光锥之内

光锥之内

用户11705094
发布于 2026-07-02 08:44:06
发布于 2026-07-02 08:44:06

当我们按下回车键,GPT5在几秒钟内吐出一个回答时,我们往往会产生一种错觉,在这个数字世界里,信息的传递是瞬间完成的。
毕竟,光速是每秒30万公里。对于生活在米级尺度的人类来说,这个速度意味着即时。
但是,当我们把镜头推得足够近,进入到那个由纳米晶体管和硅光子构成的微观世界时,光速就不再是一个代表无限快的常量,而变成了一把沉重的慢镜头约束。
物理学给了我们一个简洁的公式:
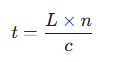

这个公式告诉我们一个反直觉的事实,在光纤的玻璃介质中,光速被打折到了真空的三分之二。
这意味着信号每跑1米,需要5纳秒(1纳秒等于十亿分之一秒)。
在H100芯片内部,时钟频率高达1.8GHz,每一个时钟周期仅为0.56纳秒。
在一个周期内,即使是宇宙中跑得最快的光,也仅仅只能前进15厘米,大概就是手机屏幕的长度。
也就是说,光信号仅仅在光纤里跑过1米的距离,芯片内部就已经完成了9次完整的运算循环。
这就引出了一个令人细思极恐的物理事实。
在一个拥有数万张显卡、占地数万平方米的超级数据中心里,当位于东区的GPU-A大喊一声“我算完了”,这个声音(信号)要跑到位于西区的GPU-B耳朵里,对于它们那纳秒级的神经系统来说,已经是一次漫长的、跨越了数千个时钟周期的星际旅行。
在这个尺度下,距离即延迟,延迟即损耗。
今天,人类试图通过堆叠十万张甚至百万张显卡,来构建那个全知全能的硅基大脑去寻找AGI。
但我们似乎忘记了,这个庞大的身躯,正被锁死在一个由光速定义的、看不见的光锥之内。

当我们为了追求更强的智能,试图把集群规模从一千张卡扩展到十万张卡时,我们并没有意识到,我们正在唤醒一个名为距离的幽灵。
想象一下,我们要建造一个拥有10万张GPU的超级智算中心。即使我们采用了最先进的液冷技术,把机柜密度做到极致,考虑到供电、散热、过道和维护空间,这个庞然大物的物理占地面积,也将达到数万平方米。
这意味着,连接这台超级计算机最两端的显卡,它们之间的物理光纤长度,可能轻易超过500米,甚至1公里。
信号在光纤中往返这1公里,加上交换机的处理延迟和光电转换的损耗,一次简单的握手,可能需要消耗10-20微秒(1微秒等于一百万分之一秒,1000纳秒)。
20微秒(2万纳秒),对人类来说只是眨眼的万分之一。但对于每秒能进行千万亿次运算的GPU来说,这是一段漫长得令人绝望的空白。
在这段时间里,那些昂贵的Tensor Core只能停下来,无所事事地空转。
这就是计算机科学中著名的阿姆达尔定律(Amdahl's Law)所预言的那堵高墙:
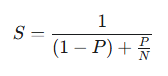

无论你的GPU数量N堆得多么大,系统的总加速比S,最终都会被那个无法被并行的串行比例(1-P) 死死锁住。
而在万卡集群中,光速延迟就是那个最顽固的、永远无法消除的(1-P)。
随着集群规模的指数级扩大,物理距离线性增加,通信延迟占比越来越高。直到某一个临界点,再增加显卡,系统的总算力不仅不会增加,甚至可能因为通信拥堵而崩塌。
这解释了为什么华为要搞全光互联,为什么英伟达要搞NVLink Switch,他们都是在拼命地把那块短板补长一点点,试图把阿姆达尔之墙往后推几米。
我们可以再做一个极简的物理推演:
为了不让阿姆达尔定律的惩罚过于严厉,假设我们要把通信延迟控制在GPU还能忍受的10 微秒以内。
光在10微秒内,只能在光纤里跑2公里。扣除交换机的处理时间,这意味着整个集群的物理直径被锁死在了200米左右。
在这个200米的圆圈里,以现在的技术,不管怎么做,我们最多也只能塞进去大约50万到100万张显卡。
百万卡集群就是当前物理学允许的的最大规模。
一旦超过这个规模,光速的延迟将超过计算的节拍,增加显卡不再带来算力的提升,只会带来无尽的等待和熵增。

面对这道不可逾越的光速之墙,地球上最聪明的两群工程师,给出了两种截然相反的解题思路。
第一种解法,来自英伟达的做小、做密,我称之为极致的向心力。
既然距离是延迟的根源,黄仁勋的策略简单而粗暴:那就消灭距离。
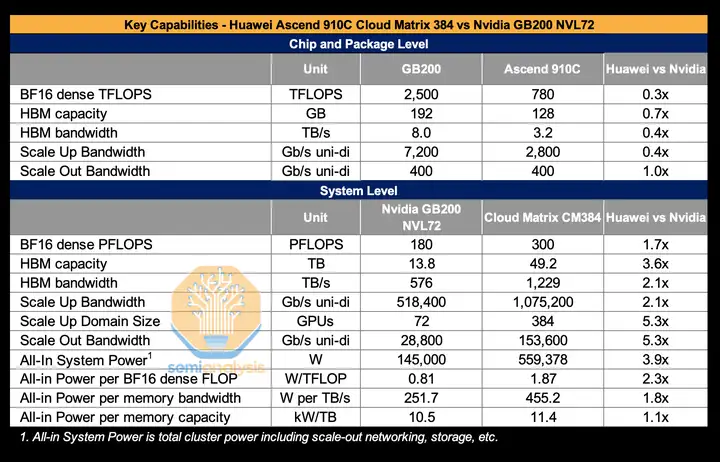
在最新的GB200 NVL72机柜中,英伟达做了一件极其疯狂的事。他们把72张顶级的Blackwell GPU,强行塞进了一个高密度的机柜里,然后用5000根铜缆,像神经网络一样把它们物理焊接在了一起。
为什么是铜缆?因为在极短的距离内,铜比光更快,更省电。
在这个机柜内部,72张卡不再是独立的个体,它们通过NVLink这个超高速总线,融合成了一块虚拟的巨型GPU。在这里,数据传输几乎没有延迟,算力密度达到了物理学的极限。

第二种解法,来自华为的做大、做广,我称之为宏大的离心力。
华为的策略是:如果距离无法消除,那我就把路修到极致。
这就是华为提出的以网强算战略。利用其在通信领域的霸主地位,华为正在构建一张庞大的、扁平的全光互联网络。
他们用全光交换机 (OXC)取代了传统的电交换,消灭了光电转换的延迟。他们优化了RoCE协议,让以太网也能跑出InfiniBand的效率。
英伟达试图把世界压缩进一个机柜。
优点是内部通信极快(铜缆),延迟极低,写程序简单,就像在一台电脑上写。
缺点是贵、热、难修,而且有物理极限,你很难把1万张卡塞进一个柜子。
而华为试图把整个数据中心编织成一张光速的网。
优点是便宜、灵活、无限扩展,坏了一台换一台,不影响整体。
缺点是延迟高, 指挥这1万只蚂蚁协同工作,比指挥一个绿巨人要难一万倍。
这是一场密度与广度的对决。
英伟达赌的是,大力出奇迹的单点极致。在光速的枷锁下,唯有抱团取暖(Scale-up,纵向扩展)才能突破极限。
华为赌的是,三个臭皮匠顶个诸葛亮的群体涌现。只要管道足够宽、速度足够快,分布式(Scale-out,横向扩展)的蚁群也能涌现出智能。

然而,无论是英伟达的铜缆,还是华为的光纤,它们本质上都在做同一件事,搬运数据。
只要我们还在使用冯·诺依曼架构,计算单元(CPU/GPU)和存储单元(内存/显存)就是分离的。数据就像是一个不知疲倦的快递员,必须在两者之间来回奔波。
我们今天所有的努力,不过是给这个快递员换了一辆更快的跑车(光纤),或者把仓库搬到了工厂隔壁(HBM)。
但只要路还在,光速的限制就还在。
真正的终局,也许不在于如何跑得更快,而在于不再奔跑。
一种可能的未来是存算一体 (Processing In Memory)。
我们不再把数据搬去计算,而是直接在数据存储的地方进行计算。让每一颗内存颗粒都拥有智能,让计算在数据发生的瞬间原地完成。这就像是让仓库里的每一粒米,自己变成了饭。
另一种更科幻的未来是光子计算。
既然电子跑不过光子,那为什么不直接用光来做计算?让光在干涉和衍射的瞬间,完成矩阵的乘法。在那一刻,传输即计算,过程即结果。
这才是对光速枷锁的终极破解。
它不再试图战胜时间,而是让计算与时间融为一体。
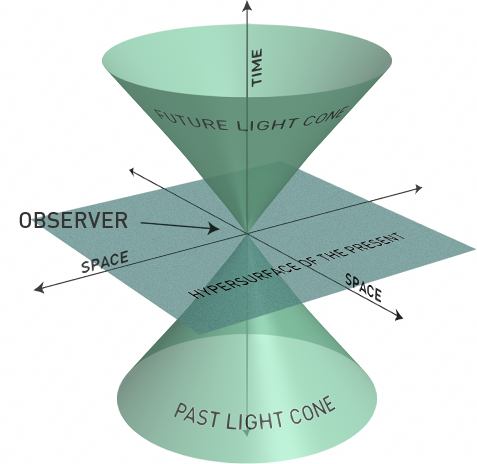
爱因斯坦的相对论告诉我们,任何信息的传播速度都无法超越光速。这个速度限制,画出了一个名为光锥的时空边界。
在光锥之外,是不可触及的未来。在光锥之内,是我们能影响的因果。
我们今天所有的努力,把芯片堆叠得更高、把光纤拉得更直、把网络编织得更密。本质上,都是人类这个物种,在光锥的边缘,试图多抢回那一纳秒的时间。
这不仅是一场关于算力的战争,这是一场关于时空的博弈。
虽然光速的枷锁冰冷而坚硬,但人类的智慧,正是在这种戴着镣铐的舞蹈中,进化出了最璀璨的文明。
我们也许永远无法超越光速,但我们永远在逼近那个极限。
而在那个极限的尽头,或许就藏着我们要寻找的,硅基灵魂的火花。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-11-26,如有侵权请联系 cloudcommunity@tencent.com 删除
本文分享自 magicyuan的AI随笔记 微信公众号,前往查看
如有侵权,请联系 cloudcommunity@tencent.com 删除。
本文参与 腾讯云自媒体同步曝光计划 ,欢迎热爱写作的你一起参与!
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号