LiTENexus:AIDD 的物理基座

LiTENexus:AIDD 的物理基座

MindDance
发布于 2026-05-20 13:38:13
发布于 2026-05-20 13:38:13
一个分子在模型里看起来活性很好,离真正成为候选药物还差很远。它要能溶解,要能穿过膜,要能在体内保持合适的暴露量,要避开关键毒性,还要在正确的靶点上表现出足够选择性。过去几年,AI 分子模型进步很快,但很多模型仍然像是在学习分子数据里的统计纹路:见过类似骨架,预测就准一些;换到天然产物、环肽、复杂代谢性质,表现就容易打折。
浙江大学药学院、上海创新研究院、澳门理工大学等团队在5月15日发表于ChemRxiv的大作,试图把问题往前推一步:不要只让 AI 记住分子的 SMILES、二维图或三维构象,而是让模型在底层就感知势能面、部分电荷、偶极矩、极化效应这些量子化学信息。团队把这个思路称为量子化学信息注入,并以此构建了一个端到端虚拟药物发现系统 LiTENexus。

它的核心不是单一模型,而是一套闭环:先用 LiTEN-Base 学到物理表征,再向下分化出构象优化的 LiTEN-FF、微观量子性质预测的 LiTEN-Micro、ADMET 预测的 LiTEN-ADMET,以及蛋白-配体虚拟筛选的 LiTENCLIP。论文给出的结果很密集:微观性质预测接近高阶量子化学计算,速度提升 2–3 个数量级;ADMET 多任务预测在多个基准上刷新表现;在天然产物、环肽等分布外化学空间也保持优势;虚拟筛选在 DUD-E 和 LIT-PCBA 上取得很高的前 1% 富集能力。
它提出的问题很直接:AI 制药下一步的关键,可能不只是把模型做大,而是让模型更像在理解分子为什么会这样。
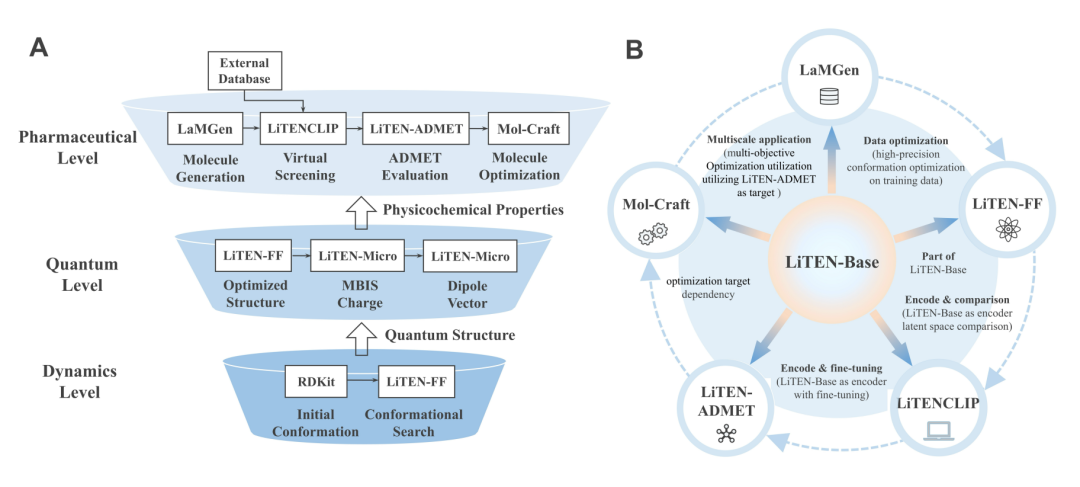
LiTENexus 的多尺度框架:系统以 LiTEN-Base 为物理表征引擎,把分子动力学、量子化学微观性质、ADMET 预测、虚拟筛选和多目标优化连接到同一条药物发现流程中。
LiTENexus 的多尺度框架:系统以 LiTEN-Base 为物理表征引擎,把分子动力学、量子化学微观性质、ADMET 预测、虚拟筛选和多目标优化连接到同一条药物发现流程中。
为什么 AI 分子模型需要重新靠近物理
AI 辅助药物发现最早让人兴奋的地方,是它能在巨大的化学空间里快速筛选、生成、排序。一个模型可以吃进去数百万甚至上亿个分子,用 SMILES 当语言,用分子图当结构,用三维坐标当几何,最后输出活性、溶解度、毒性或结合能力。这个方向确实带来了很多工具,也把传统计算化学和药物化学中的许多步骤变快了。
但分子不是普通文本,也不是普通图像。一个药物分子在体内的行为,往往取决于很细的物理量:某个原子附近电荷如何分布,分子整体偶极矩如何变化,一个可旋转键跨过能垒需要多少能量,亲水基团在脂质膜前是否能被分子内部氢键暂时藏起来。很多性质不是二维拓扑图上能直接读出来的。
过去的分子表征大致经历了几条路线。第一类是一维序列模型,把 SMILES 当成类似自然语言的字符串来学习,例如 MolFormer 这类化学语言模型。第二类是二维图模型,把原子看成节点、化学键看成边,通过图神经网络或图 Transformer 学习局部结构和官能团信息,例如 MoleBERT、KPGT 等。第三类是三维几何模型,引入原子坐标、距离、角度和等变网络,让模型能看到分子的空间形状,Uni-Mol 就是这个方向里的代表。
这些路线都很重要,但它们共同面对一个难题:当测试分子和训练数据长得不一样时,模型到底学到的是化学规律,还是训练集中的相似性捷径?在常规药物样分子上表现不错的模型,遇到天然产物、宏环、环肽、带有复杂手性中心和多重非共价相互作用的分子时,常常会出现泛化不稳。原因不难理解:二维骨架相似,不代表电子结构相似;三维构象相似,也不代表极化、偶极、局部反应性相似。
量子化学本来可以回答这些问题。密度泛函理论等方法能够计算分子的能量、电荷、偶极矩、轨道相关性质,为药物分子的溶解、膜通透、代谢稳定性和毒性提供更底层的解释。问题在于,它太贵。高精度 DFT 计算不适合直接用于百万级、十亿级化合物库的高通量筛选。于是领域里出现了一些折中做法:把 DFT 算出来的量子描述符作为额外标签,或者用电子密度图替代离散原子类型,提升模型的数据效率和物理感知能力。
LiTENexus 所挑战的,正是这种折中方式的边界。论文认为,如果量子信息只是训练标签或附加描述符,它仍然停留在浅层标注;真正想提高外推能力,就要把物理规律放进模型内部,让表征空间本身受量子化学约束。换句话说,不是让 AI 在药物发现流程末端补一个量子描述符,而是从一开始就让模型在量子化学的坐标系里看分子。
研究设计
LiTENexus 的结构可以理解成三层。最底层是量子与动力学层,它关心构象、能量、电荷、偶极矩这些微观物理量;中间是分子性质层,它把微观特征转化为 ADMET、溶解度、膜通透、代谢清除率等药物研发指标;最上层是药物发现应用层,包括从头分子生成、虚拟筛选和多目标优化。
这套系统的核心叫 LiTEN-Base。论文把它称作一个物理信息神经算子。它并不只是接收分子图,然后给出一个 embedding,而是把分子看成局部几何场中的连续物理分布,通过多极展开、张量收缩和等变表征去重建分子的势能面与电子环境。
在模型结构上,LiTEN-Base 用两个模块分别处理局部和远程相互作用。多体相互作用算子负责刻画 5 Å 范围内密集的局部化学环境,比如键角、扭转、局部空间拓扑;双体相互作用算子把感受野扩展到约 10 Å,用来捕捉偶极-偶极作用、诱导极化、色散等长程非共价相互作用。这个设计很关键,因为药物分子的行为常常不是某个单原子或单官能团决定的,而是局部结构和全局电场共同作用的结果。
训练策略也分阶段。模型先在 nablaDFT 这样的大规模量子化学数据上学习势能面和力,再引入 SPICE 数据集中的复杂生物相关分子构象,激活非局部电子环境建模能力。训练完成后,LiTEN-Base 根据应用场景分化成两个基础模块:LiTEN-FF 用于构象优化和力场相关任务,LiTEN-Micro 用于预测 MBIS 部分电荷、分子偶极矩等微观量子性质。
在这个底座之上,团队继续搭建 LiTEN-ADMET 和 LiTENCLIP。前者把量子化学表征迁移到 77 个 ADMET 相关终点上,后者把小分子的量子流形嵌入和蛋白口袋表征对齐,用于结构基础虚拟筛选。这样一来,LiTENexus 从分子生成、构象优化、虚拟筛选、ADMET 评估到多目标优化,形成了一条相对完整的计算闭环。
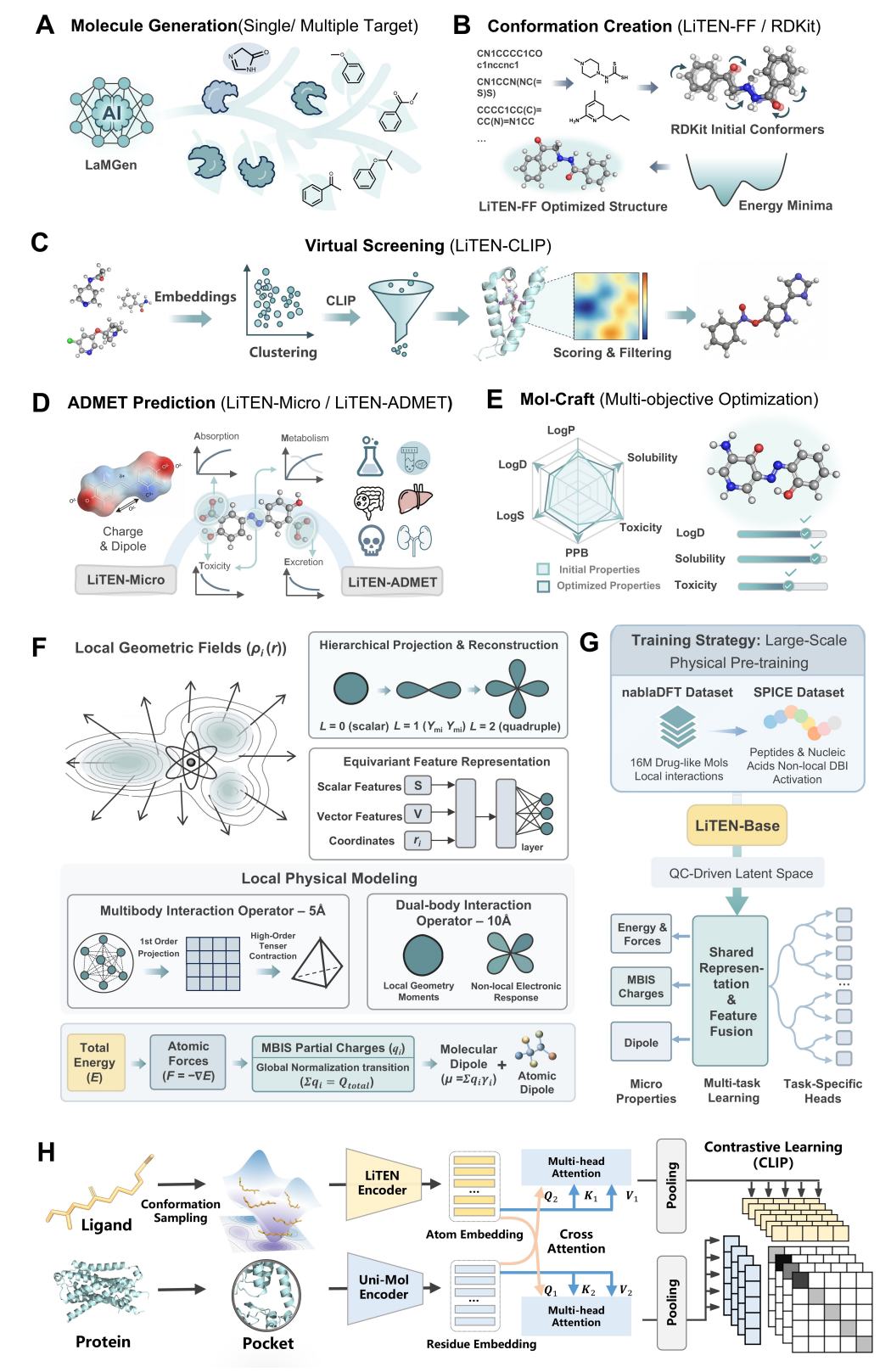
LiTENexus 的端到端流程:从靶点导向分子生成开始,经 LiTEN-FF 构象优化、LiTENCLIP 虚拟筛选、LiTEN-ADMET 多维药代毒性评估,最终进入 Mol-Craft 多目标优化;下方展示 LiTEN-Base 如何通过局部多体相互作用和长程双体相互作用构建量子化学驱动的分子表征。
LiTENexus 的端到端流程:从靶点导向分子生成开始,经 LiTEN-FF 构象优化、LiTENCLIP 虚拟筛选、LiTEN-ADMET 多维药代毒性评估,最终进入 Mol-Craft 多目标优化;下方展示 LiTEN-Base 如何通过局部多体相互作用和长程双体相互作用构建量子化学驱动的分子表征。
结果一:先看微观层,LiTEN-Base 是否真的学到了量子化学
论文首先验证的是最基础的问题:模型能不能可靠地预测微观物理量。
在构象优化任务中,作者从 ZINC 和 PubChem 中随机选择了 200 个多样化药物样分子,用 LiTEN-FF 与 DFT 结果进行对比。结果显示,初始构象和优化后构象的绝对能量误差都控制在约 0.2–0.3 kcal/mol 的水平,低于通常所说的 1 kcal/mol 化学准确性阈值。更重要的是,在构象弛豫路径上的相对能量变化中,MAE 只有 0.09 kcal/mol,R² 达到 0.99。这说明模型不只是把总能量拟合得还不错,更能较好地描述势能面上的局部起伏和梯度方向。对于构象优化来说,这一点比单个绝对能量数字更重要。
在电性特征预测上,LiTEN-Micro 的表现也很强。论文报告,在 SPICE 测试集上,MBIS 部分电荷的 MAE 为 0.0048 e,分子偶极矩的 MAE 为 0.0172 eÅ;在未见过的 Biogen 药物样分子上,电荷和偶极矩误差进一步达到 0.0038 e 和 0.0170 eÅ,Pearson 相关系数均超过 0.999。与 PBE、HF、B3LYP-D3BJ 等常用理论方法相比,LiTEN-Micro 的误差分布更收敛,精度接近计算成本更高的 M06-2X 泛函。
速度差异更有现实意义。论文给出的单次量子性质计算耗时中,LiTEN-Micro 约为 0.00326 分钟,B97-3c 约为 1.10 分钟,M06-2X 约为 5.10 分钟。也就是说,在保持接近高阶量子化学方法精度的同时,模型把计算速度提升到了能支撑高通量筛选的量级。
接下来,作者把这些微观量子特征与宏观 ADME 性质联系起来。结果显示,LiTEN-Micro 提取的偶极矩、部分电荷等特征,与多项实验 ADME 终点存在较强相关性。对于大鼠肝微粒体清除率和 MDR1-MDCK 跨膜通透性,多维物理特征融合后的 Pearson 相关系数达到 0.70;在大鼠血浆蛋白结合、溶解度、人血浆蛋白结合等任务中,多维特征融合相比单一特征也带来明显增益。
这组结果的含义在于:电荷、偶极矩、极性拓扑并不是抽象的数学 embedding,它们确实和药物分子在体内的宏观行为有关。比如一个分子能不能穿过脂质膜,往往取决于它在脱溶剂化、极性暴露和疏水环境适应之间如何平衡;一个分子和蛋白结合得是否稳定,也离不开局部电荷互补、氢键方向性和极化响应。LiTEN-Base 尝试把这些驱动力变成模型可学习、可迁移的底层表示。
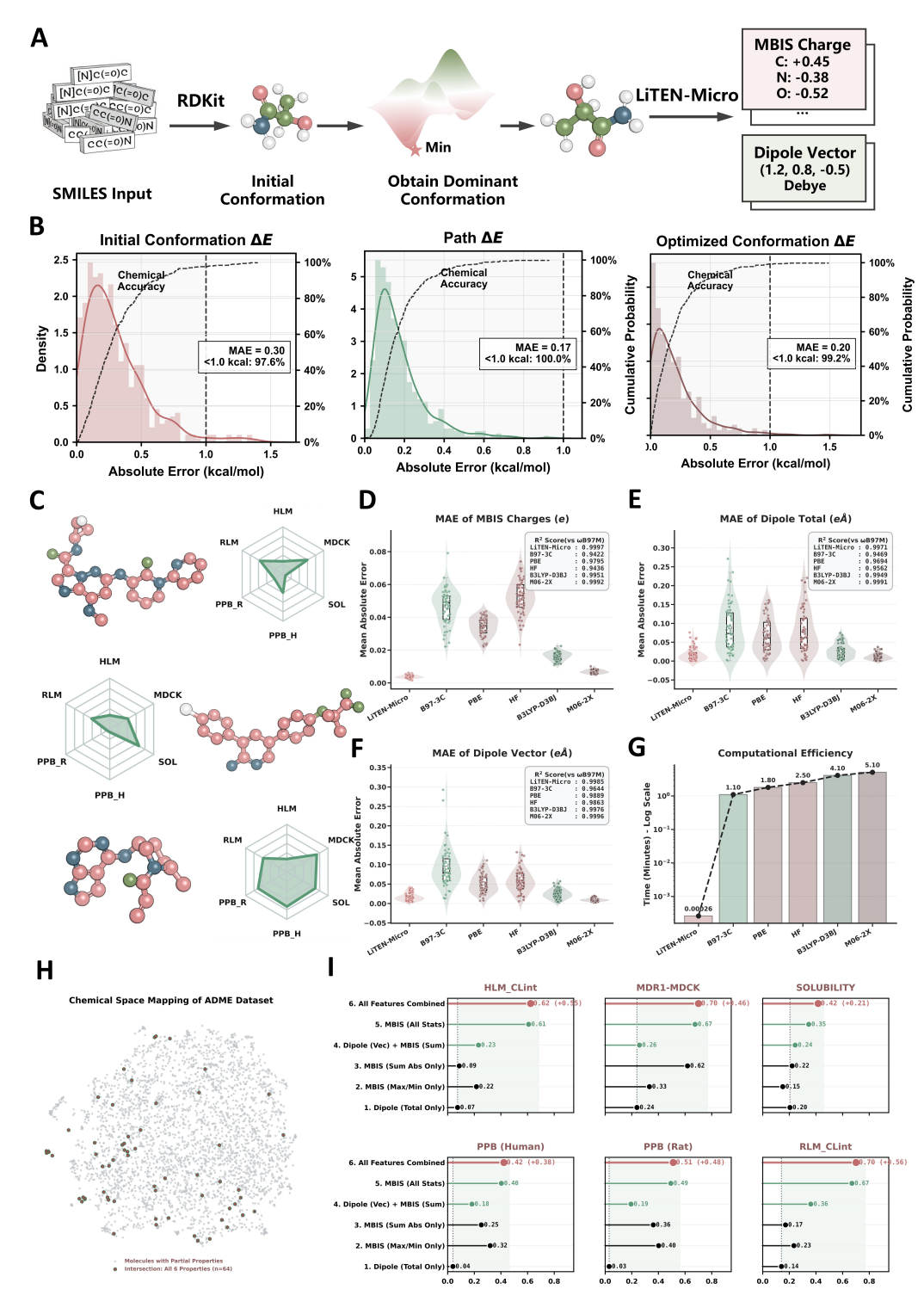
LiTEN-Base 的微观量子特征推导与跨尺度映射:模型从 SMILES 生成三维构象,经 LiTEN-FF 优化后由 LiTEN-Micro 输出 MBIS 电荷和偶极矩;图中同时展示了能量误差、不同量子化学方法对比、计算耗时,以及微观物理特征与 ADME 终点之间的相关性。
LiTEN-Base 的微观量子特征推导与跨尺度映射:模型从 SMILES 生成三维构象,经 LiTEN-FF 优化后由 LiTEN-Micro 输出 MBIS 电荷和偶极矩;图中同时展示了能量误差、不同量子化学方法对比、计算耗时,以及微观物理特征与 ADME 终点之间的相关性。
结果二:从量子特征到 ADMET,模型是否能影响真实药物性质预测
有了微观层面的验证,论文进一步把 LiTEN-Base 用到 ADMET 预测中。这里的关键不是简单多加几个量子描述符,而是让 LiTEN-Base 学到的物理表征参与下游多任务建模。
在 Biogen 数据集上,LiTEN-Base 结合量子化学信息注入后,与 20 多种基线模型进行比较,包括传统机器学习、图神经网络、分子语言模型、Uni-Mol、KPGT、CHMR 等。论文报告,LiTEN-Base 在 6 个核心性质上整体取得最优,平均 MAE×100 为 38.8,优于 CHMR 的 40.9 和 KPGT 的 43.9。具体到人肝微粒体清除率、大鼠肝微粒体清除率、外排比、溶解度、人/大鼠血浆蛋白结合等指标,模型都表现出优势。
在 PharmaBench 上,LiTEN-Base 进一步被用于结构-性质关系更细的评估。论文称其在 33 个指标中的 25 个超过基线。比如 LogD 的 R 达到 0.924,血脑屏障渗透任务的 AUC 达到 0.945。更值得注意的是 CYP2D6 这类代谢酶相关任务:纯数据驱动版本的 LiTEN 在该任务上的 R 为 0.521,引入 QCII 后提高到 0.637。代谢反应本质上涉及电子转移、键断裂和局部反应性,因此量子化学特征在这里有更直接的物理意义。
随后,团队构建了 LiTEN-ADMET。它基于 ADMETLAB 3.0 数据集的 77 个终点,将任务划分为吸收、分布、代谢、排泄、毒性、理化性质等不同簇,并采用三维构象集成预测流程:每个输入 SMILES 先生成 100 个初始构象,经力场优化后筛选 5 个低能构象,分别预测后取平均。这种策略试图降低单一构象带来的偶然误差,更接近分子在真实环境中的动态状态。
LiTEN-ADMET 在 18 个回归任务中全部达到最优,在 59 个分类任务中有 44 个达到最优。论文还观察到一个很有解释力的现象:模型带来的性能增益,与传统基线模型的性能上限呈显著负相关,Pearson r 为 -0.66。也就是说,越是传统 2D 或浅层特征难以处理的任务,量子化学信息越可能提供补充。这种 救援效应 让 LiTEN-ADMET 不只是锦上添花,而是在困难终点上更像是在补足传统表征的盲区。
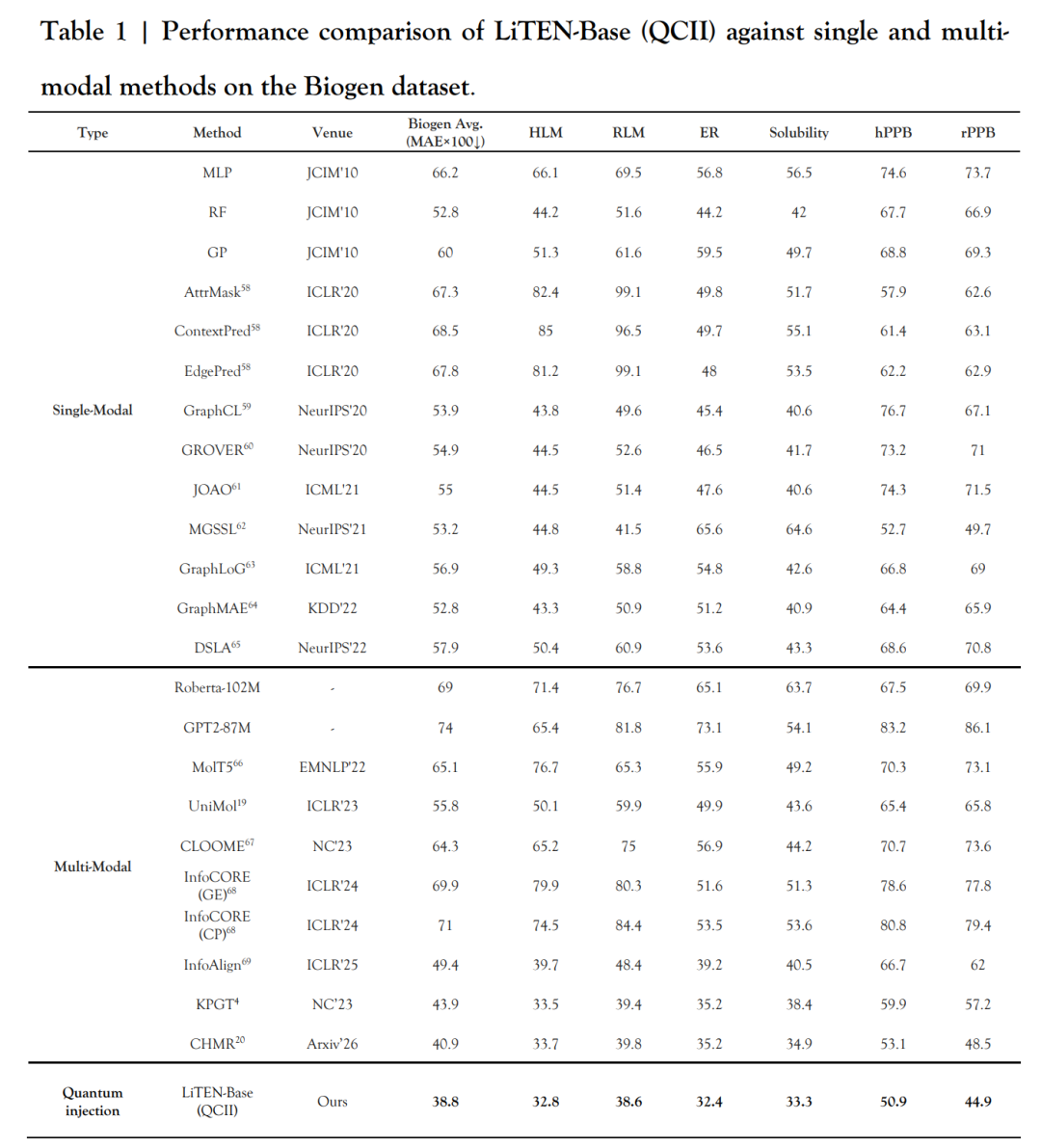
LiTEN-Base 结合量子化学信息注入后,在 Biogen 数据集 6 个核心 ADME/理化性质上与传统机器学习、图神经网络、分子语言模型、三维分子表征模型及多模态模型进行比较,平均误差达到最低。
LiTEN-Base 结合量子化学信息注入后,在 Biogen 数据集 6 个核心 ADME/理化性质上与传统机器学习、图神经网络、分子语言模型、三维分子表征模型及多模态模型进行比较,平均误差达到最低。
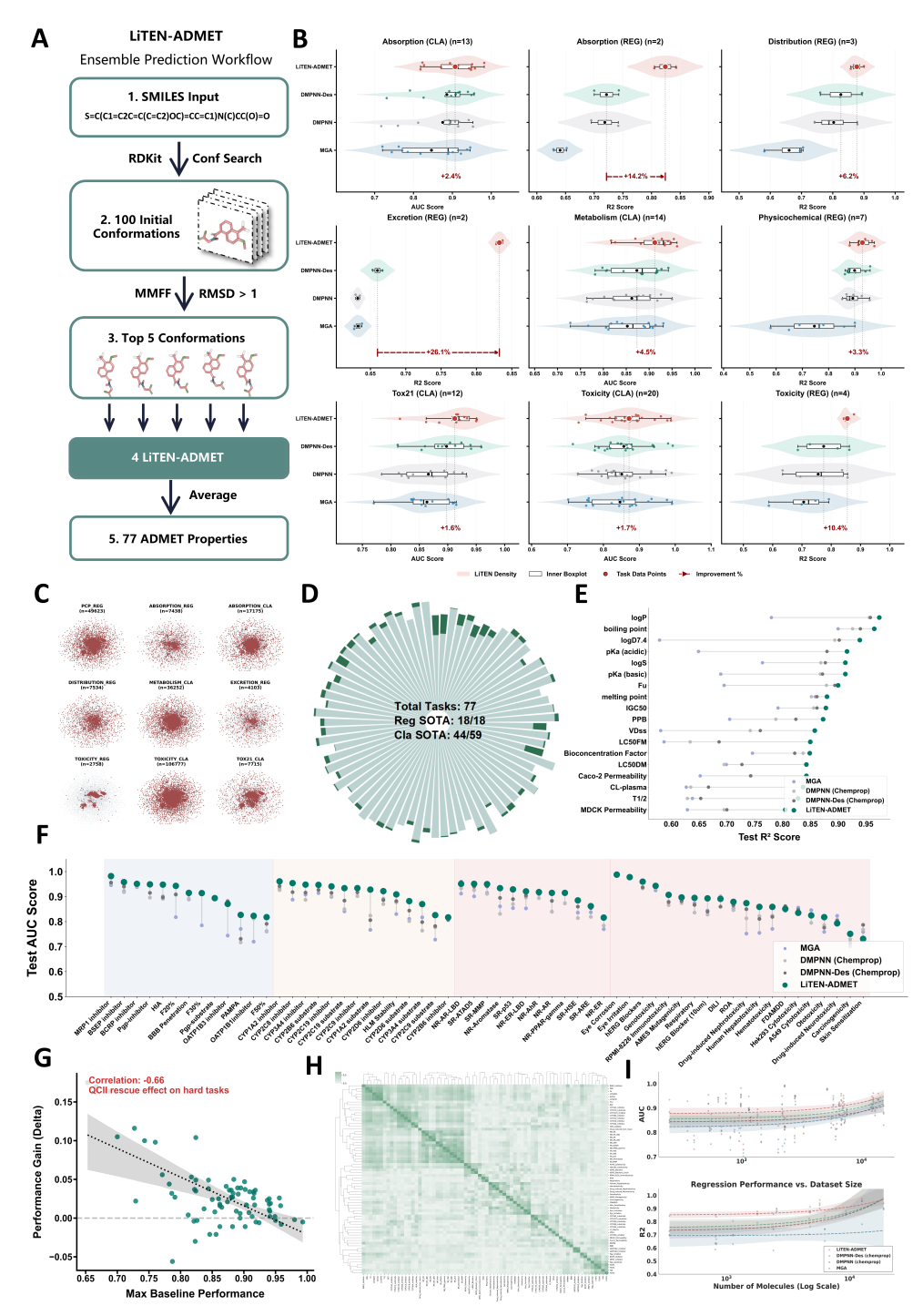
LiTEN-ADMET 的药理性质预测评估:图中展示三维构象集成预测流程、9 类 ADMET 任务簇的表现、77 个终点中的最优数量、回归与分类任务细分结果、困难任务中的性能救援效应,以及不同数据规模下的鲁棒性。
LiTEN-ADMET 的药理性质预测评估:图中展示三维构象集成预测流程、9 类 ADMET 任务簇的表现、77 个终点中的最优数量、回归与分类任务细分结果、困难任务中的性能救援效应,以及不同数据规模下的鲁棒性。
结果三:分布外泛化,天然产物和环肽是更难的考场
药物发现里真正棘手的分子,往往不是标准小分子库里那些结构规整、合成友好的化合物。天然产物和环肽就是两个典型例子。
天然产物常常有更高的 sp³ 杂化比例、复杂多环骨架、密集手性中心和丰富的非共价作用位点。环肽则兼具大分子特征和小分子药物化需求,它们的膜通透性依赖构象变化、分子内氢键网络和极性表面积的动态隐藏。传统一维序列或二维拓扑模型很难直接看到这些三维电子环境与构象适应性。
论文用 UMAP 显示,天然产物和环肽与 LiTEN-Base 预训练所用的 SPICE 分布重叠很小,属于明显的分布外化学空间。随后,作者在天然产物结合亲和力预测任务中,将 LiTEN-Base 与专门面向天然产物预训练的 NaFM 比较。即便 LiTEN-Base 采用的是配体侧微调方式,它在多数靶点上仍取得更好的 RMSE 和 Pearson 相关表现。更重要的是,误差优势并不是集中在某一小块化学空间,而是在天然产物 UMAP 空间中分布较均匀。这意味着模型可能没有简单依赖某类骨架,而是更依赖分子表面的电荷极化和供受体匹配能力。
在环肽膜通透性预测中,LiTEN-Base 与 Chemprop、Multi_CycGT 进行对比。论文报告,LiTEN-Base 将 R² 提升 42.2%,达到 0.64,同时 MAE 和 RMSE 均下降超过 17%。这组结果对应的物理图景很清楚:环肽穿膜时常常需要形成分子内氢键,把极性基团临时藏起来,从而降低穿越脂质双层时的脱溶剂化代价。QCII 注入的原子极化、电荷离域和三维电子环境信息,正好能帮助模型间接捕捉这种构象与热力学倾向。
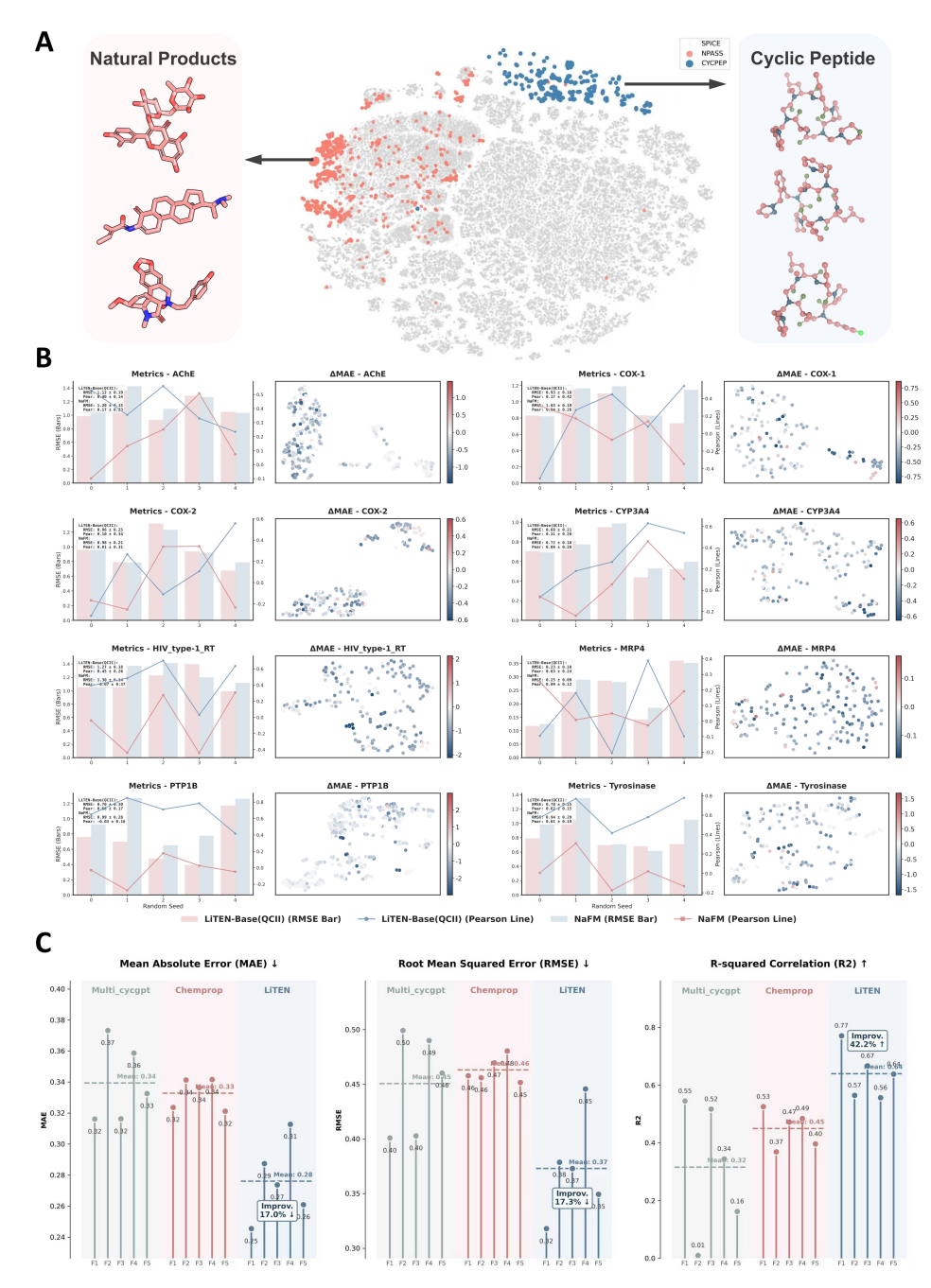
LiTEN-Base 在分布外化学空间中的泛化表现:图中展示天然产物、环肽与预训练数据的化学空间分布差异,并比较 LiTEN-Base 在天然产物结合亲和力和环肽膜通透性预测中的表现。
LiTEN-Base 在分布外化学空间中的泛化表现:图中展示天然产物、环肽与预训练数据的化学空间分布差异,并比较 LiTEN-Base 在天然产物结合亲和力和环肽膜通透性预测中的表现。
结果四:虚拟筛选,LiTENCLIP 把结合问题改写成量子流形检索
虚拟筛选一直是 AI 制药里最容易被放大的场景。传统分子对接可以给出三维结合姿势和打分,但面对超大规模分子库时,计算成本很高;深度学习打分函数速度更快,却容易受限于训练数据和数据集偏差。LiTENCLIP 的思路不是直接回归绝对结合自由能,而是把蛋白-配体识别改写为跨模态稠密检索。
具体来说,配体侧由 LiTEN-Base 生成带有立体电子信息的量子流形嵌入,蛋白口袋侧则借助 Uni-Mol 提取三维几何与残基环境特征。二者通过物理感知交叉注意力对齐,模型在训练中学习把真实活性配体和对应蛋白口袋拉近,把诱饵分子或不匹配分子推远。这个设计与 DrugCLIP 一类对比学习筛选方法有相通之处,但 LiTENCLIP 的差别在于:小分子端不是普通拓扑或几何 embedding,而是经过量子化学信息注入的物理表征。
在 DUD-E 数据集上,LiTENCLIP 的 AUROC 为 0.90,前 1% 富集因子 EF1% 达到 44.06。相较 DrugHash 的 EF1% 37.18 和 DrugCLIP 的 31.89,它在早期富集能力上分别提升 18.5% 和 38.2%。BEDROC 分数达到 0.68,也高于 Glide-SP、Gnina、RTMScore、GenScore 等基线。对于虚拟筛选来说,前 1% 富集尤其重要,因为真实项目中研究者往往只会优先合成或采购排序最靠前的一小部分化合物。
更严格的测试来自 LIT-PCBA。这个数据集的活性分子和非活性分子结构更相似,更接近真实高通量筛选中的噪声环境。论文显示,在 LIT-PCBA 上所有模型的表现都明显下降,LiTENCLIP 也不例外,但它仍以 AUROC 0.61、EF1% 6.77 保持领先。这里的判断需要克制:LIT-PCBA 上的数值提醒我们,真实筛选远比 DUD-E 更难;但 LiTENCLIP 能在这种设置下保持相对优势,说明量子化学表征确实可能帮助模型分辨那些仅靠二维相似性很难区分的分子。
论文最后还展示了 GSK-3β 和雄激素受体相关的活性悬崖案例。所谓活性悬崖,是指两个结构极其相近的分子,结合能力却相差 2–3 个数量级。传统模型很容易在这种情况下被结构相似性误导,而 LiTENCLIP 对这些微小局部差异给出了更符合亲和力变化的区分。这类案例不等于大规模实验验证,但能直观说明模型试图捕捉的不是普通骨架相似性,而是局部三维电子状态变化。
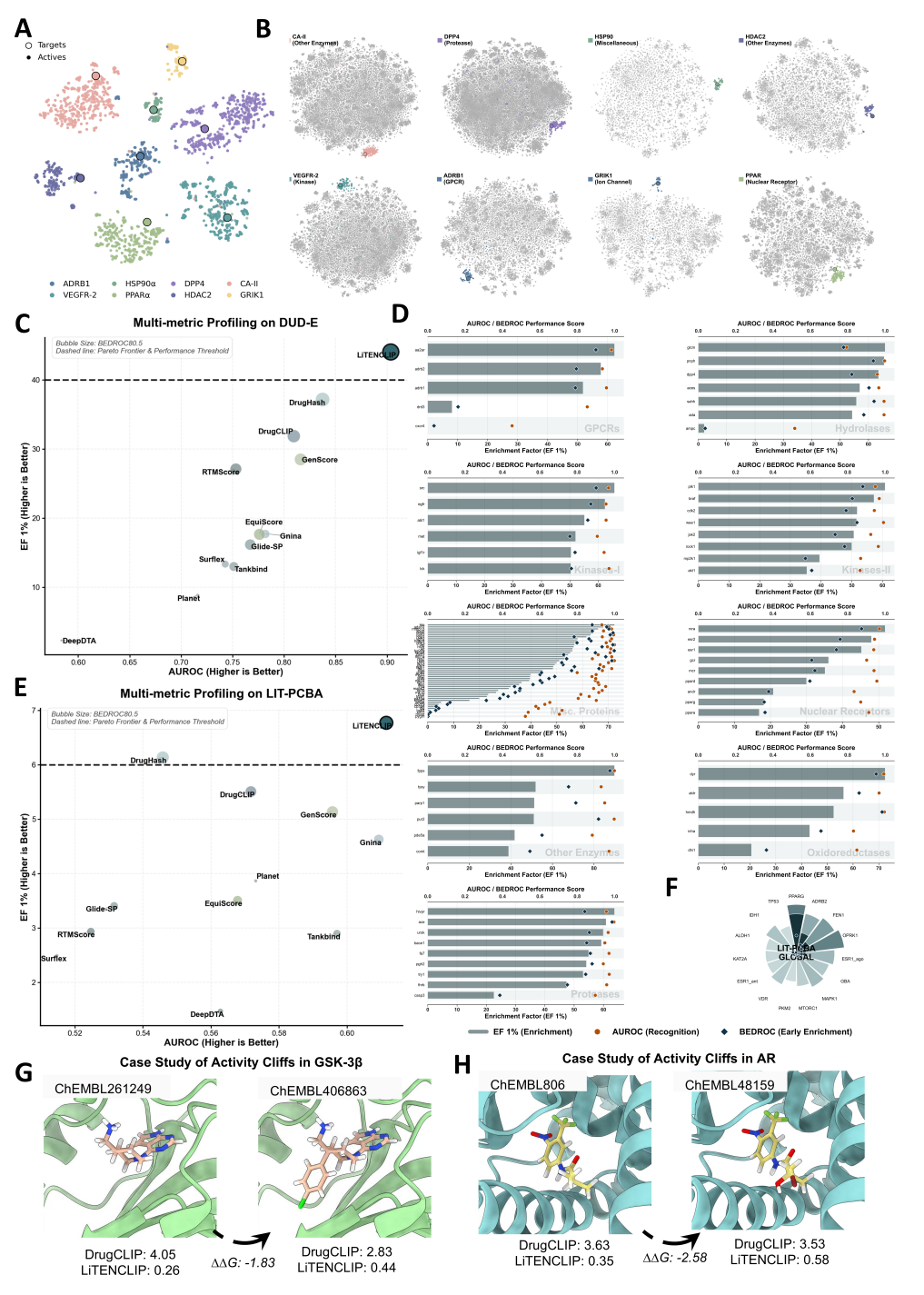
LiTENCLIP 的虚拟筛选评估:图中展示 DUD-E 靶点与活性分子的共享嵌入空间、DUD-E 和 LIT-PCBA 上的 AUROC/EF1%/BEDROC 对比、102 个 DUD-E 靶点的家族级表现,以及 GSK-3β 和雄激素受体活性悬崖案例。
LiTENCLIP 的虚拟筛选评估:图中展示 DUD-E 靶点与活性分子的共享嵌入空间、DUD-E 和 LIT-PCBA 上的 AUROC/EF1%/BEDROC 对比、102 个 DUD-E 靶点的家族级表现,以及 GSK-3β 和雄激素受体活性悬崖案例。
真正的重点不是多一个 benchmark,而是表征范式的变化
LiTENexus 把量子化学从后处理搬到了表征底座。很多模型也会使用量子描述符,但常见方式是把 DFT 计算结果当作额外输入或监督标签。LiTENexus 更进一步,把能量-力一致性、电荷守恒、偶极矩推导、局部多体相互作用、长程极化响应等物理约束放进神经算子的结构和训练过程里。这样得到的 embedding,不再只是统计意义上的分子向量,而是带有物理含义的分子状态表达。
第二层是从微观到宏观的跨尺度连接。论文并没有停留在量子性质预测,而是继续证明这些微观特征能够帮助 ADMET、膜通透、代谢、蛋白结合等宏观药物性质预测。对于药物研发来说,这一点很重要。一个计算模型如果只能预测电荷,却不能帮助判断分子是否更容易清除、是否更容易穿膜、是否更容易出现毒性,那么它的药物发现价值就会有限。LiTENexus 的设计试图让微观物理量进入真正的研发决策链条。
第三层是把虚拟筛选做成检索问题。面对大规模化合物库,逐一对接和逐一高精度打分都很难扩展。LiTENCLIP 把配体和蛋白口袋投射到同一个物理潜空间中,提前缓存小分子向量,再对新靶点做近邻检索。这种方式在速度上天然适合高通量筛选;如果量子流形嵌入能保持足够的物理分辨率,它就可能成为早期筛选中的实用基础设施。
END:AI 制药开始从像不像,走向为什么
LiTENexus 给出的答案可以概括成一句话:分子表征不应该只问这个分子像谁,还应该问它为什么会这样相互作用。
过去几年,AI 药物发现常常被大模型、生成式设计和虚拟筛选速度推动。LiTENexus 代表的是另一种路线:让模型更深地嵌入物理世界,把电子结构、势能面、极化、偶极矩这些看似微观的东西,连接到药代、毒性、膜通透和靶点结合这些宏观问题上。它不一定解决了 AI 制药的所有难题,但它把一个核心问题摆得很清楚:如果模型只会学习数据中的相似性,它终究会被新的化学空间考住;如果模型能学到更底层的物理约束,它才可能在没见过的分子上保持判断力。
对药物发现来说,真正稀缺的不是再多一个打分器,而是一个能在复杂化学空间里保持稳定、可解释、可扩展的决策底座。LiTENexus 还需要更多验证,但它把 AI 分子模型往这个方向推进了一步:从二维骨架走向三维电子环境,从经验相关走向物理约束,从单点预测走向端到端闭环。
这也是这篇工作的余味所在。AIDD的下一阶段,可能不会只靠更大的数据和更大的网络,而要靠更好的世界观:把分子重新当作一个真实的物理系统来理解。
参考文献
Qun Su, Qiaolin Gou, Hui Zhang, et al. LiTENexus: An End-to-End Virtual Drug Discovery System Based on Quantum Chemical Grounding. ChemRxiv. 15 May 2026. DOI: https://doi.org/10.26434/chemrxiv.15003380/v1
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-19,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号