YOLO-MARL:大语言模型驱动的多智能体强化学习一体化框架

YOLO-MARL:大语言模型驱动的多智能体强化学习一体化框架

一点人工一点智能
发布于 2025-07-31 14:33:35
发布于 2025-07-31 14:33:35
本文从摘要介绍到实验验证,系统剖析这一结合大语言模型(LLM)与多智能体强化学习(MARL)的创新框架。论文提出了一种名为YOLO-MARL的新方法,通过单次LLM交互生成高级规划函数,显著降低了传统方法中频繁调用LLM带来的计算开销,同时在多个测试环境中展现出优越性能。

论文地址:https://arxiv.org/pdf/2410.03997
项目地址:https://github.com/paulzyzy/YOLO-MARL

简介
论文开头指出现有多智能体强化学习(MARL)在协作游戏决策中的局限性,尤其是在稀疏奖励、动态环境和大动作空间任务中学习有效分布式策略方面面临的挑战。作者敏锐地把握了两个前沿领域的结合点:
一方面,MARL已成为解决复杂多智能体系统决策问题的重要框架;
另一方面,大语言模型(LLM)展现出令人瞩目的高级语义规划能力。
然而,由于LLM的模型规模,在训练过程中频繁调用LLM会产生高昂成本。针对这一关键问题,YOLO-MARL创新性地提出"单次LLM交互"框架,仅在策略生成、状态解释和规划函数生成模块需要与LLM交互一次,之后的MARL策略训练过程完全独立于LLM,从而大幅降低计算成本和通信开销。
引言系统梳理了MARL和LLM的研究现状与发展瓶颈。对于MARL,作者指出尽管QMIX、MADDPG等算法提出了集中训练分散执行的范式,但在稀疏奖励环境下学习完全协作策略仍存在困难。
关于LLM在强化学习中的应用,论文列举了ELLM等先驱工作,但也指出这些方法多数局限于单智能体场景或需要在训练过程中频繁与LLM交互。
YOLO-MARL的核心理念在于将LLM作为高级规划器而非直接决策者,通过一次性生成可重用的规划函数来指导后续MARL训练。这种方法既利用了LLM的通用推理能力,又避免了持续LLM交互带来的负担,在概念和实现上都具有显著创新性。
论文强调的三大优势构成了YOLO-MARL的核心价值主张:
一是通过LLM的广泛推理能力生成高级规划函数来增强策略学习;
二是最小化LLM参与带来的计算效率提升;
三是零样本提示(zero-shot prompting)提供的良好环境适应性。
这些优势在后续的方法描述和实验评估中得到了具体体现和验证。值得注意的是,作者特别指出框架的易用性——用户只需提供对环境的基本理解,这降低了领域专业知识门槛,增强了方法的普适性和实用价值。

相关工作评述
论文从三个维度系统梳理了相关研究工作,为YOLO-MARL的创新定位提供了清晰坐标系。在多智能体强化学习(MARL)方面,作者重点分析了QMIX、MADDPG和COMA等代表性算法。
QMIX采用单调值函数分解解决信用分配问题,MADDPG则基于Actor-Critic框架处理混合合作-竞争环境,而COMA通过反事实基线解决多智能体策略梯度估计问题。
然而,这些方法在稀疏奖励环境中表现受限,且鲜有研究探索LLM与MARL的结合,这为YOLO-MARL的研究提供了契机。
关于LLM用于强化学习和决策-making的研究,论文梳理了几种典型范式。一类工作如ELLM使用LLM建议探索目标来改善策略学习;另一类如SayCan通过预训练技能的价值函数将LLM生成的抽象指令落地为具体机器人动作。值得注意的是,Kwong等人探索了用LLM提供标量奖励来指导训练。
与这些方法相比,YOLO-MARL的差异化创新在于:不依赖LLM持续生成奖励或目标,而是利用其一次性生成规划函数,这种设计在保持LLM优势的同时规避了其频繁调用的成本。
第三部分探讨了LLM在多智能体系统中的应用。Camel和MetaGPT展示了多LLM代理在头脑风暴和软件开发中的潜力;SMART-LLM和CoNavGPT则分别研究了多机器人任务规划和协作导航中的LLM应用。
这些工作大多直接将LLM作为代理或决策者使用,而YOLO-MARL的创新在于将LLM定位为规划函数生成器,其生成的紧凑策略可通过传统MARL算法高效训练。这种分工既利用了LLM的通用知识,又发挥了MARL在特定任务策略优化上的优势。
相关工作的评述揭示了YOLO-MARL的独特定位:它既不同于纯MARL方法缺乏高级规划能力,也区别于直接使用LLM作为代理的方法存在效率瓶颈,而是创造性地找到了两者优势结合的平衡点。这种系统架构创新为多智能体协作决策提供了新思路,特别是在需要结合通用语义理解和专门策略优化的复杂场景中。

问题表述与理论基础
论文采用马尔可夫博弈(Markov Game)作为多智能体决策问题的形式化框架,这是多智能体强化学习领域的标准理论模型。马尔可夫博弈被定义为元组
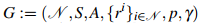
,其中N表示智能体集合,S和A分别代表联合状态空间和联合动作空间,rⁱ是每个智能体的奖励函数,p是状态转移概率,γ是折扣因子。在这一框架下,每个智能体i试图最大化其期望折扣回报
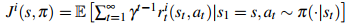
。对于合作博弈,通常考虑所有智能体共享同一奖励函数的情况,这也是YOLO-MARL研究的重点场景。
从理论角度看,论文解决的问题可以表述为:如何增强传统MARL算法在复杂合作环境中的策略学习能力,特别是面对稀疏奖励、大规模动作空间等挑战性场景。传统解决方案如集中式训练分散式执行(CTDE)虽然在一定程度上解决了信用分配问题,但在需要高级语义理解和长期规划的任务中仍显不足。YOLO-MARL的创新在于引入LLM作为外部知识源,通过生成高级规划函数来引导MARL训练,而不改变基本的马尔可夫博弈框架。
状态空间和动作空间的数学表述为后续方法设计奠定了基础。联合状态空间S=S¹×⋯×Sᴺ和联合动作空间A=A¹×⋯×Aᴺ的笛卡尔积结构反映了多智能体系统的分布式本质。值得注意的是,YOLO-MARL并不直接修改这些基本要素,而是通过引入额外的规划函数Fₜ(S₁)→Tᵢ∈T来增强学习信号,其中T={T₁,...,Tₙ}表示目标分配集合。这种设计保持了与传统MARL算法的兼容性,便于集成现有方法如QMIX、MADDPG等。
从马尔可夫决策过程的角度分析,YOLO-MARL实质上是为原始MDP引入了一个基于LLM的抽象层,将低级动作选择与高级任务规划分离。这种分层决策架构既符合人类处理复杂任务的方式,也顺应了近年来强化学习领域"分层RL"的发展趋势。不同的是,YOLO-MARL的分层结构不是通过长期训练获得,而是利用LLM的通用推理能力一次性生成,这大大提高了方法的效率和实用性。

YOLO-MARL方法论深度解析
YOLO-MARL框架包含四个核心模块:策略生成(Strategy Generation)、状态解释(State Interpretation)、规划函数生成(Planning Function Generation)和融合LLM生成规划的MARL训练过程。这种模块化设计体现了分而治之的系统工程思想,每个模块解决特定子问题,共同构成完整解决方案。

策略生成模块充当用户与环境之间的"翻译器",将基本环境描述转化为详细策略。如图1(a)所示,该模块接收任务描述、规则和约束等基本信息,输出结构化策略。这一设计的关键创新在于降低用户门槛——即使对环境了解有限,用户也能通过LLM的通用理解能力获得专业级策略建议。论文强调了该模块的三重价值:减轻用户负担、增强框架泛化能力、为后续规划函数生成奠定基础。消融研究(VI-A节)证实,缺少策略生成会导致规划函数质量显著下降,验证了该模块的必要性。
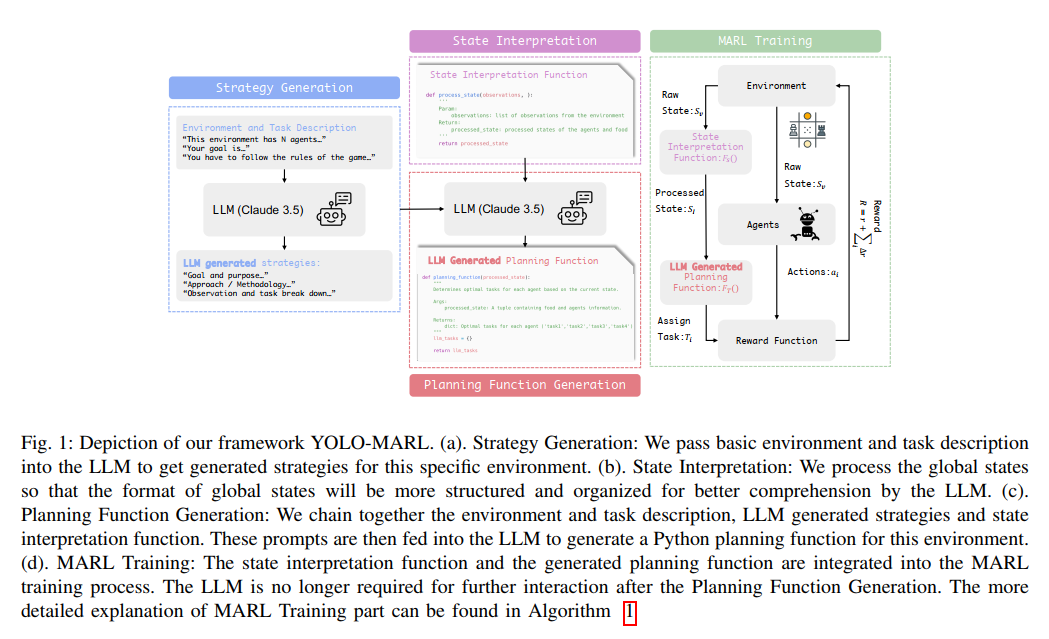
状态解释模块解决了原始环境状态表示与LLM理解能力之间的语义鸿沟。许多仿真环境(如MPE、LBF)以非语义的向量形式提供观测,虽然适合神经网络处理,却难以被LLM直接理解。状态解释函数Fₛ(Sᵥ)→S₁的引入实现了语义提升(semantic lifting),将低级状态向量转化为LLM可理解的描述。如图1(b)所示,该模块以Python环境代码形式实现,提供各状态组件的明确含义。论文指出,缺乏状态解释会导致LLM生成错误函数,这一观点在消融研究(VI-B节)中得到验证。状态解释模块的设计体现了YOLO-MARL的重要洞察:虽然LLM具有强大推理能力,但需要适当的信息呈现方式才能发挥最佳性能。
规划函数生成模块是整个框架的核心创新点,它综合前两个模块的输出,生成可直接用于MARL训练的高级规划函数。具体而言,对于处理后的状态S₁,规划函数Fₜ(S₁)→Tᵢ∈T为每个智能体分配目标任务Tᵢ。值得注意的是,目标任务空间T与原始动作空间A存在多对多关系——一个动作可对应多个目标(如"上移"可服务于不同地标),一个目标也可通过多个动作实现。这种灵活的映射关系保留了策略学习的自由度,同时提供了高级指导。如图1(c)所示,该模块仅需单次LLM交互即可生成适用于整个训练过程的规划函数,这是YOLO-MARL效率优势的关键所在。
MARL训练模块(图1(d))将生成的规划函数融入标准MARL流程。如算法1所示,框架通过修改奖励函数来整合规划函数的指导:当智能体动作aᵢ符合分配任务Tᵢ时给予额外奖励r',否则施加惩罚p'。最终奖励
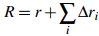
,其中r是环境原始奖励,Δrᵢ由规划函数决定。这种设计实现了双重学习信号的融合:环境提供的低级反馈和LLM生成的高级指导。公式(1)(2)清晰地表达了这一机制:

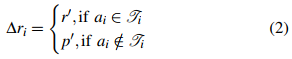
从算法角度看,YOLO-MARL的培训过程与传统MARL保持高度一致,只是奖励计算更加丰富。这种设计使得框架可以轻松兼容各种MARL算法(如QMIX、MADDPG、MAPPO),体现了良好的扩展性。论文特别强调,训练完成后,策略执行完全独立于LLM,这保证了部署阶段的效率,是区别于持续依赖LLM的其他方法的重要优势。

实验设计与结果分析
论文选取了Level-Based Foraging (LBF)和Multi-Agent Particle (MPE)两个环境进行系统评估,涵盖了稀疏奖励和密集奖励两种典型场景。实验设计体现了严谨的科学方法论:使用多个随机种子确保结果可靠性,比较三种主流MARL算法验证框架普适性,并采用环境原始奖励作为统一评估指标保证公平性。
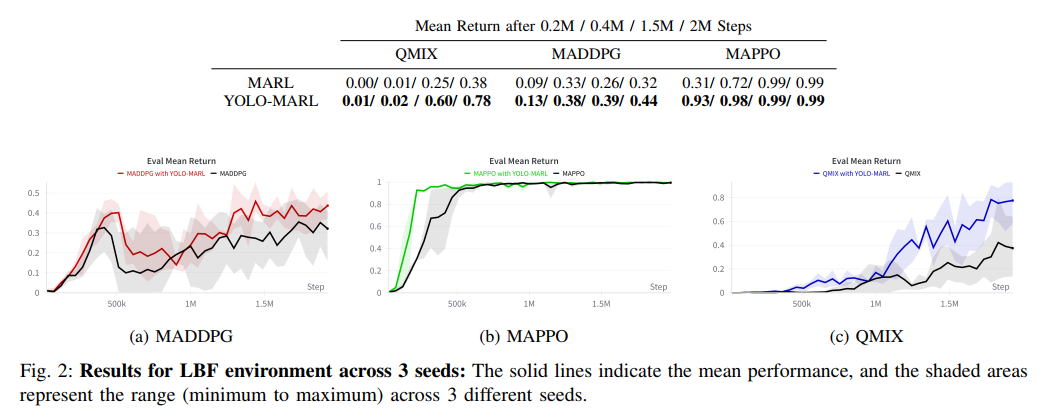
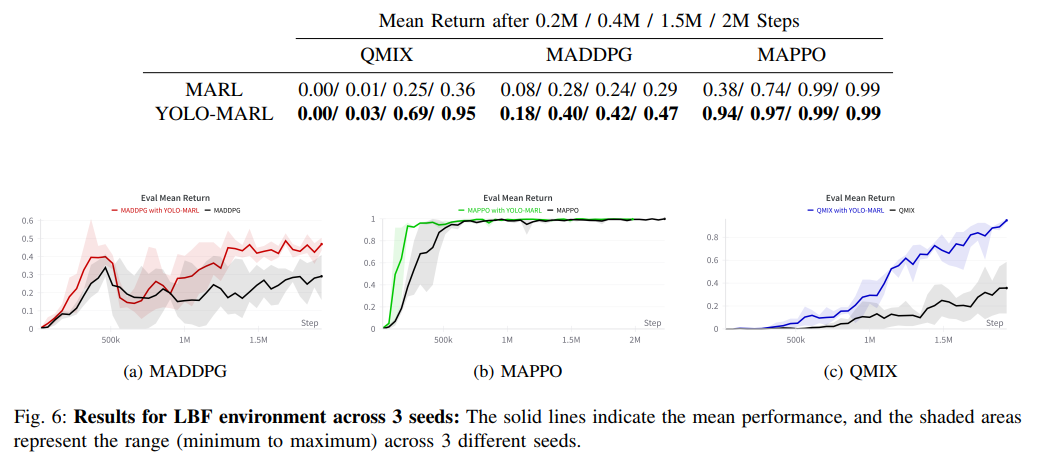
在LBF环境(2玩家2食物完全合作场景)中,YOLO-MARL展现出显著优势。如表I和图2所示,所有基线算法(QMIX、MADDPG、MAPPO)在集成YOLO-MARL后性能均有提升,其中QMIX的改进幅度最大——在150万训练步时平均回报从0.25提升至0.60,相对提高105%。值得注意的是,MAPPO在原始设置下已表现良好,但YOLO-MARL仍使其收敛速度大幅提升(31%→93% @0.2M步)。这些结果验证了框架在稀疏奖励环境中的有效性,说明LLM生成的高级规划确实弥补了传统MARL在长期信用分配方面的不足。
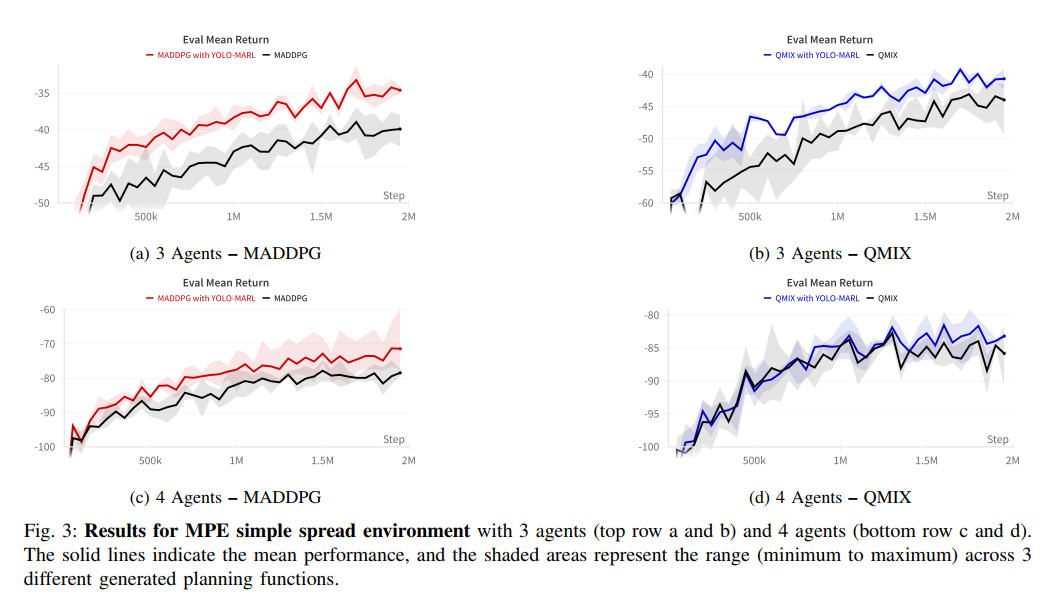
MPE简单扩散环境的结果(图3)进一步展示了YOLO-MARL的通用性。在3智能体场景中,框架使QMIX和MADDPG的平均回报分别提升7.66%和8.8%;4智能体场景的提升更为显著,特别是MADDPG达到18.09%改进。这些结果表明,随着任务复杂度(智能体数量)增加,YOLO-MARL提供的协调指导价值更加凸显。与LBF不同,MPE环境的奖励相对密集,YOLO-MARL在此仍能带来稳定提升,说明其优势不仅限于稀疏奖励场景。
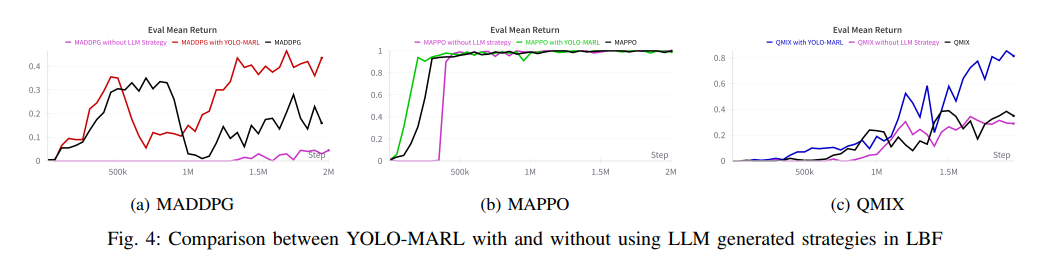
消融研究(VI节)为框架设计选择提供了有力证据。图4显示,移除策略生成模块会导致性能明显下降,生成的规划函数质量不稳定。这验证了LLM生成策略作为"中间表示"的价值——它将用户提供的环境基本描述转化为更专业的领域知识,为后续规划函数生成奠定基础。状态解释模块的消融则导致更严重后果,LLM完全无法理解原始状态表示,生成无效函数。这些结果强调了模块协同的重要性——YOLO-MARL的整体性能依赖于各模块的有机配合。
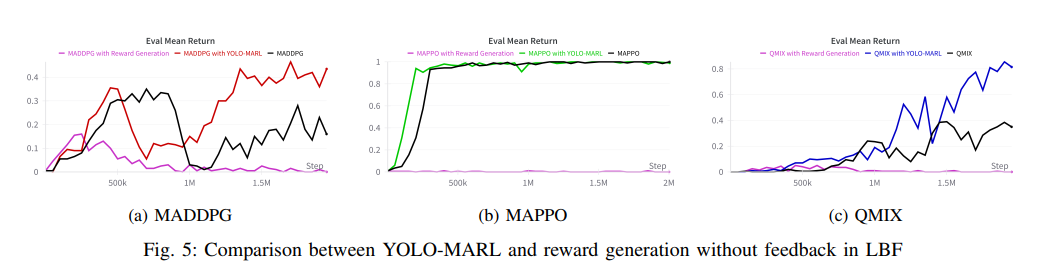
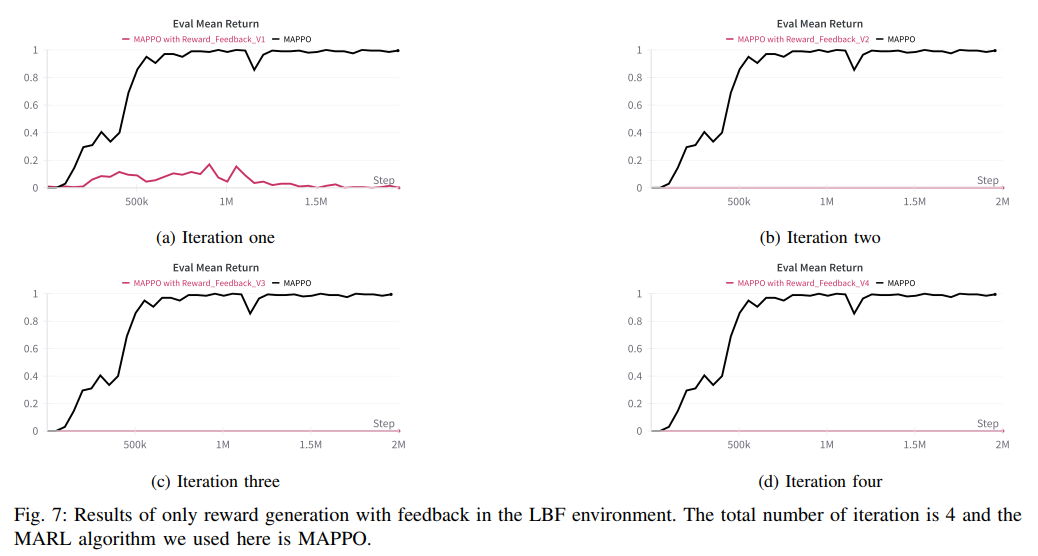
论文还探讨了将LLM用于奖励生成的可能(VI-C节),但结果显示纯LLM生成的奖励函数效果不佳(图5),即使通过迭代反馈也难有改善(图7)。这一对比突显了YOLO-MARL核心设计的优势:与其让LLM直接生成低级奖励信号(非其所长),不如发挥其高级规划专长,将具体实现留给专门优化的MARL算法。这种分工理念是YOLO-MARL成功的关键因素之一。
实验部分的全面性评估验证了YOLO-MARL在多方面的优势:性能提升(最高105%)、训练加速(2倍收敛速度)、环境适应性(LBF和MPE)和算法兼容性(QMIX、MADDPG、MAPPO)。这些结果共同支持了论文的核心论点:通过单次LLM交互生成高级规划函数,可以高效增强传统MARL算法,而不引入持续计算开销。

讨论与展望
6.1 贡献
YOLO-MARL的研究开辟了大语言模型与多智能体强化学习融合的新方向,其核心贡献在于平衡了性能与效率的权衡。传统MARL算法缺乏高级推理能力,而直接使用LLM作为代理又面临高昂计算成本。YOLO-MARL的创新架构找到了二者之间的黄金平衡点——既利用LLM的通用规划能力,又保持MARL的高效策略优化。论文报告的实验结果充分验证了这一设计理念的有效性。
从方法论角度看,YOLO-MARL的成功揭示了分层抽象在多智能体决策中的重要性。人类处理复杂任务时自然采用"分而治之"策略,先制定高级计划再落实具体行动。YOLO-MARL通过策略生成→状态解释→规划函数生成的模块化流程,实现了类似的分层处理。不同的是,这种分层结构不是通过端到端训练获得,而是利用LLM的零样本推理能力构建,这大大减少了训练负担。这种模式可能启发更多结合神经符号方法(neural-symbolic)的混合智能系统设计。
6.2 局限性
虽然实验证明了在LBF和MPE环境中的有效性,但更复杂场景(如部分可观测、非稳态环境)下的表现仍需验证。此外,规划函数的质量依赖LLM的推理能力,当面对高度专业化领域知识时可能受限。这些开放问题为未来研究指明了方向:探索更鲁棒的规划函数生成方法、扩展至竞争或混合动机环境、研究动态更新规划函数的机制等。
6.3 YOLO-MARL的实用价值
实际部署多智能体系统时常面临稀疏奖励、复杂协调等挑战,而专业奖励函数设计又需要大量领域知识。YOLO-MARL提供了一种折中方案——通过自然语言描述获取环境基本知识,自动生成规划指导。这大大降低了技术应用门槛,使更多领域专家能参与多智能体系统开发而不必掌握深度RL细节。结合论文报告的效率优势(每次环境不到1美元的LLM API成本),该方法具有良好的产业化前景。
6.4 未来研究方向
一是整合更强大的LLM代码生成能力,直接产生可自适应调整的规划函数;
二是探索多模态输入,如结合视觉语言模型处理更丰富的环境信息;
三是研究分布式场景下的规划函数传递机制,实现智能体间的知识共享。
YOLO-MARL作为开创性工作,不仅提出了具体解决方案,更开辟了LLM与MARL交叉研究的新范式,其方法论意义可能超越论文探讨的具体应用场景。
6.5 总结
论文提出了一种新颖、高效且实用的多智能体决策框架,通过巧妙结合LLM的规划能力和MARL的策略优化优势,在保持计算效率的同时显著提升了算法性能。论文在概念创新、方法设计和实验验证方面均体现出高水平,为人工智能领域两大前沿方向的融合提供了典范案例,其影响将辐射至机器人协作、游戏AI、智能交通等多个应用领域。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-07-29,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号