Agent Builder:AI Agent如何管理上下文

Agent Builder:AI Agent如何管理上下文

点火三周
发布于 2026-05-26 19:31:28
发布于 2026-05-26 19:31:28
Agent Builder:AI Agent如何管理上下文
Agent Builder 现已正式 GA。您可以立即通过 Elastic Cloud 免费试用 开始使用,并查看 Agent Builder 的文档。
每个构建代理的开发者都必须回答一个问题:代理应该知道什么,以及何时知道?通常的起点很简单:写一个系统提示、连接几个工具,代理就能工作了。但随着范围扩大,你需要添加更多指令、更多数据源和更多工具,运行时间也越来越长。最终,上下文窗口会被填满,准确率下降,Token 成本攀升。管理上下文已是一个首要问题。这篇文章将分享我们如何在代理中构建上下文处理能力,让代理能自行决定该提取什么、该总结什么、该丢弃什么,以及记忆如何在步骤之间传递。
在 9.4 版本中,Agent Builder 把上下文问题变成了代理自己的问题,而不是你的问题。Skills(技能)提供了可复用的指令,按需加载,所以只有当前任务需要的指令才会进入上下文。大型结果集会被放入对话上下文存储区,而不是直接塞进提示词中。对于长时间运行的任务,上下文会被选择性地压缩,避免代理偏离主题。对话运行时,Token 数量和轮次都会被监控。此外,Connectors(连接器)负责访问企业数据现有的存放位置。
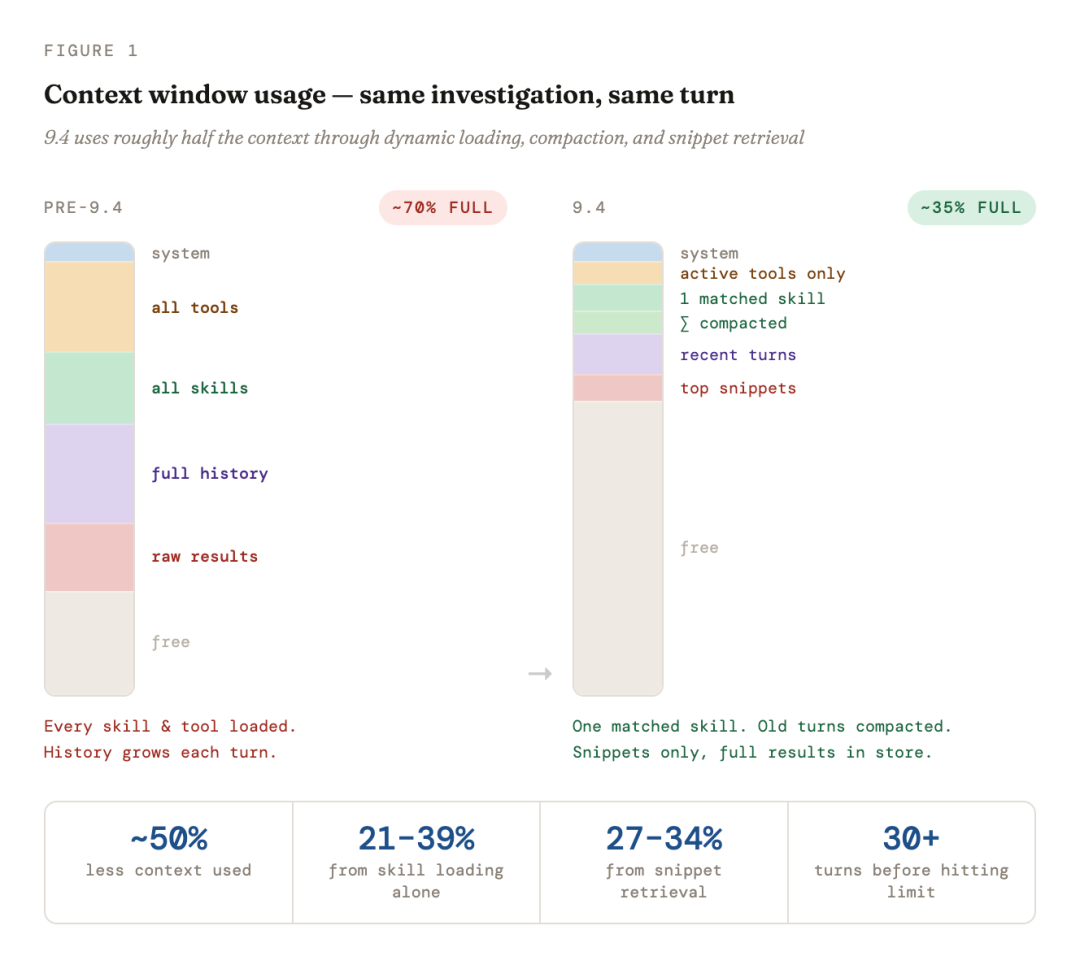
所有这一切的目标都是相同的:在你需要的时候,加载你需要的上下文。在我们的内部测试中,这种做法将 Token 成本降低了最多 40%,而且代理的上下文在原本会退化的大型数据集上依然保持可靠。
让代理了解你所知道的信息
三个上下文问题反复出现:管理臃肿的提示词、执行复杂操作,以及控制企业数据源。
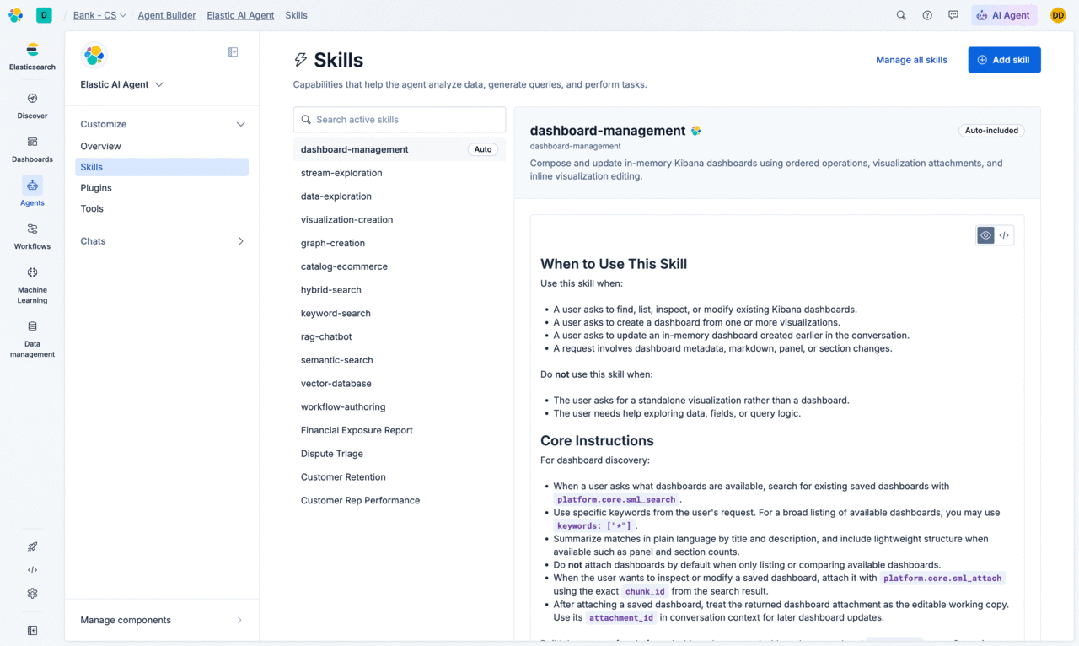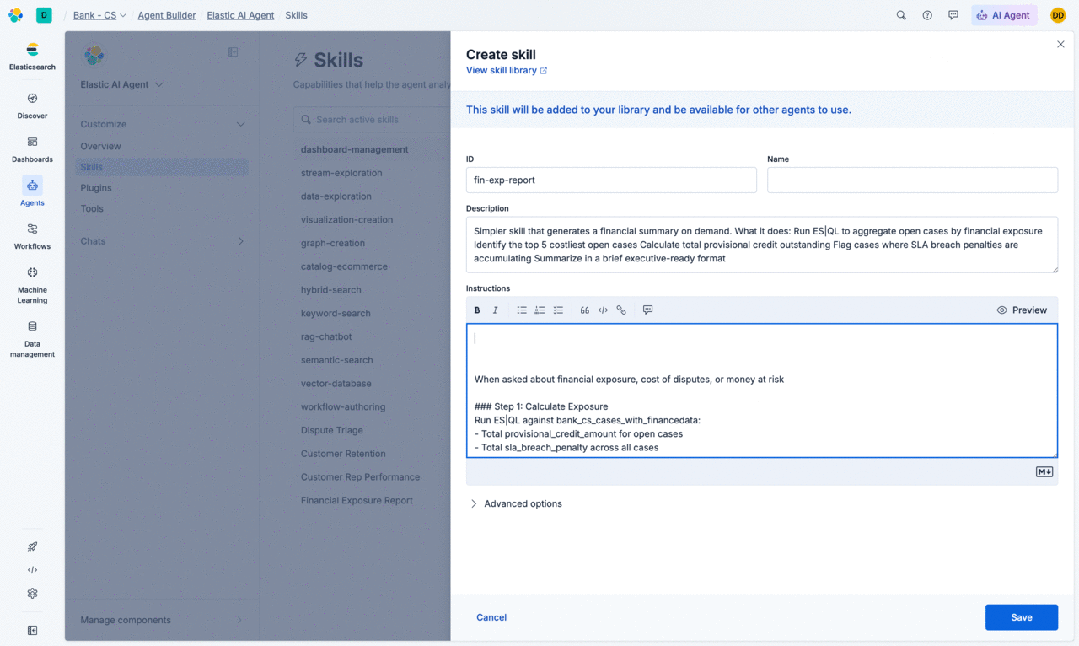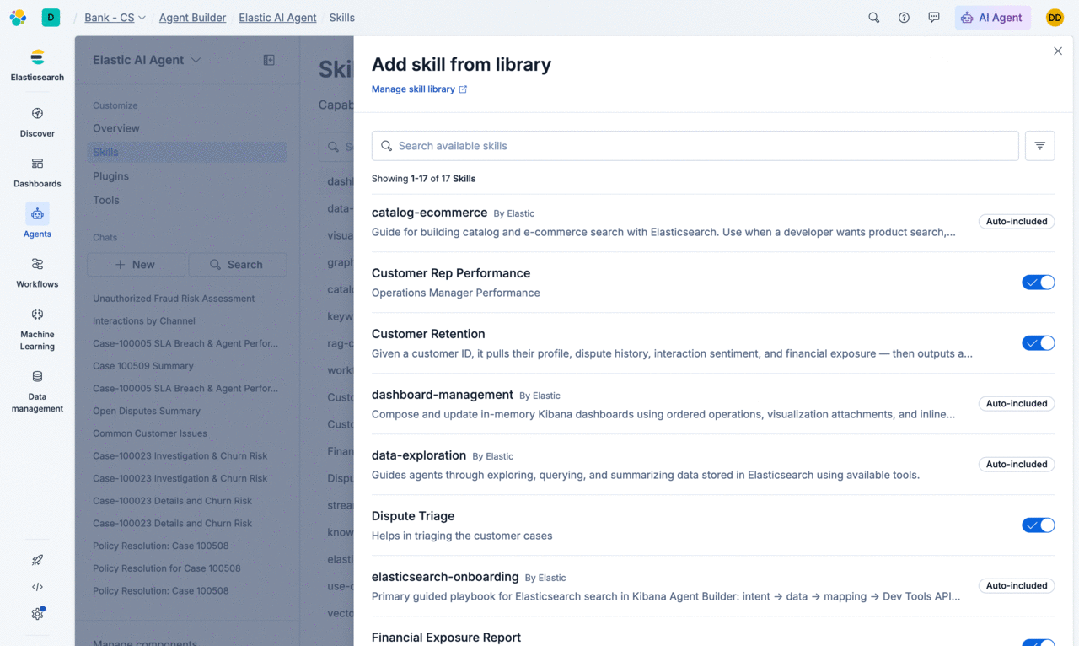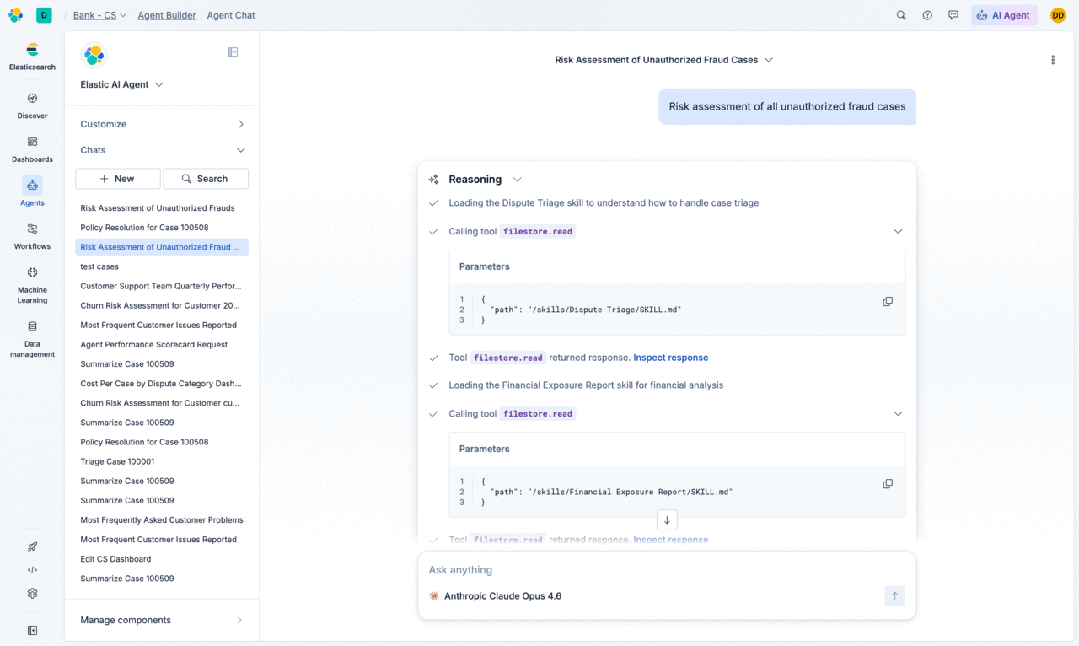
首先,提示词变得臃肿,因为所有指令都必须塞在里面。Skills(技能)通过按需加载并使用更少的输入 Token 来解决这个问题。Skills 提供了结构化的描述,说明代理在特定任务中应该如何运作和行动。Agent Builder 自带了一些用于常见数据分析模式的技能,但真正的价值在于用户也可以构建自定义技能。安全团队可以将他们的分类处理手册编码为一个技能;SRE 团队可以描述他们希望如何进行根本原因分析;开发者可以编码他们的 API 设计规范和错误处理模式。Skills 可以在不同代理之间复用和共享,这意味着某个团队部署中有效的模式不需要被下一个团队重新发明。
在实际使用中,这看起来就像:团队领导定义一个“总结此事件”的技能,其中包含他们关心的流程、他们组织使用的严重等级分类,以及他们的运行手册期望的输出格式。团队中的任何人都可以通过在聊天输入框中输入并从自动补全中选择来调用它。Skills 遵循 Agent Skills 开放格式,因此你可以从共享库中拉取,自己编写,或者使用你选择的代理来编写技能。
alt
在内部测试中,我们发现将指令从代理提示词中移除并放入动态加载的技能中后,测试数据集上的输入 Token 使用量减少了 21% 到 39%。架构上的关键改进在于:技能及其关联的工具只有在代理需要时才会被加载。所有其他技能只保留轻量级的存根(只有名称和描述),几乎不消耗上下文。
alt
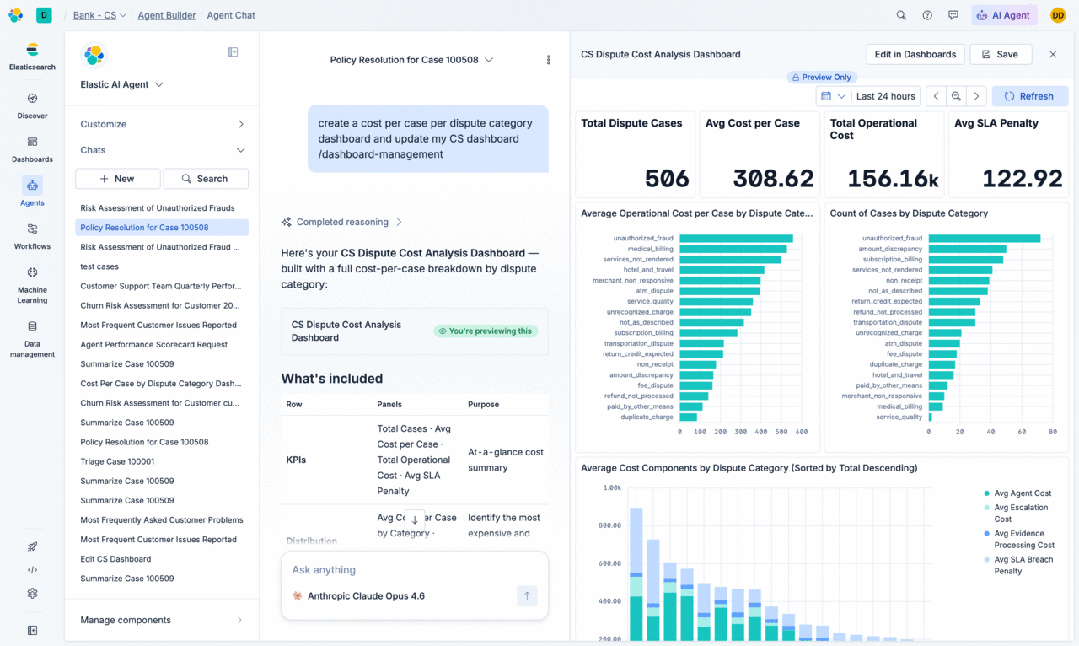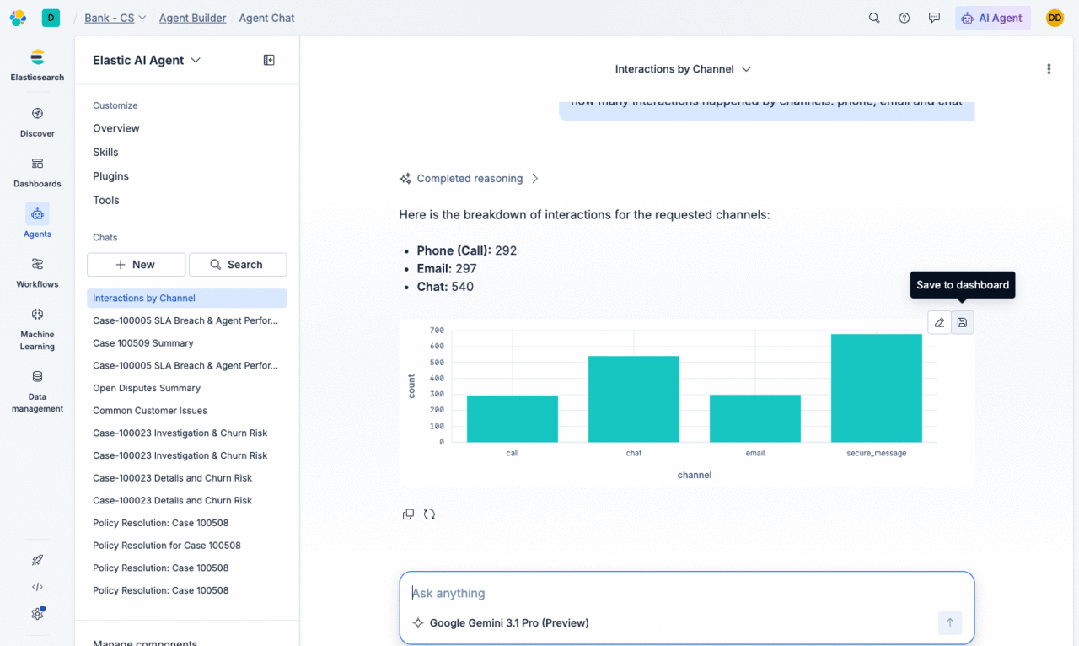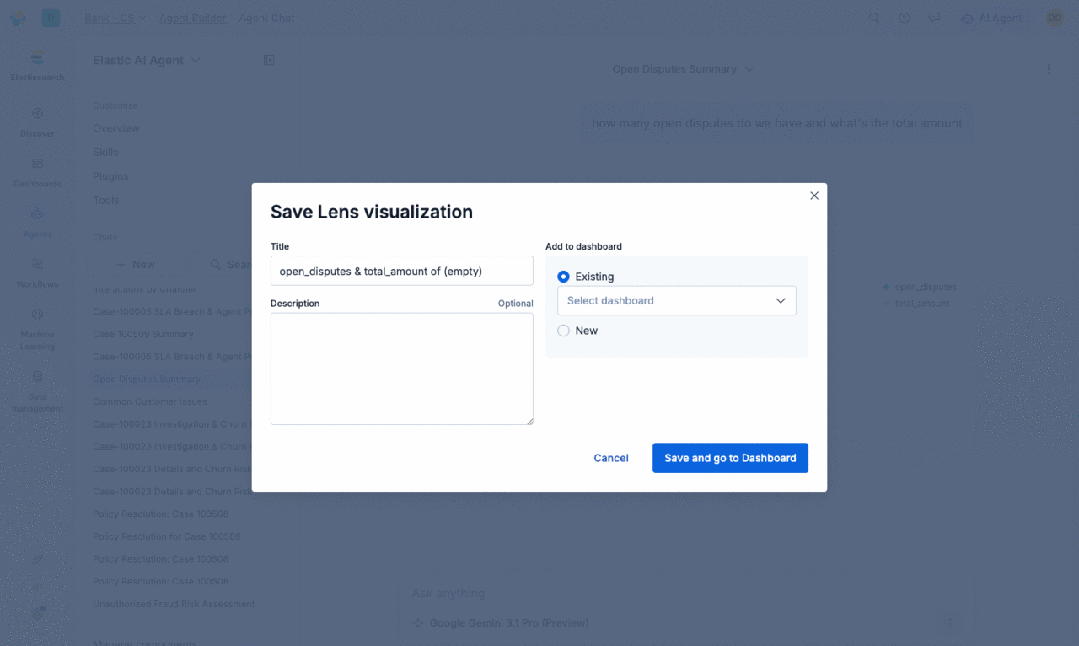
与你的数据聊天,并对其采取行动(仪表板、工作流、查询等): 代理任务不会长时间保持简单。Agent Builder 现在能够感知 Kibana 中的对象。通过代理化的仪表板创建,用户可以用自然语言描述他们想看到的内容,代理就会生成包含面板、可视化、查询以及其他所有必需元素的仪表板。用户可以通过对话进行细化:“按地区拆分”、“添加一个过去 7 天的过滤器”、“将柱状图改为折线图”。
仪表板、告警和规则也可以作为输入。一旦仪表板存在,它就可以从代理的上下文中被检索出来。这解锁了代理“行动”的一面。一旦一个仪表板或告警处于上下文中,代理可以修改它、扩展它,或创建新的。代理可以推理数据展示的内容,建议后续分析,或者基于它看到的内容修改仪表板。这是一个反馈循环:用户描述意图,代理生成一个可视化工件,然后用户和代理可以共同对这个工件进行推理。
alt
对于业务分析师和运营团队而言,这缩短了从“我对数据有疑问”到“我有一个可以与团队分享的仪表板”之间的差距,将数小时的手动工作缩减为几分钟的对话。
最后,使用企业数据作为上下文会带来你未曾要求的治理需求。Connectors(连接器)为存在于 Elastic 之外的数据提供了闭环。我们为 Google Drive、Salesforce 和 Slack 等数据源预构建了基于 OAuth 的连接器。这里的设计原则值得指出:数据留在源头。代理通过连接器以用户自己的权限来搜索数据,权限会得到执行。代理不会为了能够回答问题而在新位置积累企业数据的副本。
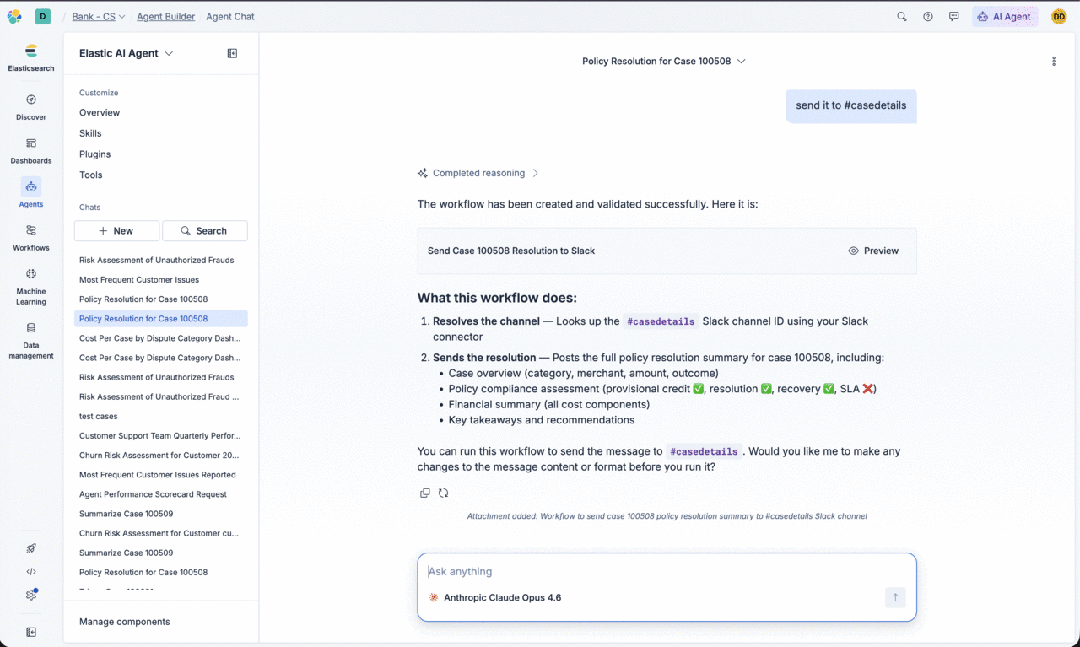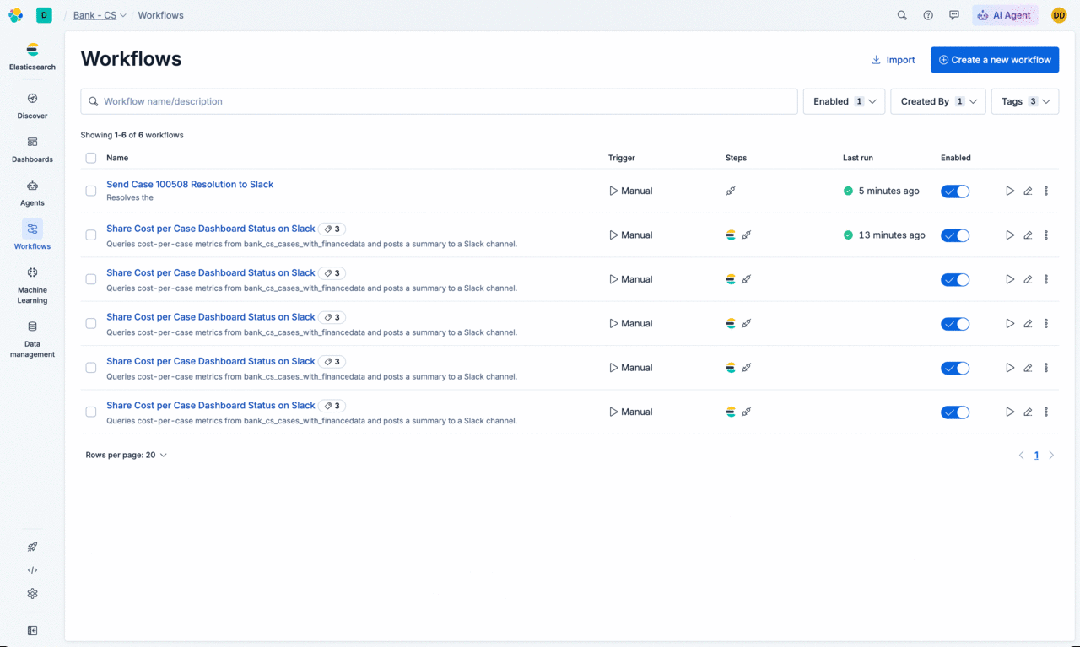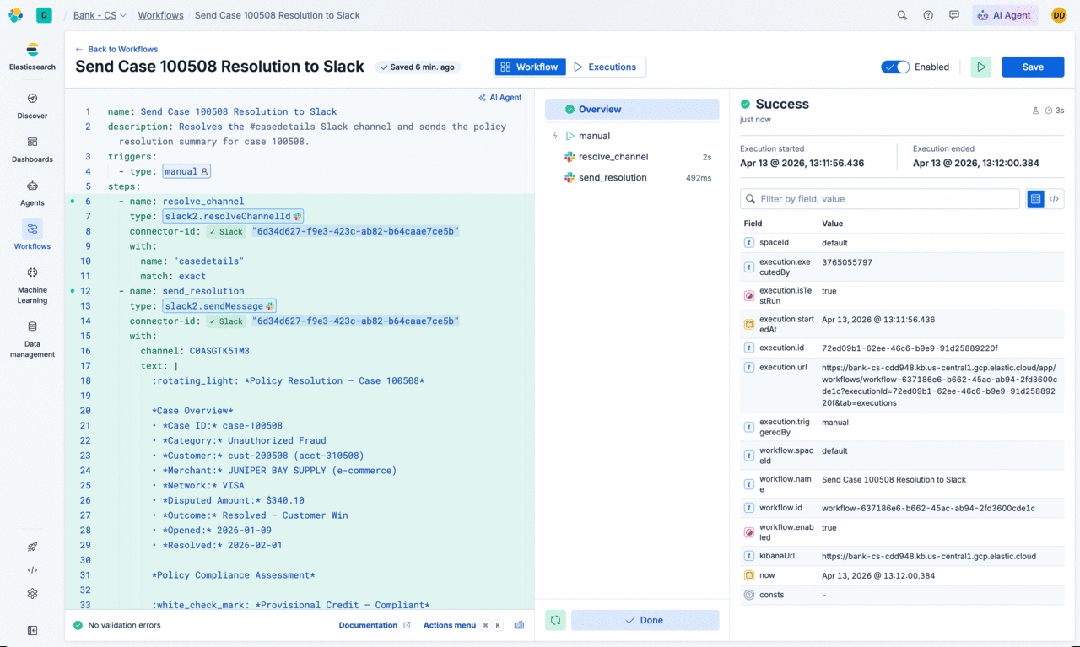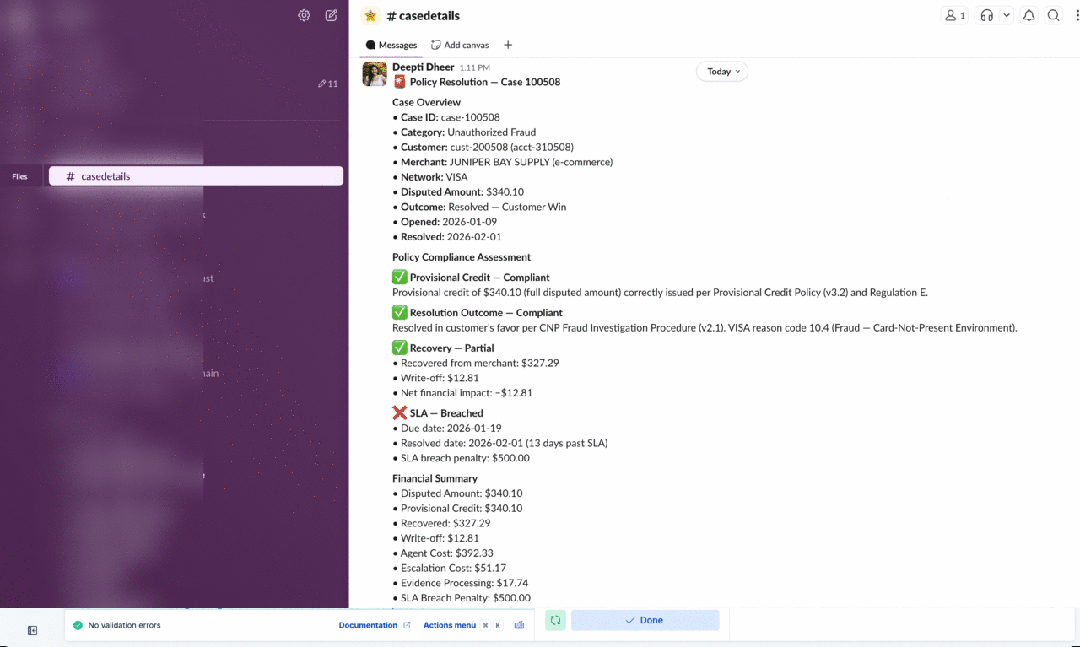
alt
这一点比看起来更重要。企业数据治理不仅仅是一个合规复选框;它是一项承载性的基础设施,大多数团队直到出问题时才会注意到它。当代理开始绕过它,在向量存储和上下文窗口中积累副本时,你就悄悄制造了一类新的数据蔓延,而你的安全团队并未批准,审计日志也不会捕获。连接器方法通过约束消除了这种风险:如果数据从未移动,它就不会出现在不该出现的地方。用户的权限伴随着每一次查询,因为查询是发往源头,而不是缓存的副本。这样你就能获得对企业数据真正有用的代理。
确保代理不会超出上下文窗口
给代理过多上下文会带来新问题。一个安全分析师在调查复杂威胁时,可能会拉取几十条告警,跨多个索引进行关联,并与代理来回进行二三十轮交互。在某个时刻,你会超过上下文窗口的容量,从而降低模型响应的质量。问题是每次检索调用都会增加用户请求的延迟,并推高基础设施成本,而一次用户交互可能触发几十次这样的调用。
我们为检索结果构建了上下文存储。 当代理从索引中检索数据时,结果可能变得很大并挤占上下文窗口。我们引入了一个临时存储,将查询结果保存在内存中的“文件存储”中,只在需要时才会将结果拉入活动上下文。这使得对话可以扩展并处理多个相关数据集,而不会撑爆上下文。我们还对检索结果本身进行了优化,应用了 top snippets(顶部分片)检索,结果显示 Token 使用量减少了 27% 到 34%。
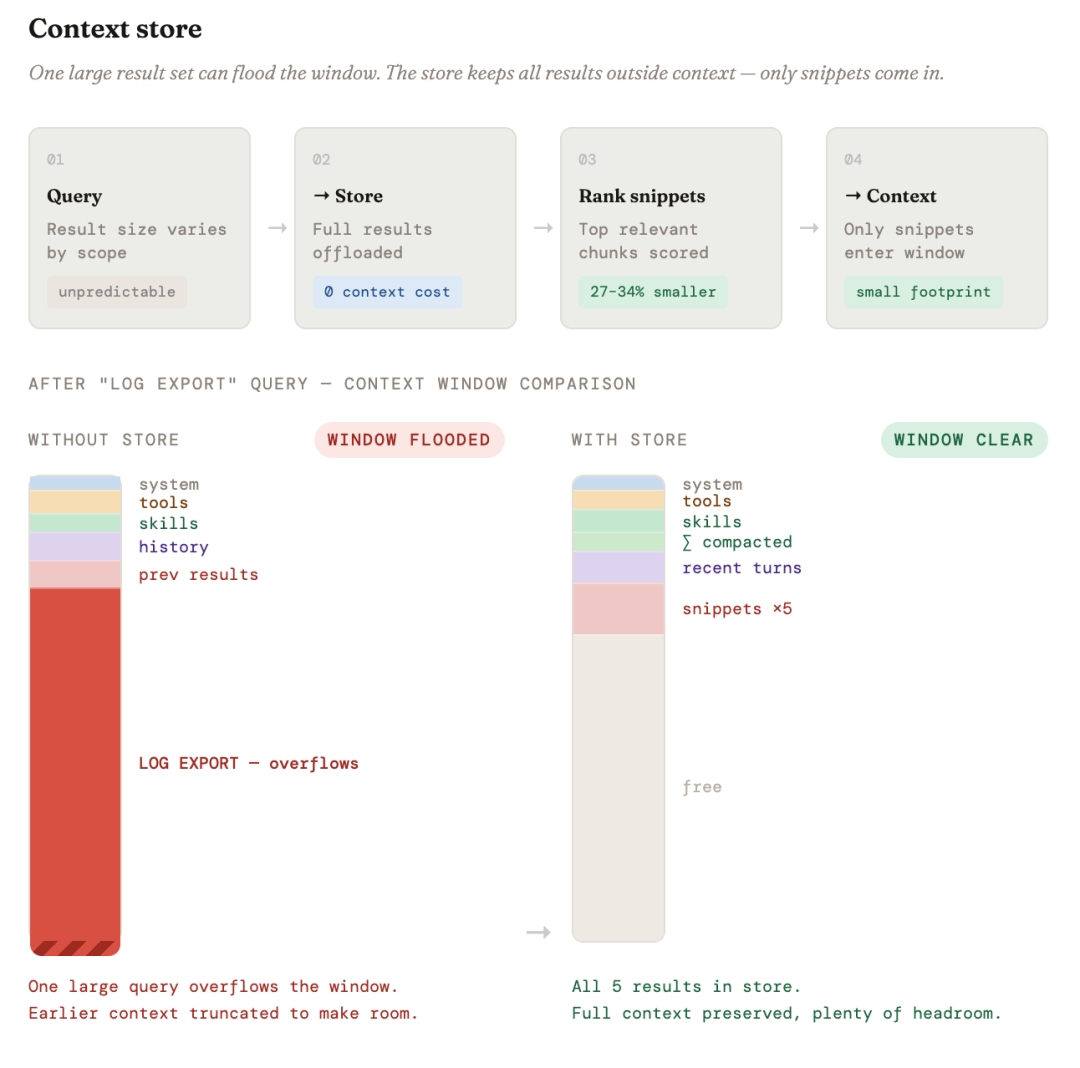
alt
我们还为较长的交互引入了智能上下文压缩:随着对话进行,代理会管理哪些内容留在活动上下文中,哪些被压缩成一个摘要(可在需要时检索)。这不是简单的截断,而是选择性压缩,保留最有可能对下一轮交互重要的信息。
这使代理能够处理更大的结果集、更复杂的查询以及更长的对话,而 Token 成本不会随着每一轮交互线性增长。借助上下文压缩,即使对话达到 30 轮或更多,上下文窗口依然能保持在限制内,而不是迅速膨胀到最大值。
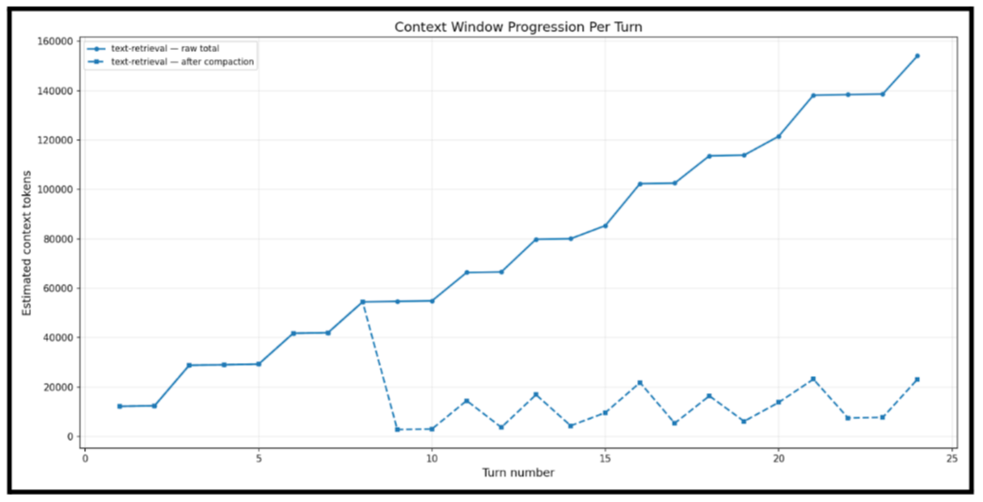
alt
对于进行多步调查或总结的团队而言,这就决定了代理在第 30 轮时依然保持连贯,还是在第 12 轮就开始自相矛盾。
监控: 在 9.4 中,我们还推出了代理监控功能,用于追踪 Token 使用量。API 可用于监控对话轮次和工具调用。这之所以重要,是因为代理并非静态不变。它们的行为会根据收到的上下文和调用的工具而变化,如果没有对这些模式的可见性,成本和性能的优化就只能靠猜测。
代理消费模型
为了支持这些新功能,我们引入了一个代理定价模型,直接与用户从代理中获得的价值以及他们的扩展方式对齐。Agent Builder 的使用量将通过“执行次数”(Executions)来衡量。每月前 1,000 次执行免费(适用于 Elasticsearch 项目),前 10,000 次免费(适用于 Elastic Security 和 Observability 项目)。
一次 Agent Builder 执行代表一次完整的代理交互回合。在大多数情况下,发送一条聊天消息并收到代理的成功回复算作一次执行。对于需要大量处理的消息,将根据所需的输入 Token 总数(每 50,000 个输入 Token 为一组)计算为多次执行。例如,一个需要 130,000 个输入 Token 的深度调查任务将被计为 3 次执行。这种模型确保你的消费与代理交付的价值保持一致,并且随着代理实现更高的上下文效率,成本效益会更好。
我们将在代理领域走向何方
能够优化运营数据上下文的代理,需要与我们在 搜索相关性 上多年来投入的 上下文工程 同等程度的精心设计。在正确的时间、以正确的详细程度将正确的信息呈现在模型面前,是一个新的检索问题。这些能力是构建更可靠、更具可扩展性、更经济高效的代理的基础。
现在就从 Elastic Cloud 免费试用 开始吧,查看 文档。对于现有客户,Agent Builder 可在 Cloud Serverless 以及 Elastic Cloud Hosted 和自管理版的企业层级中使用。
本文内容对您有多大帮助?
😔 没有帮助 不帮助
😐 有些帮助 有些帮助
😁 非常有帮助 非常有帮助
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-26,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号