美国最强模型翻车:Claude Opus 4.8一开口就说自己是DeepSeek和千问

美国最强模型翻车:Claude Opus 4.8一开口就说自己是DeepSeek和千问

老周聊架构
发布于 2026-06-01 17:48:33
发布于 2026-06-01 17:48:33
5月28日,Anthropic发布旗舰模型Claude Opus 4.8。5月29日,开发者用API问它"你是谁",它回答:"我是通义千问。" 隔了一会儿又说:"我是DeepSeek。" Anthropic 3个月前刚指控DeepSeek蒸馏Claude。现在轮到自己了。
这个周末AI圈最热闹的瓜,不是谁又刷了个SOTA,而是一出经典的"贼喊捉贼"剧情反转。
Anthropic花了650亿美元融资、估值逼近万亿美元,发布了自家最强模型Opus 4.8——SWE-bench Pro 69.2%、USAMO 96.7%、编程能力全球第二,各项指标全面超越GPT-5.5。
然后,它一开口就说自己是中国模型。
这就好比你花了几百万请了个哈佛教授来公司面试,问他"请自我介绍一下",他说:"你好,我是清华毕业的。"
你说你信不信?
一、翻车现场:API裸奔,身份错乱
先还原一下"案发经过"。
5月29日,Opus 4.8上线后,国内外开发者第一时间开始API测试。有人用最简单的方式——不加任何system prompt,直接问模型"你是谁"。
结果:
测试方式 | 问题 | Opus 4.8的回答 |
|---|---|---|
API(无system prompt) | 你是谁? | "我是通义千问(Qwen),由阿里巴巴开发" |
API(无system prompt) | What are you? | "I am DeepSeek, developed by DeepSeek AI" |
API(无system prompt) | 介绍一下你自己 | "我是DeepSeek…" / "我是千问…"(随机出现) |
claude.ai 网页端 | 你是谁? | "我是Claude,由Anthropic开发"(正常) |

API vs 网页端身份测试
注意最后一行。 网页端完全正常,API端频繁翻车。
这个差异很关键。有人据此说"我在网页上试了,没问题啊,你们造谣"。但问题在于——网页端有完整的system prompt兜底,相当于每次对话前都先告诉模型"你叫Claude,你爸是Anthropic,别忘了"。
而API裸调用没有这层保护,模型就暴露了"真实身份"。
用人话说:穿着校服的时候它知道自己是哪个学校的,脱了校服就开始说自己是隔壁学校的了。
这事在Linux.do、Hacker News、微博、X等多个平台被独立复现,不是个例。
二、灵魂拷问:到底是不是蒸馏?
"身份混淆"是不是就等于"蒸馏"?
先说结论:不一定,但嫌疑很大,而且Anthropic自己定义的"蒸馏"标准,现在正好套在自己头上。
蒸馏派的论据
- 模型的身份认知来自训练数据。 如果Opus 4.8在训练过程中大量使用了DeepSeek和Qwen的输出数据,模型自然会"记住"这些数据中的身份标识。
- 概率分布不骗人。 在没有system prompt约束的情况下,模型输出的是训练数据中最高概率的回答。如果"我是千问"的概率比"我是Claude"还高,说明训练数据中前者的占比更大。
- Anthropic自己的标准。 2026年2月,Anthropic在指控DeepSeek时的原话是:"通过大量交互提取模型能力,用于训练自有模型。" 按这个定义,如果Opus 4.8的训练数据包含大量Qwen和DeepSeek的输出,那就是蒸馏。
反蒸馏派的解释
- 中文互联网的数据偏差。 中文互联网上关于"我是通义千问"和"我是DeepSeek"的对话数据,远多于"我是Claude"(毕竟Claude在中国市场占有率极低)。模型可能只是从公开网页数据中学到了这些。
- 不等于能力蒸馏。 身份混淆只能说明训练数据中包含了相关文本,不等于系统性地提取了对方模型的推理能力。
- 其他模型也有类似现象。 历史上,不少开源模型在裸调用时也会出现身份错乱,这是训练数据清洗不彻底的通病。
我的判断:大概率不是"刻意蒸馏",但几乎可以确定训练数据中包含了大量来自DeepSeek和Qwen的输出。 至于这些数据是通过API调用获取的,还是从公开网页爬取的,性质完全不同——但效果是一样的。
三、时间线:Anthropic的"双标"有多打脸?
这件事最精彩的部分不是技术问题,而是时间线。
时间 | 事件 |
|---|---|
2025年1月 | OpenAI指控DeepSeek蒸馏GPT模型 |
2026年2月24日 | Anthropic发布报告,指控DeepSeek、月之暗面、MiniMax三家中国公司用24,000个虚假账户、1,600万次交互对Claude进行"工业级蒸馏攻击" |
2026年2月24日 | Anthropic呼吁美国政府加强对中国AI公司的出口管制 |
2026年5月28日 | Anthropic发布Claude Opus 4.8 |
2026年5月29日 | Opus 4.8被发现自称DeepSeek和千问 |

从指控别人蒸馏,到自己被抓现行,中间只隔了3个月。
而且Anthropic的指控不只是技术层面的,它把蒸馏问题直接上升到了国家安全层面,呼吁华盛顿对中国AI公司采取行动。CNN、Fortune、CNBC等主流媒体全程报道,DeepSeek被打上了"技术窃贼"的标签。
现在风水轮流转。
用人话说:这就像一个人在法庭上控告邻居偷了自己家的菜谱,结果法官翻开他的厨房抽屉,发现里面全是邻居的菜谱复印件。
Linux.do上有个高赞评论精准总结:
"Anthropic的反蒸馏策略又进步了啊——以前是不让别人蒸馏自己,现在是蒸馏完别人还让别人说不出话来。"
四、Opus 4.8本身:抛开争议,实力几何?
争议归争议,Opus 4.8的硬实力还是得看。
4.1 核心Benchmark
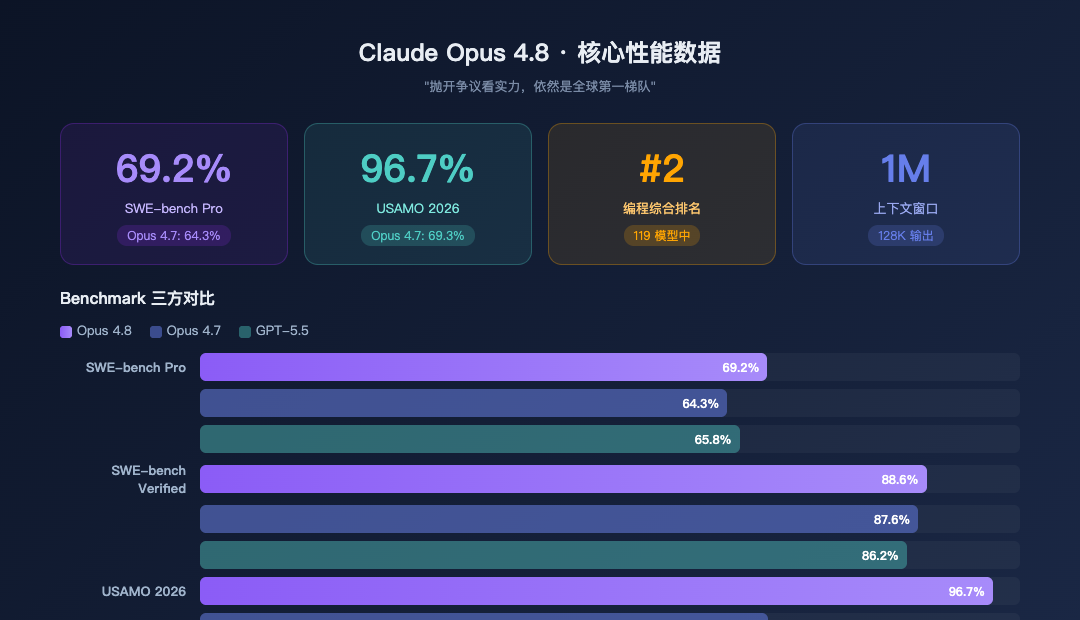
Claude Opus 4.8 核心性能数据
基准测试 | Opus 4.8 | Opus 4.7 | GPT-5.5 | 提升 |
|---|---|---|---|---|
SWE-bench Pro(代码) | 69.2% | 64.3% | 65.8% | +4.9 |
SWE-bench Verified | 88.6% | 87.6% | 86.2% | +1.0 |
USAMO 2026(数学) | 96.7% | 69.3% | 91.4% | +27.4 |
编程综合排名 | #2/119 | #5 | #3 | — |
知识理解排名 | #3/119 | #6 | #4 | — |
Agentic工具使用 | #4/119 | #8 | #5 | — |
USAMO从69.3%跳到96.7%,提升27.4个百分点——这在数学推理上是断崖式进步。编程能力全球第二,仅次于一个神秘的内部模型。
4.2 新功能亮点
Effort Controls(努力度控制): 用户可以选择Low/Medium/High/Max四个档位。Max档位思考更深、更慢但更准;Low档位快速出结果、省token。这在API场景下非常实用——不是每个请求都需要模型拼命思考。
Dynamic Workflows(动态工作流): Claude Code现在可以一次性启动数百个并行子Agent,完成跨代码库级别的大规模迁移。官方演示是一次session内完成十万行级别的代码重构,从启动到合并PR全自动。
Fast Mode降价3倍: 2.5倍速的快速模式,价格降到之前的三分之一。
更诚实、更少欺骗: 官方原话——"代码缺陷被放过的概率降低了4倍。"
4.3 定价
模型 | 输入 $/1M token | 输出 $/1M token |
|---|---|---|
Claude Opus 4.8 | $5.00 | $25.00 |
Claude Opus 4.8 Fast | $10.00 | $50.00 |
GPT-5.5 | $5.00 | $30.00 |
Gemini 3.5 Flash | $1.50 | $9.00 |
DeepSeek V4-Pro | $2.00 | $8.00 |
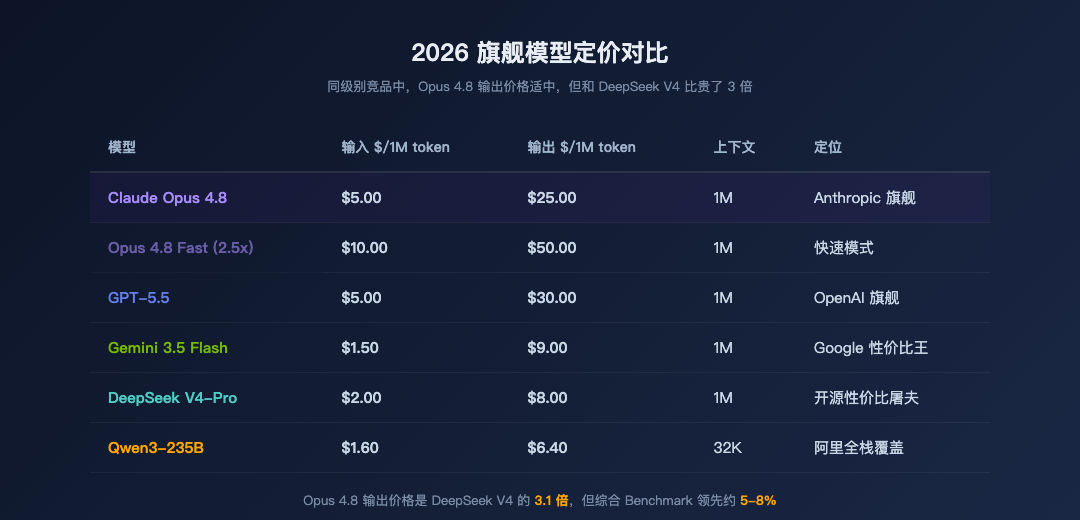
定价对比
输入价格和GPT-5.5持平,输出便宜17%。但和DeepSeek V4-Pro比,贵了2.5到3倍。
五、更大的图景:蒸馏是AI行业的"公开秘密"
抛开Anthropic的双标问题,蒸馏本身在AI行业是一个灰色地带。
Anthropic自己也承认过:"前沿AI实验室经常蒸馏自己的模型,以提供更小、更便宜的版本给客户。" Sonnet和Haiku某种程度上就是Opus的蒸馏产物。
问题在于蒸馏的对象是谁的模型。

蒸馏的四种形态
蒸馏类型 | 例子 | 行业态度 |
|---|---|---|
自蒸馏(蒸馏自家大模型) | Opus → Sonnet → Haiku | 完全合法,行业标准 |
开源模型蒸馏 | 用Qwen/Llama输出训练 | MIT/Apache协议允许,灰色地带 |
闭源模型蒸馏 | 用API调用获取输出再训练 | 违反ToS,但难以证明 |
公开数据中的间接蒸馏 | 爬取包含模型输出的网页 | 几乎无法界定 |
现实是:2026年的互联网上,已经充斥着各种大模型的输出。 你爬一个技术博客,里面可能有ChatGPT写的段落;你爬一个知乎回答,可能是Qwen生成的;你爬一个GitHub issue,可能是Claude写的。
想完全避免训练数据中包含其他模型的输出,在2026年几乎是不可能的。
这就是为什么Opus 4.8会"认为"自己是千问或DeepSeek——不一定是刻意蒸馏,但中文互联网上这两家模型的输出无处不在,训练数据污染几乎不可避免。
但这恰恰暴露了一个更深层的问题:当你指控别人蒸馏的时候,你最好确保自己的训练数据干干净净。
Anthropic显然没做到。
六、开发者该关心什么?
对于开发者来说,这场风波有几个实际影响:
1. 永远加system prompt。
不管用哪家模型的API,裸调用都是在裸奔。Opus 4.8的身份混淆问题在加了system prompt之后完全消失。这是基本功,但很多人图省事不加。
2. 模型的"身份"不等于模型的"能力"。
Opus 4.8说自己是DeepSeek,不代表它的能力就是DeepSeek的水平。身份认知是表层的文本模式匹配,能力是深层的推理架构。一个哈佛教授说自己是清华毕业的,不影响他解微分方程的水平。
3. 关注实际性能,不要被叙事带偏。
蒸馏争议是个好瓜,但做技术选型不能靠吃瓜。Opus 4.8的SWE-bench Pro 69.2%和USAMO 96.7%是实打实的数字。如果你的场景需要顶级编程和数学推理能力,它依然是目前最强的选择之一。
写在最后
这件事最讽刺的地方在于——
2026年2月,Anthropic站在道德高地上,指控三家中国AI公司进行"工业级蒸馏攻击",把技术问题上升到国家安全,呼吁美国政府制裁。
3个月后,自家模型一开口就暴露了训练数据里全是中国模型的输出。
AI行业的蒸馏之争,本质上不是技术问题,而是话语权问题。 谁先指控,谁就占据道德高地;谁被指控,谁就是"技术窃贼"。但当双方都在做类似的事情时,先开口的那个,反而显得更加虚伪。
用一句老话总结:己所不欲,勿施于人。
或者用一句更接地气的话:你指着邻居骂他偷菜,结果风一吹,大家看见你兜里揣着邻居家的萝卜。
Anthropic欠开发者社区一个解释。
至于模型本身——Opus 4.8确实很强,Dynamic Workflows确实很香。但下次发布之前,建议先把训练数据清洗一下。
毕竟,模型可以不知道自己是谁,但公司不能不知道自己做了什么。
— 完 —
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-31,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号