90%的人只看到矩阵乘法,却不知道大模型偷偷藏了200年前的搬土问题和物理学相变

90%的人只看到矩阵乘法,却不知道大模型偷偷藏了200年前的搬土问题和物理学相变

chouheiwa
发布于 2026-05-06 21:41:42
发布于 2026-05-06 21:41:42
我在南开读软件工程硕士的时候,第一次认真推 Transformer 的注意力公式,盯着看了半天,心想这也太朴素了吧,就是矩阵乘法加一个归一化。但越往后学越觉得不对劲。这个看起来人畜无害的公式背后,藏着旋转群、最优传输、统计物理的相变理论,甚至还有一个 1957 年被证明的纯数学定理在 2024 年突然被人拿来造新型神经网络,拿了 ICLR 2025 最佳论文。
我本科学化工的,有个职业病叫控制变量法,分析任何复杂系统都想先拆变量。这篇回答不打算把大模型背后的数学全列一遍,那是综述论文干的事。我就挑几个我觉得最让人拍案叫绝的,把它们的核心直觉讲清楚。你不需要会推公式,但看完应该能理解:为什么搞大模型的人越来越需要数学,而且需要的数学越来越奇怪。
注意力机制的秘密:它其实是个"投票系统"
大模型的核心组件是 Transformer,Transformer 的核心是注意力机制(Attention)。这个机制在做的事情,用大白话说就是:对于句子中的每个词,去问一遍其他所有词你跟我有多相关,然后按相关度加权平均。
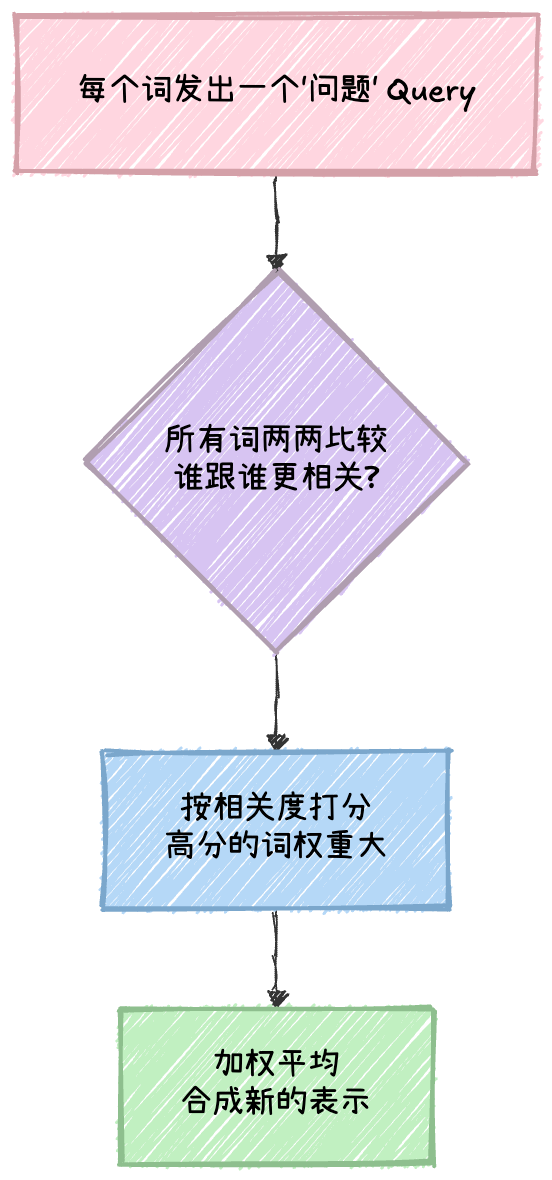
这整个过程在数学上全是矩阵运算。每个词被表示成一个向量,一句话就是一个矩阵。"比较相关度"是两个矩阵做乘法,"加权平均"又是一次矩阵乘法。Anthropic 在 2021 年拆解了这个结构,发现注意力头里其实跑着两套独立的电路:一套决定"看谁",一套决定"传什么",各自对应不同的矩阵乘积。
其实吧,线性代数在这儿的角色有点像建筑里的钢筋混凝土,不起眼但拿掉就塌。更让我觉得精妙的是后面几个。
但光有矩阵运算还不够。Wi et al.(IJCAI 2025)从信号处理的角度证明了一个很直觉的结论:因为注意力的权重全是正数而且加起来等于 1,它天然就是个低通滤波器,会把高频噪声抹平、保留低频的全局语义。说白了,注意力机制天生就在"抓大放小"。
LoRA 的低秩魔法:用 0.01% 的参数微调整个模型
GPT-3 有 1750 亿参数。你想让它学会一个新任务,难道要把 1750 亿个数字全重新训练一遍吗?
微软的 LoRA(2021)给出了一个数学上极其优雅的解决方案。核心思路是:微调的时候,模型权重的变化量其实是一个"低秩"矩阵。
打个比方。假设你有一张 1000×1000 的大表格,代表模型的某一层权重。微调之后这张表格变了,但变化的部分可以用一张 1000×4 的表格乘以一张 4×1000 的表格来近似。4 比 1000 小太多了,所以你只需要存储和训练这两张小表格就够了。这就是低秩近似的威力。
这个直觉背后有一个真实的经验发现:预训练好的大模型,它的"能力空间"其实是高度压缩的。Aghajanyan et al.(2020)发现微调更新的内禀维度远小于参数维度。LoRA 对 GPT-3 把可训练参数从 1750 亿降到了大约 1800 万,效果几乎无损。苏剑林在科学空间上的分析从梯度的角度解释了为什么这行得通,写得很漂亮。
这事的启示是:数学上的低秩假设,反映的恰恰是大模型本身的结构特征。 模型看起来有千亿参数,但真正干活的自由度可能只有几百万。这是线性代数告诉我们的。
位置编码背后的旋转群:一个让群论教授都觉得漂亮的设计
Transformer 有个先天缺陷:它处理序列的方式是"一口气全看完",不像 RNN 那样一个词一个词地读。所以它天生分不清词的顺序。你得额外告诉它"这个词在第 3 个位置,那个词在第 7 个位置"。
2017 年原版 Transformer 用的是正弦/余弦函数来编码位置,其实就是不同频率的波。但 2021 年,苏剑林提出了 RoPE(旋转位置编码),现在几乎所有主流大模型(LLaMA、Qwen、Mistral、Gemma)都在用。
RoPE 的核心想法优美得令人发指:把位置信息编码成旋转。 每个词的向量被分成一对一对的分量,每对分量按照它在句子中的位置旋转一个角度。位置越靠后,转的角度越大。
为什么旋转?因为两个向量做点积(用来算相关度)的时候,旋转的效果恰好只取决于两个位置之间的差值。第 3 个词和第 7 个词之间的关系,跟第 100 个词和第 104 个词之间的关系,在数学上是一样的。这正是旋转群 SO(2)(二维平面上的旋转变换群)的核心性质。
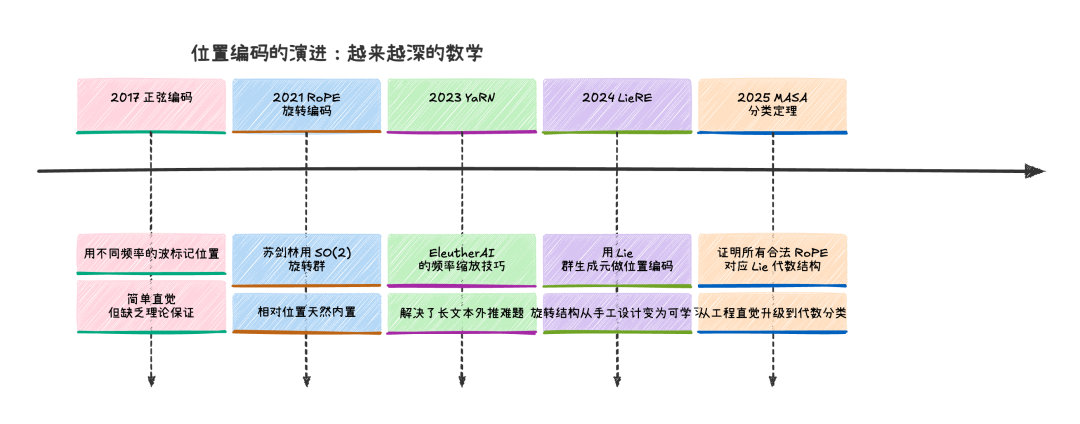
你猜怎么着,2025 年 Manchester 的研究者证明了一个分类定理:所有数学上合法的旋转位置编码,恰好对应一种叫"Lie 代数的极大交换子代数"的东西。 这意味着 RoPE 的设计空间不是无限的,它被抽象代数严格限定了。苏剑林拍脑袋想出来的设计,恰好落在了这个代数结构的最自然的点上。
这种事在数学史上反复出现:工程师凭直觉做出了好用的东西,数学家后来发现它好用的原因是因为它恰好满足了某个深层的数学结构。
Scaling Laws:大模型领域的"万有引力定律"
物理学有牛顿定律,大模型有 Scaling Laws(缩放定律)。
OpenAI 在 2020 年发现了一个惊人的经验规律:大模型的性能(用困惑度衡量)与模型大小、训练数据量之间存在幂律关系。模型变大 10 倍,性能按照一个固定的指数提升。这个关系跨越了好几个数量级,稳定得不像话。
DeepMind 的 Chinchilla 论文(2022)把这个幂律做了更精确的数学建模,得出一个至今影响深远的结论:模型大小和训练数据应该等比例增长。70B 参数配上 1.4 万亿 token 的数据训练,比 280B 参数配少量数据效果更好。这直接颠覆了当时"越大越好"的共识。
但 2025 年出了一个更有趣的转折。UC Berkeley 的 Snell et al.(ICLR 2025 Oral)证明了推理时多花计算也遵循缩放定律,而且效果可以非常惊人:一个小模型在推理时多做几轮"思考",可以超越大 14 倍的模型。Chen et al.(2024)甚至给出了数学证明:用锦标赛式的多次采样,错误率以指数速度衰减。
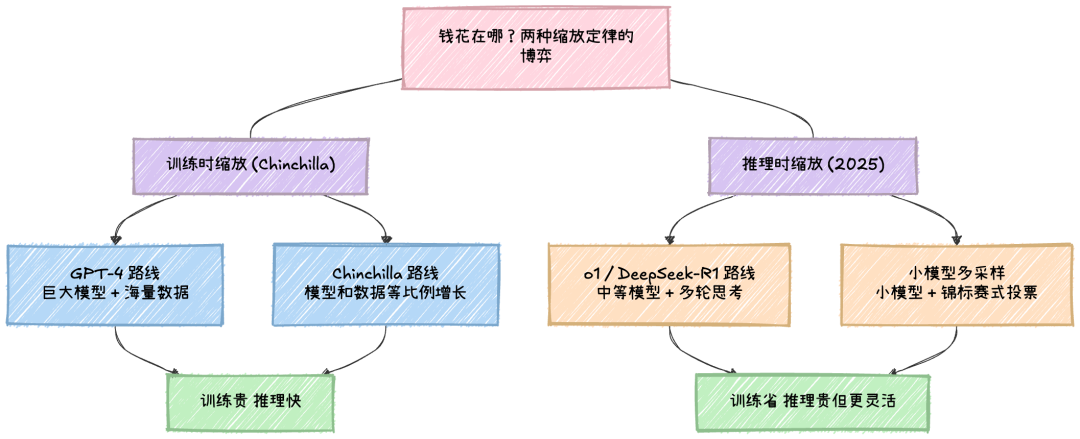
说白了,Chinchilla 回答的是训练时怎么花钱最划算,测试时缩放定律回答的是推理时怎么花钱最划算。DeepSeek-R1 和 OpenAI 的 o1 系列就是后者的工程化产物。这两个定律背后都是幂律,但最优分配策略完全不同。
为什么是幂律?为什么不是指数或者对数?其实吧,到今天没人能完全解释。这是大模型理论里最大的开放问题之一。不过统计物理的人觉得他们可能有线索。
统计物理的入侵:学习率就是温度
2025 年最让我震撼的跨学科成果来自 MIT 的 Tegmark 团队。他们提出了一套叫神经热力学定律的框架,核心发现是:
训练大模型的过程和加热/冷却一块金属在数学上是同一回事。
学习率大的时候,参数到处乱跳,像高温下分子的剧烈运动。学习率小的时候,参数安定下来,像低温下分子排列成晶体。学习率就是温度,这不是类比,是严格的数学等价。
从这个对应关系出发,他们推导出了一系列物理定律在训练过程中的对应物:能量均分定理(参数方差的分布规律)、热力学第一定律(损失的分解)、甚至最优的学习率衰减策略 η(t) ∝ 1/(t+t₀) 可以从热力学原理直接推出来。这意味着以前靠炼丹经验调的超参数,现在有了物理学定律的指导。
这个方向还揭示了一个更奇妙的现象:Grokking(顿悟)。

Grokking 说的是这样一个现象:模型在训练数据上很快就能达到 100% 准确率(死记硬背),但在测试数据上长期表现很差,然后在训练了很久很久之后突然开窍,测试准确率蹿上去了。这个突然有多突然呢?跟水结冰一样突然。
统计物理学家一看就兴奋了,这不就是相变吗?2025 年的 JMLR 论文从学习局部规则的角度严格证明了 Grokking 是一阶相变。Cullen et al.(2026)用奇异学习理论给出了闭式的数学描述。而 arXiv:2501.16241 甚至在 Transformer 中识别出了物理学中 O(N) 自旋模型的对应物。
大模型"越来越大时突然获得新能力"这个现象(也就是所谓的涌现),也被用类似的相变框架来分析。虽然 Stanford 的 Schaeffer et al.(NeurIPS 2023)论证了部分涌现是度量选择造成的假象,但 ICLR 2025 的研究从 next-token 分布中检测到了真实的相结构。当前的共识是:单步能力的提升是平滑的,但需要多步配合才能完成的复杂任务确实存在"临界点"。
In-Context Learning:Transformer 在推理时偷偷做梯度下降
这是我个人觉得整个大模型理论里最让人拍案叫绝的发现。
你给 ChatGPT 几个示例,它就能学会一个新任务,不需要重新训练。这叫 In-Context Learning(ICL,上下文学习)。但它是怎么做到的?
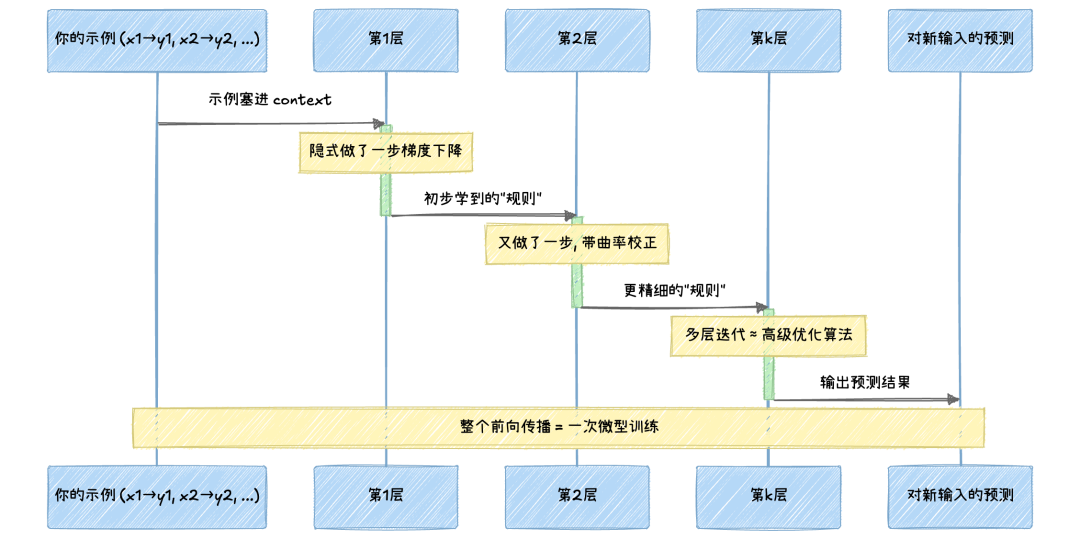
Google Research 的 Von Oswald et al.(ICML 2023)证明了一个让人目瞪口呆的结论:Transformer 的前向传播过程,在数学上等价于在做梯度下降。 你以为你只是在跑推理?其实模型在内部偷偷跑了一个"微型训练过程"。
说得更具体一点:单层注意力的前向传播,等价于用你给的示例做了一步梯度下降。多层 Transformer 就是做了多步。而且不只是普通的梯度下降,Bai et al.(NeurIPS 2023, Salesforce/UC Berkeley)证明它还能根据输入数据的特征自动选择不同的优化算法:有时候做 Ridge 回归,有时候做 Lasso,有时候做普通最小二乘。
2025 年这个方向进展飞快。Princeton 团队证明了 ICL 具有通用近似能力,ICLR 2025 证明深层 Transformer 是连续上下文映射的通用近似器。换句话说,只要层数够深、示例够多,Transformer 理论上可以在推理时学会任何函数。
更绝的是 Daneshmand et al.(ICLR 2025)的发现:机器翻译中的注意力权重,在数学上逐步逼近的是词嵌入之间的最优传输映射。最优传输理论是 18 世纪 Monge 提出的"怎么最省力地搬一堆土"问题的数学解,200 多年后被发现藏在 Transformer 的注意力矩阵里。
可解释性:用数学把黑箱撬开
最后说一个跟实际应用最相关的方向。大模型是黑箱,但数学正在把这个箱子撬开。
Anthropic 在 2022 年提出了超位假说(Superposition Hypothesis):模型的隐藏层维度不够用,所以不同的概念被"叠加"存储在同一组神经元里。打个比方,你家只有 3 个抽屉但要存 100 件东西,怎么办?每个抽屉里混着放,需要的时候再分拣。数学上这之所以行得通,是因为高维空间有一个反直觉的性质:d 维空间可以容纳指数级多的"几乎正交"方向。 这是 Johnson-Lindenstrauss 引理的核心结论。
基于这个理论,稀疏自编码器(SAE) 被用来从模型中提取可解释的特征。核心思路很简单:找一组稀疏的方向,使得它们的线性组合能还原模型的内部表示。Anthropic 2025 年 3 月发布的 Circuit Tracing 是目前最前沿的工具:它能把模型对一个具体问题的推理过程,分解成一张可读的有向图,节点是可解释的特征(比如"这个词是地名""这句话在问因果关系"),边是特征之间的因果影响。
另一个让我印象深刻的工具是 Representation Engineering(Zou et al., 2023)。研究者发现大模型内部有一些"概念方向",比如"真实性"对应嵌入空间中的一个方向。沿着这个方向加一个控制向量,就能让模型变得更诚实或更不诚实。实验表明这个操作在 TruthfulQA 上把 LLaMA-2-13B 的准确率从 35.9% 拉到了 54.0%。背后的 线性表示假说说的是:高级概念在模型内部近似线性地编码。2026 年的 Lattice Representation Hypothesis 甚至把这个假说跟数学中的概念格(Concept Lattice) 统一了起来。
而拓扑数据分析(TDA)也杀了进来。HalluZig(2026)用一种叫 zigzag persistence 的拓扑工具追踪注意力矩阵在各层之间的"形状变化",发现幻觉生成时拓扑特征有显著异常。说白了就是用数学上的"形状指纹"来检测模型在不在胡说八道,而且只需要看前 70% 的层就够了。
回到开头的问题
大模型背后的数学,最让人惊叹的地方,其实不在于某一个公式有多复杂。而在于不同分支的数学在这里意外地连接起来了。RoPE 连接了工程和 Lie 代数,Grokking 连接了深度学习和统计物理的相变理论,ICL 连接了推理和优化理论,最优传输连接了 18 世纪的搬土问题和 2025 年的注意力机制。
KAN(Kolmogorov-Arnold Networks, ICLR 2025 Best Paper)是一个特别有象征意义的例子。Kolmogorov 和 Arnold 在 1957 年证明了一个纯数学定理:任何多元连续函数都可以表示为单变量函数的组合与加法。当时这个定理被认为"漂亮但没用"。67 年后,有人用它设计了一种全新的神经网络架构,在科学发现任务上表现优异,拿了 ICLR 2025 最佳论文。
我本科学化工的时候觉得线性代数没用,转行写 iOS 之后觉得抽象代数更没用。读研之后才慢慢理解,数学这东西的价值是非线性增长的,你永远不知道哪个看似没用的分支会在什么时候变成关键工具。
大模型理论最深刻的几个问题至今没有答案:为什么 Scaling Laws 是幂律?过参数化模型泛化的完整理论是什么?In-Context Learning 理论(基于线性注意力和合成任务)跟自然语言 ICL 之间的鸿沟何时弥合?这些问题的答案,大概率还是要从数学里找。
你看,67 年前 Kolmogorov 证明定理的时候不会想到 KAN,200 年前 Monge 研究搬土问题的时候不会想到 Transformer。数学就是这样,它不会过期,只是还没轮到它上场。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-14,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号