08-GRPO 为什么能省掉 critic

08-GRPO 为什么能省掉 critic

anzhsoft
发布于 2026-07-01 21:09:24
发布于 2026-07-01 21:09:24
上一篇拆清了 PPO 后训练里的四个角色:actor 才是被 policy loss 更新的主策略,critic 只是给 PPO/GAE 提供 value baseline。第 08 篇继续问一个更具体的问题:GRPO 为什么可以把这条 critic 路径拿掉?
本文的核心判断是:GRPO 不是“没有 baseline”,而是把 baseline 从可学习的 critic value 换成了同一 prompt 下多条 response 的组内相对 reward。这样一来,advantage 计算不再需要 values字段,系统上就可以省掉 value forward 和 critic train 两条路径;但代价是 rollout.n、reward 方差、组内样本质量和长度偏置变得更关键。
先看 GRPO 的核心闭环。读这张图时重点看 uid:它把同一 prompt 的多条 response 绑定成一组,后面的 relative reward 才有比较对象。
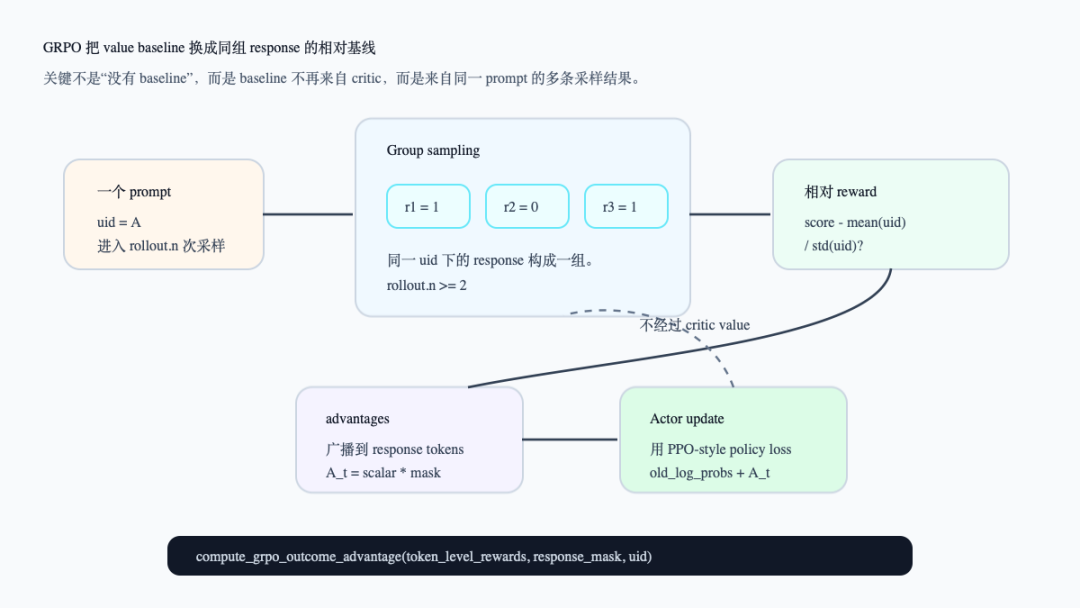
GRPO 的 group-relative 闭环
这张图对应 examples/grpo_trainer/README.md对 GRPO 的描述:它用 group sampling 为同一输入生成多条 completion,再用组内平均 reward 做 baseline,强化高于组内平均的 response,压低低于组内平均的 response(examples/grpo_trainer/README.md:5-9)。README 也把 actor_rollout_ref.rollout.n列为 GRPO 的关键旋钮,并说明总轨迹数是 train_batch_size * rollout.n(examples/grpo_trainer/README.md:21-23)。
1. group sampling 是省 critic 的前提
GRPO 的前提不是“每个 prompt 生成一条 response”,而是“同一个 prompt 生成多条 response”。在 RayPPOTrainer.fit()里,trainer 会给原始样本补 uid,再把 gen_batch按 rollout.n做 repeat;生成完成后,主 batch 也按同样倍数 repeat,并和 rollout 输出做 union()(verl/trainer/ppo/ray_trainer.py:1330-1407)。
这一步让 DataProto 里出现一种结构:多行样本拥有同一个 uid,但各自的 responses、reward 和 logprob 不同。GRPO 的 baseline 就从这个结构里来。没有这个组,只有单条 response,组内平均就没有统计意义;源码里如果某个 uid 只有一个 score,会把 mean 设成 0、std 设成 1,这是兜底,不是理想训练形态(verl/trainer/ppo/core_algos.py:314-321)。
这也解释了为什么 GRPO 对 rollout 吞吐更敏感。省掉 critic 后,系统少了一条训练链路;但每个 prompt 要生成多条 response,rollout 阶段的 token 数、长尾 response 和 reward 调用都会被放大。
2. 源码分叉点在 advantage,不在 actor loss
PPO 和 GRPO 的 actor update 仍然都会走 policy loss。真正的分叉发生在 advantage 计算。
compute_advantage()的 GAE 分支会把 token_level_rewards、values和 response_mask传给 compute_gae_advantage_return(),再写回 advantages和 returns(verl/trainer/ppo/ray_trainer.py:166-182)。GRPO 分支则只把 token_level_rewards、response_mask和 data.non_tensor_batch["uid"]传给 compute_grpo_outcome_advantage()(verl/trainer/ppo/ray_trainer.py:183-195)。
下面这张图把资源路径差异画出来。它要强调的是:GRPO 省掉的不是 reward、old logprob 或 actor update,而是 critic value 和 critic train。
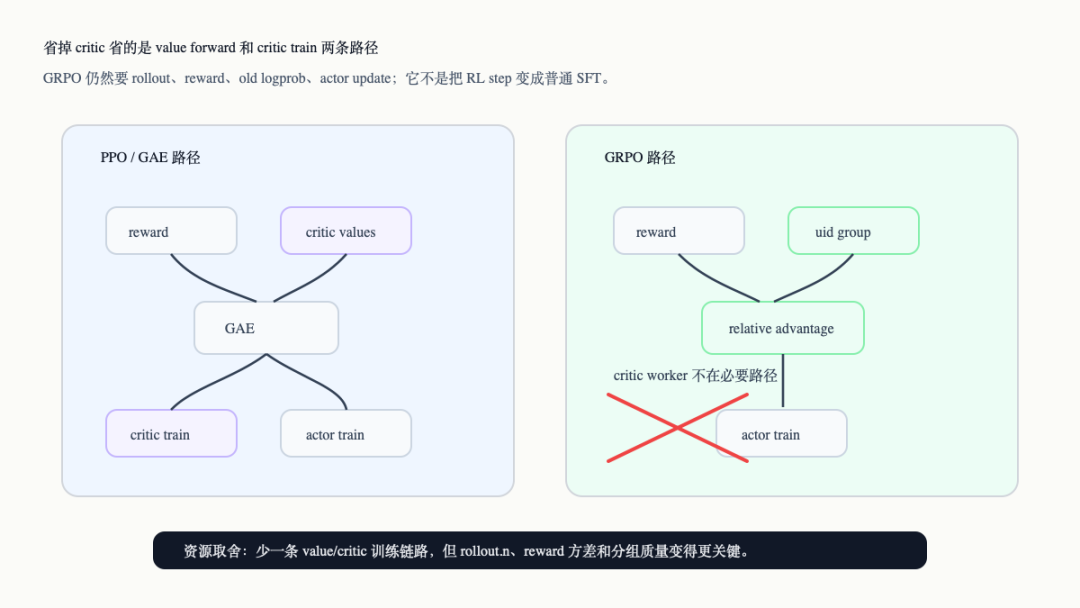
PPO 与 GRPO 的资源路径差异
资源层面,这个差异很直接。PPO/GAE 需要先调用 _compute_values()取得 values,再在更新阶段调用 _update_critic()训练 value model(verl/trainer/ppo/ray_trainer.py:1130-1142,verl/trainer/ppo/ray_trainer.py:1247-1272)。GRPO 的 advantage 分支不消费 values,所以它的必要路径里没有这两步。
3. GRPO 的字段合同更窄
判断一个算法在工程里能不能省掉某个 worker,最可靠的方法不是看算法名,而是看它消费哪些字段。
compute_grpo_outcome_advantage()先把 token_level_rewards沿 response 维求和,得到每条 response 的 outcome score;然后按 index,也就是 uid,把同组 score 收集起来,计算组内 mean/std;最后把归一化后的 scalar 乘以 response_mask,广播成 token-level advantages,并把同一个张量同时作为 returns 返回(verl/trainer/ppo/core_algos.py:267-331)。
下面这张图把字段合同单独列出来。看图时注意红叉:values是 PPO/GAE 的输入,不是 GRPO 分支的输入。
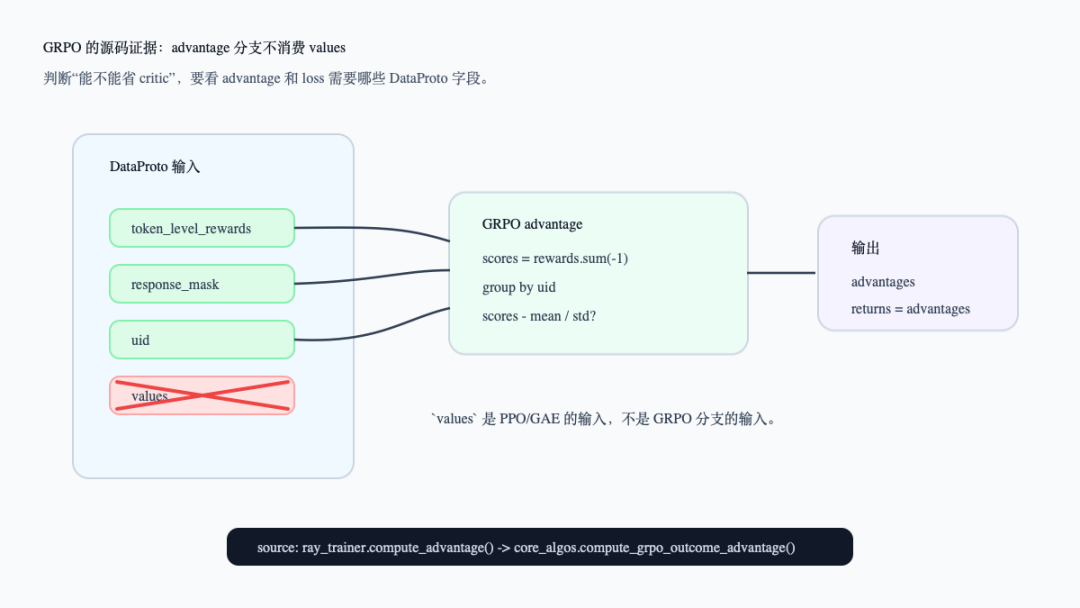
GRPO 的 DataProto 字段合同
这也是 GRPO 的工程边界:它仍然需要 old_log_probs去构造 actor loss,需要 response_mask去限制有效 token,需要 reward 去提供 outcome score;只是它不再需要 critic 预测一个 value baseline。
4. 省 critic 后,压力转向采样、reward 和长度
GRPO 的收益很清楚:少一个 value model,少一次 value forward,少一条 critic train 链路,也少一部分显存和调度复杂度。但这些收益不是免费的。
第一,rollout.n 变成算法质量和系统吞吐的共同旋钮。n 太小,组内相对比较不稳定;n 太大,生成、reward、logprob 和 DataProto 字段都会放大。README 里把 data.train_batch_size * rollout.n明确写成总轨迹数,就是这个原因(examples/grpo_trainer/README.md:21-23)。
第二,reward 方差变关键。GRPO 用组内 reward 相对差来给 actor 指方向。如果同组 response 的 reward 全部一样,relative advantage 会接近退化;如果 reward 噪声很大,模型会跟着噪声更新。
第三,长度偏置会更显性。compute_grpo_outcome_advantage()把 outcome reward 的相对 scalar 乘到每个 valid response token 上(verl/trainer/ppo/core_algos.py:329-331);actor loss 又会通过 loss_agg_mode聚合 token loss(verl/trainer/ppo/core_algos.py:1141-1199)。长答案和短答案在 token 维度上的权重差异,不能被 critic 自动吸收。
最后这张图把这些取舍放在一起。它和前面的“省 critic”形成互补:省掉了哪条路径,就要在哪些地方补管理。
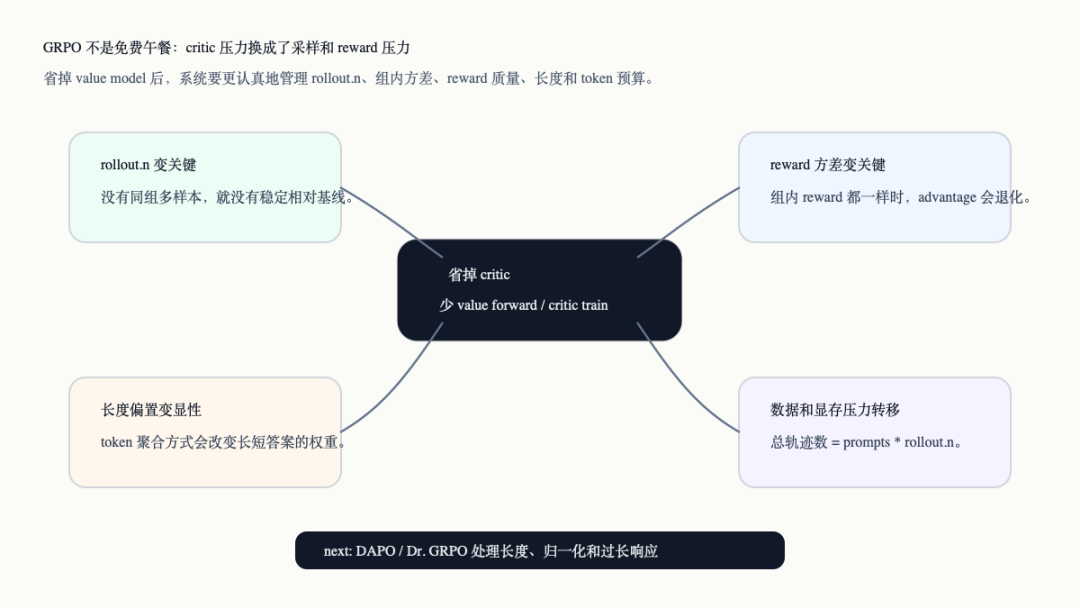
GRPO 省 critic 后的取舍地图
从系统角度看,GRPO 把复杂度从 value model 挪到了 rollout、reward 和 loss 聚合上。它让角色图更轻,但让样本组织、reward 形状和长度处理更重要。
小结:GRPO 省掉的是 critic 路径,不是训练约束
GRPO 可以省掉 critic,因为它的 advantage 不从 value model 来,而从同一 prompt 的多条 response 的相对 reward 来。源码上的证据很明确:GRPO 分支不读 values,而是读 token_level_rewards、response_mask和 uid。
但这不意味着 GRPO 更简单到没有系统问题。它只是把 critic 的建模和训练成本,换成了 group sampling、reward 可靠性、rollout 吞吐、长度偏置和 loss 聚合的工程约束。
下一篇继续沿着这个约束写:DAPO-style recipe 和 Dr. GRPO 不是新增一个 worker,而是在 GRPO 主线上处理 overlong reward、advantage 归一化和 token/sequence 聚合带来的长度偏置。
本文源码索引
examples/grpo_trainer/README.md:5-17:GRPO 的 group sampling、relative rewards 和 critic-less 描述。examples/grpo_trainer/README.md:21-28:GRPO 的关键配置旋钮。verl/trainer/ppo/ray_trainer.py:1330-1407:uid、rollout.nrepeat 和 rollout output union。verl/trainer/ppo/ray_trainer.py:166-195:GAE 与 GRPO 在compute_advantage()中的分支差异。verl/trainer/ppo/ray_trainer.py:1130-1142:PPO/GAE critic value 计算路径。verl/trainer/ppo/ray_trainer.py:1247-1272:critic update 路径。verl/trainer/ppo/core_algos.py:267-331:GRPO 如何按 uid 计算组内相对 advantage。verl/trainer/ppo/core_algos.py:1141-1199:actor loss 的聚合模式如何影响 token/sequence 权重。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-22,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号