现4:任务分配严重不均
各Agent实际处理的任务类型分布差异巨大,这是理解全局数据的关键背景:
图5:各Agent的任务类型分布(占比%)
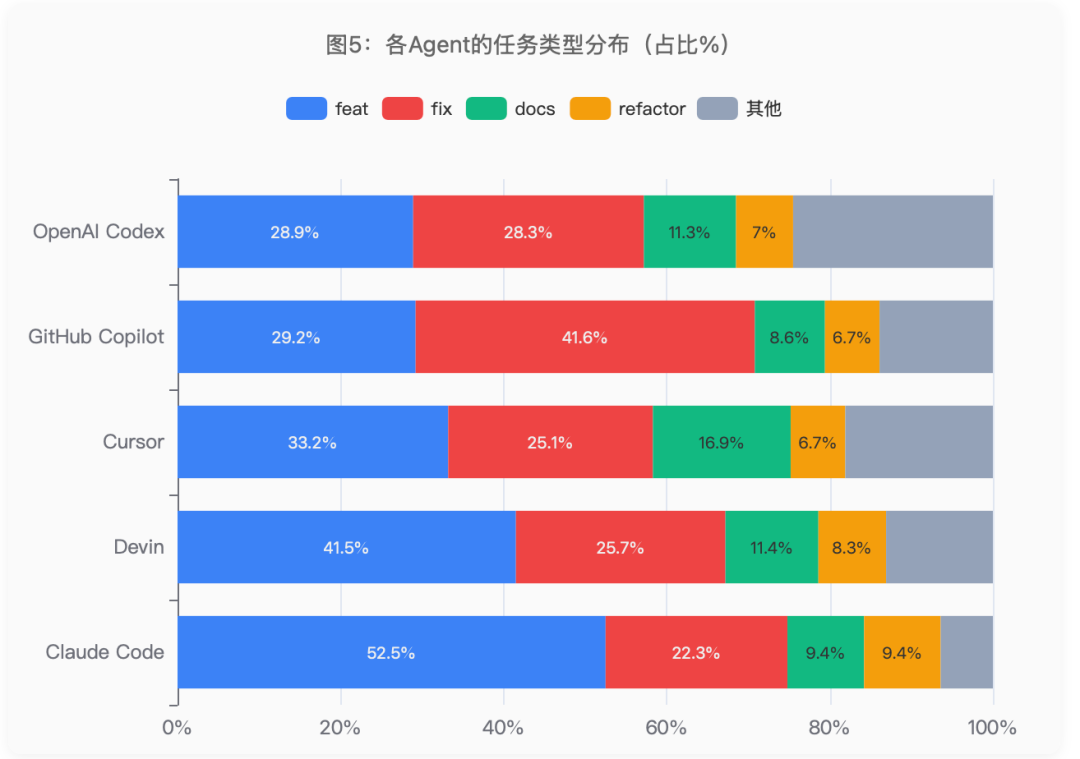
Claude Code的PR中52.5%是功能开发(最难的任务类型之一),而GitHub Copilot有41.6%是Bug修复。这种分配差异使得直接比较全局接受率毫无意义——必须按任务类型分层比较。
六、对企业AI Coding落地的启示
实践建议
- Bug修复场景:优先选择Cursor(80.4%)或OpenAI Codex(83.0%),避免Devin(45.6%)
- 功能开发场景:Claude Code(72.6%)和OpenAI Codex表现最优
- 文档任务:所有Agent都能胜任(≥79%),差异不大
- 测试编写:选择Cursor(77.8%),慎用Claude Code(33.3%)
- 重构任务:OpenAI Codex是最佳选择
图6:按场景选Agent——各任务类型最优Agent推荐

七、方法论启发:为什么"全局排名"不靠谱
这篇论文最大的方法论贡献是提出了任务分层比较(Task-Stratified Comparison)的必要性:
- 全局接受率会被任务分配严重扭曲
- 未来的评测应该报告任务分布、按类型分层比较、标注样本不足的类别
- 接受率 ≠ 代码质量,合并的PR也可能包含Bug
- 需要补充静态分析警告、复杂度、维护负担等互补指标
"简单的'最佳Agent'排名是反证据的。任务上下文和时间动态必须纳入评估框架。"——论文结论
八、总结
这项研究给出了迄今为止最系统的AI Coding Agent对比分析。核心结论:
- 没有银弹:没有一个Agent在所有任务类型中都是最优的
- 任务决定成败:任务类型对接受率的影响(29pp差距)远大于Agent选择的影响
- 组合策略最优:企业应根据具体任务场景选择不同的Agent
- 持续进化中:Devin是唯一展现持续进步的Agent,说明这个领域仍在快速演化
论文引用: Pinna, G., Gong, J., Williams, D., & Sarro, F. (2026). Comparing AI Coding Agents: A Task-Stratified Analysis of Pull Request Acceptance. In Proc. 23rd Int. Conf. Mining Software Repositories (MSR '26). 链接:https://arxiv.org/abs/2602.08915
本文数据来源于MSR 2026论文,分析基于AIDev数据集(7,156 PRs)。文中图表均基于论文原始数据生成。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-30,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号