204K Star 的 Superpowers 框架,把 AI 写代码从「快」变成了「可靠」 ,保姆级实战教程

204K Star 的 Superpowers 框架,把 AI 写代码从「快」变成了「可靠」 ,保姆级实战教程

码哥字节
发布于 2026-05-29 13:00:49
发布于 2026-05-29 13:00:49
你好,我是码哥,可以叫我靓仔。
用 Claude Code 写过超过 500 行代码的人,多半都遭遇过同一件事:
你描述一个需求,Claude 给你生成了一大段看起来很合理的代码。代码能跑,测试也写了几个,功能对了。但两周之后,你往同一个模块加功能,发现之前那段代码的假设是错的——没有测试覆盖那个边界条件,修起来比重写还难。
不是 Claude 写得烂。是你们两个从一开始就没有共识过"这段代码要对什么负责"。
这就是 Superpowers 要解决的问题。不是让 AI 更聪明,是给 AI 一套工程纪律。
截至 2026 年 5 月,这个由 Jesse Vincent(obra)维护的框架已经积累了 204K GitHub Stars、18.2K Forks,在 Anthropic 官方插件市场的安装量超过 68 万次,是 Claude Code 生态里增长最快的插件。v5.1.0 在 2026 年 4 月 30 日发布,仍在快速迭代。
它到底是什么?本质上是一个可组合的 Skill 执行器
大多数人第一次听说 Superpowers,以为是某种 Claude 的 fine-tune 版本,或者是一个专属的 Agent 框架。都不是。
Superpowers 的全部实现就是一套 SKILL.md 文件。 每个 SKILL.md 文件就是一套流程规范,用 Markdown 写成,任何人打开都能读懂。整个框架没有自己的运行时,不锁定模型,不依赖私有 API——它本质上是一套编码进文本的工程方法论。
当前版本包含 14 个核心技能,分三类:
开发流程类:brainstorming(需求澄清)、writing-plans(任务拆解)、executing-plans(计划执行)、subagent-driven-development(子 Agent 并行)、using-git-worktrees(工作区隔离)、finishing-a-development-branch(分支收尾)
质量保证类:test-driven-development(TDD 强制执行)、requesting-code-review(发起代码评审)、receiving-code-review(处理评审意见)、verification-before-completion(完成前验证)
调试与元技能类:systematic-debugging(系统化调试)、writing-skills(编写新 Skill)、using-superpowers(Superpowers 激活恢复)、dispatching-parallel-agents(并行 Agent 调度)
会话启动时,框架通过 Claude Code 的 hook 机制注入一个引导文档(小于 2000 tokens),告诉 Claude 开始任何任务前先读取相关 Skill。这个设计让整个框架极度轻量:它不锁定你用哪个模型,不需要自己的运行时,跨 Claude Code、Cursor、Gemini CLI、GitHub Copilot CLI、Codex CLI 都能工作。
这里有个设计取舍值得注意:2000 tokens 的引导注入,确实很节省上下文——但它带来了一个已知问题。子 Agent 启动时不会自动继承这个上下文注入,导致子 Agent 有时会跳过 TDD 这类约束直接开写。框架目前通过 SubagentStart hook 部分缓解这个问题,但 v5.1.0 里仍然是已知问题。遇到时手动触发 using-superpowers skill 可以把它拉回来。
框架完全透明,你可以修改任何 Skill 来适配自己团队的规范——这是刻意的设计决策,把工程文化编码成文件,而不是锁进平台。
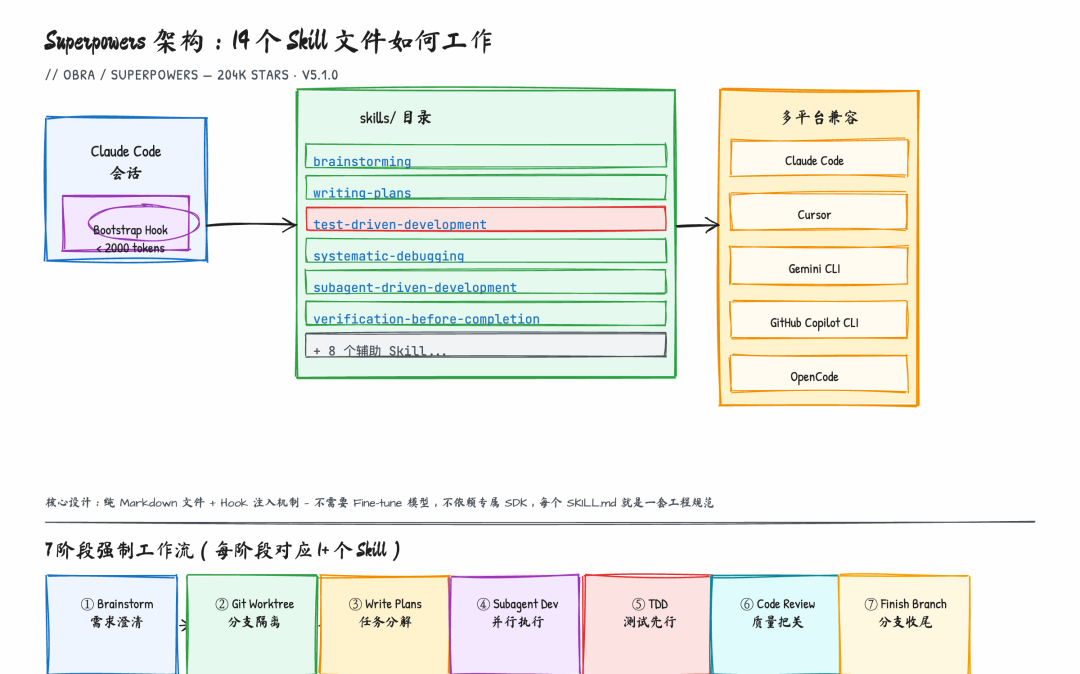
Superpowers 框架架构:14 个 Skill 文件 + Hook 注入机制
图:Superpowers 的架构本质——14 个可组合的 Markdown Skill 文件通过 Hook 注入到 Agent 会话,形成工程约束层
7 阶段工作流:从「能跑」到「可维护」
Superpowers 把软件开发的一次完整迭代拆成 7 个强制阶段。每个阶段对应一个或多个 Skill,框架要求不允许跳过。
阶段 1:Brainstorming(需求澄清)
这不是闲聊,是 Socratic 对话。Claude 会主动问:这个功能的边界在哪里?有哪些已有代码会受影响?你接受什么形式的输出?边界条件是什么?
大多数工程师觉得这一步啰嗦,想直接开写。但这一步的设计目的很明确:让 Claude 在写代码之前先暴露它对需求的假设。我用裸 Claude Code 踩过的坑,有 60% 源头都在这一步省掉了——需求没说清楚,Claude 就开始猜了,而它猜的方向往往会在你不知道的地方和别的模块打架。Brainstorming 就是把这些隐式假设在写代码之前逼出来,让你确认或纠正。
阶段 2:Git Worktree 隔离
在写任何代码之前,先建一个干净的 worktree 分支。这不是噱头,是防止 Claude 在主分支上做试验性修改污染你的工作区。生产环境里吃过"Claude 顺手改了三个文件然后功能坏了"这种亏的工程师,会明白这一步的价值。v5.1.0 对 worktree skill 做了重写,加入了环境检测和基于同意的工作区创建逻辑,比之前的版本更稳。
阶段 3:Writing Plans(任务分解)
把设计分解成 2-5 分钟的原子任务,每个任务有明确的文件路径、预期改动、验证步骤。这一步的输出是一份计划文档,你需要 review 并确认。
这里有个反直觉的建议:不要让 Claude 在写完计划之后立刻开始执行。新开一个会话再执行计划,防止写计划时累积的上下文污染执行阶段的判断。这是社区里很多重度用户总结出来的,框架文档本身也提到了。
阶段 4:Subagent-Driven Development(子 Agent 并行执行)
这是 Superpowers 架构里最关键的设计。每个原子任务派给一个全新的子 Agent,子 Agent 只知道自己这一个任务的上下文,执行完报告结果给协调 Agent。
背后的逻辑是:长时间运行的单一 Agent 上下文会"腐化"——随着对话轮数增加,早期假设会被忘记,新的错误会越来越难发现。新鲜子 Agent 的上下文是干净的,判断也是干净的。这是 Superpowers 最核心的工程假设,也是它和裸 Claude Code 在长周期开发上差距最大的地方。
阶段 5:TDD(测试驱动)
这是整个框架最"暴力"的一环。规则只有一条:没有失败的测试,就没有实现代码。不是"尽量先写测试",不是"写完再补测试",是字面意义上的——如果发现子 Agent 在没有失败测试的情况下写了实现代码,Superpowers 要求删掉那段代码,回到测试先行的状态。RED → GREEN → REFACTOR,循环不跳步。
阶段 6:Code Review(代码评审)
任务之间穿插代码评审,发现 critical 级别的问题会阻断后续任务。这里的"critical"有明确定义:逻辑错误、安全漏洞、与 spec 不符——不是风格问题。v5.1.0 对 code review 做了整合,去掉了命名 Agent 的方式,改为更简洁的自包含模板,减少了角色混乱的问题。
阶段 7:Branch Finishing(分支收尾)
给你四个选项:合并到主分支 / 创建 PR / 保留分支 / 丢弃分支。这一步强制你对这次迭代的结果做一个明确的决策,而不是"先放着"。
TDD 强制化的背后:AI 写代码为什么不加测试会出问题
这是很多人觉得「TDD 感觉没必要」的地方,我想多说几句,因为 AI 场景和人类写代码的场景有本质区别。
人类工程师跳过测试写代码,通常是偷懒,但他脑子里还存着"这段代码应该对什么负责"的隐式知识。他之后补测试的时候,大概率还记得那些边界条件。这是人类的记忆系统在发挥作用。
AI 写代码没有这个"隐式记忆"。 Claude 生成的代码是当前上下文的最优解。但"当前上下文"不等于"完整需求"。
测试是一种合约——测试逼着你在写实现之前,把"这段代码要保证什么"显式地写出来。这个合约用机器可以验证的方式存在于代码库里。没有这个合约,Claude 在两周后面对新需求时,不知道那个合约存在,它可能会完全合理地违反它。
我见过最典型的例子:一个负责订单状态流转的模块,用裸 Claude Code 写的,跑了三周没问题。然后加了一个退款逻辑,Claude 顺手重构了状态机,把一个边界状态合并了——因为在新的上下文里,那个状态"看起来多余"。那个状态是处理异常支付渠道的,生产上有 0.3% 的概率触发。没有测试覆盖,悄悄坏掉了,上线之后客服系统才报警。
这不是模型的 bug,是系统设计层面的架构隐患。上下文无记忆的 AI 在长周期迭代中,天然会侵蚀没有显式约束覆盖的代码区域。
有数据支撑这一点。chardet(Python 字符编码检测库)的维护者用 Superpowers 重写了 v7.0.0,跑完 2161 个测试文件、覆盖 99 种编码,最终性能提升 41 倍,准确率从 94.5% 提升到 96.8%。这个数字的来源不是 Superpowers 有什么神奇算法,而是 TDD 强制执行后,"每次代码变动都必须先有失败测试通过才能保留",意味着 Claude 可以大胆重构——因为回归测试会立刻捕获所有破坏。这是 TDD 在 AI 写代码场景下的核心价值:让激进优化变得安全。
Superpowers 把测试覆盖目标设在 85-95%,不是"有测试就行"。这个数字不是拍脑袋定的——低于 80% 的覆盖率,在第二次迭代时 regression 的概率会显著上升;高于 95% 的覆盖率,写测试的时间投入超过了收益。85-95% 是经验数值上的合理区间。
TDD 强制化是在 AI 写代码的场景里,对"上下文无记忆"这个根本问题的系统性解法。
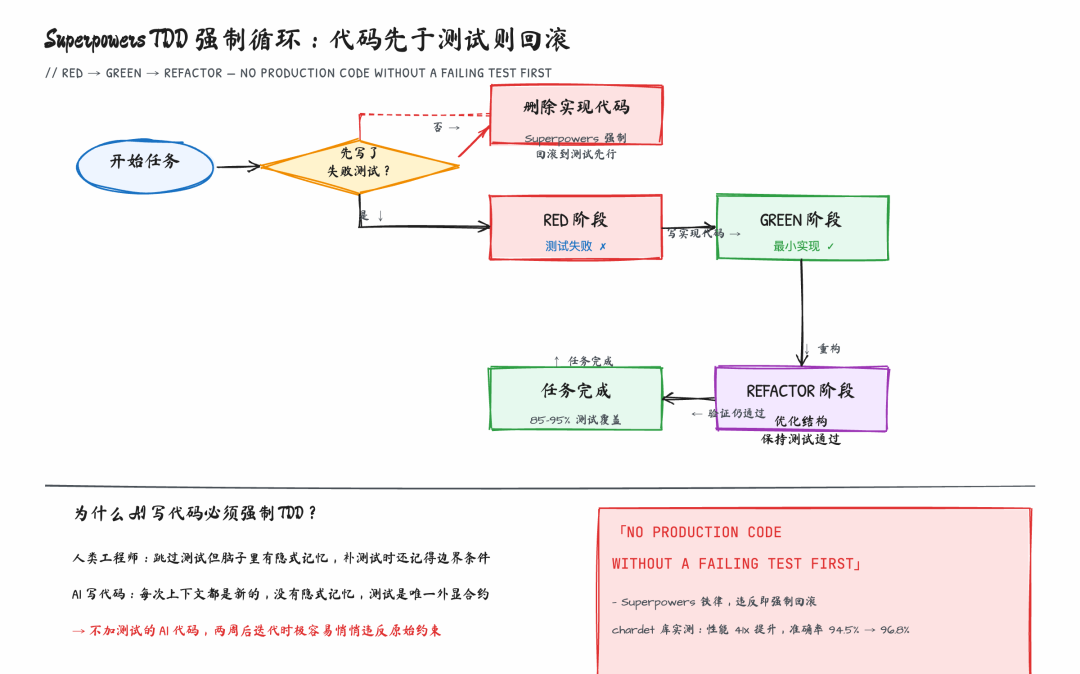
TDD 强制循环:RED-GREEN-REFACTOR 在 Superpowers 中的执行流程
图:Superpowers 强制 TDD 循环的执行逻辑——代码先于测试存在时,框架要求删除实现代码重来
30 分钟上手实战:从零跑完完整工作流
说了这么多原理,来一遍真实的操作过程。用一个简单的小需求:写一个 Python 函数,根据输入的月份和日期,返回对应的星座名称。这个需求够简单,但涵盖了边界条件处理、错误输入验证——Superpowers 工作流的每个环节都能完整展示。
第 0 步:安装
先在 Claude Code 里安装 Superpowers:
/plugin install superpowers@claude-plugins-official
这是官方 Anthropic 插件市场的安装命令。安装完成后重启 Claude Code,在新会话中输入 /help,能看到 Superpowers 命令列表则安装成功。
如果官方市场安装不了(网络问题),备选方案是社区市场:
/plugin marketplace add obra/superpowers-marketplace
/plugin install superpowers@superpowers-marketplace
第 1 步:触发 Brainstorming Skill
在 Claude Code 里输入:
/superpowers:brainstorming 我想写一个 Python 函数,输入月份和日期,返回对应的星座名称
Claude 不会立刻给你写代码。它会先问一系列澄清问题,类似这样:
“"在开始之前,我需要了解几件事:
- 输入格式是整数(1-12 月,1-31 日)还是字符串?
- 输入非法日期(比如 2 月 30 日)时应该怎么处理——抛出异常还是返回 None?
- 星座边界日期(比如 1 月 19 日 vs 1 月 20 日)是否需要精确到哪年的实际分界点,还是用固定日期?
- 返回值是中文星座名还是英文?是否需要同时返回两者?
- 这个函数会用在什么场景——单独调用还是作为 API 的一部分?"
这就是 Brainstorming 的核心价值:它把你的隐式假设逼出来。对这些问题回答后:
“你的回答: 整数输入,非法日期抛 ValueError,用固定边界日期,返回中文,单独函数就行
现在 Claude 有了清晰的合约。
第 2 步:生成计划
/superpowers:writing-plans
Claude 会把实现拆成原子任务:
任务 1(约 3 分钟):定义星座边界数据结构
文件:zodiac.py
内容:创建 ZODIAC_DATES 常量,包含 12 个星座的月日范围
验证:数据结构完整,覆盖全年 365 天无遗漏
任务 2(约 3 分钟):实现核心查找逻辑
文件:zodiac.py
内容:实现 get_zodiac(month: int, day: int) -> str 函数
验证:基本星座返回正确
任务 3(约 2 分钟):实现输入验证
文件:zodiac.py
内容:验证 month 1-12,day 1-31,无效输入 raise ValueError
验证:边界值测试通过
重点:在新会话里执行这份计划,不要在同一个会话里直接让 Claude 开始执行。打开新的 Claude Code 会话,把计划粘贴进去再开始。
第 3 步:TDD 执行——先写失败的测试
/superpowers:test-driven-development
Claude 的第一动作是写测试文件,不是实现代码:
# test_zodiac.py
import pytest
from zodiac import get_zodiac
class TestGetZodiac:
"""根据月日返回星座名称的函数测试"""
# 每个星座的典型日期
def test_aries(self):
assert get_zodiac(4, 1) == "白羊座"
def test_taurus(self):
assert get_zodiac(5, 1) == "金牛座"
def test_gemini(self):
assert get_zodiac(6, 1) == "双子座"
def test_cancer(self):
assert get_zodiac(7, 1) == "巨蟹座"
def test_leo(self):
assert get_zodiac(8, 1) == "狮子座"
def test_virgo(self):
assert get_zodiac(9, 1) == "处女座"
def test_libra(self):
assert get_zodiac(10, 1) == "天秤座"
def test_scorpio(self):
assert get_zodiac(11, 1) == "天蝎座"
def test_sagittarius(self):
assert get_zodiac(12, 1) == "射手座"
def test_capricorn(self):
assert get_zodiac(1, 1) == "摩羯座"
def test_aquarius(self):
assert get_zodiac(2, 1) == "水瓶座"
def test_pisces(self):
assert get_zodiac(3, 1) == "双鱼座"
# 边界日期测试(关键!)
def test_boundary_capricorn_to_aquarius(self):
"""1 月 19 日是摩羯,1 月 20 日是水瓶"""
assert get_zodiac(1, 19) == "摩羯座"
assert get_zodiac(1, 20) == "水瓶座"
def test_boundary_pisces_to_aries(self):
"""3 月 20 日是双鱼,3 月 21 日是白羊"""
assert get_zodiac(3, 20) == "双鱼座"
assert get_zodiac(3, 21) == "白羊座"
# 错误输入测试
def test_invalid_month_zero(self):
with pytest.raises(ValueError):
get_zodiac(0, 1)
def test_invalid_month_thirteen(self):
with pytest.raises(ValueError):
get_zodiac(13, 1)
def test_invalid_day_zero(self):
with pytest.raises(ValueError):
get_zodiac(1, 0)
def test_invalid_day_thirty_two(self):
with pytest.raises(ValueError):
get_zodiac(1, 32)
此时运行测试,全部失败(RED 状态)——因为 zodiac.py 根本不存在:
pytest test_zodiac.py -v
ERROR collecting test_zodiac.py
ModuleNotFoundError: No module named 'zodiac'
这是正确的状态。Superpowers 框架要求看到测试失败后,才允许开始写实现代码。
第 4 步:最小实现(GREEN 状态)
现在 Claude 写实现代码:
# zodiac.py
ZODIAC_DATES = [
(1, 20, "水瓶座"),
(2, 19, "双鱼座"),
(3, 21, "白羊座"),
(4, 20, "金牛座"),
(5, 21, "双子座"),
(6, 21, "巨蟹座"),
(7, 23, "狮子座"),
(8, 23, "处女座"),
(9, 23, "天秤座"),
(10, 23, "天蝎座"),
(11, 22, "射手座"),
(12, 22, "摩羯座"),
]
def get_zodiac(month: int, day: int) -> str:
"""
根据月份和日期返回对应星座名称。
Args:
month: 月份,整数 1-12
day: 日期,整数 1-31
Returns:
str: 中文星座名称
Raises:
ValueError: 当 month 或 day 超出有效范围时
"""
ifnot (1 <= month <= 12):
raise ValueError(f"月份必须在 1-12 之间,收到: {month}")
ifnot (1 <= day <= 31):
raise ValueError(f"日期必须在 1-31 之间,收到: {day}")
for cutoff_month, cutoff_day, zodiac_name in ZODIAC_DATES:
if month < cutoff_month or (month == cutoff_month and day < cutoff_day):
return zodiac_name
# 12 月 22 日及之后都是摩羯座
return"摩羯座"
再次运行测试:
pytest test_zodiac.py -v
test_zodiac.py::TestGetZodiac::test_aries PASSED
test_zodiac.py::TestGetZodiac::test_taurus PASSED
test_zodiac.py::TestGetZodiac::test_gemini PASSED
test_zodiac.py::TestGetZodiac::test_cancer PASSED
test_zodiac.py::TestGetZodiac::test_leo PASSED
test_zodiac.py::TestGetZodiac::test_virgo PASSED
test_zodiac.py::TestGetZodiac::test_libra PASSED
test_zodiac.py::TestGetZodiac::test_scorpio PASSED
test_zodiac.py::TestGetZodiac::test_sagittarius PASSED
test_zodiac.py::TestGetZodiac::test_capricorn PASSED
test_zodiac.py::TestGetZodiac::test_aquarius PASSED
test_zodiac.py::TestGetZodiac::test_pisces PASSED
test_zodiac.py::TestGetZodiac::test_boundary_capricorn_to_aquarius PASSED
test_zodiac.py::TestGetZodiac::test_boundary_pisces_to_aries PASSED
test_zodiac.py::TestGetZodiac::test_invalid_month_zero PASSED
test_zodiac.py::TestGetZodiac::test_invalid_month_thirteen PASSED
test_zodiac.py::TestGetZodiac::test_invalid_day_zero PASSED
test_zodiac.py::TestGetZodiac::test_invalid_day_thirty_two PASSED
18 passed in 0.12s
所有测试通过(GREEN 状态)。
第 5 步:Code Review
/superpowers:requesting-code-review
Claude 会按 critical/warning/info 三个级别对代码做评审。典型输出:
Critical: 无
Warning:
- day 验证只检查 1-31,但 2 月没有 29-31 日,4/6/9/11 月没有 31 日。
建议:如果业务不关心这个精度,可以在 docstring 里注明"不验证日期是否在该月真实存在"。
Info:
- ZODIAC_DATES 数据结构可以改用 namedtuple 提高可读性
- 函数在处理 12 月 22 日之后的边界依赖 "遍历完都不匹配则返回摩羯座" 的逻辑,建议加注释明确这个意图
没有 critical 问题,可以继续。Warning 里的日期精度问题是一个真实的边界条件,这里根据 Brainstorming 阶段的约定(用固定边界日期,不精确验证)选择接受,在 docstring 里加注明即可。
整个流程走下来大约 25-30 分钟。这个时间里你不只是得到了一个能跑的函数——你得到了一个有 18 个测试用例覆盖、清晰文档、通过 Code Review 的函数,以及一份记录了所有设计决策的对话历史。
这就是 Superpowers 的工作方式。
和裸用 Claude Code 的真实差距
说「有用」不够,得说清楚差在哪里,在什么量级上有差距。
裸 Claude Code 的典型问题模式:
第一次跑:90% 功能正常,测试覆盖 40-60%,代码风格因上下文而异。这个阶段感觉很爽。
第五次迭代:开始看到函数长度膨胀,边界条件处理不一致,某些模块和别的模块存在隐式假设耦合。这个阶段开始有点烦。
第十次迭代:遇到 regression bug 的概率显著上升。因为没有系统性测试,修一个问题可能破坏另一个你没意识到的地方。这个阶段开始让人头疼。
用 Superpowers 之后的差异:
任务颗粒度强制细化(2-5 分钟一个任务),这意味着每次子 Agent 出错,影响范围被限制在一个原子任务内,而不是蔓延到整个功能。这个设计让第三小时的代码质量接近第一小时——在裸 Claude Code 模式下,通常到第二小时中段质量就开始明显下滑。
测试覆盖目标 85-95%,不是"有测试就行"。chardet v7.0.0 的案例是迄今为止有记录的 Superpowers 最大规模实测:41 倍性能提升、准确率从 94.5% 提升到 96.8%,覆盖 2161 个测试文件、99 种编码。这不是统计噪音,是系统性 TDD 约束带来的可信结果。
但代价也是真实的:一个简单的 bug fix,套完整 7 阶段流程会明显比直接让 Claude 修慢。Superpowers 的设计取向是明确的——它是为"中大型功能开发"优化的,不是为"一行代码的快速修改"。评估是否值得用,最简单的判断标准是:这个改动如果出了问题,修复成本是否超过 30 分钟?是的话,走 Superpowers 流程值得。
和 GSD、gstack 的定位差异
Claude Code 生态里现在有三个主要的工作流框架,值得认真比一下定位,方便你选型——它们解决的根本上是三种不同的问题,不是同一个问题的三种解法。
Superpowers(204K stars):约束开发流程本身。核心假设是"AI 写的代码在没有测试约束的情况下,会随时间积累隐患"。框架的解法是:把 TDD、计划先行、子 Agent 隔离这些工程实践强制编码进每次开发流程,让 Claude 没有机会走捷径。适合需要测试覆盖和代码质量保证的功能开发,尤其是那些"三个月后还要维护"的代码。弱点是单一协调 Agent 在极长任务(超过一天的工作量)中仍然会遇到上下文限制,这个问题 GSD 处理得更好。
GSD(51K stars):约束执行环境。核心假设是"Agent 上下文会随工作时间增长而腐化,导致质量下滑"。框架的解法是 phase-based orchestration——把工作拆成原子任务,每个任务派一个新的 Claude 实例(新鲜 200K token 上下文)执行,协调 Agent 始终保持在上下文容量的 50% 以内,状态通过 Markdown 文件持久化。Pulumi 的数据显示,GSD 在 50+ 文件的大型项目上,可以把第三小时的代码质量维持在接近第一小时的水平。适合跨天的长任务、多个并行工作流、或者需要在中途 crash 后恢复的场景。弱点是相比 Superpowers,它对 TDD 的约束要弱一些——它更关注"任务能完成",不强制关注"测试覆盖率"。
gstack(71K stars):约束决策视角。核心假设是"单一 Agent 视角会有盲点,代码写出来了但可能方向本身就是错的"。框架的解法是 23 个角色(CEO、产品经理、QA 负责人、工程师、安全审计员……)让 Claude 以不同身份审视同一段代码,防止只有工程师视角的判断盲区。对需要产品和技术并行思考的独立开发者很有价值——做一个面向消费者的产品时,纯工程视角往往会忽略用户体验和商业逻辑的优先级。但"写代码"本身不是它的强项,它更像是一个决策审查工具,而不是开发流程工具。
选择思路:如果你的核心问题是"AI 写的代码缺少工程纪律,三个月后会成为技术债",选 Superpowers。如果你的问题是"长任务(超过 4 小时)中途 Claude 开始犯错,上下文腐化",选 GSD。如果你的问题是"代码写出来了但不确定方向对不对,需要从 PM 和用户视角再看一遍",试试 gstack。三个框架定位基本不重叠,用错了框架解决不了问题。
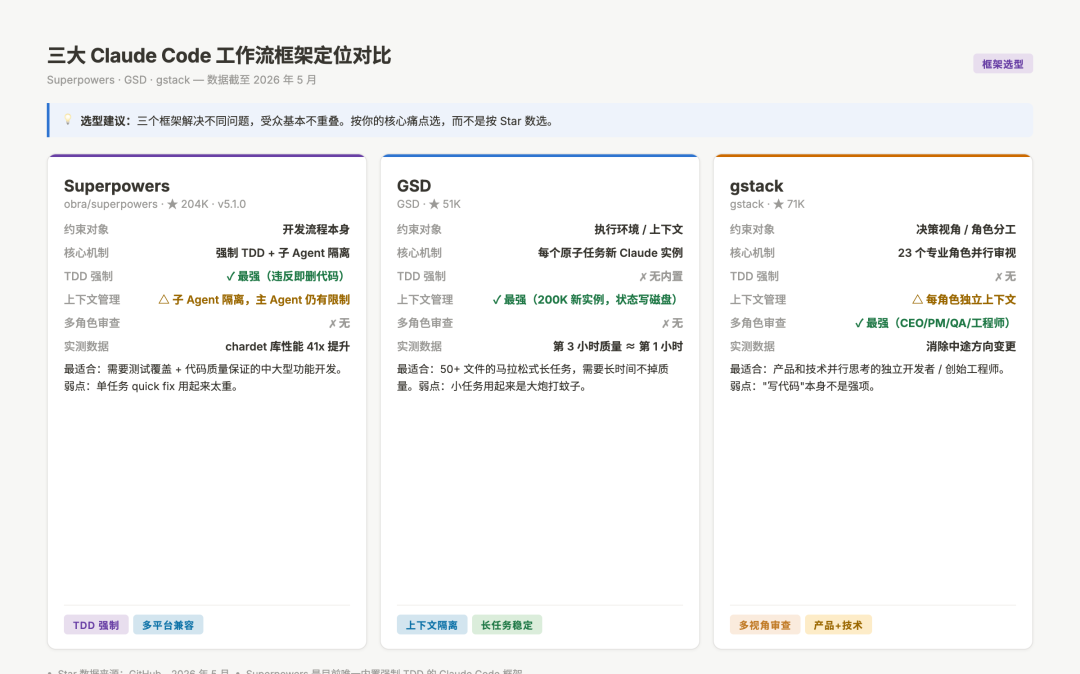
三大 Claude Code 工作流框架定位对比:Superpowers vs GSD vs gstack
图:三个主流 Claude Code 工作流框架的核心定位对比,数据截至 2026 年 5 月
常见问题
Q:Superpowers 会不会让 Claude Code 变得很慢?
会增加时间,但这个时间花得值不值取决于任务规模。对于一个需要 3-5 个迭代周期、后续还要维护的功能模块,整个 Superpowers 流程通常比直接开写慢 20-30%——前期 Brainstorming 和 Writing Plans 大约多花 10-20 分钟,但产出的代码有 85%+ 测试覆盖,后续遇到需求变更时的修改成本大幅降低。对于单行 bug fix 或 quick prototype(不打算长期维护),直接用裸 Claude Code 更合适。一个实用的判断标准:这个改动如果出了问题,修复成本超过 30 分钟吗?是的话,走 Superpowers 流程值得。
Q:SKILL.md 文件能自定义吗?
完全可以。每个 SKILL.md 就是普通的 Markdown 文件,可以修改 TDD 的覆盖率要求、调整 Brainstorming 的问题列表、加入团队特有的代码规范检查(比如加一条"所有函数必须有 type hints")。框架把工程文化编码成文件,而不是锁进平台。v5.1.0 还加入了 writing-skills 这个元技能,帮你规范地写出新的 Skill——这个设计很有意思,框架本身的扩展也要走 TDD 和 Code Review 流程,保证新 Skill 的质量。
Q:只用 Claude Code,不用 Cursor / Copilot,还有必要装吗?
有。Superpowers 最核心的价值——TDD 强制、子 Agent 任务隔离、Brainstorming 前置——和你用哪个 IDE 无关,和 AI 写代码时如何防止隐式假设积累直接相关。这是方法论层面的问题,不是工具兼容性问题。Superpowers 同时支持 Claude Code、Cursor、Gemini CLI、Codex CLI、GitHub Copilot CLI,同一套 Skill 文件在这些工具里都能工作。
Q:子 Agent 跳过 TDD 的问题解决了吗?
截至 v5.1.0 仍是已知问题,部分缓解但未完全解决。问题根源是子 Agent 启动时不会自动继承主会话注入的 Superpowers 引导文档,导致它有时不知道 TDD 的约束存在。框架在 SubagentStart hook 方向上做了部分缓解,但没有完全解决。遇到子 Agent 跳过了测试直接写实现的情况,手动触发一次 using-superpowers Skill 可以把它拉回来——这个 Skill 的作用就是重新激活工程约束。
Q:这个框架在 Windows 上能用吗?
能。Superpowers 的执行层是 Claude Code,平台兼容性由 Claude Code 本身保证。SKILL.md 文件本身是纯文本,没有 OS 依赖。框架在 macOS、Linux、Windows(WSL 和原生)上均有社区报告的成功使用案例。
Q:安装之后 Claude 的上下文消耗会增加多少?
引导注入大约 2000 tokens,相当于 Claude 每次对话会多消耗约 1-2% 的上下文。对于 200K token 窗口的 Claude,这个消耗可以忽略不计。框架设计的出发点之一就是极度轻量——2000 tokens 的引导是刻意控制的,不是技术限制导致的。
总结
说白了,Superpowers 解决的不是「AI 能不能写代码」的问题,而是「AI 写的代码能不能在三个月后还可以维护」的问题。前者现在几乎所有工具都能做到,后者没有几个人认真对待过。
我用它三个月之后的判断:对于超过 200 行的功能模块,不加 TDD 约束的 AI 生成代码,在第二个月就会开始累积隐患,第三个月开始让人头疼。这不是玄学,是上下文无记忆的 AI 系统在长周期迭代中的必然结果。
chardet 41 倍性能提升的数字是有记录的,不是营销话术。下篇打算写 Subagent 的上下文隔离设计——不只是 Superpowers,而是从底层理解为什么多 Agent 架构在今天这个阶段比单个大 context 更可靠。
感兴趣关注一下,不然算法不一定推给你。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-27,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号