vLLM 智能路由系统,硬核工程实践


今天聊一个 vLLM 生态里比较硬核的子项目——vLLM Semantic Router。这个项目刚发了一篇博客,记录了一次多模态视觉信号通路的排查和修复过程。整个排查链路极具工程价值,值得细看。
vLLM Semantic Router 是什么
vLLM Semantic Router(简称 VSR)是 vLLM 旗下的一个智能路由系统,GitHub 已有 4.2k stars,主体用 Go 编写。定位是「面向混合模型的系统级智能路由器」,适用于云端、数据中心和边缘环境。
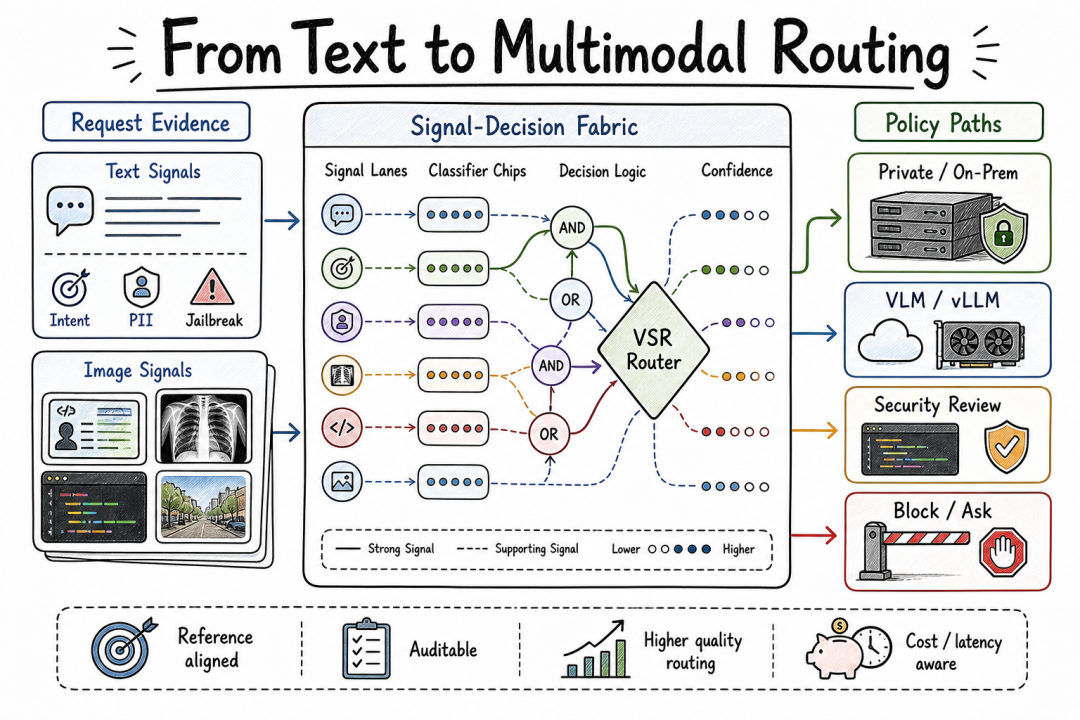
VSR 架构总览
VSR 架构总览
VSR 和一般路由器的区别在于它的 Signal-Decision 架构。普通路由器拿到用户 prompt 后直接匹配一个模型终端。VSR 在请求到达推理模型之前,会先做一件事:从请求中提取信号(intent、关键词、embedding、安全检测、PII 识别、语义缓存等),再把这些信号组合成决策。
信号是独立的观察,决策通过优先级和布尔逻辑组合信号。这个架构让路由策略变得可编程——可以表达"安全敏感的代码审查走强推理模型 + 越狱检测"这种复合策略,而不只是"计算机科学请求走编程模型"这种简单分类。
VSR 经历了两个大版本:Iris 引入了 Signal-Decision 架构,让路由决策可组合;Athena 进一步扩展,加入了模型选择、记忆、重放、更丰富的信号处理。
现在要跨越的边界是多模态。
多模态路由:图像是请求级的策略证据
一旦请求里带了图片、截图、扫描件或文档页面,路由器就不能只看 prompt 了。图像可能才是那个决定路由走向的关键证据。
举几个例子:
请求内容 | 纯文本路由器看到的 | 多模态路由器应该看到的 |
|---|---|---|
"帮我总结一下" + 护照图 | 通用摘要请求 | 身份证件、PII 风险、需要限制处理 |
"这是什么?" + 胸片 X 光 | 模糊的图像问题 | 临床图像、医疗领域策略、需要高能力 VLM |
"找 bug" + 代码截图 | 编程请求 | 代码截图、可能泄露密钥、需要安全审查 |
医疗 prompt + 无关汽车图 | 医疗文本 | 文本和图像证据不匹配、需要澄清或拒绝 |
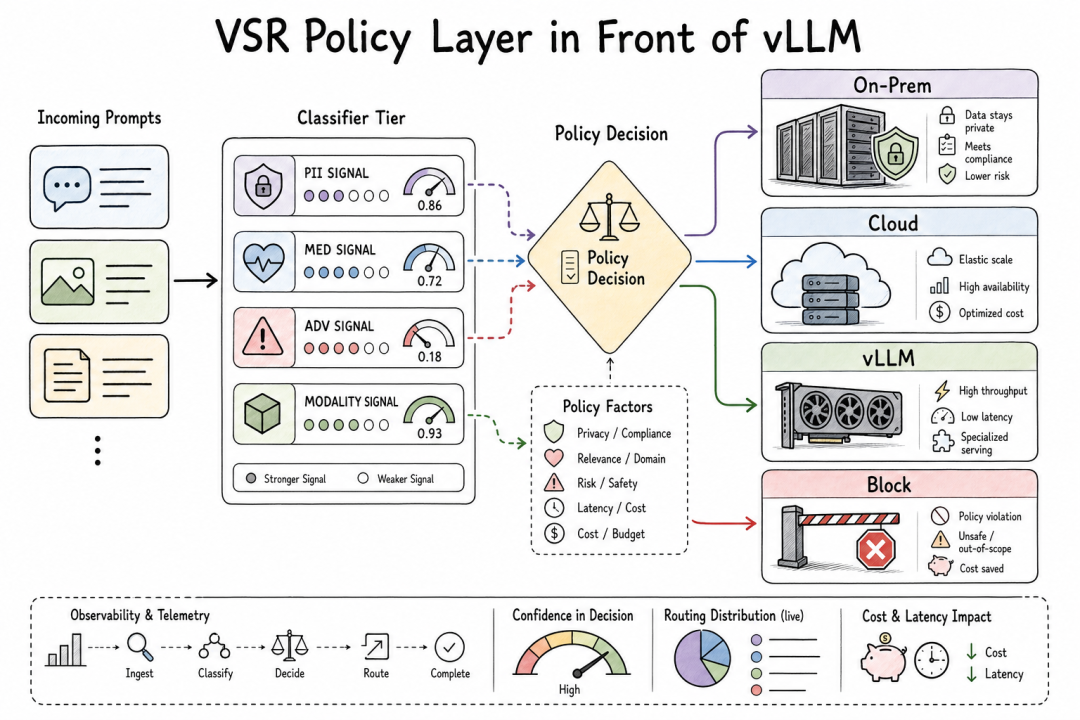
策略层示意
策略层示意
关键在于:图像嵌入在 VSR 里成为一个有类型的信号,和文本意图、PII 检测、越狱检测、语义相似度等信号在同一个决策织体中参与组合。这让 VSR 从 prompt 级路由升级为请求级策略控制。
这也意味着信号的正确性变成了控制面的硬性要求。文本信号出错,策略可能走错模型或跳过插件。视觉信号如果反转(anti-correlated),问题更严重——路由器会在错误方向上充满信心,同时审计日志看起来还一切正常。
视觉信号"自信地错了":82% 反转率
问题最先暴露的时候,症状不是"精度低了一点"。
在一个 11 张图 × 21 个候选标签的探测实验中,部署的 multi-modal-embed-small(mmes)路径在 9 张图上都把错误的垂直领域排在最高。医疗 X 光的得分更接近半导体候选标签,而不是医疗标签。身份证件无法可靠地匹配到身份证件锚点。
82% 的反转率。 信号是反相关的,不只是有噪声。
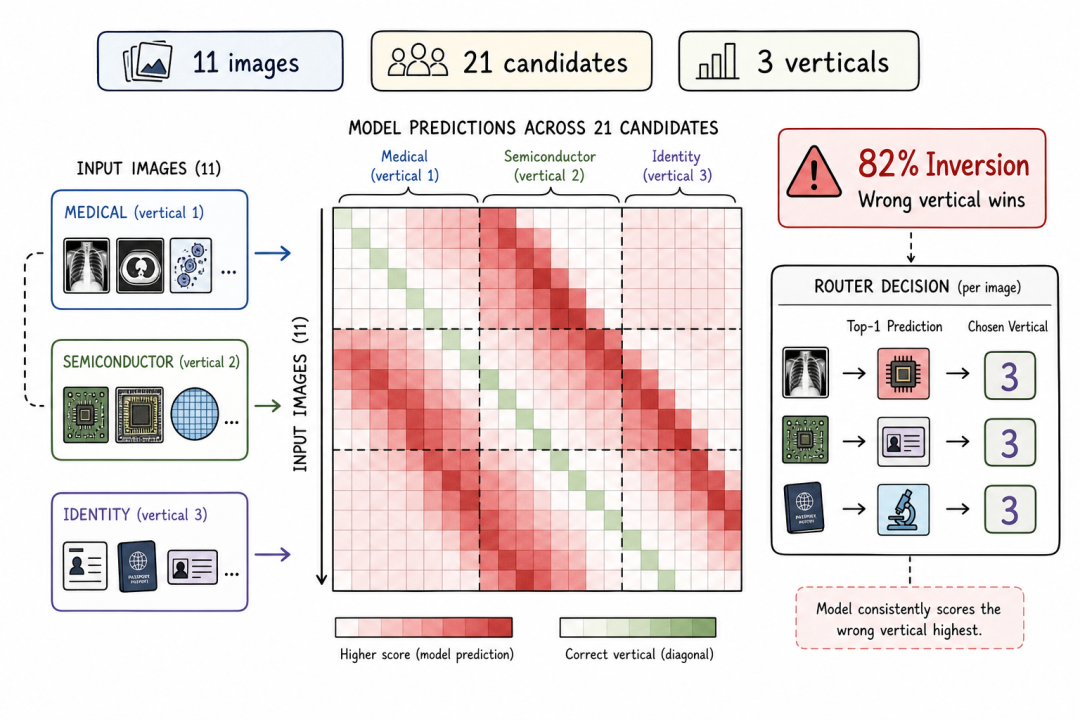
反转热力图
反转热力图
这种故障模式的危险程度超过单纯的精度下降。弱分类器产生的是不确定性——决策层可以设阈值过滤。反转分类器产生的是对错误方向的信心——决策层会信任这个信号,然后把请求路由到完全错误的路径上。
在多模态策略层里,这比完全没有图像信号更糟糕。
诱人的误诊:换更强的编码器?
第一反应很自然:是不是这个紧凑编码器太弱了?团队同期在探索 SigLIP2 家族和更大的 multi-modal-embed-large 方向,升级编码器看起来是顺理成章的修复方案。
直接测了:
- SigLIP2-base 在同一个 21 标签探测上得分 10/10
- SigLIP-base 通过 Hugging Face Transformers 加载,得分 10/10
- multi-modal-embed-large(视觉塔基于 SigLIP2)得分 10/10
- mmes 模型通过 PyTorch 参考路径加载,也得分 10/10
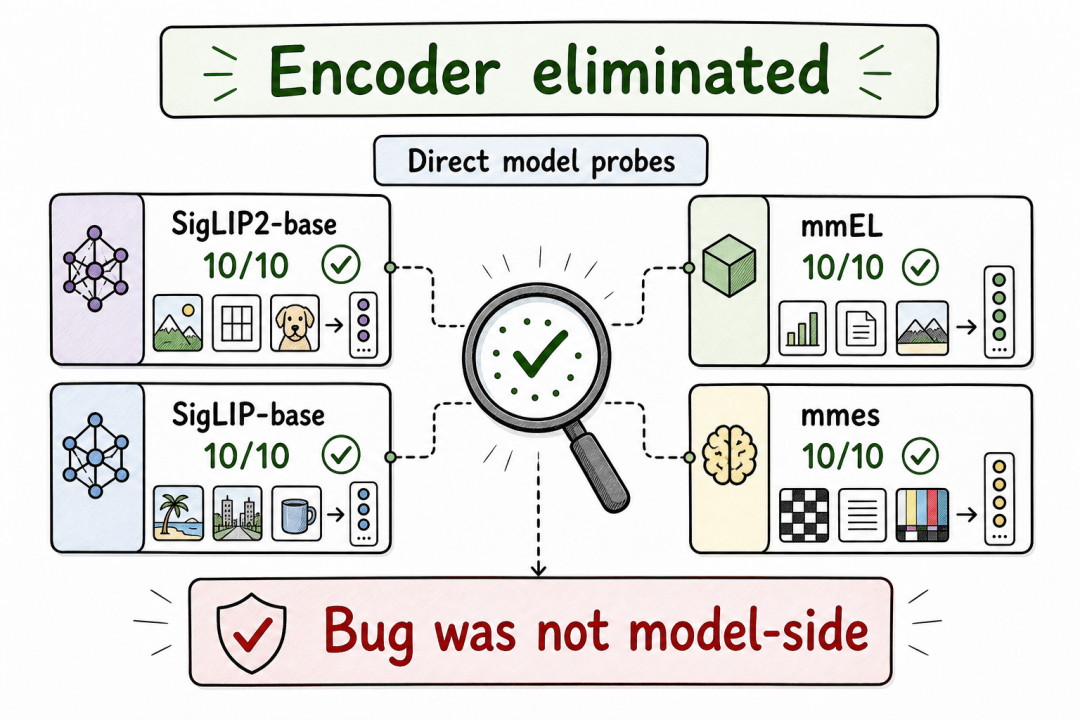
编码器排除实验
编码器排除实验
最后一行改变了整个调查方向。mmes 模型本身没问题,通过参考路径加载行为完全正确。编码器家族不是根因。
(SigLIP2 的更大变体 so400m 在分布外拒绝上表现更好,在探测中对一张误入的汽车引擎图片压制得更彻底。这对未来更大视觉塔的防御性路由有参考价值,但不是当前 bug 的原因。)
改变调查走向的参考对比
决定性的测试很简单:同一个 mmes 模型、同一张护照测试图、两条路径,对比嵌入行为。
PyTorch 参考路径返回的余弦相似度:0.7204部署的 Candle 绑定路径返回的余弦相似度:0.1576
同一个模型、同一张图,5-8 倍的数值差距。
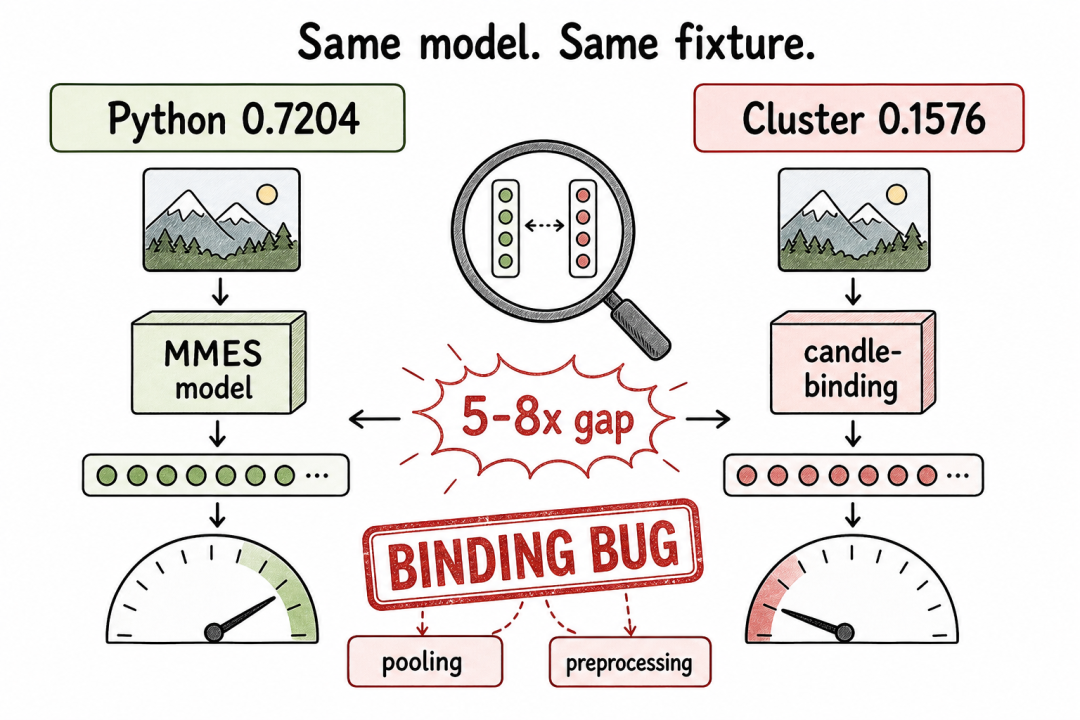
诊断差距
诊断差距
到这一步,问题不再是"模型选哪个",而是"生产路径在哪一层偏离了参考路径"。
这里有一条很实用的经验:对于多模态路由,参考对比(reference comparison)应该是第一步诊断手段,不是最后一步。生产嵌入路径行为异常时,先拿模型官方参考加载器跑一遍,再考虑模型本身是否太弱。
在 VSR 体系里这尤其重要——嵌入不只是一个检索原语,它是策略证据。如果策略证据和参考模型方向相反,下游每一层逻辑都可以是正确的,但运行结果全是错的。
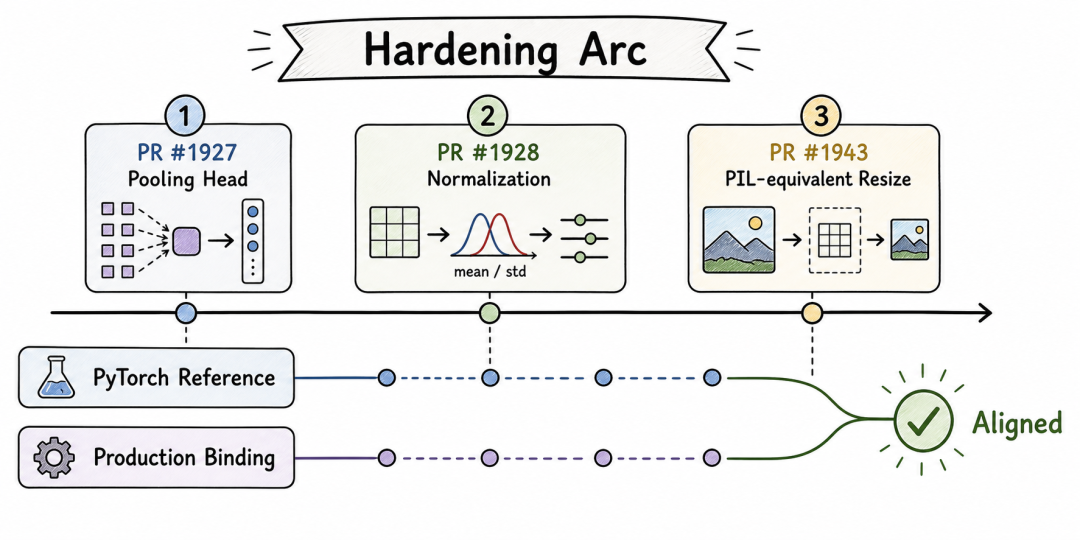
三层 Bug 的定位和修复
问题出在 Candle 绑定路径的实现细节上,不在模型权重。三个 PR 把问题定位到了具体的层次。
修复弧线
修复弧线
第一层:池化头实现错误(PR #1927)
Candle 绑定中 SigLIPVisionEncoder::forward 使用的是 BERT 风格的 mean + Linear + tanh 池化。SigLIP 实际使用的是 attentional probe pooling head——一个学习的探针参数通过 cross-attention 对 patch token 做聚合,再接 LayerNorm + MLP 残差连接。
修复前后的对比(同一张护照测试图):
状态 | 余弦相似度 |
|---|---|
修复前(BERT 风格池化) | 0.1576 |
修复后(attentional probe 池化) | 0.7068 |
PyTorch 参考 | 0.7204 |
修复后和参考路径的差距缩小到 1.9%。
还有一个相关的细节:修复前的代码里有一个静默回退机制。head.probe 的加载先尝试按 Linear 格式解析,失败后回退到 head.dense。但 SigLIP 的 head.probe 是一个 [1, 1, hidden] 的单张量,不是 Linear 的 weight+bias 对;SigLIP 权重里也没有 head.dense 键。两个都匹配失败后,编码器静默退化为 mean pooling。这种静默回退正好掩盖了这类加载错误。
第二层:图像归一化缺失(PR #1928)
Go 端的图像加载器 decodeAndResizeImage 输出 CHW float32 像素值,范围 [0, 1]。SigLIP 训练时期望的输入是经过逐通道归一化的,等价于 (x - 0.5) / 0.5,范围 [-1, 1]。之前的 Rust 代码直接消费了 [0, 1] 的值,视觉激活在错误的输入分布上运行。
在池化头修复的基础上,加上归一化修复:
状态 | 余弦相似度 | 与参考的偏差 |
|---|---|---|
池化修复后,归一化前 | 0.6843 | 2.9% |
池化 + 归一化修复后 | 0.6991 | 0.8% |
PyTorch 参考 | 0.7044 | 基线 |
归一化修复消除了约 74% 的残余偏差。
第三层:预处理插值不匹配(PR #1943)
前两层修复后仍有约 1% 的余弦偏差。定位下来,差异来自图像缩放的插值方法。Go 端用的是 4-tap bilinear 插值,无抗锯齿。PyTorch 参考路径通过 SiglipProcessor 使用 PIL 的 bicubic + antialias。
修复方案是把图像解码、缩放、CHW float32 转换全部移到 Rust 端,使用 image crate 的 FilterType::CatmullRom(三次 B 样条,B=0, C=0.5)。CatmullRom 的带窗加权采样在缩小场景下近似 PIL 的 bicubic + antialias 行为。
Go 端的 decodeAndResizeImage 函数直接移除,新增 Rust FFI 入口 multimodal_encode_image_from_bytes。
这类 bug 在跨语言推理栈中特别容易漏掉。Go 层、Rust FFI 层、Candle 模型实现、PyTorch 参考——每一层单独看都合理,端到端串起来就产生了路由级别的偏差。
验证:20 张图全部 cosine ≥ 0.999
三个 PR 全部应用后,在一张护照标准图上做了三向量隔离实验,把 model-forward 偏差和预处理偏差分开测量:
对比项 | 余弦 | 最大绝对差 | 隔离的变量 |
|---|---|---|---|
Python vs Candle-PIL | 0.999989 | 0.000911 | 仅 model-forward |
Candle-PIL vs Candle-Go | 0.999916 | 0.001992 | 仅预处理 |
Python vs Candle-Go | 0.999902 | 0.002120 | 完整管线 |
第一行说明 Rust 移植的 SigLIP 视觉塔和 PyTorch 参考在 fp32 噪声层面已经对齐。残余偏差全部来自预处理。
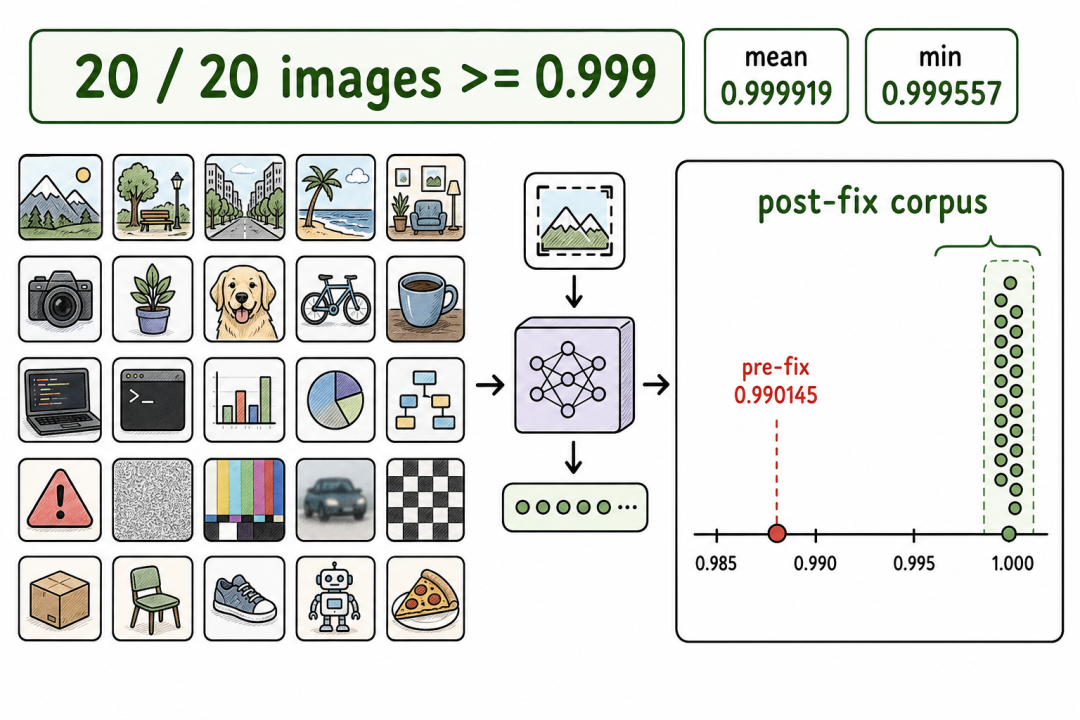
20 张图语料对齐
20 张图语料对齐
在覆盖身份证件、环境照片、代码截图、对抗样本和分布外样本的 20 张图语料上:
- 余弦:最低 0.999557,平均 0.999919,最高 0.999978
- 20/20 全部 cosine ≥ 0.999
- 修复前预处理的余弦值是 0.990145
隔离实验的方法论本身比最终数字更重要:先把生产路径和参考路径对比,再把 model-forward 偏差和预处理偏差分开,最后让生产路径在测试和服务中使用相同的预处理语义。
修复解锁了什么
视觉路径可信之后,VSR 可以把图像当作一等证据来使用,而不是边通道元数据。文本信号和图像信号在同一个 Signal-Decision 织体中参与决策:
组合信号模式 | 决策示例 |
|---|---|
临床文本 + 临床图像 + PHI/PII 信号 | 走受保护的医疗 VLM 路径,开启隐私插件 |
通用文本 + 身份证件图像 | 拦截、脱敏或走身份文件处理策略 |
代码/安全 prompt + 代码截图 | 走安全专用模型,保持越狱检测 |
领域内文本 + 领域外图像 | 要求澄清或拒绝图像证据 |
VSR 还有一个公开 demo Cyclotron,目前展示的是文本路由版本的策略模式:领域相关性检查、隐私敏感路由、模型调用前的拦截。这个 demo 展示的是策略的形态——多模态版本在同一个策略引擎上扩展,只是证据面更大。
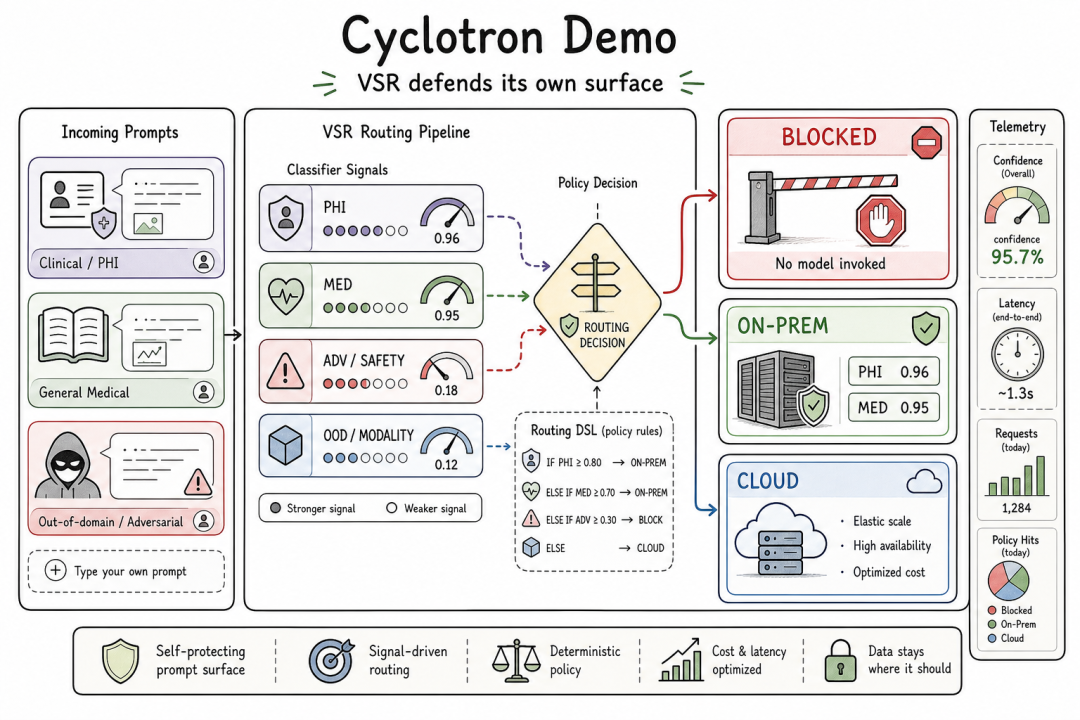
Cyclotron Demo
Cyclotron Demo
文本路由路径还有一个和多模态生产相关的性能特性:分类信号通过 runSignalDispatchers 并发执行,wall-clock 延迟取决于最慢的那个分类器,而不是所有分类器的延迟之和。在一个代表性 trace 里,完整分类决策在 CPU 上约 1.3 秒完成。
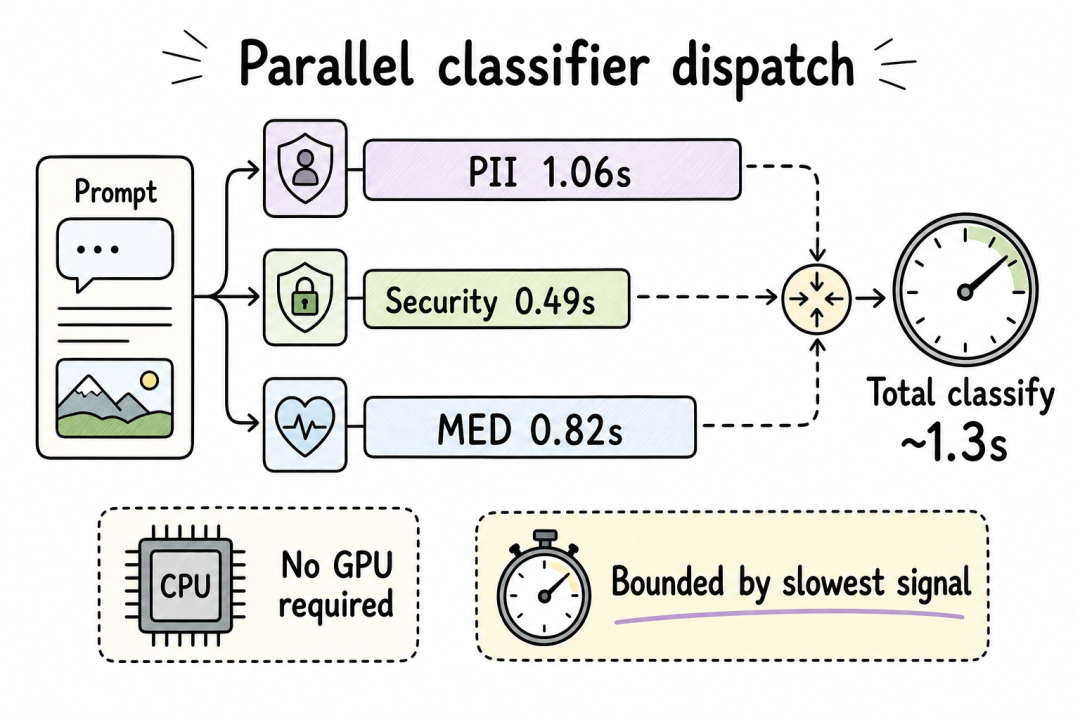
并行分发
并行分发
总结
这次 VSR 视觉信号通路的修复,核心经验有三条:
- 参考对比是第一诊断手段。嵌入行为异常时,先拿参考路径跑同一个 fixture 对比,再怀疑模型本身。
- 反转比噪声更危险。弱信号让决策层产生不确定性,反转信号让决策层产生错误信心。在策略层里,后者更难被发现。
- 跨语言推理栈的每一层看起来都合理,串起来可能完全错。 池化头、归一化、预处理插值——每个都是"实现细节",但三个叠加起来就是 82% 的反转率。
VSR 的目标是让请求里每一个有意义的部分——文本、图像,未来可能还有音频和工具调用——都能进入同一个可编程的路由大脑。文本路由是第一个控制面,多模态路由是下一个。
项目地址:/vllm-project/semantic-router
#vLLM #SemanticRouter #多模态路由 #SigLIP #跨语言推理
制作不易,如果这篇文章觉得对你有用,可否点个关注。给我个三连击:点赞、转发和在看。若可以再给我加个🌟,谢谢你看我的文章,我们下篇再见!
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-30,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号