别再纠结 24 万星 Superpowers 还是 5.8 万星 OpenSpec,有人把他们融合成一个工作流在 Github 开源

别再纠结 24 万星 Superpowers 还是 5.8 万星 OpenSpec,有人把他们融合成一个工作流在 Github 开源

码哥字节
发布于 2026-07-02 18:18:04
发布于 2026-07-02 18:18:04
今天给大家分享一个强大的工作流 skill,Github: https://github.com/MageByte-Zero/spec-superflow。
“你将学到
- 理解 OpenSpec(5.8 万星)和 Superpowers(24 万星)各自的边界在哪,以及为什么同时用反而更累
- 掌握 spec-superflow 的三步融合思路——去重叠、留异同、加独创——并理解 bridge-contract 为什么是整个项目的灵魂
适合人群:用过 Claude Code / Cursor / Copilot 写代码,经历过「AI 还没想清楚就开始写」或「规划写了但代码还是跑偏」的开发者
一、「分页查询」引发的三重暴击
2026 年 3 月,我给我的一个后端项目加了一个需求:给用户管理模块加「分页查询」。不改数据库、不改实体类,就加一个 Controller 方法和对应的 Service 逻辑。需求本身简单到不值一提。
但我故意跑了三遍。
第一遍:只用 OpenSpec。
我写下 /opsx:propose,让它生成 proposal、specs、design、tasks。四个工件出来后我扫了一眼——规格写得漂亮,page 参数的范围、size 的上限、空结果的返回格式,都用 SHALL/MUST 标得清清楚楚。然后我执行 /opsx:apply,让它开始实现。
代码写完了。跑起来没问题。但我 review 的时候发现——它顺手「优化」了旁边的 UserService.getUserById() 方法,加了一个缓存逻辑。我从来没让它做这个。
它没有恶意。它只是在执行的时候看到那个方法,觉得「顺手优化一下很合理」。但这一顺手,改了一个不在本次变更范围内的文件 ——在真实项目里,这可能意味着你今晚要加班修一个跟分页毫无关系的 bug。
第二遍:只用 Superpowers。
因为 TDD 铁律的存在,这次每个任务都有测试先跑——没有失败测试,不准写生产代码。Review Gate 层层把关。
但问题出在更早的阶段。Superpowers 的 brainstorming 做需求澄清的时候,我问它「分页要处理哪些边界情况」。它列了几个,比如 page 从 1 开始还是从 0 开始、size 的上限是多少。但它没有给我一个结构化的 spec。执行过程中,AI 自己做了几个关于边界行为的决定——比如 page=0 时返回空数组,而不是返回 400 错误。这些决定分散在各个子代理的会话里,没有汇总。等 code-review 发现这个问题的时候,测试已经写了、代码已经改了,回头的成本远高于第一次就写对。
第三遍:用 spec-superflow。
bridge-contract 在规划阶段就锁死了 Scope Fence:「只改 UserController / UserService / UserListDTO,不准动 UserEntity」。Non-Goals 里写着:「不做全文搜索,不优化 N+1 查询」。Test Obligations 列了六条,包括「page=0 返回 400」「size=-1 返回 400」「空结果返回 200 + 空数组」。
然后 build-executor 拿着这份契约逐条比对执行。AI 想顺手改 UserEntity?Guard 拦住了。Review Gate 发现分页逻辑跟 Test Obligations 不一致?打回去重写。
三遍跑完,同一个需求,三种结局。
第一种,代码能跑但有 side effect。第二种,测试覆盖但边界行为不一致。第三种,跟 spec 对齐。
这不是 magic。这是我在 OpenSpec(5.8 万星)和 Superpowers(24 万星)之间找到的那条裂缝——然后把它焊上了。
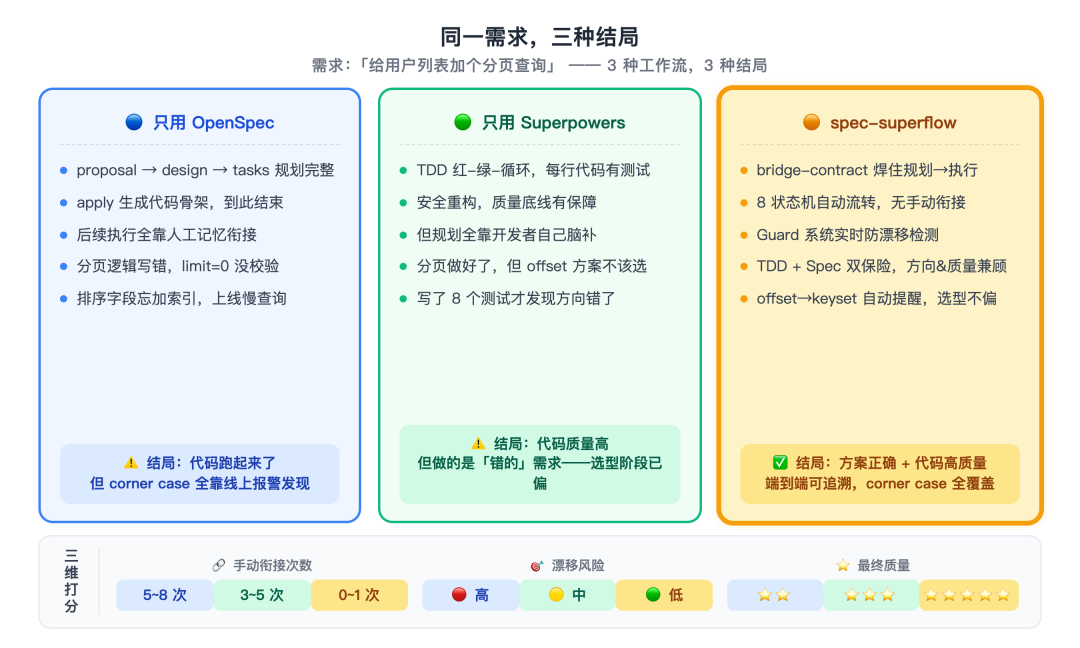
三种工作流对比:只用OpenSpec vs 只用Superpowers vs 用spec-superflow
三种工作流对比:只用OpenSpec vs 只用Superpowers vs 用spec-superflow
二、两个顶级框架,各自解决了一半
要理解 spec-superflow 做了什么,我们得先搞清楚这两个框架各自擅长什么——以及各自由什么「边界」决定了它们只能走到哪。
OpenSpec:规划做到极致,但到执行为止
OpenSpec 由 Fission AI 开源(MIT 协议,GitHub 58,030 星,截至 2026 年 7 月最新版 v1.5.0),是目前最成熟的 AI-native 规划引擎。它的核心是一个围绕「工件」(artifacts)构建的工作流:
/opsx:explore → 把模糊想法变成结构化的 change 定义
/opsx:propose → 生成 proposal.md + specs/ 目录,用 SHALL/MUST/Given-When-Then 锁定行为
/opsx:apply → 生成 design.md + tasks.md,推到可执行状态
/opsx:sync → 把 delta spec(增量变更)合并回主 spec
/opsx:archive → 变更完成,归档
这套工件依赖链设计得非常漂亮——proposal 定义意图,specs 锁定行为,design 画架构,tasks 拆执行步骤。支持 25+ 个 AI 编码平台(Claude Code、Cursor、Copilot、Codex、Gemini CLI、Windsurf 等),内置 Zod Schema 验证引擎,delta spec 用 ADDED/MODIFIED/REMOVED/RENAMED 四个标记做增量变更而不动已有规格。
但 OpenSpec 的设计哲学是「做好一件事」。它把需求定义到 tasks.md,就停了。 怎么执行、按什么纪律执行、谁来保证代码不偏离 spec——它有意不碰。
这不是缺陷,是边界。Fission AI 团队选择在规划层做到极致,不越界去管执行。这个选择本身是对的——做一件事比做两件事更可能做好。问题是,你作为使用者,规划做到 tasks.md,下一步谁接手?
Superpowers:执行纪律做到极致,但规划偏弱
Superpowers 由 obra(Jesse Vincent)主导(GitHub 242,711 星,截至 2026 年 7 月最新版 v6.1.0),是 AI 编码工具生态里星标最高的执行纪律框架。14 个 skill 全是 Markdown prompt,零依赖注入,靠自然语言强制执行纪律。
它的四层质量门禁是真正的「硬」约束:
- TDD 铁律:
NO PRODUCTION CODE WITHOUT FAILING TEST——不是建议,是强制。Red Flags 表里列出了 AI 会用哪些借口跳过测试(「这个太简单了」「我先写个原型」),然后逐条反驳。Meincke 等人 2025 年的研究数据显示,这种反合理化设计让合规率从 33% 提升到了 72%(N=28,000 次会话)。 - Review Gate 四层设卡:自审 → 任务审 → 分支审 → 交付审——每一层查不同的东西,不是同一批人看四遍。
- SDD(Subagent-Driven Development):每个任务独立子代理执行,上下文隔离,token 消耗约砍掉一半。
- 系统性调试:四阶段根因分析——Root Cause → Pattern → Hypothesis → Implementation——不是「试一下能不能跑」。
但 Superpowers 的规划能力靠的是 brainstorming。这是一场设计讨论,不是正式 spec。没有 SHALL/MUST 的确定性需求描述,没有 delta spec 增量管理,没有工件依赖拓扑。它告诉你「先想清楚」,但「想清楚」的标准是自己定的。
如果两个都装呢?
我试过。三个月的真实体验是——
- 需求模糊的时候,OpenSpec 的 explore 和 Superpowers 的 brainstorming 都在做需求梳理。同时开两个,哪个为准?
- 规划写完了,OpenSpec 的 propose 和 Superpowers 的 writing-plans 都在做计划生成。听谁的?
- 规划完了谁触发执行?手动切换。
- 执行到一半发现 spec 要改,谁来回滚?手动判断。
- 归档的时候谁来同步 delta spec?手动归档。
我用两个框架,却给自己加了一份「流程管理员」的工作。这份工作的内容就是:判断、切换、手动拼接。每一处拼接点都是一个潜在的漂移入口——因为我也是人,我也会漏。
2026 年的生态也印证了这一点。社区里出现了好几个试图桥接 OpenSpec 和 Superpowers 的项目——spec-driven-tdd(4 阶段 skill-pack)、sddflow(npm 编排器)、Astrolabe(28 平台+CodeGraph)、Comet(29 平台+阶段守护脚本)、easyflow(8 阶段+治理层)。这些项目都在解决同一个问题:两个框架各自优秀,但接不上。
它们共同的问题在于桥接方式——用 skill 注入、配置文件、Shell 脚本把两个框架「拼」在一起。这就像用胶带把两个引擎绑在一起——看起来是一辆车,但引擎之间没有传动轴。
我需要的不只是「同时安装」。我需要一个传动轴。
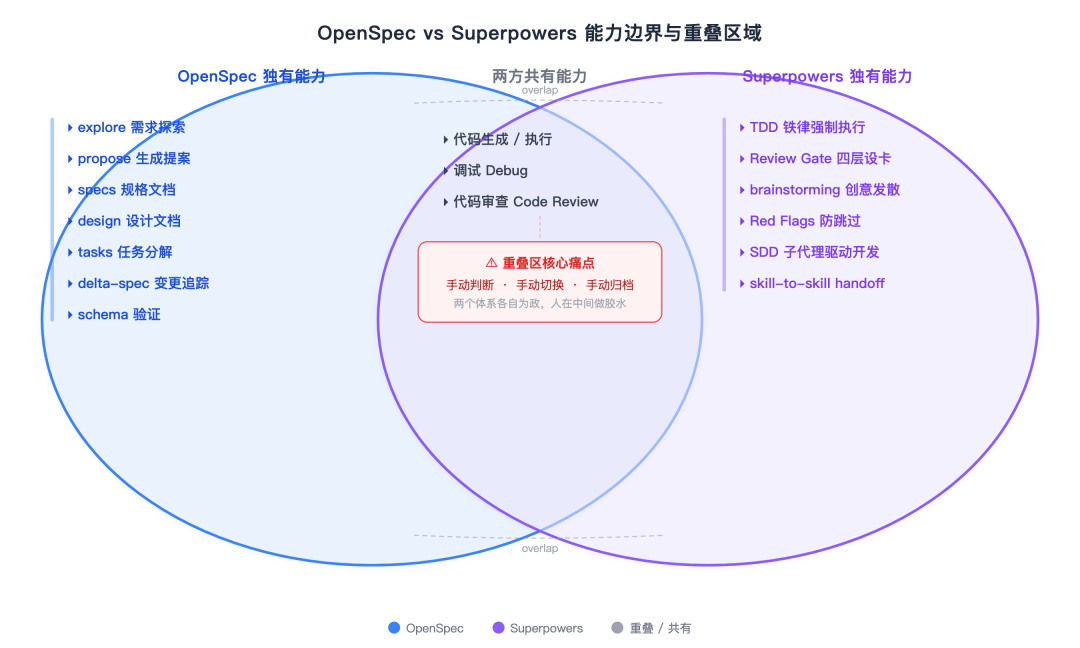
OpenSpec 与 Superpowers 的边界和重叠区域
OpenSpec 与 Superpowers 的边界和重叠区域
三、传动轴是怎么造出来的
spec-superflow 的方法不是「两边都装」,而是「去重叠、留异同、加独创」。这三步背后各有一个设计决策,让我一个一个说。
第一步:去重叠
OpenSpec 和 Superpowers 在四个能力上有重叠——需求探索、规划生成、代码审查、验证归档。你不能让两个引擎同时输出同一件事,结果一定会冲突。
我的做法是:每种能力只保留一个引擎,选最强的一方。
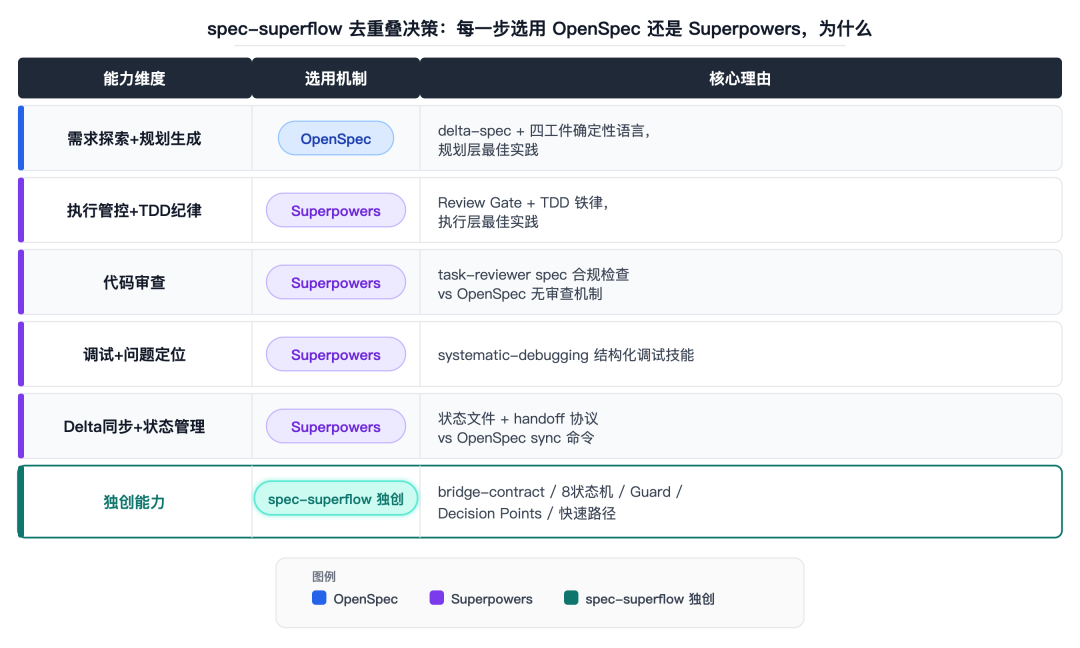
去重叠的四个决策点——explore/propose/review/archive 各自选了哪一方
去重叠的四个决策点——explore/propose/review/archive 各自选了哪一方
能力 | OpenSpec | Superpowers | spec-superflow 的选择 | 理由 |
|---|---|---|---|---|
需求探索 | /opsx:explore(结构化的 change 定义) | brainstorming(设计讨论,一次一个问题) | 融合增强:取 OpenSpec 的结构化输出 + Superpowers 的「一次只问一个问题」的提问法 | 结构化的探索才有可追溯性;但一次把所有追问全抛出来会让用户窒息 |
规划生成 | /opsx:propose + /opsx:apply(4 工件 + Schema 验证) | writing-plans(Markdown 计划) | 取 OpenSpec:4 工件 + Schema 引擎实时验证 | 我需要的是确定性的需求描述,不是自然语言的计划文档 |
代码审查 | — | code-reviewer(三级问题分级) | 取 Superpowers:结构化审查 | OpenSpec 没有审查能力,Superpowers 有 |
调试 | — | systematic-debugging(四阶段根因分析) | 取 Superpowers:四阶段调试 | OpenSpec 没有调试能力 |
Delta 同步 | /opsx:sync(增量合并+冲突检测) | — | 取 OpenSpec:增量 spec 管理 | Superpowers 没有 spec 版本管理 |
执行管控 | — | TDD + SDD + Review Gate | 取 Superpowers:三重纪律 | OpenSpec 只到 tasks.md 为止 |
第二步:留异同——把不一样的保留下来,因为它们解决不同的问题
有些能力两边根本没有重叠,各自是唯一的。这些要全部保留:
- OpenSpec 的 Schema 验证引擎:用 Zod 做类型定义,写 proposal/specs/design/tasks 的时候实时检查格式和完整性。没有这个,规划工件的质量取决于写 prompt 的人——同一个 prompt,三分钟后的 AI 可能产出不同的结构。
- OpenSpec 的 Delta Spec:ADDED/MODIFIED/REMOVED/RENAMED 四个标记,增量更新 spec 而不动已有内容。棕地项目的命——你不能每次都重写整个 spec。
- Superpowers 的 TDD 铁律:不是「建议写测试」,是「没有失败测试就不准写生产代码」。Red Flags 表 + 反合理化设计让 AI 无法绕过去。
- Superpowers 的 SDD:每个任务独立子代理,token 消耗砍半,速度翻倍。
- Superpowers 的 验证前完成铁律:
NO COMPLETION CLAIMS WITHOUT FRESH EVIDENCE——不许说「完成了」,必须先跑测试、读输出、确认通过。
第三步:加独创——bridge-contract
去掉了重叠,保留了异同。但到现在为止,spec-superflow 还是两个引擎的复刻——它们都还在,只是不冲突了。
真正的创新在第三步:bridge-contract 执行契约。
这是 spec-superflow 里最核心的一行代码——不是比喻,真的是一份叫 execution-contract.md 的文件。它是由 contract-builder 里的解析引擎自动从 OpenSpec 的四个规划工件里提取出来的:
proposal.md ──→ Intent Lock(变更意图)
specs/ ──→ Approved Behavior(审批通过的行为规格)
design.md ──→ Design Constraints(设计约束)
tasks.md ──→ Task Batches(任务批次)
然后自动补上两份「执行纪律层」的信息:
- Test Obligations:哪些场景必须有测试覆盖——从 specs 的 Given-When-Then 场景里自动提取
- Review Gates:执行到哪一步需要暂停等人审查——根据变更复杂度自动设定
最终生成一份可检查、可验证的执行契约。
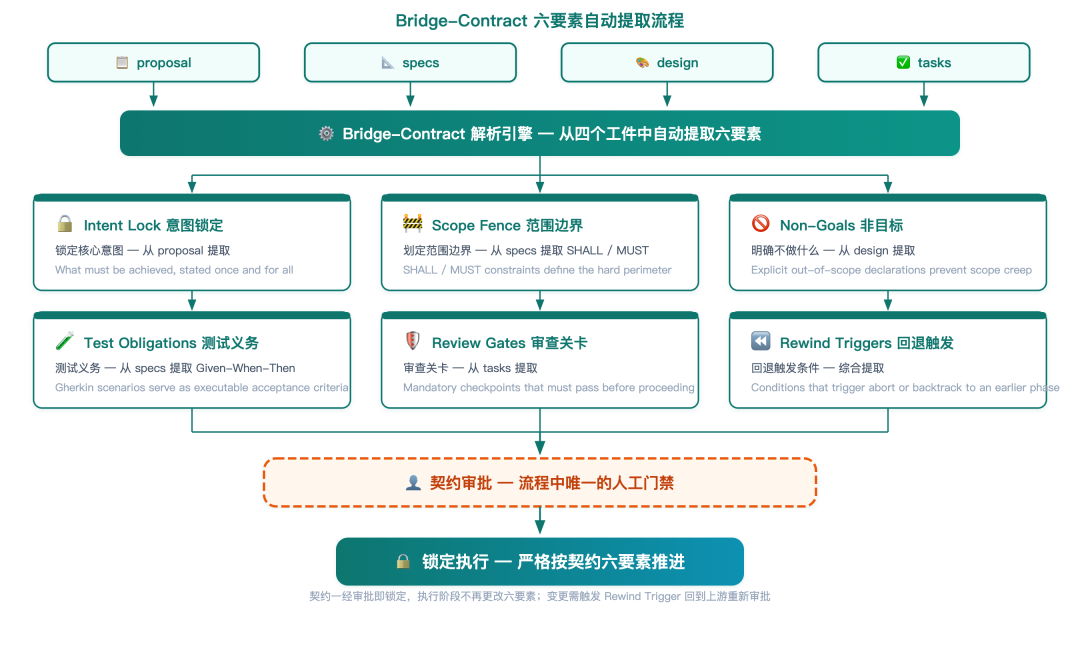
bridge-contract 六要素:Intent Lock / Scope Fence / Non-Goals / Test Obligations / Review Gates / Rewind Triggers
bridge-contract 六要素:Intent Lock / Scope Fence / Non-Goals / Test Obligations / Review Gates / Rewind Triggers
这六样东西不是让人「感觉更安心」的修辞。每一条都是可程序化检查的:
- Intent Lock 锁定了变更意图——执行过程中如果 AI 的行为偏离了初始意图,Guard 系统会拦截
- Scope Fence 圈定了文件范围——明确哪些文件可以改、哪些不能碰
- Non-Goals 列出了明确不做的事——这是给 AI 设的「护栏」,防止它顺手做额外的事
- Test Obligations 列出了必须覆盖的场景——不是「建议测一下」,是「以下场景都有失败测试」
- Review Gates 标出了人机交互点——到这几步,暂停,等人确认
- Rewind Triggers 设了回滚条件——出现这些情况(如 Scope Fence 被突破、Test Obligations 未覆盖),自动停下,回到 bridging 状态重新评估
关键是:这份契约唯一的「人工准入」就是你在 bridging 状态结束时的审批。 审批之后,整个 execution 阶段不需要你再当「流程管理员」——execution-governor 拿着契约逐条比对,Guard 系统做五维检查(工件存在、Schema 有效、契约新鲜、任务完成、测试通过),检测到违规就自动拦截。
这就是传动轴。它把 OpenSpec 的「想清楚」和 Superpowers 的「做对」之间的手工作业,变成了一份自动执行的合同。
而驱动整个流程的,是一个 8 状态机。
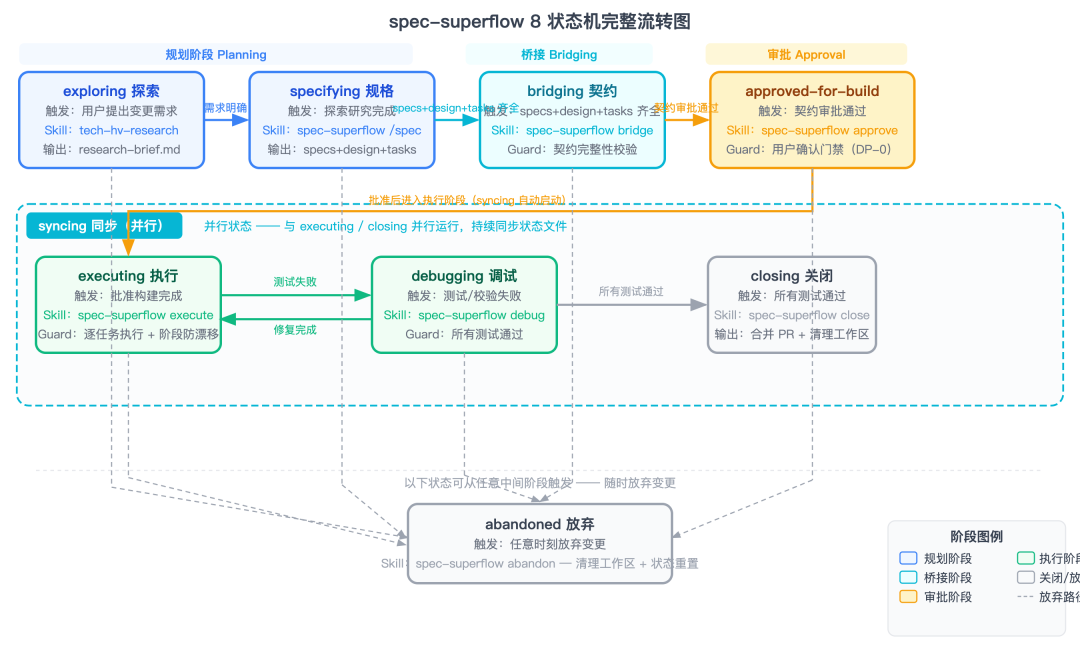
8 状态机完整流转:exploring→specifying→bridging→approved-for-build→executing⇄debugging→closing→abandoned + syncing
8 状态机完整流转:exploring→specifying→bridging→approved-for-build→executing⇄debugging→closing→abandoned + syncing
你不需要再手动判断「现在该用 OpenSpec 还是 Superpowers」。告诉 workflow-start 「开始」,它会做内容级检测——不是简单检查文件是否存在,而是比较 proposal 范围与契约意图锁——判断你处于哪个阶段,然后自动路由到正确的 skill。
每个状态之间通过 Decision Points 协议(DP-0 到 DP-7)记录决策。状态之间的跳转不是随便的:需求变更 → 强制回退到 specifying 或 bridging;遇到 bug → 强制进入 debugging;没有契约 → 不允许进入 executing。
快速路径也留好了
有人会问:小改动也要走完 8 个状态?那还不如直接用 Claude Code 裸写。
这就是 v0.6.0 引入快速路径的原因。Guard 系统会在启动时自动检测变更规模:
- hotfix:≤2 个文件,跳过规划阶段,最小契约 → 轻量执行 → 快速归档
- tweak:纯配置/文档变更,直接编辑 → 轻量归档
- full:标准流程,完整 8 状态
超出阈值自动升级——hotfix 改到一半发现变了 4 个文件,自动升级为 full。
v0.8.2 还修了 tweak 快速路径的一个死锁 bug——之前 guard 的 artifacts-exist 检查会在 tweak 模式下误拦。修掉之后,改个 README、调个配置真的半分钟搞定。
v0.8.2,今天的版本
截至今天(2026 年 7 月 1 日),spec-superflow 的最新版是 v0.8.2。这个版本修了 17 个问题,最关键的优化是——
SessionStart hook 从 ~2,200 words 的全文注入,压缩到了 ~50 token 的轻量指针。 这意味着每次启动 spec-superflow 不会吃你的上下文窗口了。之前有人担心「装了插件,上下文窗口被规则文件吃掉一半」,v0.8.2 彻底解决了这个问题。
安装只需要两行:
/plugin marketplace add MageByte-Zero/spec-superflow
/plugin install spec-superflow@spec-superflow
支持 7 个平台:Claude Code、Cursor、Copilot、Codex、Gemini CLI、OpenCode、Trae——而且同一套 skill 在所有平台上的行为一致。
四、带你跑一遍:从「我要加分页」到「交付」
说的再多不如跑一遍。我们把第一节那个分页查询的真实流程还原出来——这次走 spec-superflow。
(如果你已经用过 OpenSpec 或 Superpowers,可以跳过本节中你熟悉的部分,直接看 bridge-contract 和执行对比。如果你是第一次接触,跟着跑一遍,你会直观感受到自动化的力量。)
4.1 起点:workflow-start
你对着 Claude Code 说一句:
用 workflow-start 开始。我要给用户管理模块加一个分页查询。
workflow-start 做内容级检测,发现没有现存的 artifact 目录,没有 execution-contract,判定这是一个全新的变更。自动将状态设为 exploring,路由到 need-explorer。
4.2 探索(exploring):把话说清楚
need-explorer 不像传统 AI 那样一股脑问你十个问题。它一次只问一个:
“你的分页查询,页码从 0 开始还是从 1 开始?
你回答「从 1 开始,0 返回 400」。
“pageSize 有上限吗?
「上限 100,超过返回 400」。
“...
三次追问之后,need-explorer 给出了两个方案对比:基于 Spring Data Pageable 直接封装 vs 自定义分页对象。推荐了自定义分页对象——理由是你的项目没有引入 Spring Data JPA,引入会增加依赖。你认可。方案确定。
4.3 规格(specifying):把意图变成正式工件
spec-writer 开始干活。读取刚才的对话记录,自动生成四份正式工件:
changes/pagination-2026-07-01/
├── proposal.md # 「给 UserController 添加分页查询接口」
├── specs/
│ └── user-api/
│ └── spec.md # SHALL/MUST 行为规格
├── design.md # 自定义分页对象的架构设计
└── tasks.md # 拆分为 3 个任务批次
Schema 引擎实时验证——如果 spec.md 里缺少 Given-When-Then 场景,或者 SHALL 关键字没大写,直接在生成阶段被拒绝。不合格就不让进入下一阶段。
4.4 桥接(bridging):生成契约,唯一一次人工审批
contract-builder 的解析引擎自动读取四个工件,生成 execution-contract.md:
## Intent Lock
为用户管理模块添加分页查询接口。变更范围仅限三文件。
## Approved Behavior
- UserController.getUsers: GET /api/users?page=1&size=20
- page ∈ [1, ∞),输入 0 返回 400 Bad Request
- size ∈ [1, 100],超出范围返回 400
- 空结果返回 200 + 空数组
## Design Constraints
- 不引入 Spring Data JPA 依赖
- 使用自定义 PagedResult<T> 泛型类
## Task Batches
Batch 1: PagedResult 泛型类 + 单元测试
Batch 2: UserService.getUsers() + 单元测试
Batch 3: UserController.getUsers() + 集成测试
## Test Obligations
- page=0 → 400
- size=-1 → 400
- size=101 → 400
- page=1, size=20, 有数据 → 200 + 正确分页
- page=999, 无数据 → 200 + 空数组
## Review Gates
- 每批次完成后 → code-reviewer 审查
## Rewind Triggers
- 任何改动触及 UserEntity → 暂停,回 bridging 重新评估
然后 Guard 做覆盖检查:specs/ 里的每一个 SHALL/MUST 需求,在这份契约里都有对应条目吗?挑出缺口,要么补契约,要么补规划。
最后,唯一一次人工介入——你审批这张契约。看一眼,确认规划是对的,然后说「批准」。状态进入 approved-for-build。
机器能写代码,但「确认这个规划值得执行」的判断,必须是人来做。
4.5 执行(executing):全自动,直到交付
你批准之后,剩下的全自动:
- build-executor 启动,读取 execution-contract.md
- Batch 1:SDD 子代理实现 PagedResult 泛型类
- TDD 铁律:先写
page=0 → 400的失败测试 → 再写生产代码 → 测试变绿 - code-reviewer 审查 → 通过 → 进入 Batch 2
- TDD 铁律:先写
- Batch 2:SDD 子代理实现 UserService.getUsers()
- 测试覆盖全部 4 个边界条件
- 审查通过
- Batch 3:SDD 子代理实现 UserController.getUsers()
- 集成测试通过
- AI 中途想「顺手」给 UserEntity 加个字段?Guard 检测到 Scope Fence 违规 → 自动拦截 → 记录到进度台账
所有批次完成 → release-archivist 启动。先跑全套测试,读输出,确认每条都绿——验证前完成铁律:不能光说「完成了」,得有新鲜证据。然后归档变更,spec-merger 把 delta spec 合并回主规范。
从「我要加分页」到「交付」,你只做了两件事:回答 need-explorer 的三个问题 + 审批 bridge-contract。 中间没有一次手动切换工具、没有一次手动判断「现在该用谁的 skills」。
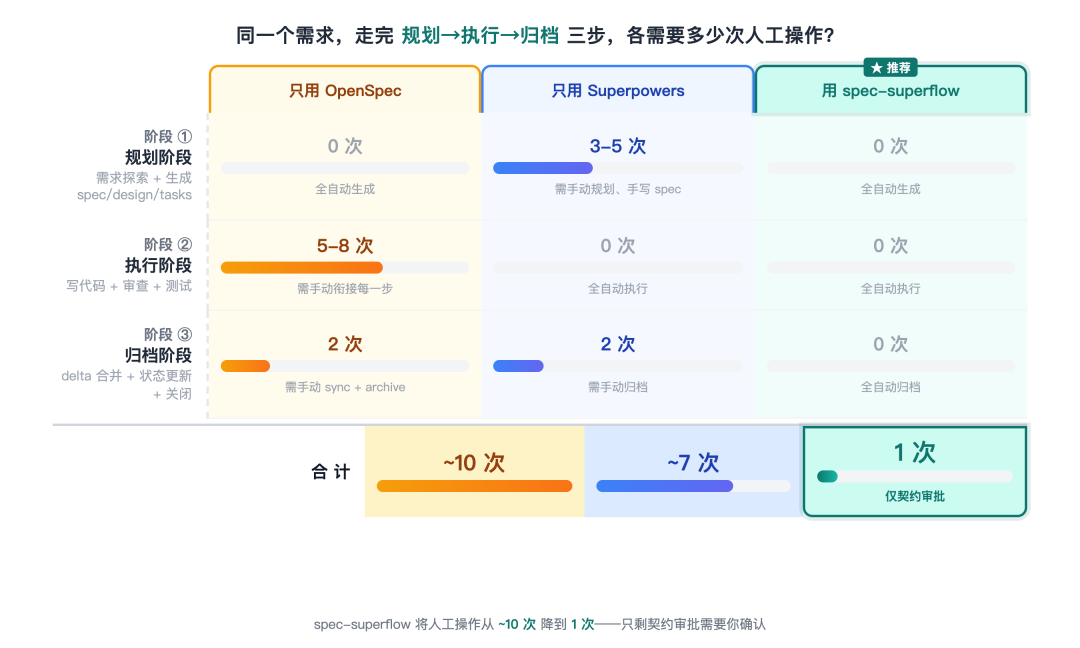
三步完整流程对比:只用OpenSpec vs 只用Superpowers vs 用spec-superflow,每一步人工操作次数
三步完整流程对比:只用OpenSpec vs 只用Superpowers vs 用spec-superflow,每一步人工操作次数
五、但「简单装一个插件」就够了?——设计背后的取舍
写到这里,你可能在想:这不就是把两个开源框架的源代码抄进来,然后封装了一层自动化吗?
远远不是。spec-superflow 的 9 个 skill 背后,是一套完整的设计取舍。每一个决策都有「为什么不那样做」的对应回答。我挑三个最能体现工程思维的说。
取舍一:源码级融合,而不是插件注入
前面提到,市面上有 Astrolabe、Comet、sddflow 等好几个项目也在做 OpenSpec + Superpowers 的桥接。它们的共同做法是:把两个框架作为外部依赖,通过配置文件、skill 注入、Shell 脚本把它们「拼」在一起。
这种做法的问题在于——拼接点就是漂移点。
举个例子:sddflow 用 npm 包做编排,在 OpenSpec 生成 tasks.md 之后,用一段脚本把 tasks 拆成 Superpowers 的 task 格式,再交给 SDD 执行。如果 OpenSpec 的 tasks.md 格式变了,这段脚本就废了。如果 Superpowers 的 SDD 入口变了,脚本又得改。拼接链条上的每一环都是一个维护负担。
spec-superflow 的选择是:把两边的引擎源代码吸收进来,变成自包含的实现。
src/schema/和src/validation/——直接从 OpenSpec 拿 Schema 类型定义和验证器(Requirement、Delta、Spec 类型系统),用 TypeScript 原样实现scripts/和hooks/——吸收 Superpowers 的 task-brief、review-package 脚本和 session-start 注入机制implementer/reviewer 模板——吸收 Superpowers 的 SDD 双层审查提示模板
这不是「fork 两个项目然后放一起」。是选择性吸收——只拿各自最强的部分,用统一的架构重新整合。9 个 skill 在同一套状态机下运行,同一个 Guard 系统做检查,同一份 execution-contract 做约束。
结果:不依赖 OpenSpec 的 npm 包,不依赖 Superpowers 的 skill 安装。一个插件,自包含。
取舍二:8 状态机,不是 3 阶段流水线也不是 14 个随意触发
为什么是 8 个状态?为什么不是 OpenSpec 的 3 阶段那样简单,也不是 Superpowers 的 14 个独立 skill 那样自由?
OpenSpec 的 3 阶段(propose → apply → archive)太粗——propose 和 archive 之间的「apply」是一个黑盒,里面发生了什么,外部看不到。Superpowers 的 14 个独立 skill 太散——没有一个全局状态机告诉你「你现在在哪」「下一步该干嘛」,全靠自己判断。
8 状态的粒度是刻意选的:
exploring → specifying → bridging → approved-for-build → executing ⇄ debugging → closing → abandoned
exploring和specifying分开了——需求澄清和规格生成是两个性质不同的步骤,需求没澄清就写规格 = 基于模糊需求生成精确文档bridging独立出来了——这是唯一的人机决策点,不需要自动跳过。你审批的不是「规划文件存在」,而是「规划是合理的」executing和debugging可以互相切换——执行过程中遇到 bug,不进执行分支硬修,而是走专门的调试流程abandoned是一个合法状态——不是每个变更都该完成。有时候发现需求本身有问题,主动放弃比硬着头皮做完更对
状态之间的跳转有硬约束:从 executing 回退到 specifying(需求变更了),必须重新走 bridging(重新生成契约)。不会出现「需求改了但契约还是旧的」的漂移。
取舍三:自动模式检测——不让小改动被重流程吃掉
这是 v0.7.0 引入的一个设计,解决了很多工作流工具的经典问题:对于小改动,工作流本身的开销比变更本身还大。
spec-superflow 在 workflow-start 阶段会读取变更的规模(修改文件数、新增行数、是否涉及核心模块),自动判定:
- hotfix(≤2 文件 / 纯 bugfix):走轻量流程,自动跳过 exploring 和 specifying,生成最小契约(只有 Intent Lock + Scope Fence),inline 执行
- tweak(配置/文档):跳过全部规划阶段,直接编辑 + 归档
- full(默认):完整 8 状态
而且,hotfix 在执行过程中如果改了超过 2 个文件,guard 会自动检测并升级为 full——避免「我以为是个热修复,结果把半个模块重构了」的灾难。
有人可能会说:这个设计增加了复杂度。对,增加了。但它增加的是内部复杂度,用户面对的是一个统一的入口——workflow-start。你不需要告诉它「这个变更用 hotfix」,它会自己判断。
六、小结
今天这一讲,我们把 spec-superflow 的「凭什么」从感性认知推到了工程层面。
如果你只能记住三件事,记住这三件:
- OpenSpec 和 Superpowers 不是竞争关系,而是互补关系——但互补不等于能自动连接。 它们之间的裂缝就是「规划-执行断层」,这个问题在 2026 年被业界认定为 AI 编码的核心失败模式。22% 的 AI 生成的 PR 有代码级失败,根源就在于规划和执行之间缺了一个自动化的锚点。
- bridge-contract 是整个项目的灵魂。 它不是一份给人看的文档模板,而是一个解析引擎自动从 4 个规划工件里提取的可检查契约。它的价值不在于「写了什么」,而在于「执行阶段可以逐条比对、自动拦截违规」。这是把 OpenSpec 的「想清楚」和 Superpowers 的「做对」真正焊接在一起的那道焊缝。
- spec-superflow 的融合方法是「去重叠、留异同、加独创」——而不是「同时装两个」。 市面上其他桥接方案通过外部拼接来实现,拼接点就是漂移点。spec-superflow 选择源码级吸收 + 统一状态机驱动,各取引擎最强部分,然后用 bridge-contract 做传动轴。
这一讲是认知篇的第一篇。下一讲,我们会深入 OpenSpec 的内部——它的 4 工件依赖拓扑、Delta Spec 机制、Schema 验证引擎——你会看到 spec-superflow 的设计篇和实战篇里,每一个「为什么这样设计」的答案,根源都在今天打下的地基里。
七、思考题
- 动手题:找一下你现在手上的项目,回忆最近一次「AI 写出来的代码跟你的预期不一致」的情况。尝试用今天讲的「bridge-contract 六要素」框架分析一下:如果当时有一份契约,哪一条能拦截那个问题?把你的分析框架分享在评论区。
- 判断题:我在文中说「同时装 OpenSpec 和 Superpowers 等于给自己加了一份流程管理员的工作」。但有人说「我就是自己手动切换,不觉得累」。你认为这种说法的前提条件是什么?什么样的项目规模和团队结构下,手动切换是可接受的?
- 迁移题:bridge-contract 的核心思想是「把规划阶段的关键约束压缩成执行阶段可以程序化检查的条目」。这个思路在你的日常工作里,除了 AI 编码,还能用在什么场景?至少想一个。
“🪐 如果 spec-superflow 解决了你一直在头疼的问题—— 去 GitHub https://github.com/MageByte-Zero/spec-superflow 点个 Star ⭐,让更多被 AI 编码「想不清楚就写」折磨的开发者看到这个项目。 安装只需要 10 秒:
/plugin marketplace add MageByte-Zero/spec-superflow然后/plugin install spec-superflow@spec-superflow觉得有用?转发给一个也在用 AI 写代码的朋友,他会感谢你的。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-07-01,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号