ICML 2026 | 从观测到状态:深度时序预测模型的隐藏缺陷

ICML 2026 | 从观测到状态:深度时序预测模型的隐藏缺陷

时空探索之旅
发布于 2026-05-18 12:26:39
发布于 2026-05-18 12:26:39
论文标题: From Observations to States: Latent Time Series Forecasting
会议: ICML 2026
作者: Jie Yang*, Yifan Hu*, Yuante Li, Kexin Zhang, Kaize Ding, Philip S. Yu
单位: 伊利诺伊大学芝加哥分校、清华大学、卡内基梅隆大学、西北大学
代码: https://github.com/Muyiiiii/LatentTSF
论文:https://arxiv.org/abs/2602.00297

点击文末阅读原文跳转本文arXiv链接
引入
时序预测(Time Series Forecasting, TSF)是人工智能领域的核心任务之一,广泛应用于交通调度、天气预报、金融分析等场景。近年来,以 Transformer、MLP 为代表的深度学习模型在各类基准测试上取得了令人瞩目的预测精度。然而,预测精度高 = 模型真正"理解"了时序数据的动态规律吗?本文的研究给出了一个令人意外的答案:不一定。
潜在混沌
作者通过对多个主流时序预测模型的系统性分析,发现了一个普遍存在却鲜有关注的现象——💥潜在混沌(Latent Chaos):模型在观测空间中预测误差很低,但其内部学到的潜在表示(latent representations)却在时间上高度无序、缺乏连续性。
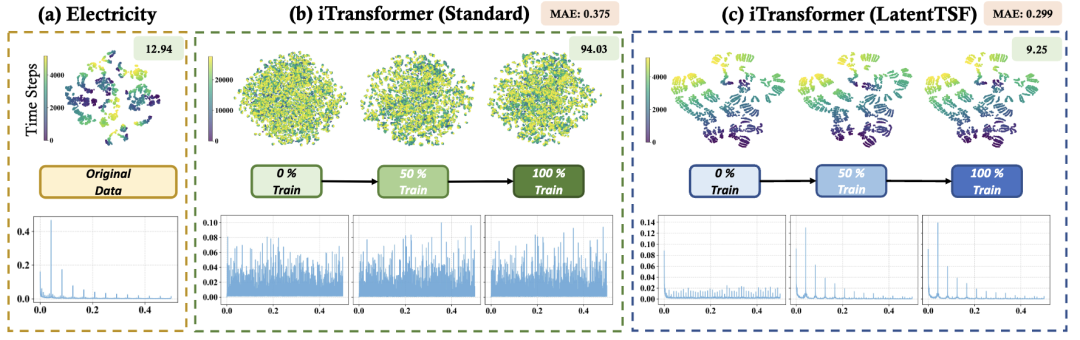
以 iTransformer 在 Electricity 数据集上的实验为例:
- t-SNE 可视化显示,原始观测数据呈现清晰的时序局部性(相邻时刻的样本聚集在一起),而标准 iTransformer 学到的潜在表示则毫无规律地散布各处;
- 相邻时刻的潜在距离从原始数据的 12.94 暴增至 94.03(增大约 7 倍);
- 频域分析显示,潜在表示严重扭曲了原始数据的周期结构。
这说明:低预测误差,并不代表模型学到了有意义的时序动态规律。
为什么会出现潜在混沌?
作者从两个互补的视角深入剖析了这一现象的根源:
① 系统论视角:部分可观测性
现实世界的观测数据 往往是高维动态系统状态的噪声化、低维投影。真正驱动系统演化的潜在变量并不完整地体现在观测空间中。因此,单纯最小化观测空间的预测误差,不能保证模型恢复出完整的动态规律,反而容易拟合均值回归、自相关等低阶统计特征。
② 优化视角:时序归纳偏置不足
标准的逐点损失函数(MAE、MSE)只奖励数值精度,对潜在表示如何随时间演变完全不感知。这导致模型倾向于学习输入历史中的组合相关性,而非平滑可识别的动态过程。
这样的损失对"表示是否随时间连续演变"毫无约束,自然容易产生潜在混沌。
LatentTSF 范式
为了从根本上解决这一问题,作者提出了 LatentTSF——一种将时序预测从"观测回归"转向"潜在状态预测"的通用训练范式。
框架概览
LatentTSF 包含两个阶段:
阶段一:潜在状态空间构建
原始观测 X ──[预训练 AutoEncoder]──→ 潜在状态序列 Z_X, Z_Y
阶段二:潜在状态预测
Z_X ──[TSF 主干网络]──→ 预测潜在状态 Ẑ_Y ──[解码器]──→ 最终预测 Ŷ
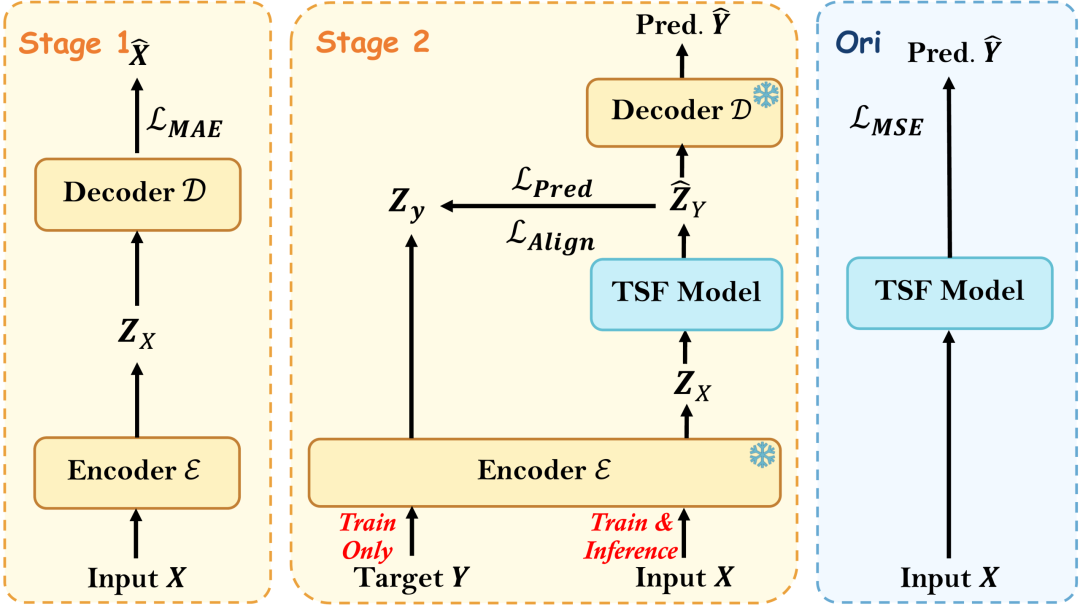
与标准范式的关键区别:
标准 TSF 范式 | LatentTSF 范式 | |
|---|---|---|
预测目标 | 观测空间未来值 | 潜在空间未来状态 |
损失计算 | 观测空间 vs | 潜在空间 vs |
主干网络修改 | — | 无需修改,即插即用 |
阶段一:潜在状态空间构建
对每个时刻 的观测向量 ,使用一个逐点(point-wise)AutoEncoder 将其映射到潜在状态:
AutoEncoder 通过重构损失预训练后冻结,为后续的潜在预测提供稳定的目标空间:
阶段二:潜在状态预测
在潜在空间中,TSF 主干网络学习从历史潜在状态预测未来潜在状态:
最终预测通过解码器映射回观测空间:
训练目标:预测损失 + 对齐损失
LatentTSF 的训练目标完全定义在潜在空间中,由两部分组成:
- :预测损失,约束潜在状态的幅度精度;
- :对齐损失,通过余弦相似度约束方向一致性,防止退化解。
理论支撑:互信息最大化视角
作者从信息论角度证明了 LatentTSF 的合理性:
是最大化互信息 的变分下界
假设潜在预测误差服从各向同性高斯分布 ,则:
是最大化互信息 的有效代理
受 InfoNCE 启发, 通过最大化预测潜在状态与未来观测之间的余弦相似度,使预测表示对未来真实观测保持充分信息量。
此外,由于编码器冻结,LatentTSF 从结构上排除了表示坍缩(representation collapse),无需负样本对比或 stop-gradient 等额外机制。
实验结果
预测精度全面提升
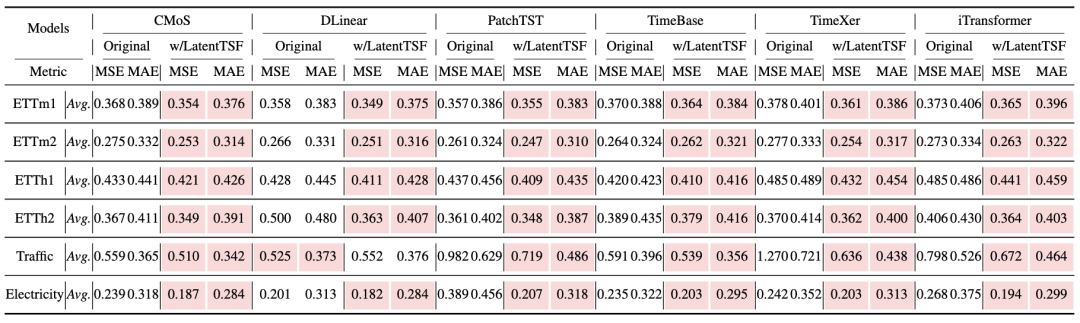
在六个广泛使用的基准数据集(ETTh1/h2/m1/m2、Electricity、Traffic)上,LatentTSF 作为即插即用的训练范式,对六个主流 TSF 主干(DLinear、PatchTST、iTransformer、TimeBase、TimeXer、CMoS)均带来了一致的性能提升。
实验揭示了规律性结论:数据集变量维度越高,LatentTSF 的增益越显著。
- 高维数据集(Electricity 321变量,Traffic 862变量):DLinear 在 Electricity 上 MSE 从 0.201 降至 0.182(降幅 9.5%),iTransformer 在 Traffic 上 MSE 从 0.798 降至 0.672(降幅 15.8%)。高维观测中存在大量噪声与冗余,观测空间本身偏离真实状态空间更远,潜在建模的优势最为突出。
- 低维数据集(ETT 系列 7变量):提升依然存在但相对温和。这与直觉相符——系统越简单,观测空间本身越接近真实状态空间,潜在重构的边际收益自然较小。
AutoEncoder 分析
作者设计了两组对照实验:
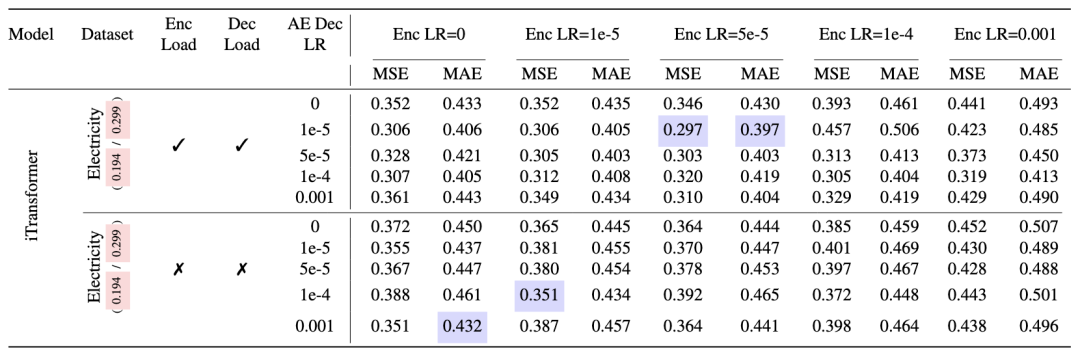
组 A:加载预训练 AE,微调编码器/解码器(引入 )
以 iTransformer 在 Electricity 上为例(基线 MSE/MAE = 0.194/0.299):一旦引入观测空间的 MSE 监督并微调编码器,即便是网格中表现最好的配置(Enc LR=5e-5,Dec LR=1e-5)也只达到 MSE=0.297/MAE=0.397,仍明显劣于仅使用潜在损失的冻结 AE 配置(0.194/0.299)。解码空间的监督信号会扰动已学成的稳定潜在流形。
组 B:不预训练,用随机初始化 MLP 替代 AE
性能进一步大幅下降(网格中最低也仅约 0.351/0.432),甚至在某些设置下接近未训练水平。原因在于:没有预训练,潜在表示高度不稳定,预测目标随训练不断漂移,梯度噪声极大,主干网络无法收敛到有意义的动态结构。
因此,预训练且冻结的 AE 是 LatentTSF 获得稳定增益的核心前提。
潜在表示质量大幅改善
仅凭预测误差下降不足以说明潜在表示的质量,作者从三个正交指标定量评估:
指标 | 含义 |
|---|---|
CKA(中心核对齐)↓ | 潜在空间与观测空间的结构相似度;远低于 1.0 说明非恒等映射 |
有效秩(Effective Rank)↑ | 潜在协方差的显著方向数;越高说明表示越丰富 |
时序转移一致性(TTC)↑ | 相邻潜在状态的余弦相似度;越高说明轨迹越连续 |
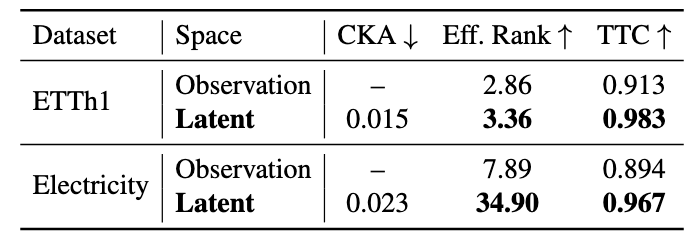
三项指标同时改善,且效果显著:Electricity 的有效秩提升 4.4 倍(7.89 → 34.90),时序一致性提升 8.2%(0.894 → 0.967),CKA 远低于 1.0 排除了恒等映射的可能。这些数据有力佐证了 LatentTSF 确实学到了结构化的时序动态,而非仅对观测空间的重新标注。
潜在状态压缩
LatentTSF 并不依赖于维度扩张,无论压缩还是等维均能有效工作。以 PatchTST 在 Traffic()上的结果为例。
即使在压缩()的设定下,LatentTSF 仍大幅优于原始基线,且内存效率更高。这证明了方法的核心价值在于潜在状态建模本身,而非维度扩展带来的容量增加。

如果觉得有帮助还请分享,在看,点赞
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-12,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号