主动推理的混合学习-优化范式

主动推理的混合学习-优化范式

CreateAMind
发布于 2026-04-03 09:07:02
发布于 2026-04-03 09:07:02
实用好奇心:一种基于主动推理的混合学习优化范式
Pragmatic Curiosity:A Hybrid Learning-Optimization Paradigm via Active Inference
https://arxiv.org/abs/2602.06104

摘要
许多工程和科学工作流程依赖于昂贵的黑盒评估,要求决策能够同时提高性能并减少不确定性。贝叶斯优化(BO)和贝叶斯实验设计(BED)提供了强大但基本分离的目标寻求与信息寻求处理方式,对于学习与优化内在耦合的混合场景,它们提供的指导有限。我们提出了实用好奇心(pragmatic curiosity),这是一种源自主动推断的混合学习 - 优化范式,其中动作通过最小化期望自由能来选择——这是一个将实用效用与认知信息增益耦合的单一目标。我们在各种现实世界混合任务上展示了实用好奇心的实际有效性和灵活性,包括约束系统辨识、目标主动搜索以及具有未知偏好的复合优化。在这些基准测试中,实用好奇心持续优于强大的 BO 型和 BED 型基线,实现了更高的估计精度、更好的关键区域覆盖以及改进的最终解质量。
1. 引言
工程和科学应用通常依赖于昂贵的黑盒评估,以识别高性能设计或理想的系统状态。当主要目标是达到指定目标时,贝叶斯优化(BO)加速了这一过程(Shahriari 等人,2016;Frazier,2018),而贝叶斯实验设计(BED)则优先获取关于未知系统参数的信息(Rainforth 等人,2023)。两种方法都利用概率模型和采集准则,量化评估未知配置的效用,针对优化或学习目标量身定制。尽管它们各自取得了成功且各领域研究爆炸式增长,但它们的脱节为一大类混合问题造成了真空,这些问题通常需要同步寻求知识和实现目标。
对于许多现实世界应用,如目标导向规划(Lookman 等人,2019)、环境监测(Konakovic Lukovic 等人,2020)和针对性材料设计(Matsumoto 等人,2025),学习和优化不是独立的阶段,而是深度交织的目标。这一挑战根本性地出现在具有日益复杂性的任务中,就认知考虑(即从参数模型到非参数模型)和实用评估(即从已知目标到未知目标)而言:(1) 约束系统辨识,其中精确学习系统参数的认知愿望受限于将实验保持在安全或有效操作范围内的实用需求(例如,避免传感器饱和或危险化学反应)。此类任务可见于众多应用,包括环境监测(Konakovic Lukovic 等人,2020)和催化剂设计(Zhong 等人,2020)。(2) 目标主动搜索,其中发现符合特定标准区域(例如,系统故障模式或特定性能范围)的实用目标需要认知好奇心来探索区域的形状、大小和边界。应用示例可见于故障发现(Ramanagopal 等人,2018)和医疗监控(Malkomes 等人,2021)。(3) 复合贝叶斯优化,其中实用目标是根据用户的隐藏偏好找到最优设计——这是一项如果不首先对用户目标本身产生认知好奇心就不可能完成的任务。此类场景常见于基于模拟的设计(González & Zavala,2025;Coelho 等人,2025)和 A/B 测试(Bakshy 等人,2018)。
传统上,为解决这些混合问题,从业者被迫在专用工具之间选择,并通过利用信息增益准则来增强优化(反之亦然)以适应特定问题的调整。在 BO 方面,Russo & Van Roy(2018)将信息导向采样(IDS)提出用于在线优化问题。Hvarfner 等人(2023)将基于统计距离的主动学习(SAL)准则引入 BO 循环,即使在搜索最优解时也主动学习模型超参数。在 BED(也称为贝叶斯主动学习,BAL)方面,Smith 等人(2023)提出了预期预测信息增益(EPIG)准则,专注于模型预测中的信息增益,通过考虑输入数据分布,减轻了经典 BAL 选择分布外或低相关性查询的倾向。这些方法突显了优化与学习之间日益增长的协同作用,但它们仍然是特定于任务的,且很少跨类别泛化。
在本文中,我们提出实用好奇心:一种源自主动推断(AIF)(Friston,2010;Friston 等人,2017)的混合学习 - 优化范式。AIF 通过最小化期望自由能(EFE)规定动作选择,这是一个单一目标,结合了 (i) 偏好首选结果的实用项和 (ii) 偏好信息增益的认知项。我们证明 EFE 最小化提供了各种采集策略的统一视角:通过指定偏好、观测模型和近似,所得准则将 BO 类和 BED 类行为作为极限机制恢复。
在此范式下,寻求知识和实现目标不被视为竞争目标,而是最小化 EFE 这一单一指令的两个不可分割的方面。这两种驱动力由一个称为好奇心的系数平衡,该系数设定了学习与优化之间的权衡。好奇心在保证自洽学习(即后验收敛于真理)和无遗憾优化(即具有有界累积遗憾)方面的正式作用在 Li 等人(2026)中提供了理论支持。本文转而展示该范式在处理广泛一类复杂混合问题上的实际有效性和灵活性,这些问题常被标准方法忽略,包括具有演化目标(条件随时间变化)和隐式目标(目标未先验定义)的任务。我们围绕上述三类问题结构进行实验,借鉴的应用包括羽流场中的环境监测(Konakovic Lukovic 等人,2020)、自动驾驶场景中的故障检测(Ramanagopal 等人,2018)和电网中的分布式能源资源分配(Kianmehr 等人,2019)。
实证结果揭示了一贯的优越性能模式,表明我们的框架在解决复杂混合目标方面具有优势。在约束系统辨识任务中,我们的算法实现了近乎完美的估计精度,同时所需的查询次数比其他方法少高达 40%。对于目标主动搜索任务,它展示了一种更有效的探索策略,在相同预算内多发现了关键失败区域中至关重要的 10%。最值得注意的是,在具有未知用户偏好的任务中,我们的方法总是成功学习了潜在目标,而其他基线方法则未能捕捉到。总之,这些发现验证了我们统一方法的强大效力,表明实用驱动力与认知驱动力之间的原则性平衡能够在多样且具有挑战性的问题设置中带来实质性的收益。
综上所述,我们的主要贡献如下:
• 通过主动推断的视角,对各种采集策略提供了统一的观点。
• 提出了一种针对通用混合学习 - 优化问题的实用好奇心范式。
• 在三个具有多样混合学习 - 优化目标的典型现实世界问题类别上进行了全面的实证验证。
2. 预备知识
2.1. 贝叶斯优化



2.2. 贝叶斯实验设计


3. 采集策略的统一视角
BO 中的采集策略通常导致目标导向的行为,其中(隐式的)目标是某个(未知)目标函数的最优值。相反,BED 中的采集策略鼓励信息寻求行为,旨在收集关于某些感兴趣参数的最大信息量。尽管两者都可以被视为自适应采样(Di Fiore 等人,2023)的实现,但由于指令不同(Hvarfner 等人,2025),这两个领域之间不存在可迁移的方法。
在本节中,我们表明这两个看似竞争的指令可以通过主动推断(AIF)的原则自然地平衡。
3.1. 作为期望自由能最小化的主动推断
我们指定一个概率代理模型 q(⋅) 来捕捉结果 y 与决策变量 x 基于一组感兴趣参数 s 之间的关系,该关系分解为
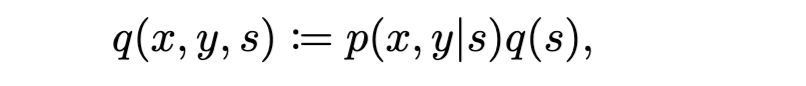

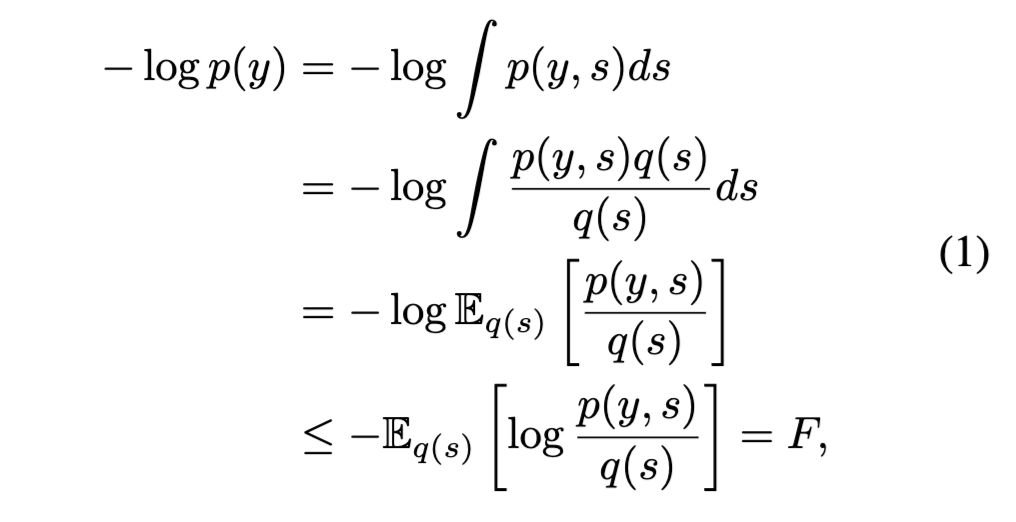
其中最后一个不等式遵循琴生不等式(Jensen's inequality),该不等式指出对数的期望总是小于或等于期望的对数。
公式 (1) 的右边被称为变分自由能(VFE),其名称源于 FF 类似于物理学中的亥姆霍兹自由能这一事实。我们可以看到 VFE 总是大于或等于惊异(即,它是惊异的上界)。在机器学习中,VFE 的符号通常被反转,使其成为证据下界(ELBO)。最大化 ELBO 是机器学习中常用的一种优化方法(Titsias, 2009)。
为了制定决策策略,我们需要考虑决策变量 x 以及由动作选择导致的结果。由于未来结果尚未发生,我们转而考察基于预测分布 q(y∣x) 的预测结果上的惊异期望:
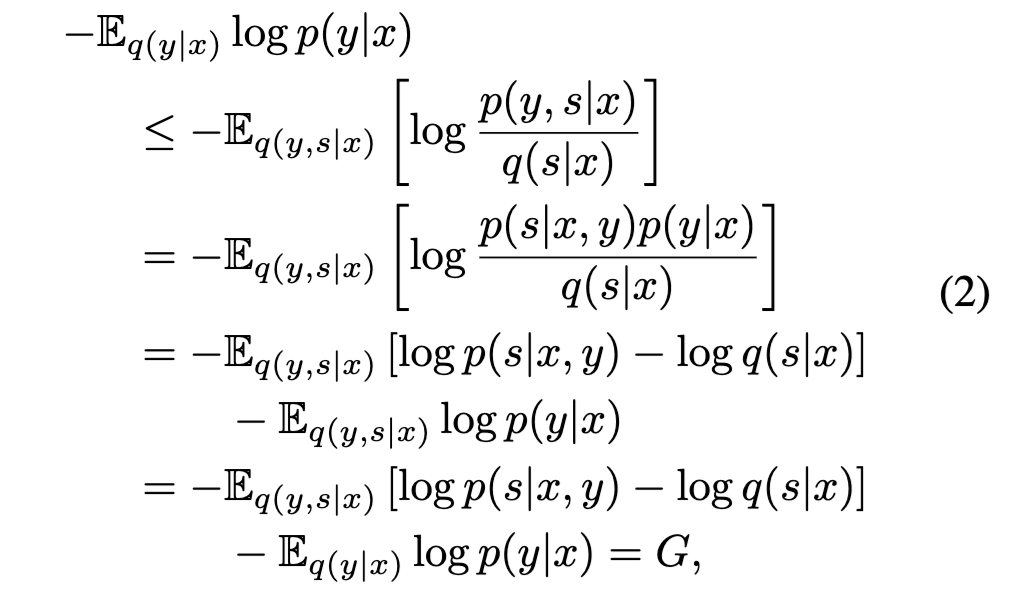
其中公式 (2) 的右侧记为期望自由能(EFE)。

我们可以看到,通过构造,EFE 在某些先验偏好下平衡了信息寻求和目标导向行为。它界定了认知价值(关于参数)与实用价值(关于结果)之间的差异,这捕捉到了在与环境交互时最大化认知价值(即关于潜在状态的信息增益)的指令,同时关于先验偏好最大化实用价值(即期望偏好对齐)。AIF 的这一关键方面有效地解决了“探索 - 利用困境”,因为探索和利用的指令只是 EFE 的两个方面:
实用价值(利用):这一项通过偏好预期能产生首选结果的动作来鼓励目标导向行为。它由对期望观测的先验分布编码,其功能类似于强化学习中的效用或奖励函数(Millidge 等人,2020),驱动智能体利用其当前知识来实现其目标。
认知价值(探索):这一项通过偏好预期能最大程度减少关于底层系统不确定性的动作来促进信息寻求行为。它量化了关于模型参数的期望信息增益,驱动智能体探索环境以完善其世界模型。
3.2. BO 和 BED 中采集策略的重新诠释
至关重要的是,最小化 EFE 作为一个统一的 umbrella 原则。BO 和 BED 中的许多经典采集策略可以重新诠释为最小化 EFE 的特例,如表 1 所示。
表 1 中大多数采集策略的重新诠释根据其定义是直截了当的。然而,将相当直观的 GP-UCB 策略置于该框架中似乎较为隐式。为了揭示它们之间的联系,我们依赖于以下引理:
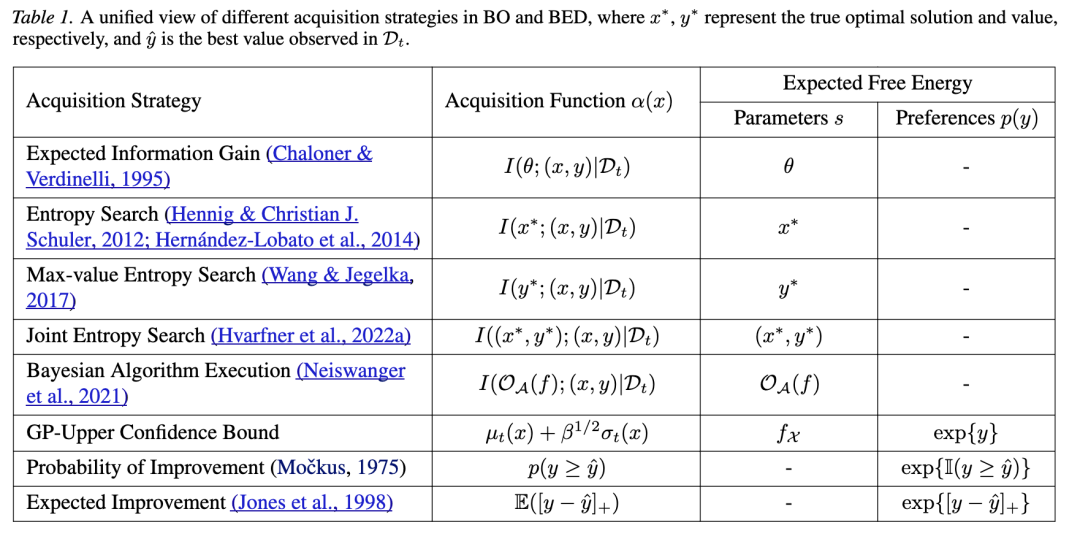

这揭示了 GP-UCB 与 AIF 之间的紧密联系,表明即使是像 GP-UCB 这样看似纯粹直观的策略,其背后也有着相当严谨的数学基础。
4. 推导采集函数的新范式
表 1 中的偏好分布 p(y) 可以解释为针对结果的时变价值函数的 softmax 变换。从这一观察推广开来,我们提出了一种推导采集函数的新范式,该范式适用于除传统 BO 和 BED 之外更广泛的一类混合问题。

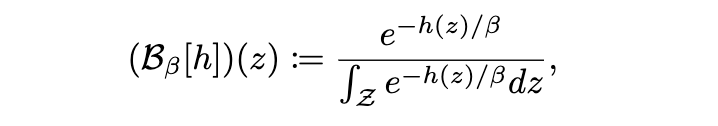



好奇心 βt 在平衡学习与优化的性能方面起着重要作用。Li 等人 (2026) 推导出了在充分好奇心条件下后验一致性和有界累积遗憾的形式化理论保证,并提供了在不同设置中选择 βt的实用设计指南。
本文转而考察问题依赖的能量函数 h(y∣Dt) 如何提供一种灵活的机制,以显式地表示关于目标本身的不确定性。这种增强的表达能力使得能够为标准方法经常忽略的一大类复杂设置进行采集设计,包括具有演化目标(条件随时间变化)和隐式目标(未先验指定)的任务。这种公式化在此类任务上的有效性和通用性将在下一节中展示。
5. 实验
在本节中,我们通过跨三个彼此显著不同的类别进行实验,来举例说明所提出的采集策略的优势和可变性。这些问题源于 BO 和 BED 领域内不同的文献,且它们都不是典型的 BO 或 BED 任务。因此,每一个任务都针对适合该特定任务的一组不同的 BO 型(专注于优化)和 BED 型(专注于学习)基线进行评估,以确保公平且严谨的比较。
5.1. 具有已知不变目标的参数模型

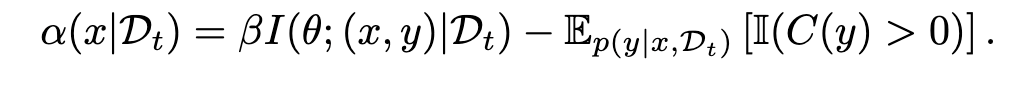
任务。 我们在二维羽流场(2D plume fields)中的现实环境监测问题上进行实验,其中传感器具有饱和阈值
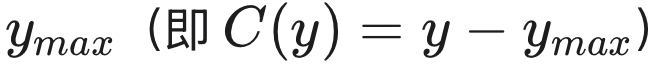
(详细设置和超参数选择见附录 D.2)。我们考虑三种类型的监测任务:(a) 定位未知源位置;(b) 估计未知风向和强度;以及 (c) 识别多源场中的活跃源。
基线方法。 我们将我们提出的采集策略(AIF)与针对此任务定制的 BO 型和 BED 型基线方法进行比较:(a) 随机(Random);(b) 通过选择导致违反约束概率最小的点来进行贪婪选择(BO 型);以及 (c) 关于未知参数的期望信息增益(EIG,BED 型)。
评估。 我们从认知和实用两个角度评估性能:(a) 估计精度;以及 (b) 约束违反情况。
结果。 图 1 显示,我们的方法在遵守所有操作约束的同时,比基线方法实现了持续更强的查询效率,且累积约束违反始终为零。这一优势在源定位任务中尤为明显,在该任务中,获取信息的驱动力与满足约束的需求产生了相互对立的压力。通过解决这一冲突,我们的方法使用的查询次数比竞争方法少高达 40%,达到了近乎完美的估计。
5.2. 具有已知演化目标的非参数模型
接下来,我们考虑一个更具挑战性的设定,其中任务条件会演化,且模型完全是黑盒的,以至于我们需要诉诸于非参数模型(例如,高斯过程 GP)。一个这样的例子是多目标设计问题中的目标主动搜索。目标被视为度量指标,其中特定范围具有特殊意义,而目标是设计实验以最大化这些重要区域 S 的覆盖率。

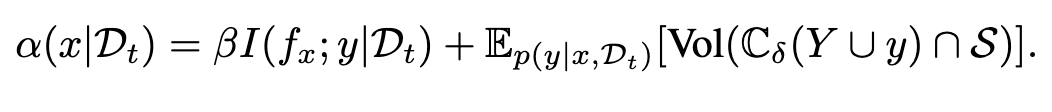
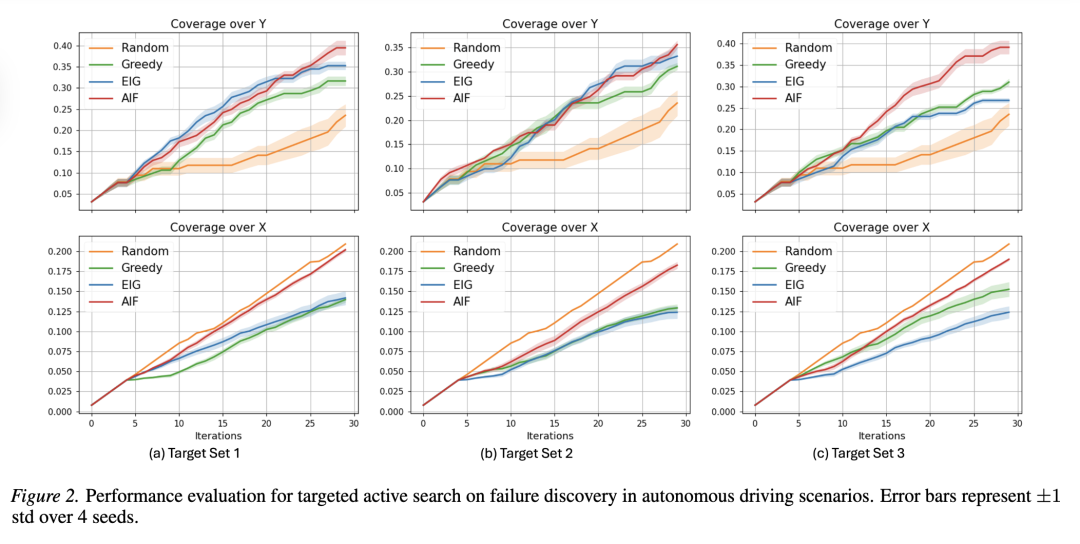
任务。 我们在自动驾驶场景中的现实故障发现问题上进行实验,其中感知模块(一个 YOLO 检测器)可能因多种原因失效,这潜在地可能导致碰撞(3D 输入-2D 输出)。我们考虑三个体积递减的目标集,即目标集 1 ⊃ 目标集 2 ⊃ 目标集 3(详细设置和超参数选择见附录 D.3)。
基线方法。 我们再次将我们提出的采集策略(AIF)与针对此任务定制的 BO 型和 BED 型基线方法进行比较:(a) 随机(Random);(b) 通过最大化度量空间中的覆盖体积来进行贪婪选择(BO 型);以及 (c) 通过最大化参数空间中的覆盖体积来进行期望信息增益(EIG,BED 型)。

结果。 如图 2 所示,我们的 AIF 算法有效地平衡了参数空间和度量空间的覆盖。这种能力对于搜索更为困难的较小目标集尤其具有显著影响。在最具有挑战性的情况(目标集 3)下,与领先的基线方法相比,我们的方法识别出了近 10% 更多的关键故障区域。
5.3. 具有未知目标的非参数模型
最后,我们要研究最困难的设定,即模型和目标都是黑盒的。
一个实际场景源于多目标优化问题中的复合贝叶斯优化。目标由一个偏好函数 g(y) 进行加权,该函数是先验未知的,并且必须在优化过程中被同时学习。


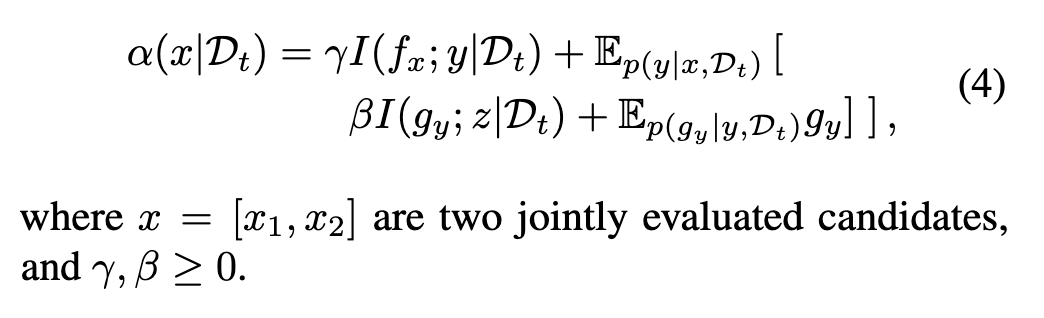
任务。 我们在三个现实世界问题上进行实验,包括车辆安全(5 维输入 -3 维输出)、青霉素生产模拟器(7 维输入 -3 维输出)和电网中的分布式能源资源分配(40 维输入 -4 维输出)(详细设置和超参数选择见附录 D.4)。

评估。 我们通过使用真实偏好函数 g(y) 检查所有收集结果中的最佳偏好来评估它们的性能。
结果。 图 3 展示了我们的 AIF 方法在学习未知偏好函数方面的卓越能力,这是相对于常因查询方向不当而失败的基线方法的一个关键优势。随着任务变得更加复杂且噪声更大(从 (a) 到 (c)),我们的结果表明,采集函数 (4) 的每个组件在实现最优性能方面都发挥着不可替代的作用。这一优势在能源资源分配任务中最为显著,在该任务中,竞争方法未能捕捉到任何有意义的偏好模型,而我们的方法始终成功。
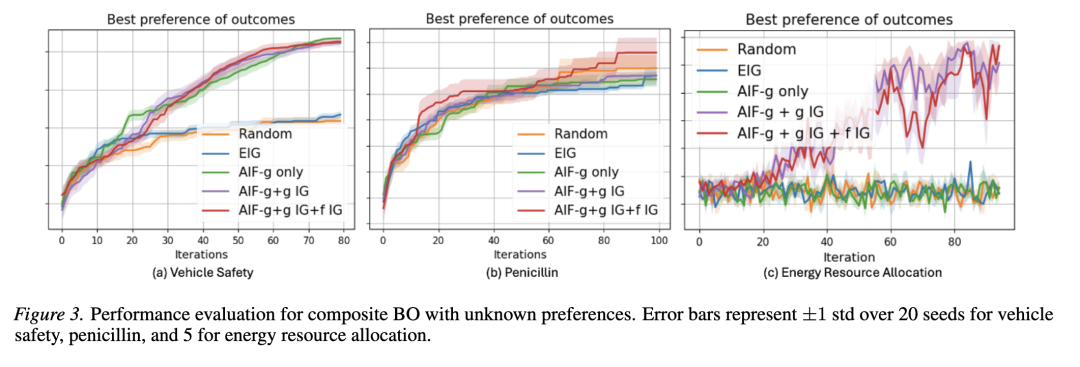
联合学习与优化的优势。 为了强调联合学习和优化而非将其分阶段进行的好处,我们将我们的方法与 Lin 等人 (2022) 中使用不同阶段设计选择的几种 BOPE 变体进行比较。详细的实验设置、设计选择、图表和分析见附录 D.4.3。结果表明,我们的方法在每一步自然地平衡探索与利用,并持续发现更高偏好的区域,而 BOPE 变体对阶段的配置方式高度敏感。因此,像 BOPE 这样的分阶段方法需要仔细手动调整这些选择,而我们的统一公式自动化了这一权衡,因此更适用于高阶分层模型。
6. 结论与局限性
我们提出了实用好奇心,这是一种基于 AIF 的范式,用于在昂贵黑盒评估下进行混合学习 - 优化。通过最小化 EFE 来选择动作,该方法在单一采集目标内统一了目标寻求和信息寻求。在约束系统辨识、目标主动搜索和具有未知偏好的复合优化中,实用好奇心始终优于强大的 BO 型和 BED 型基线,在固定预算下提高了估计精度、关键区域覆盖率和最终解质量。
我们方法的局限性源于问题依赖的能量/偏好模型的指定;错误指定可能会使采集产生偏差并降低性能。性能也继承了底层代理和观测模型的假设;严重的模型不匹配或非平稳性可能会损害不确定性量化和偏好诱导的指导。未来的工作包括将该范式的评估扩展到多智能体、长视野或多保真度设置。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-16,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号