ESM3蛋白质语言模型cookbook(2)

ESM3蛋白质语言模型cookbook(2)

Tom2Code
发布于 2026-04-17 17:25:25
发布于 2026-04-17 17:25:25
上一张我们讲解了最基础的ESMProtein类:
ESM3蛋白质语言模型cookbook(1)
今天我们继续介绍第二章的内容:
使用ESM-C模型获取蛋白质的特征表达(embedding),进行一个简单蛋白质序列分类的任务。
所以我们提出两个问题,可以替大伙可以更好的理解今天本章的内容:
Question1.什么是ESM-C模型?上一张刚刚解释了ESM3模型,这一次的ESM-C模型又是什么?
Qustion2.什么是embedding表达?
好,那我们今天就开始围绕这些话题展开描述。
一.背景解答
ESM-C模型的全称是:ESM Cambrian ,yep, C for Cambrian
ESM Cambrian: Revealing the mysteries of proteins with unsupervised learning
这句话是ESM官网对ESM-C的解释,
翻译过来就是:
ESM寒武纪:用无监督学习揭示蛋白质的奥秘
yep,寒武纪大模型,所以这是一个很powerful的蛋白质模型。
ESM-C(寒武纪)是他们的旗舰ESM3生成模型的平行模型家族。
ESM3专注于可控的蛋白质生成,而ESM C专注于创建蛋白质潜在生物学的表示。

ESM官网对ESM-C模型的介绍
所以大家可以理解成ESM-C模型就是一个特征提取模型。
接下来是对第二个问题的解答,什么是embedding?
在自然语言处理中,embedding(嵌入)是一种将文字(如单词、句子)转换为数字向量的方式。因为计算机无法直接理解“词”的含义,我们需要把词转换成它能处理的数字形式。Embedding 的意义在于,它不仅仅是简单地编号每个词,而是通过学习让语义相近的词在向量空间中更接近。比如,“猫”和“狗”的向量距离会比“猫”和“汽车”更近。
这种表示方式的好处是,它能让模型更好地理解语言中的上下文关系、语义相似性和词语之间的复杂联系,是现代语言模型(如BERT、GPT)的基础。
所以我们这次将会通过ESM-C蛋白质语言模型去提取蛋白质序列的embedding表示也就是用特征向量来表示蛋白质序列。
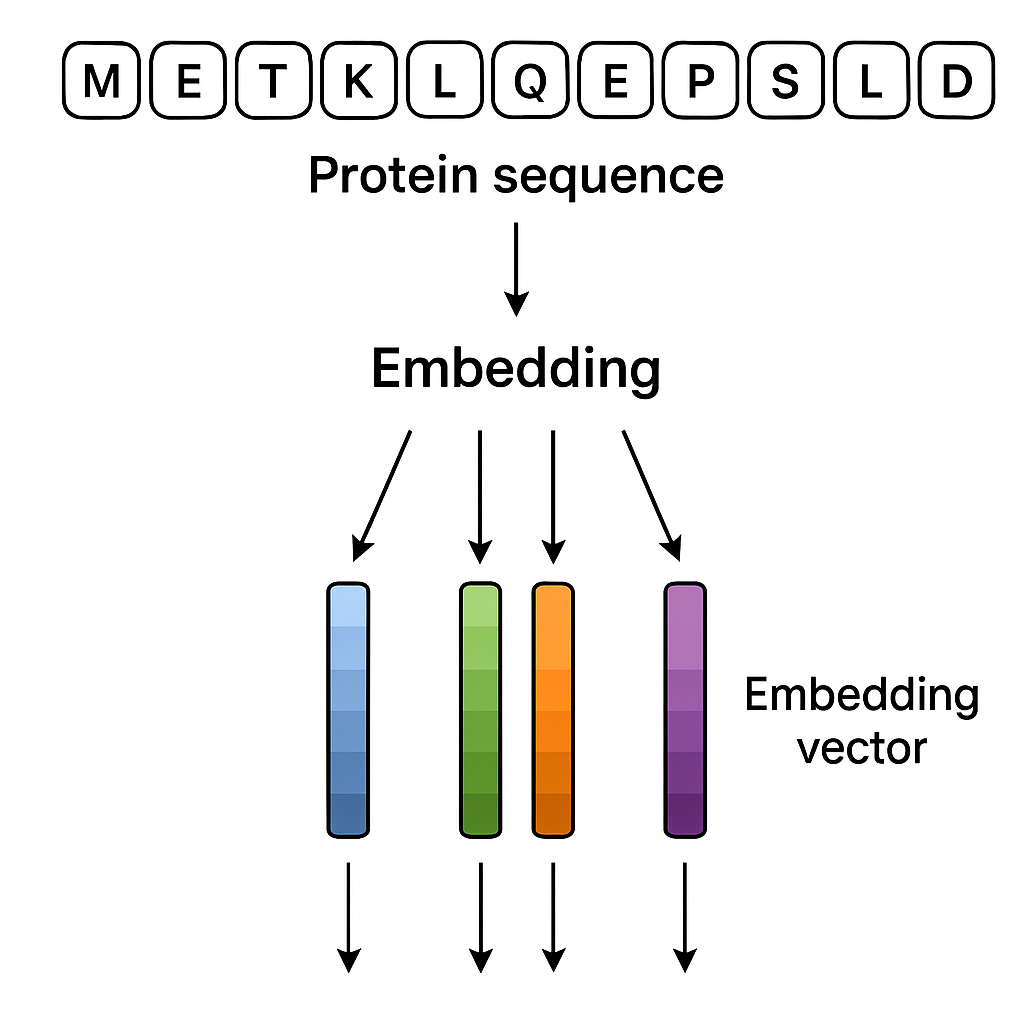
蛋白质序列的embedding表示
二.依赖安装
接下来直接开始进入正题,我们安装本次代码所需要的依赖:
! pip install esm
! pip install matplotlib三.数据集介绍
本次使用的数据集取自Muir等人2024年的"Evolutionary-Scale Enzymology Enables Biochemical Constant Prediction Across a Multi-Peaked Catalytic Landscape"(https://www.biorxiv.org/content/10.1101/2024.10.23.619915v1),该数据集探索了一种名为腺苷酸激酶(ADK)的模型酶。腺苷酸激酶出现在许多不同结构类别的生物体中(称为“lid type”)。我们将对这组 ADK 序列进行 embedding(嵌入),看看是否能够还原出已知的结构类别。
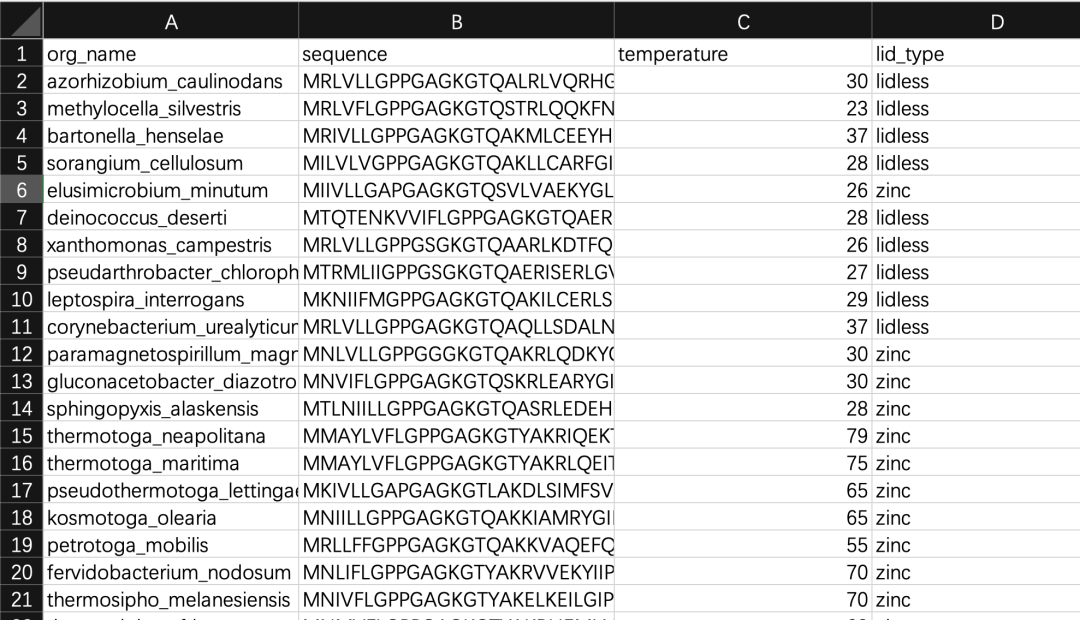
数据集部分展示

数据集的生物学背景意义
所以我们希望通过将蛋白质序列通过ESM-C模型得到每一条序列的embedding表示,然后看看是否可以对这些特征向量进行分类从而达到对lid type的分类。
四.上代码(上刺刀)
4.1申请ESM的api key
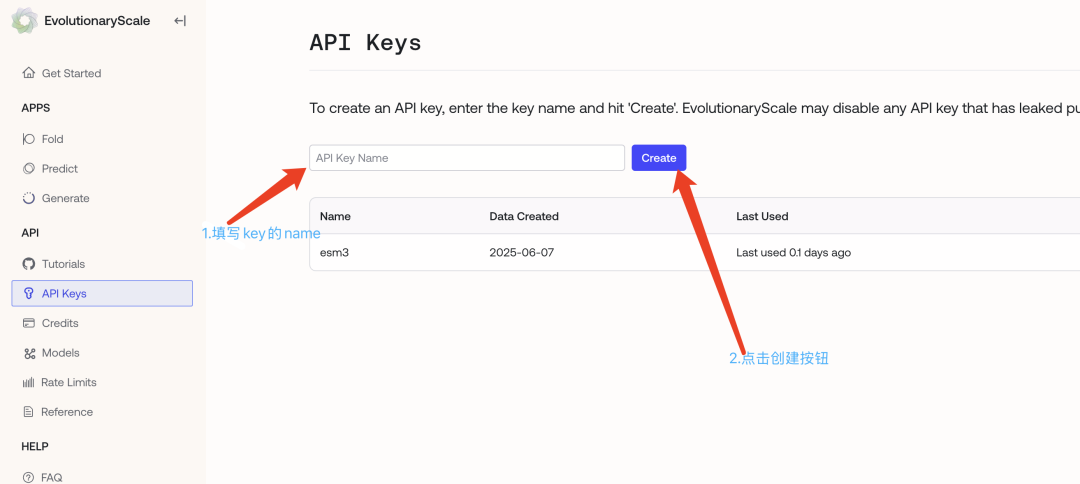
https://forge.evolutionaryscale.ai/apikeys
这个apikey我们一会会在程序中使用
4.2在程序中设置api key
from getpass import getpass
token = getpass("Token from Forge console: ")
当运行这行代码的时候会在这里弹出一个对话框,然后输入我们刚才申请的api key即可完成ESM apikey的配置。
4.3加载模型
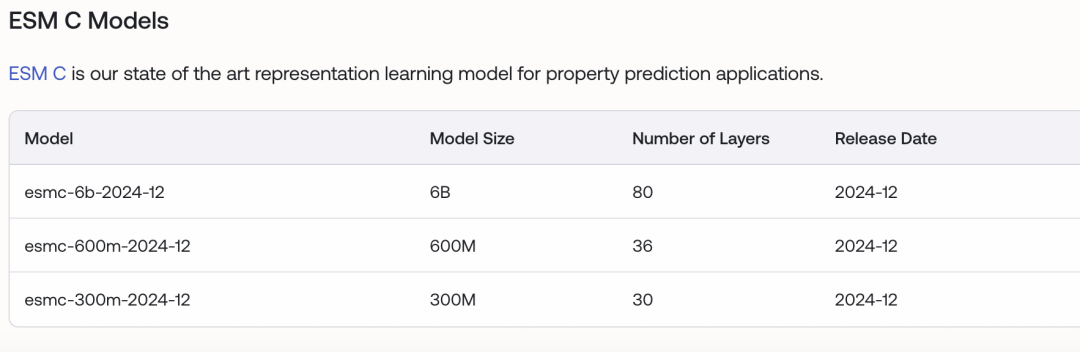
我们将使用ESM的sdk进行模型的加载,加载esmc-300m-2024-12
from esm.sdk import client
model = client(
model="esmc-300m-2024-12", url="https://forge.evolutionaryscale.ai", token=token
)下图展示了可加载的ESMC模型的列表
4.3获取embedding特征向量
由于我们嵌入了多个序列,我们将使用线程异步调用Forge,让Forge负责后端的批处理和并行化。
from concurrent.futures import ThreadPoolExecutor
from typing import Sequence
from esm.sdk.api import (
ESM3InferenceClient,
ESMProtein,
ESMProteinError,
LogitsConfig,
LogitsOutput,
ProteinType,
)
EMBEDDING_CONFIG = LogitsConfig(
sequence=True, return_embeddings=True, return_hidden_states=True
)
def embed_sequence(model: ESM3InferenceClient, sequence: str) -> LogitsOutput:
protein = ESMProtein(sequence=sequence)
protein_tensor = model.encode(protein)
output = model.logits(protein_tensor, EMBEDDING_CONFIG)
return output
def batch_embed(
model: ESM3InferenceClient, inputs: Sequence[ProteinType]
) -> Sequence[LogitsOutput]:
"""Forge supports auto-batching. So batch_embed() is as simple as running a collection
of embed calls in parallel using asyncio.
"""
with ThreadPoolExecutor() as executor:
futures = [
executor.submit(embed_sequence, model, protein) for protein in inputs
]
results = []
for future in futures:
try:
results.append(future.result())
except Exception as e:
results.append(ESMProteinError(500, str(e)))
return results然后进一步对数据进行加载和清洗:
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
adk_path = "adk.csv"
df = pd.read_csv(adk_path)
df = df[["org_name", "sequence", "lid_type", "temperature"]]
df = df[df["lid_type"] != "other"] 然后获取其embedding 特征向量
outputs = batch_embed(model, df["sequence"].tolist())接下来我们对特征向量进行处理,将每条序列在“氨基酸序列维度”上做平均
import torch
all_mean_embeddings = [
torch.mean(output.hidden_states, dim=-2).squeeze() for output in outputs
]
# now we have a list of tensors of [num_layers, hidden_size]
print("embedding shape [num_layers, hidden_size]:", all_mean_embeddings[0].shape)为什么要这么做呢?
举个例子:

那么得到的embedding张量则是:

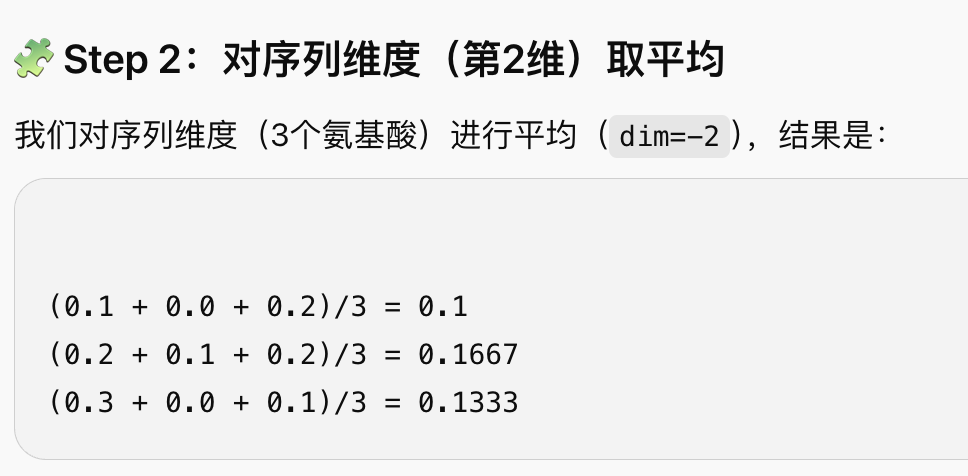
得到最新的向量
[0.1, 0.1667, 0.1333]
这样做的好处是:
- 原来有 3 个向量(每个氨基酸一个)→ 现在变成了 1 个向量
- 原来知道“R 是中间的氨基酸”,现在这个顺序信息没了
- 原来序列长度是 3,现在你无法从平均后的向量中看出长度
4.4 可视化结果
接下来我们将通过esmc-300m-2024-12这个模型的不同层去获取特征向量,然后观察这些特征向量是否可以直接进行精准的分类。
from sklearn.cluster import KMeans
from sklearn.decomposition import PCA
from sklearn.metrics import adjusted_rand_score
N_KMEANS_CLUSTERS = 3接下来构建一个完整的画图类:
这个方法它首先提取每条序列在指定层的embedding向量,对这些高维向量使用PCA降维到二维以便可视化;
然后通过K-Means聚类并计算Rand Index来衡量聚类结果与真实类别(如lid type)的吻合程度;
最后绘制一个二维散点图,其中点的颜色表示真实类别,用于观察该层的embedding是否能够有效区分不同结构类型的蛋白质。
def plot_embeddings_at_layer(all_mean_embeddings: torch.Tensor, layer_idx: int):
stacked_mean_embeddings = torch.stack(
[embedding[layer_idx, :] for embedding in all_mean_embeddings]
).numpy()
# project all the embeddings to 2D using PCA
pca = PCA(n_components=2)
pca.fit(stacked_mean_embeddings)
projected_mean_embeddings = pca.transform(stacked_mean_embeddings)
# compute kmeans purity as a measure of how good the clustering is
kmeans = KMeans(n_clusters=N_KMEANS_CLUSTERS, random_state=0).fit(
projected_mean_embeddings
)
rand_index = adjusted_rand_score(df["lid_type"], kmeans.labels_)
# plot the clusters
plt.figure(figsize=(4, 4))
sns.scatterplot(
x=projected_mean_embeddings[:, 0],
y=projected_mean_embeddings[:, 1],
hue=df["lid_type"],
)
plt.title(
f"PCA of mean embeddings at layer {layer_idx}.\nRand index: {rand_index:.2f}"
)
plt.xlabel("PC 1")
plt.ylabel("PC 2")
plt.show()然后我们使用第28层和第7层的特征向量进行分类(因为esmc-300m-2024-12模型一共有30层,读者可以自行测试不同层的效果):
plot_embeddings_at_layer(all_mean_embeddings, layer_idx=28)
plot_embeddings_at_layer(all_mean_embeddings, layer_idx=7)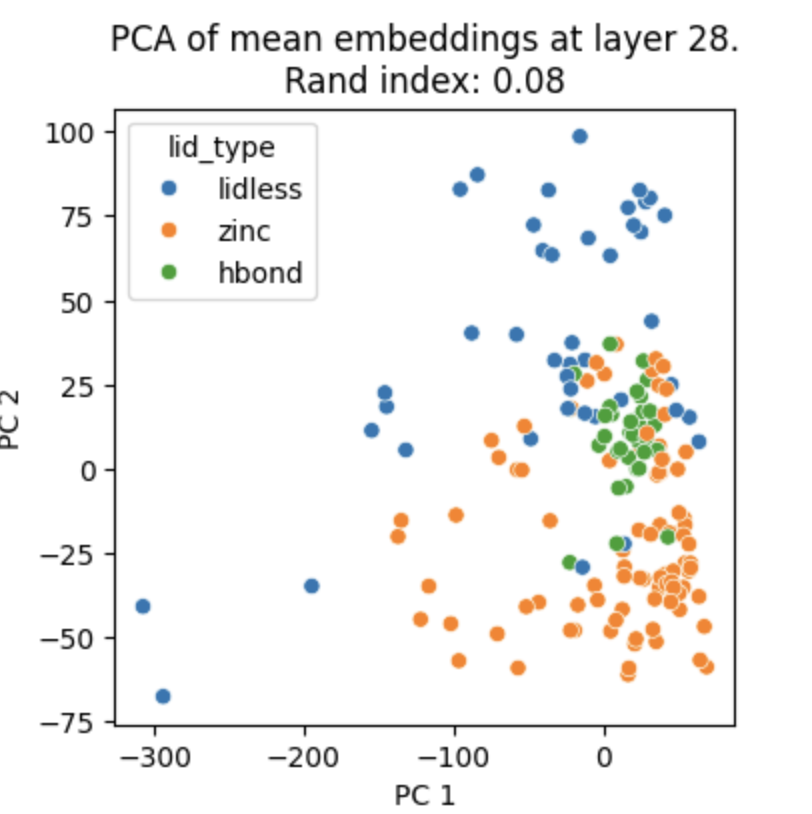
上图是使用第28层进行特征提取后的区分度。
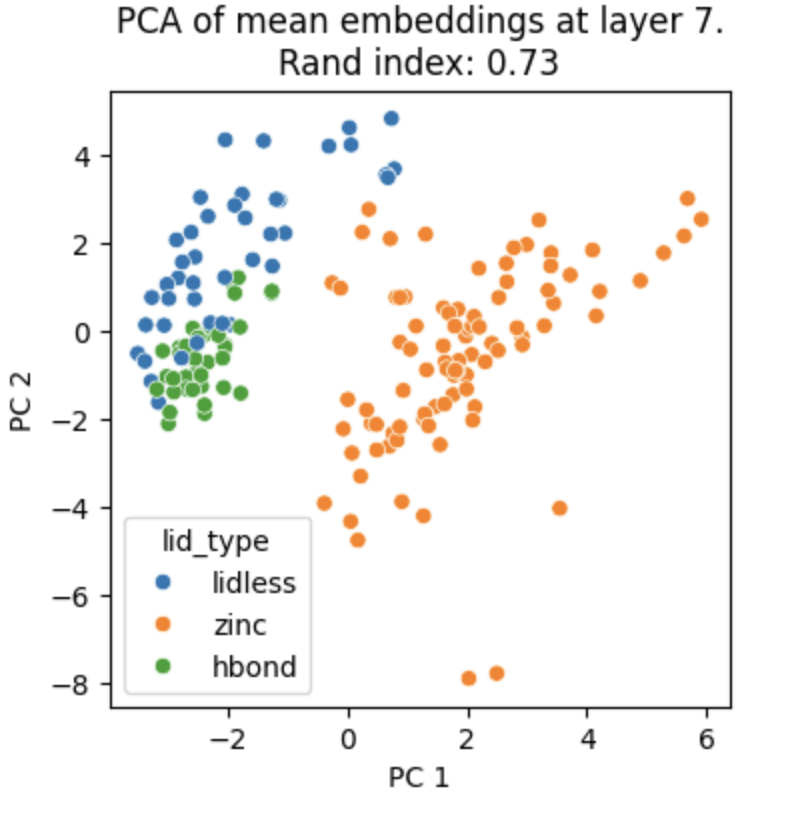
上图是使用第七层的embedding进行分类的效果,可以看到当汤姆使用第七层进行蛋白质序列的特征向量的提取之后,然后对向量进行降维,直接映射在2D pca的散点图就可以明显区分出来lid_type为zinc,lidless和hbond的类别。
当然读者也可以进行后续的研究,例如衔接一个神经网络即可完成蛋白质的lid_type分类任务,that's it!大家集思广益,今天的分享就到这里咯,大家的点赞和在看是我创作的动力,谢谢各位大佬捧场~
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-06-07,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号