构建 Claude Code 的经验:Prompt Caching 是一切

构建 Claude Code 的经验:Prompt Caching 是一切

用户1640761
发布于 2026-07-01 21:55:35
发布于 2026-07-01 21:55:35
转发:构建 Claude Code 的经验:Prompt Caching 是一切
作者:Thariq(@trq212) 发布时间:2026 年 2 月 20 日
原文链接:https://x.com/trq212/status/2024574133011673516
工程里常说一句话:“Cache Rules Everything Around Me(缓存支配我周围的一切)”,这条规律同样适用于 Agent。
像 Claude Code 这样的长时运行型 Agent 产品之所以可行,正是因为有了 Prompt Caching。它让我们能够复用前几轮请求中的计算结果,从而显著降低延迟和成本。
什么是 Prompt Caching?它是怎么工作的?又该如何在工程上把它实现出来?
在 Claude Code 中,我们几乎是围绕 Prompt Caching 来设计整个 Harness 的。高缓存命中率可以显著降低成本,也能帮助我们为订阅计划提供更宽松的速率限制。因此,我们会为 Prompt Cache Hit Rate 设告警;如果它太低,我们甚至会按 SEV 级别来处理。
下面这些,就是我们在大规模优化 Prompt Caching 时总结出的经验。其中不少结论,最开始其实都相当反直觉。
规划缓存提示

图片 1
图片 1
Prompt Caching 的工作方式是“前缀匹配(prefix matching)”。API 会从请求开头开始缓存,一直缓存到每个 cache_control 断点为止。
这意味着,你把内容放进 Prompt 的顺序极其重要。你需要尽可能让更多请求共享相同的前缀。
最好的方式是:静态内容放前面,动态内容放后面。对 Claude Code 来说,大致是这样:
- 1.
静态的 system prompt 和 tools(全局缓存) - 2.
CLAUDE.md(在项目内缓存) - 3.
Session context(在会话内缓存) - 4.
Conversation messages(对话消息)
这样我们就能最大化不同 session 之间共享缓存命中的概率。
但这件事有时会脆弱得超出预期。我们以前就因为很多原因破坏过这个顺序,比如把过于精细的时间戳放进静态 system prompt、以非确定性方式打乱工具定义顺序、修改工具参数(例如 AgentTool 能调用哪些 agents)等等。
使用消息进行更新
有些时候,你放进 Prompt 里的信息会过时,比如时间变化了,或者用户修改了某个文件。你会很自然地想去更新 Prompt,但这么做会导致 Cache Miss,而且对用户来说,成本可能相当高。
这时可以考虑,是否能把这些变化通过下一轮的 messages 传进去。比如在 Claude Code 里,我们会在下一条用户消息或工具结果里加一个 <system-reminder> 标签,把更新后的信息传给模型,例如“现在已经是周三了”。这样就能尽量保住缓存。
不要在会话中途更改模型
Prompt Cache 是按模型隔离的,这会让缓存成本的计算方式变得相当反直觉。
如果你已经和 Opus 对话到了 100k tokens,这时只是想问一个相对简单的问题,那么切到 Haiku 实际上可能比继续让 Opus 回答还更贵,因为我们得给 Haiku 重新构建一遍 Prompt Cache。
如果确实需要切模型,最好的做法是用 Subagents。也就是让 Opus 先给另一个模型准备一条 handoff 消息,说明它需要完成什么任务。我们在 Claude Code 里经常这么做,比如 Explore agents 就会用 Haiku。
切勿在会话期间添加或删除工具
在对话进行到一半时修改工具集,是最常见的 Prompt Caching 破坏方式之一。这看起来很合理,因为你可能会觉得“只把模型当前需要的工具给它”才是最优解。但由于工具本身也是缓存前缀的一部分,只要你新增或移除一个工具,整段对话的缓存就会失效。
Plan Mode — Design Around the Cache
Plan mode 就是一个很好的例子,它说明了功能设计应该围绕缓存约束来展开。最直觉的做法是:当用户进入 plan mode 时,把工具集替换成只读工具。但这会直接破坏缓存。
相反,我们会始终在请求里保留全部工具,同时把 EnterPlanMode 和 ExitPlanMode 本身也设计成工具。当用户打开 plan mode 时,Agent 会收到一条 system message,告诉它当前处于 plan mode,以及此时的规则是什么,比如探索代码库、不要编辑文件、计划完成后调用 ExitPlanMode。工具定义本身始终不变。
这样还有一个额外好处:因为 EnterPlanMode 本身就是模型可以主动调用的工具,所以它在发现问题较难时,可以自主进入 plan mode,而不会导致任何缓存断裂。
Tool Search — Defer Instead of Remove
同样的原则也适用于我们的 Tool Search 功能。Claude Code 可能会加载几十个 MCP tools,如果把它们全都塞进每一次请求里,成本会很高;但如果在对话中途把它们移除,又会破坏缓存。
我们的解决方案是:defer_loading。我们不移除工具,而是发送轻量级的 stub,只包含工具名,并带上 defer_loading: true。模型在需要时,可以通过 ToolSearch 工具去“发现”它们。只有当模型真正选中某个工具时,我们才加载完整的工具 schema。
这样做的好处是,缓存前缀始终稳定:同样的 stubs 总是以同样的顺序存在。
幸运的是,你现在也可以通过我们的 API 直接使用 tool search 工具,来把这件事简化掉。
图片 2
图片 2
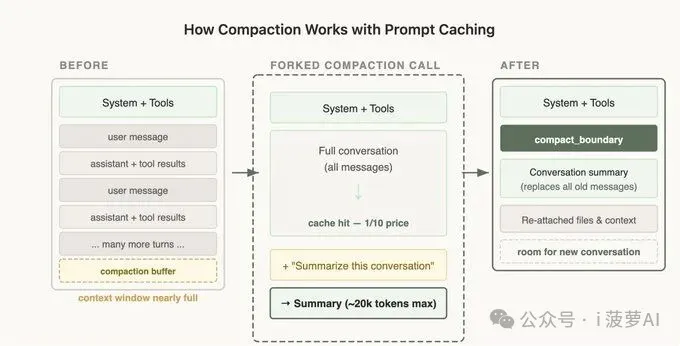
分叉上下文 — 压缩
当你用完整个上下文窗口时,就会发生 Compaction。我们会把到目前为止的对话做一次总结,然后带着这个摘要继续开启一个新会话。
让人意外的是,Compaction 在 Prompt Caching 上有很多边界情况,而且往往并不直观。
最典型的一种情况是:当我们做 Compaction 时,需要把整段对话重新发给模型,让它生成摘要。如果这是一次独立的 API 调用,而且它用了不同的 system prompt,也没有任何工具定义,这虽然是最简单的实现方式,但它和主对话的缓存前缀就完全对不上了。
这意味着,用户需要为这些输入 tokens 支付全价,成本会被大幅拉高。
The Solution — Cache-Safe Forking
因此,在执行 Compaction 时,我们会使用和父对话完全一致的 system prompt、user context、system context 以及工具定义。我们先把父对话的 conversation messages 放在前面,然后把 compaction prompt 作为一条新的用户消息追加到最后。
从 API 的角度看,这个请求和父对话最后一次请求几乎一模一样:同样的前缀、同样的工具、同样的历史。因此,缓存前缀就可以被直接复用,新增的 tokens 只剩 compaction prompt 本身。
当然,这也意味着我们需要额外保留一个“compaction buffer”,确保上下文窗口里有足够空间容纳 compact 消息和摘要输出所需的 tokens。
Compaction 很棘手。不过好消息是,你不需要自己再踩一遍这些坑了。基于我们在 Claude Code 里的经验,我们已经把 compaction 直接内建进了 API,所以你可以把这些模式直接用到自己的应用里。
经验教训
- 1. Prompt Caching 本质上是前缀匹配。只要前缀中的任意位置发生变化,其后的所有内容都会失效。因此,你应该围绕这个约束来设计整个系统。只要顺序排对,大部分缓存收益几乎是“白送”的。
- 2. 尽量用 messages,而不是修改 system prompt。你可能会想通过编辑 system prompt 来进入 plan mode、修改日期等,但更好的方式,通常是在对话过程中把这些信息插入到 messages 里。
- 3. 不要在对话中途切换工具或模型。应该用工具来表达状态变化,比如进入 plan mode,而不是直接改工具集。对于工具,尽量用延迟加载,而不是移除。
- 4. 像监控 uptime 一样监控缓存命中率。我们会对 cache break 做告警,并把它当成事故来处理。哪怕只是几个百分点的 miss rate,也会显著影响成本和延迟。
- 5. 所有分叉操作都应该共享父对话的前缀。如果你需要运行一个侧向计算,比如 compaction、summarization 或 skill execution,就应该使用与父对话一致的 cache-safe 参数,这样才能命中父对话前缀的缓存。
Claude Code 从第一天起就是围绕 Prompt Caching 构建的。如果你也在构建 Agent,你最好也这么做。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-22,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号