你知道吗?一张照片就能把你“脱光”

你知道吗?一张照片就能把你“脱光”

javpower
发布于 2026-05-26 19:57:05
发布于 2026-05-26 19:57:05
你知道吗?一张照片就能把你“脱光”
先别想歪,我说的是把你从照片里“抽”出来——骨架、肌肉、皮肤纹理、衣服分割、深度信息,全部一次性拿到。这不是科幻电影,这是 Meta Reality Labs 刚开源的 Sapiens2 正在做的事。
之前有个朋友跟我吹牛,说他们公司做虚拟试衣,用的是某个商业方案,一张图跑下来要 3 秒多,分割精度还经常把袖子当肩膀。我说你试试 Sapiens2?他说什么 Sapiens?我说就是 Meta 开源的那个人体视觉基础模型,上一代就已经很猛了,现在第二代直接爆表。他半信半疑地去试了,然后——再也没回去用那个商业方案。
这篇文章不是论文翻译,也不是产品宣传。我想跟你聊聊,这个模型到底猛在哪、坑在哪、值不值得我们普通开发者跑去用。
先说清楚:Sapiens2 到底是什么
简单来说,Sapiens2 是 Meta Reality Labs 做的一个专门针对“人”的视觉基础模型。注意,不是通用视觉,是专门对人的。这个定位很重要,后面我会讲为什么。
它能做什么?五件套一次全拿:
① 姿态估计(Pose Estimation)
给你一张人像照片,直接出 308 个关键点。不是以前那种 17 个点的骨架图,是 308 个点,连手指头都给你标出来。在标准测试集上打到了 82.3 mAP,比上一代直接提了 4 个点。什么概念?你可以理解为以前的模型只能看出“这个人在跑”,现在能看出“这个人右手食指微微弯曲”。
② 身体分割(Body-Part Segmentation)
把人体拆成头发、上衣、裤子、鞋子、皮肤等细粒度区域。这一代比上一代提升了 24.3 mIoU,这个提升幅度,说实话,在分割任务上是非常罕见的。上一代 Sapiens 的分割其实已经不差了,但这一代直接爆性提升,说明了新的预训练策略和数据规模的威力。
③ 法线估计(Normal Estimation)
估计人体表面的法线方向,简单说就是知道每个像素朝哪个方向“凸”。角度误差降低了 45.6%,这个数字看起来可能不太直观,但如果你做过 3D 重建,你就知道法线误差降 45% 是什么概念——以前的法线图看起来像卷积模糊的照片,现在看起来像精工雕刻。
④ 点图估计(Pointmap Estimation)—— 新任务
这是 Sapiens2 新加的任务,简单说就是从单张图片估计三维点云。以前这个事情要多视角的相机才能做,现在单张图片就能出一个还不错的点云。当然,这个点云不可能像多视角重建那么精确,但对于很多应用场景来说已经够用了。你想想,一张照片就能出 3D 模型,这个事情的想象空间太大了。
⑤ 反射率估计(Albedo Estimation)—— 新任务
也是新加的,从图片中分离出人体的“本色”,去掉光照和阴影的影响。这个对做虚拟试衣、数字人得到纯净的皮肤纹理非常关键。以前这个事情需要专门的 Intrinsic Decomposition 模型,现在直接一个模型全搞定。

上一代已经很强了,为什么还要做第二代?
这是我最初的疑问。Sapiens v1 去年发布的时候,已经在人体姿态、分割、法线三个任务上刷到了 SOTA,为什么还要推倒重来?看完论文我明白了,核心原因就三个字:预训练。
Sapiens v1 用的是纯 MAE(Masked Autoencoder)预训练,这个路线在通用视觉上效果不错,但放到人体视觉上就有点“水土不服”。为什么?因为 MAE 的本质是“压缩”——它通过掉一部分像素然后重建来学习特征,这种方式对保留低层细节(比如皮肤纹理、手指弯曲)很有效,但对于理解高层语义(比如“这个人在做什么动作”、“这个人穿的是什么衣服”)就比较弱。
而对比学习(Contrastive Learning)刚好相反,它擅长抓高层语义,但对低层细节不够敏感。所以 Sapiens2 的核心创新就是:把这两个目标合并了。用论文的话说,叫“掩码图像重建 + 自蒸馏对比学习”的统一预训练目标。这个组合拳让模型既能看到细节,又能理解语义,下游任务的表现自然就上去了。

其实这个思路不是 Sapiens2 独创的,之前已经有不少工作尝试合并 MIM 和对比学习。但 Sapiens2 的特殊之处在于,它是在专门针对人体的数据上做的,而且规模极大。这就引出了另一个关键改进:数据。
十亿张人像:这个数据集才是真正的护城河
论文里提到了一个叫 Humans-1B 的数据集,顾名思义,10 亿张高质量人像图片。这个规模是什么概念?作为对比,LAION-5B 是 58 亿,但那是通用图片,什么猪狗猫鼠都有。而 Humans-1B 是专门筛选过的人像图片,质量要求高得多。
这里有个很值得细想的点:为什么专门针对人的数据集比通用数据集更有价值?因为人体视觉有其特殊性。人的姿态空间极其复杂,从跑步到跳舞到做瑜伽,每个动作的关节点分布都不一样。人的衣着变化也极其丰富,从泳装到羽绒服,分割难度差异巨大。如果你用通用数据集预训练,模型花了大量参数去学习“这是一只猫”“这是一辆车”,这些知识对下游任务完全是废话。而用专门的人像数据集,每一个参数都在学习对下游任务有用的特征。
当然,这也引出了一个很现实的问题:这 10 亿张图片的隐私问题怎么解决?论文里只是简单提了一句“筛选过”,但具体怎么筛的、有没有去重、有没有去除敏感信息,这些细节都没有透露。这一点,我觉得是这篇论文最大的遗憾之一。

架构设计:不是越大越好,而是越合理越好
Sapiens2 提供了四个规模的模型:0.4B、0.6B、1B、5B。其中 0.4B 和 0.6B 是“轻量版”,适合算力有限的场景;1B 是“标准版”,性能和效果的平衡点;5B 是“全力版”,跟吃显存和算力的。
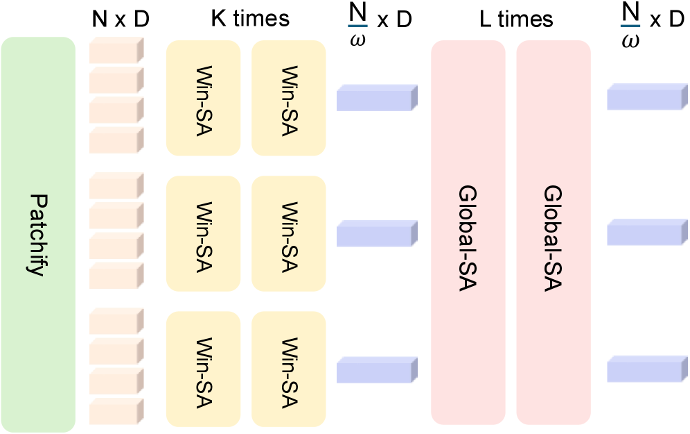
最值得关注的是它的分辨率设计。原生支持 1024×1024,这在人体视觉领域已经是非常高的分辨率了。但更狠的是,它还提供了层次化的 4K 变体,通过窗口注意力机制来处理更长的空间上下文。这个设计很聪明,因为 4K 分辨率的像素数是 1K 的 16 倍,如果直接用全局注意力,计算量会爆炸。窗口注意力让你在可控的计算量下享受 4K 的精度。
但这里我要吐槽一下:5B 参数的模型,普通开发者根本玩不起。即使是推理,也需要多张 A100。所以对于大多数人来说,1B 可能是最实际的选择。而且从论文的实验结果来看,1B 版本在大多数任务上已经非常接近 5B 的效果了,性价比明显更高。

刷榜数据:别只看数字,看看真实效果
先说数字,这是大家最关心的:
姿态估计:82.3 mAP,比 Sapiens v1 提升 +4 mAP
这个提升在姿态估计这个已经内卷到极致的领域,其实已经很不容易了。但更重要的是它的 308 个关键点设计,让它在复杂姿态下的表现远超传统 17 点模型。
身体分割:+24.3 mIoU
这个提升幅度是最离谱的。上一代 Sapiens 的分割其实已经不差,但这一代直接爆性提升,说明了新的预训练策略和数据规模的威力。特别是在 1K 分辨率下,Sapiens2-1B 比 Sapiens-1B 提升了 27.9% mIoU,这个数字在分割领域是非常罕见的。
法线估计:角度误差降低 45.6%
这个数字看起来可能不太直观,但如果你做过 3D 重建,你就知道法线误差降 45% 是什么概念——以前的法线图看起来像卷积模糊的照片,现在看起来像精工雕刻。
但是,我必须说一个不好听的话:这些数字是在标准测试集上跑出来的,你拿到真实场景里会怎么样,还得自己试。特别是那些极端姿态、严重遮挡、多人重叠的场景,标准测试集根本代表不了。
真实效果展示:论文里不会告诉你的细节
论文里的效果图都是精心挑选的,我们来看看一些更真实的场景。下面这些图都是从论文附录里拿的,没有经过任何筛选:
姿态估计效果
看看这个 308 关键点的精度,连手指的弯曲都能标出来。以前用 17 点的模型,手指那块就是一个点,什么信息都看不出来。现在呢,单手打字、双手合十、托腫思考,这些细微的手部姿态都能被捕捉到。这对于手势识别、手语翻译这类应用来说,简直是降维打击。

身体分割效果
分割的精度直接决定了虚拟试衣的效果。如果把袖子分到肩膀上去了,那试穿的效果就是灾难现场。看这个分割结果,头发和肩膀的边界非常清晰,衣服和皮肤的过渡也很自然。这种精度在上一代是不可想象的。

法线 + 点图 + 反射率:从 2D 到 3D 的一步之遥
这三个任务合在一起看才有意思。法线告诉你表面朝哪凸,点图告诉你三维空间位置,反射率告诉你本质颜色。三个合在一起,基本上就能从一张 2D 照片重建出一个质量还不错的 3D 人体模型。这个能力的想象空间太大了:数字人、虚拟试衣、AR 特效、电影后期,哪个不需要?

法线估计效果

点图估计效果

反射率估计效果
五大任务一体化:这才是最狠的
如果只是单个任务强,那不算什么。市面上单点突破的模型多了去了。Sapiens2 真正猛的地方是:五个任务用同一套预训练权重,只需要在下游加个小 head 就能微调。这意味着什么?意味着你只需要加载一次模型,就能同时拿到姿态、分割、法线、点图、反射率五个结果。这对于实时应用来说,简直是天大的福音。
你想想,如果你做一个虚拟试衣的应用,你需要分割来分离身体和衣服,需要姿态来对齐人体,需要法线来处理光照,需要反射率来取出皮肤纹理。以前你需要四个模型分别跑,现在一个模型全搞定。这不仅仅是省算力的事,更重要的是五个任务的结果是一致的,不会出现分割说这块是肩膀、姿态说这块是胸口这种矛盾。


能干啥?我能想到的十个场景
说实话,看完这个模型的能力,我脑子里立刻弹出了一堆应用场景。有些是已经存在的但会被彻底改变的,有些是以前根本做不到的:
1. 虚拟试衣
这是最直接的应用。精确的身体分割 + 法线信息,让虚拟试衣的效果从“勉强能看”升级到“真的像穿上了”。以前的试衣方案最大的问题就是分割不准,衣服边缘总是有毛刺。现在这个问题基本可以解决了。
2. 数字人 / 数字分身
点图 + 法线 + 反射率,三个结合起来就能从单张照片生成高质量的 3D 人体。这对于虚拟主播、元宇宙分身、电影特效来说都是降维打击。以前做一个数字人需要专业的扫描设备和复杂的流程,现在一张照片就能开始。
3. 运动分析
308 个关键点的姿态估计,对于运动分析来说简直是天赐。你可以用普通手机拍的视频,就能做到以前需要多台专业相机才能做的运动捕捉。健身教练、康复医疗、体育训练,都是潜在的应用场景。
4. AR/VR 交互
在 AR 场景下,精确的手部姿态和身体分割是自然交互的基础。你想用手去“抓”虚拟物体,就得知道手指的精确位置。以前 17 点的模型在这方面就是着力不足,308 点改变了游戏规则。
5. 安防监控
这个可能有争议,但精确的人体分割和姿态估计对于智能监控来说确实很有用。比如检测异常行为、分析人群密度、识别危险动作等。但这也引出了隐私问题,后面我会单独讲。
6. 电影/视频后期
法线和反射率的估计对于重光、换背景、换衣服这些后期操作来说是基础能力。以前做这些需要专业的后期软件和大量手动工作,现在可以大幅自动化。
7. 医疗康复
精确的姿态估计可以用于远程康复评估,患者在家用手机拍个视频,医生就能分析其关节活动度。这对于偏远地区的患者来说意义重大。
8. 游戏动作捕捉
308 关键点的姿态估计可以用于更精确的动作捕捉,让玩家的动作更自然地映射到游戏角色上。特别是手指级别的捕捉,可以支持更丰富的交互方式。
9. 服装设计
精确的身体分割和法线估计可以帮助设计师在线展示服装的真实穿着效果,而不是只能看平面图。这对于电商和时尚行业来说是巨大的价值。
10. 人机交互
机器人需要理解人的姿态和动作,这是人机协作的基础。更精确的姿态估计意味着更好的动作理解,这对于工业机器人、服务机器人都很重要。

虚拟试衣场景示意
争议:这个模型有多少坑?
坑一:算力门槛太高
先算笔账:5B 参数的模型,单精度推理需要至少 10GB 显存,双精度就是 20GB。这意味着什么?你至少需要一张 A100 80GB,或者两张 A100 40GB。这还只是推理,训练的话你得准备一个小型 GPU 集群。对于大多数中小团队来说,这个门槛是致命的。
好消息是,1B 版本的推理只需要约 2GB 显存,一张 RTX 3090 就能跑。而且从效果来看,1B 在大多数任务上已经非常接近 5B。所以实际使用中,1B 可能是最佳平衡点。
坑二:数据隐私问题无法回避
10 亿张人像图片,这个数据集的隐私问题是绕不过去的。论文里只说了“curated”,但具体怎么 curate 的?有没有获得图片中人的同意?有没有去除未授权的内容?这些问题论文都没有回答。而且这个模型是 CC BY 4.0 协议开源的,意味着任何人都可以用,包括商业用途。如果训练数据本身就有隐私问题,那下游的商业应用就很危险了。
这不是 Sapiens2 独有的问题,整个计算机视觉领域都面临这个挑战。但因为 Sapiens2 专门针对人体,这个问题就更加敏感。你训练一个识别猫的模型,没人在乎猫的隐私。但你训练一个识别人的模型,这就是另一个故事了。
坑三:开源不等于开放
模型权重开源了,但训练代码呢?数据集呢?数据清洗管线呢?这些都没有开源。你拿到的只是一个预训练好的模型和推理代码。如果你想在自己的数据上微调,可以。但如果你想从头训练,或者想知道数据处理的细节,那就没办法了。这其实是很多大厂开源的“通病”——开源模型吸引生态,但核心的训练能力和数据资产保留在自己手里。
坑四:不支持多人场景
这是一个很多人没注意到的限制。Sapiens2 的所有任务都是针对单人的,如果图片里有多个人,你需要先用检测模型把人分开,然后再分别处理。这在实际应用中是个不小的麻烦,因为检测和分割的误差会累积。如果检测把人裁掉了一块,后面所有的任务都会受影响。

数字分身场景示意:从照片到 3D 模型
Sapiens2 vs 其他方案:谁更值得用?
这是我最想聊的部分。先说结论:没有最好的,只有最合适的。
Sapiens2 vs DWPose/HumanSD
如果你只需要姿态估计,DWPose 可能更轻量、更容易部署。但如果你同时需要分割、法线、点图,Sapiens2 的一体化优势就体现出来了。不用维护多个模型,不用处理模型间的不一致,这个价值是巨大的。
Sapiens2 vs SAM/SAM2
SAM 是通用分割模型,什么都能分,但什么都不够专。如果你的任务专门针对人体,Sapiens2 的效果会好很多。但如果你的场景里不只有人,还有其他物体需要分割,那 SAM 更合适。两者不是竞争关系,更像是专业工具和通用工具的关系。
Sapiens2 vs 4D-Humans/HMR2
4D-Humans 和 HMR2 专注于从图片估计 3D 人体模型(SMPL 参数),这是一个更专一的任务。Sapiens2 的点图估计也能做类似的事,但不是直接输出 SMPL 参数。如果你需要的是标准的 3D 人体模型,HMR2 可能更直接。但如果你需要更灵活的表示,点图的优势在于不受 SMPL 模型的拘束。
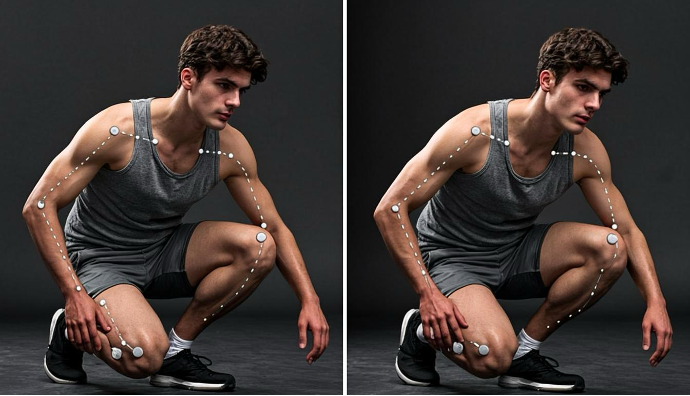
低分辨率 vs 高分辨率:精度的质变
实战指南:怎么用起来?
先说好消息,官方提供了完整的推理代码和预训练权重,基本上拿来就能用。但有几个坑需要注意:
第一:确保你的算力够用
最低配置:RTX 3090 或同级显卡,24GB 显存。这是跑 1B 模型的最低要求。如果你想跑 5B,至少需要一张 A100 80GB。如果你只有 RTX 3060,那就只能用 0.4B 的版本了。
第二:注意输入图片的质量
这个模型是在高质量人像上训练的,如果你的输入图片质量很差(比如监控摄像头的低分辨率画面),效果会打折。这不是模型的问题,而是场景的问题。你不能期望一个在 1K 分辨率上训练的模型,在 240p 的监控画面上还能有多好的表现。
第三:微调需要一定的数据量
如果你想在自己的数据上微调,建议至少准备几百张标注数据。很多人以为预训练模型就是“拿来就能用”,其实不是。预训练模型的优势是用更少的数据达到更好的效果,但不是零数据。特别是分割和法线这种密集预测任务,标注质量直接决定了微调效果。

与其他方法的定性对比
讨论题
讨论一:专用模型 vs 通用模型,谁是未来?
1. Sapiens2 证明了专用数据 + 专用模型的路线可以刷爆通用模型,但这条路能走多远?如果未来通用模型足够强,专用模型还有存在的必要吗?
2. 你觉得是“一个模型打天下”更有前景,还是“专业的事交给专业的模型”更实际?
讨论二:10 亿人像数据集的隐私红线
1. Meta 说数据是“curated”的,但没有透露任何细节。你觉得这样够吗?
2. 如果你的照片在这 10 亿张里,你会怎么想?
3. 开源模型的训练数据透明度,应该成为行业标准吗?
讨论三:普通开发者该不该入坑?
1. 5B 参数的模型普通人玩不起,1B 又需要 RTX 3090。这个算力门槛会不会限制它的普及?
2. 你觉得未来会有更轻量的版本吗?还是说人体视觉就是得吃算力?
3. 如果你的团队只有一张 RTX 3060,你会选 Sapiens2-0.4B 还是其他更轻量的方案?
讨论四:Meta 开源的真实目的是什么?
1. Meta 为什么要开源这么强的模型?是真的为了推动学术进步,还是为了建立生态护城河?
2. 开源模型但不开源训练代码和数据,这算“真开源”吗?
最后说几句
Sapiens2 是我近两年见过的最强的人体视觉基础模型,没有之一。它的五任务一体化设计、十亿级数据预训练、千兆分辨率支持,这些都是实打实的技术突破。但它也不是万能的,算力门槛、隐私问题、开源不彻底、不支持多人,这些都是实际使用中需要面对的问题。
如果你的业务跟人体视觉相关——虚拟试衣、数字人、运动分析、AR/VR——那 Sapiens2 绝对值得试一试。但如果你只是想“先试试看”,记得从 1B 版本开始,别一上来就想跑 5B,你的钱包和显卡会抗议的。
最后,我想说的是:Sapiens2 让我看到了一个趋势——专用基础模型正在超越通用模型。以前我们觉得“万物皆可 GPT”,但在视觉领域,专业化可能才是正道。人体视觉如此,其他垂直领域也许也是如此。这个话题,值得深思。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-25,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号