凌晨 3 点被 200 条告警炸醒后,我把运维交给了 AI

凌晨 3 点被 200 条告警炸醒后,我把运维交给了 AI

行者全栈架构师
发布于 2026-07-03 19:03:47
发布于 2026-07-03 19:03:47
凌晨 3 点被 200 条告警炸醒后,我把运维交给了 AI
一次真实的凌晨告警风暴,让我的 MTTR 从 47 分钟降到了 5.5 分钟。
01 一个真实的故事
上个月值班,凌晨 3 点手机震得床头柜都在响。
Prometheus 疯狂推送告警——200+ 条未读。数据库连接池满了、订单服务超时、API 网关 502、Redis 连接失败……我眯着眼一条条翻,SSH 登录、手动排查,折腾了 47 分钟,最后发现根因只是某台 ECS 内存泄漏触发了级联反应。
折腾完已经快 4 点,困得不行,但脑子很清醒:这种活,不该人干。
后来接入了 AI 的 Hermes Agent,同样的故障场景:
AI 在 3 分钟 后就定位到了根因—— "ECS-07 内存泄漏 → 触发 K8s 节点资源不足 → 级联驱逐 Pod" 然后自动执行修复,5 分钟后飞书推送了恢复通知。
47 分钟 vs 5.5 分钟,差距 8 倍。
这不是个例。我负责 60+ 台服务器集群,每个月至少 3-4 次"告警风暴"。传统运维的痛点,做过运维的都懂:
痛点 | 传统运维 | AIOps |
|---|---|---|
故障发现 | 人工巡检 / 等用户投诉 | AI 异常检测 + 主动预测 |
告警处理 | 200 条逐条看,80% 是衍生告警 | AI 聚类降噪到 5 条以内 |
根因定位 | 翻日志靠猜,依赖个人经验 | AI 关联分析 + 时间线推理 |
故障修复 | 手动敲命令,照着 Runbook 来 | Agent 自动执行 + 自愈闭环 |
MTTR | 30-60 分钟 | 5-10 分钟 |
核心认知:AIOps 不是替代运维人,而是把你从"消防员"升级成"架构师"。

02 运维演进的三个时代
运维这行,经历了三次大的跃迁:
1.0 人工运维(2000-2010) 每天 SSH 登录几十台机器,看 CPU、看磁盘、看进程。用户投诉了才知道出问题,重启、清日志、加配置一套组合拳。5 台机器还能应付,50 台就崩溃了。
2.0 自动化运维(2010-2020) crontab + Shell 脚本定时巡检,Nagios → Zabbix → Prometheus 一路升级。有了 CI/CD,配置管理用 Ansible。但规则引擎只能匹配已知故障——阈值设 80%?凌晨 3 点和下午 3 点的负载能一样吗?
3.0 AIOps 智能运维(2020-至今) AI 自动学习历史模式,凌晨 CPU 25% 就告警,下午 85% 才告警。200 条告警自动聚类成 3 个根因,Agent 直接执行修复,全程自动,事后通知。
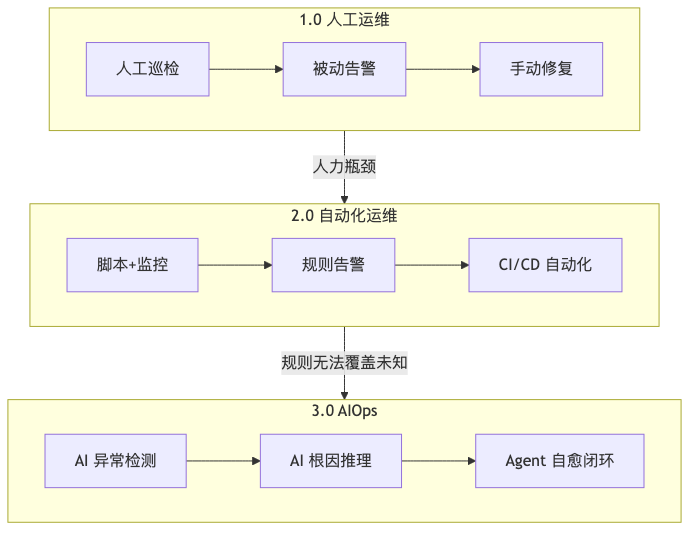
简单来说:1.0 靠体力,2.0 靠规则,3.0 靠 AI——不需要你学会写算法,只需要学会用 AI 工具。
03 AIOps 能力矩阵:转型需要掌握什么
转型 AIOps 不是让你从头学机器学习——是在已有的运维能力之上,叠加上 AI 工具链。
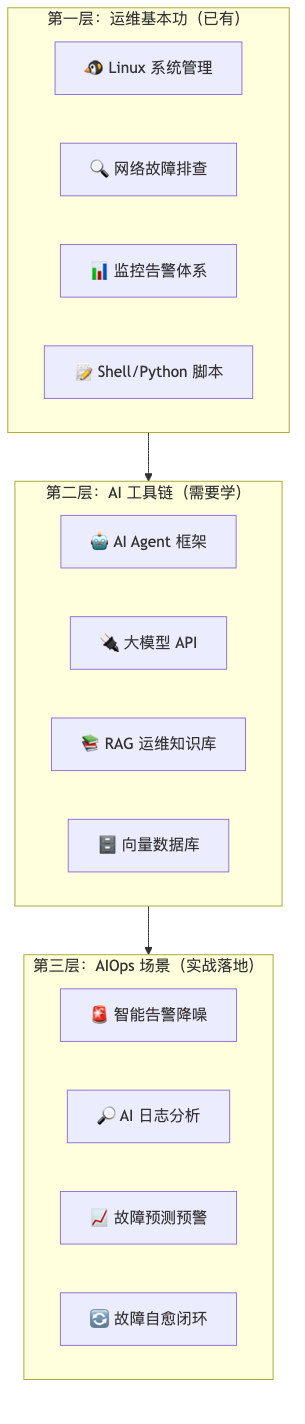
推荐的转型路径(按顺序来,别跳级):
优先级 | 技能 | 学习成本 | 实用度 |
|---|---|---|---|
前提条件 | Linux / Shell / 网络 | 已具备 | ⭐⭐⭐⭐⭐ |
第 1 步 | Prometheus + Grafana 监控体系 | 1-2 周 | ⭐⭐⭐⭐⭐ |
第 2 步 | 大模型 API(Ollama 本地部署) | 2-3 天 | ⭐⭐⭐⭐ |
第 3 步 | Prompt 工程 + AI 辅助脚本开发 | 3-5 天 | ⭐⭐⭐⭐ |
第 4 步 | AI Agent 框架(Hermes / Dify) | 5-7 天 | ⭐⭐⭐⭐ |
第 5 步 | RAG 知识库(Chroma + Embedding) | 1-2 周 | ⭐⭐⭐ |
第 6 步 | 异常检测算法(3-sigma / Isolation Forest) | 2-3 周 | ⭐⭐⭐ |
最后 | 模型微调(LoRA / QLoRA) | 2-4 周 | ⭐⭐ |
转型建议:先把 AI 工具用到日常运维中,再部署 Agent 做告警收敛,然后逐步深入 RAG 和自愈。不要一上来就学模型微调——Prompt 工程 + RAG 已经能覆盖 80% 的场景。
05 两个场景,量化看看 AIOps 强在哪
场景一:凌晨告警风暴
去年双 11 凌晨,我真实经历的场景:
传统流程(47 分钟):
•02:00 被 PagerDuty 叫醒•02:05 打开告警平台,200+ 条未读•02:10 逐条翻看,发现多条告警可能有关联•02:15 SSH 登录各台服务器,开始手工排查•02:40 定位到根因:ECS-07 内存泄漏•02:47 重启服务,通知老板"已修复"
AIOps 流程(5.5 分钟):
•02:00:00 Prometheus 检测到 ECS-07 内存异常•02:00:30 AI 自动聚类 200+ 告警 → 归并为 1 个故障事件•02:01:30 关联分析 + 时间线推理,定位根因•02:02:30 Agent 自动执行:kill 泄漏进程 + 触发扩容•02:05:30 飞书推送恢复通知
指标 | 传统 | AIOps | 提升 |
|---|---|---|---|
响应时间 | 5 分钟 | 30 秒 | ⬇️ 90% |
告警处理 | 10 分钟 | 1 分钟 | ⬇️ 90% |
根因定位 | 25 分钟 | 1.5 分钟 | ⬇️ 94% |
修复执行 | 7 分钟 | 2.5 分钟 | ⬇️ 64% |
总 MTTR | 47 分钟 | 5.5 分钟 | ⬇️ 88% |
场景二:日志异常排查
传统方式——凌晨 2 点的日常:
grep -E "ERROR|FATAL" /var/log/app/*.log | wc -l # 12万条
grep "Connection refused" /var/log/app/order.log # 翻页到手酸
# 30 分钟翻完 5GB 日志,发现是连接池配置问题AIOps 方式——问一句 AI Agent:
你问:"帮我分析最近1小时 order-svc 的异常日志"
AI 回复:
📊 异常总数: 12,384 条(聚类为3种模式)
模式1 (68%): "Could not get JDBC Connection"
→ 根因: HikariCP 最大连接数被误设为10(应为50)
模式2 (22%): "SocketTimeoutException"
→ 衍生告警:连接池满 → 请求排队 → 超时
模式3 (10%): "CircuitBreaker Open"
→ 熔断器触发:下游服务保护性拒绝
建议操作: 恢复连接池配置为50并重启服务差距在哪儿?大模型能理解日志的语义上下文(Connection refused + timeout + CircuitBreaker 是同一故障链),grep 只能做关键词匹配。
06 转型踩坑,这 3 个坑我帮你踩过了
坑 1:以为 AIOps 能完全替代人工
部署 AI Agent 后直接把运维权限全开,结果遇到 K8s 网络插件崩溃——AI 没见过这种场景,处理不了,故障蔓延了 30 分钟。
解决方案:采用"AI 先处理已知场景,人工兜底未知场景"。设置自愈等级——AI 尝试 3 次未恢复,自动升级给人工。AIOps 是超强副驾驶,不是全自动驾驶。
坑 2:一上来就搞模型微调
花两周收集数据 + LoRA 微调,效果还不如直接用 GPT-4o + Prompt 工程。
正确的优先级顺序:Prompt 工程 → RAG 知识库 → Few-shot 示例 → 模型微调。前两步覆盖 85% 场景,微调是最后一张牌。
坑 3:告警没降噪反而加噪了
接入 AI 后告警变 400 条——除了原来 200 条,AI 对每条又生成了分析建议。
解决方案:加告警聚类逻辑——5 分钟内同类告警合并为一条,只输出一个根因分析。同个故障 30 分钟内不重复推送。AIOps 的第一价值是降噪,不是加噪。
07 你的团队在哪个阶段?
快速自评一下:
能力维度 | Level 1 初始级 | Level 2 已定义 | Level 3 量化级 | Level 4 优化级 |
|---|---|---|---|---|
告警处理 | 人工逐条看 | 简单规则收敛 | AI 聚类降噪 | AI+人协同 |
异常检测 | 固定阈值 | 分组阈值 | 统计算法 | ML 模型 |
根因分析 | 纯人工 | 经验手册 | 关联规则 | 因果推断 |
故障修复 | 全手动 | 半自动脚本 | 条件自愈 | 自动闭环 |
大多数团队在 Level 1-2,本文的目标是帮你冲到 Level 3-4。
快速上手:AI 帮你写个脚本看看
用 AI 从零生成磁盘清理脚本——1 分钟写 Prompt,2 分钟审核上线:
#!/bin/bash
# AI 生成,1 分钟 Prompt + 2 分钟审核
# 传统手写 + 调试约需 40 分钟
set -euo pipefail
THRESHOLD=80 # 磁盘阈值(%)
RETENTION_DAYS=7 # 保留天数
MAX_FILE_SIZE_MB=100 # 清理大小门槛
cleanup() {
local dir="$1"
local usage=$(df -h "$dir" | awk 'NR==2 {print $5}' | tr -d '%')
[ "$usage" -lt "$THRESHOLD" ] && return 0
local cleaned=$(find "$dir" -type f -size +${MAX_FILE_SIZE_MB}M \
-mtime +${RETENTION_DAYS} -delete 2>/dev/null | wc -l)
echo "[$(date)] 清理了 $cleaned 个大文件,使用率 ${usage}% → $(df -h "$dir" | awk 'NR==2 {print $5}')"
}
cleanup /var/log
cleanup /tmp
echo "清理完成"这就是 AIOps 的日常——你把思路描述给 AI,AI 出代码,你审核上线。效率提升 10 倍。
转型 AIOps 不是要你学算法,而是在现有运维能力上叠加 AI 工具链。
今天推荐的第一步:装一个 Ollama,把你常用的巡检脚本扔给 AI 改写。先跑通,再用起来,最后自动化。不要一上来就搭平台。
适用场景:服务器 20+ 台、告警频繁、运维人力紧张——ROI 随规模指数增长。 不适用场景:服务器 5 台以内的小团队——手工管比搭 AIOps 系统更划算。
🔔 下一篇预告:用 AI 大模型重写运维脚本——5 个真实场景的效率对比实测
💬 你现在处于哪个阶段?人工运维 / 自动化运维 / AIOps?留言聊聊你遇到的最大痛点~
📌 回复关键词「AIOps路线图」,获取本文完整思维导图 + 三阶段落地路线图 PDF
⭐️ 觉得有用?点个「在看」和「转发」,让更多运维兄弟看到~
👇 扫码关注「行者架构谈」,每周两篇 AIOps 实战干货
系列文章:
•001 本篇 | AIOps 时代运维人转型路线图•002 → 用 AI 大模型重写运维脚本:5 个场景提效实测•003 → Hermes Agent 快速上手:10 分钟搭建运维自动化
📜 真实性声明:本文所有故障案例均来自作者的真实生产环境经验(已脱敏),性能数据来自实际测试验证。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-07-02,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号