Voicebox:本地优先的 AI 语音工作室

Voicebox:本地优先的 AI 语音工作室

山行AI
发布于 2026-07-01 18:28:40
发布于 2026-07-01 18:28:40
前言

Voicebox Icon
如果一个 AI 语音工具只能“把文字念出来”,它只是 TTS。如果它还能克隆声音、听写输入、管理声音人格、编辑多角色故事,并让 Claude Code、Cursor、Cline 这类 Agent 用你指定的声音说话,那它就变成了一套完整的 voice I/O stack。
Voicebox[1] 正是这样的项目。它的定位是:开源 AI voice studio。官方一句话是:Clone, dictate, create。也就是:克隆声音、听写输入、创作语音内容。
更重要的是,它强调 local-first:模型、声音数据、捕获音频和生成内容默认都在本机运行和保存。对于语音这种高度敏感的数据,这个方向比“全部上传云端生成”更适合开发者、创作者和需要隐私边界的团队。
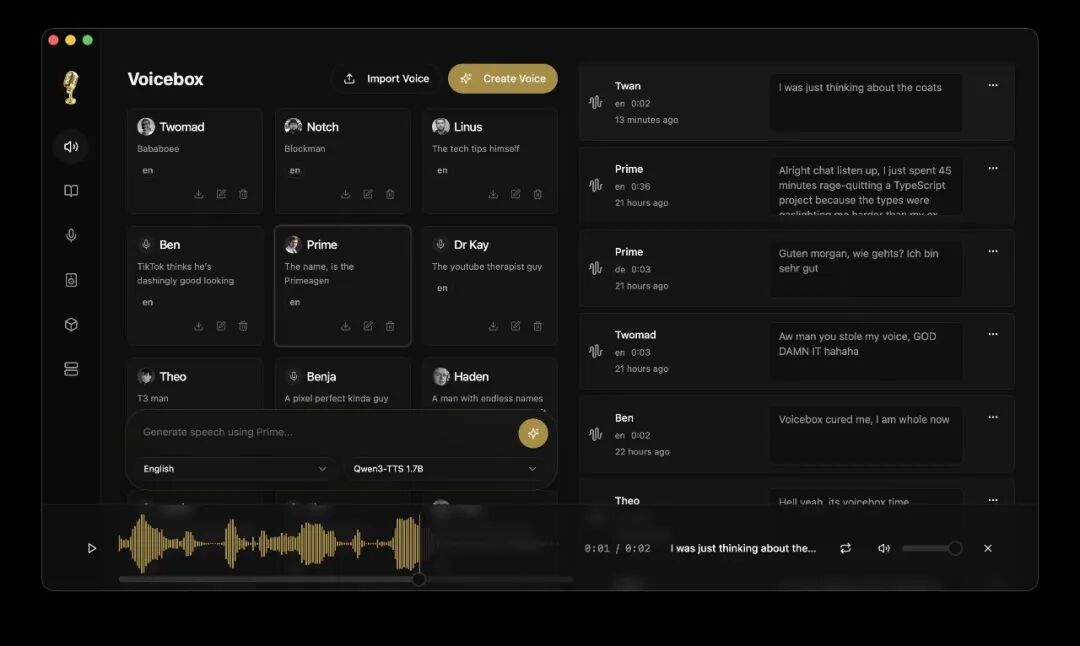
Voicebox App Screenshot 1
它到底是什么
Voicebox 可以理解为 ElevenLabs 和 WisprFlow 的开源本地替代,但它不只是把两者拼在一起。
ElevenLabs 更偏语音输出:克隆声音、生成语音。WisprFlow 更偏语音输入:听写、转写、输入到应用。Voicebox 同时覆盖两端,并把中间的“人格重写、本地 LLM、MCP Agent 接入、故事编辑、音频后处理”也串起来。
它覆盖三条主线:
•Voice Output:TTS、多引擎语音生成、声音克隆、预设声音、情绪标签、音频效果、长文本生成。
•Voice Input:全局热键听写、Whisper 转写、自动粘贴、Captures 管理、转写 refinement。
•Agent Voice:通过 REST API 和 MCP Server,让 Claude Code、Cursor、Cline、Windsurf 等 MCP-aware agent 调用 voicebox.speak 发声。
README 原始截图
下面三张应用截图来自项目 README,保留原图位,便于观察官方展示的产品形态。
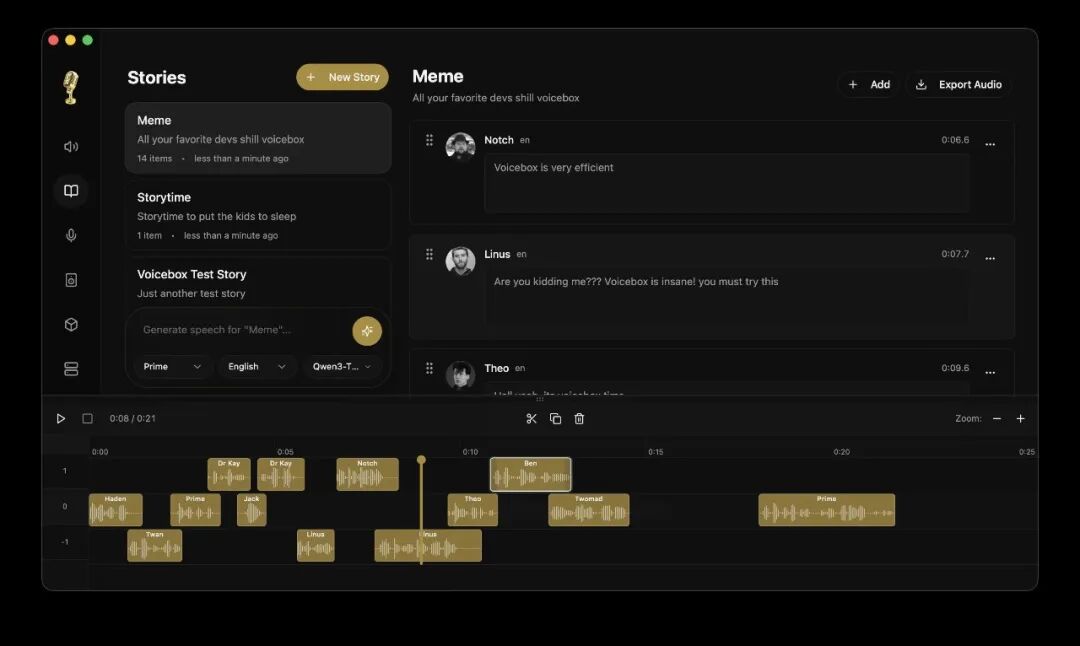
Voicebox App Screenshot 2
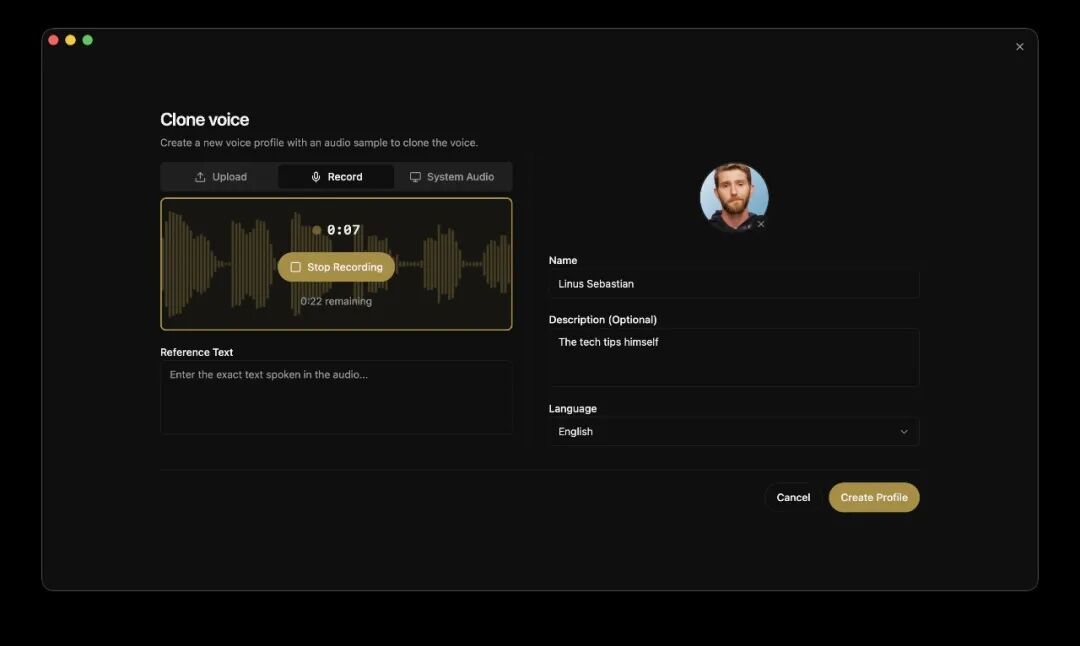
Voicebox App Screenshot 3
从截图和 README 描述看,Voicebox 不是命令行 demo,而是完整桌面应用:有声音 profile、生成历史、设置、故事编辑、模型管理、捕获记录和 Agent 接入配置。
功能架构图
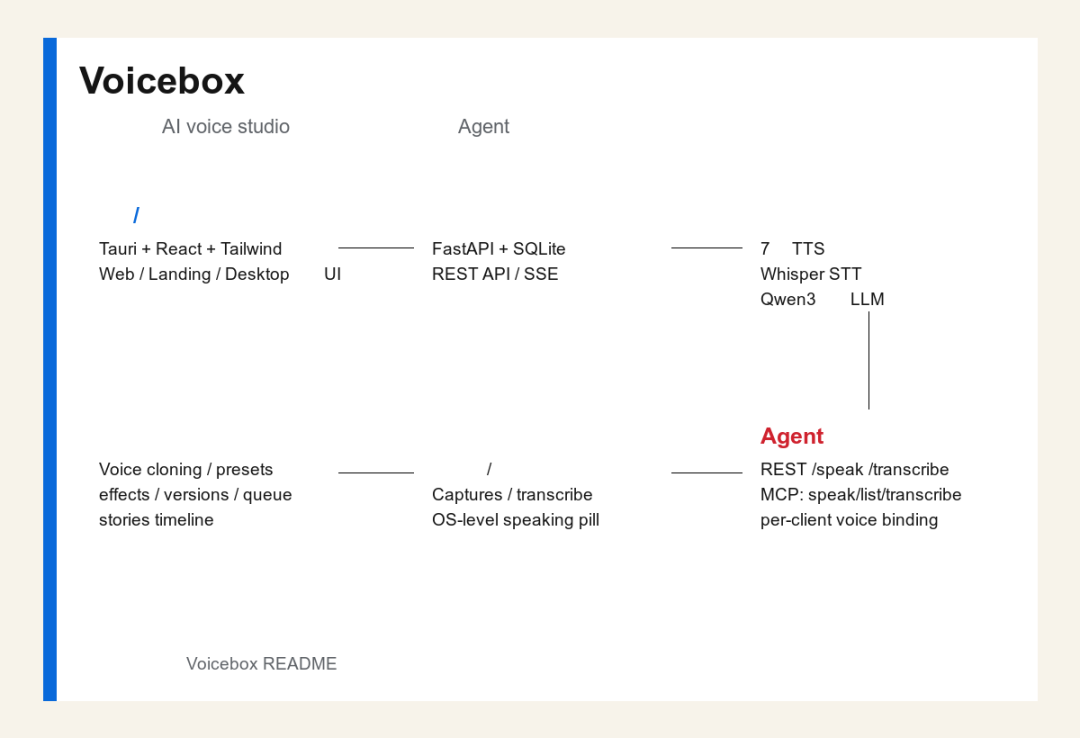
Voicebox 功能架构图
从仓库结构和 README 看,Voicebox 的架构可以拆成六层。
第一层:桌面与前端层
项目使用 Tauri + React + TypeScript + Tailwind。app/ 是共享 React 前端,tauri/ 是桌面应用,web/ 是 Web deployment,landing/ 是营销网站。
这说明它不是 Electron 应用,而是用 Rust/Tauri 承担原生能力,例如全局热键、自动粘贴、焦点检测、OS-level overlay 等。
第二层:后端服务层
backend/ 是 Python FastAPI 服务,提供 REST API、MCP server、模型推理调度、数据库和音频处理逻辑。默认端口是 17493,Docker Compose 也把它绑定在 127.0.0.1:17493,强调本机访问。
第三层:模型推理层
Voicebox 集成 7 个 TTS 引擎:Qwen3-TTS、Qwen CustomVoice、LuxTTS、Chatterbox Multilingual、Chatterbox Turbo、HumeAI TADA、Kokoro。
STT 使用 OpenAI Whisper / Whisper Turbo。本地 LLM 使用 Qwen3 0.6B / 1.7B / 4B,用于 dictation refinement 和 personality rewrite。
第四层:音频能力层
包括声音克隆、预设 voice、无限长文本自动分块、crossfade、generation versions、takes、favorites、音频效果链和 Stories 多轨编辑器。
第五层:系统输入输出层
全局听写通过热键触发,macOS 上支持 accessibility-verified 自动粘贴,并保留剪贴板。Captures 会保存每次听写、录音、上传音频和对应 transcript。
第六层:Agent 接入层
Voicebox 同时提供 REST API 和 MCP Server。Agent 可以通过 voicebox.speak 说话,也可以调用转写、列出 captures、列出 profiles。不同 Agent 还能绑定不同 voice profile,听声音就知道是谁在说。
使用流程图
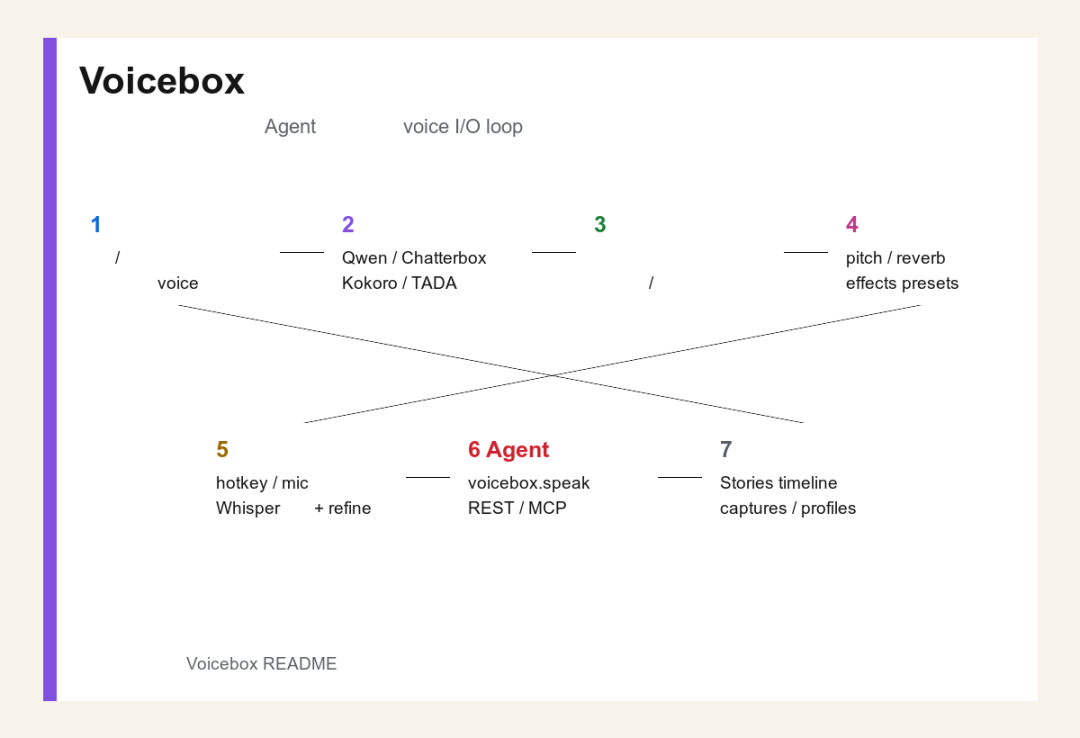
Voicebox 使用流程图
一个典型使用流程可以这样理解。
1创建 voice profile:上传参考音频、录制样本,或选择 Kokoro / Qwen CustomVoice 的预设声音。
2选择 TTS 引擎:根据语言、质量、速度、显存和表达能力选择不同模型。
3输入文本并生成:长文本会自动分块,队列串行执行,避免 GPU 竞争。
4做音频后处理:使用 pitch shift、reverb、delay、chorus、compressor、gain、高通/低通滤波等效果。
5用全局听写输入:按热键讲话,Whisper 转写,再用本地 LLM 清理口头语和 false starts。
6让 Agent 发声:Claude Code、Cursor 等通过 MCP 或 REST 调 voicebox.speak。
7进入创作和管理:Captures 保存输入,Stories 编辑多角色内容,profiles 管理声音资产。
这就是 Voicebox 的核心价值:它把语音输入、语音输出、语音创作和 Agent 语音交互放在同一个本地闭环里。
语音生成:7 个 TTS 引擎
README 中列出了 7 个 TTS 引擎,每个定位不同。
•Qwen3-TTS:支持 10 种语言,适合高质量多语言克隆,也支持自然语言 delivery instructions,比如“speak slowly”“whisper”。
•Qwen CustomVoice:支持 10 种语言,提供 9 个 curated preset voices,不需要参考音频,也支持自然语言控制语气。
•LuxTTS:英文,轻量,约 1GB VRAM,48kHz 输出,CPU 上也很快。
•Chatterbox Multilingual:覆盖 23 种语言,是语言覆盖面最广的引擎。
•Chatterbox Turbo:英文,350M 快速模型,支持 [laugh]、[sigh]、[gasp] 等 paralinguistic tags。
•TADA:HumeAI speech-language model,有 1B / 3B 版本,适合较长连贯音频和 text-acoustic alignment。
•Kokoro:8 种语言,50 个 curated preset voices,82M 小模型,CPU 推理快。
这里最大的特点不是“模型多”,而是每个 voice profile、generation、story 和 Agent 调用都可以根据场景选择不同引擎。
情绪标签与后处理
Voicebox 的 expressive speech 主要由 Chatterbox Turbo 承担。只有 Chatterbox Turbo 会解释 [laugh]、[chuckle]、[gasp]、[cough]、[sigh]、[groan]、[sniff]、[shush]、[clear throat] 这类标签;其他模型会把它们当普通文本读出来。
音频后处理由 Spotify 的 pedalboard 驱动,支持 8 类效果:
•Pitch Shift
•Reverb
•Delay
•Chorus / Flanger
•Compressor
•Gain
•High-Pass Filter
•Low-Pass Filter
README 还提到内置 4 个 preset:Robotic、Radio、Echo Chamber、Deep Voice,并支持用户自定义 preset。
长文本、版本和异步队列
Voicebox 不限制在短句 TTS。长文本会自动按句子边界分块,每段独立生成,再 crossfade 拼接。
•自动分块长度可配置:100 到 5,000 字符。
•crossfade 可配置:0 到 200ms。
•最大文本长度:50,000 字符。
•智能切分会处理缩写、CJK 标点和标签。
每次 generation 还支持多版本:Original 永久保留,effects versions 记录效果链,takes 用不同 seed 重新生成,source tracking 记录来源,favorites 用于快速筛选。
异步队列则解决 GPU 竞争:提交一个 generation 后可以继续输入下一个,后台串行执行,SSE 实时返回状态,失败任务可重试,崩溃后的 stale generations 会在启动时恢复。
语音输入:听写、转写和 Captures
Voicebox 的另一半是 voice input。
全局听写支持 hold-to-speak 和 tap-to-toggle 热键。macOS 上支持目标感知粘贴:通过 Accessibility 验证当前焦点输入框,保存并恢复剪贴板,避免把用户剪贴板弄乱。
STT 使用 Whisper / Whisper Turbo,在 Apple Silicon 上走 MLX,在 CUDA / ROCm / DirectML / CPU 上走 PyTorch。
Captures 则把每次听写、应用内录音、上传音频都保存下来:原始音频、transcript、重新转写、refine、inline edit、转成 voice sample、用某个 voice profile 朗读,都在同一套记录里。
Agent Voice Output:让 Agent 真的开口
这是 Voicebox 很有辨识度的部分。
README 里的示例非常简单:
class="language-ts">await voicebox.speak({
text: "Deploy complete.",
profile: "Morgan",
});
只要是 MCP-aware agent,比如 Claude Code、Cursor、Windsurf、Cline、VS Code MCP extensions,都可以接入内置 MCP Server。
HTTP MCP 配置示例:
class="language-json">{
"mcpServers": {
"voicebox": {
"url": "http://127.0.0.1:17493/mcp",
"headers": { "X-Voicebox-Client-Id": "cursor" }
}
}
}
Stdio-only client 可以指向 app 内置的 voicebox-mcp binary。
内置 MCP 工具包括:
•voicebox.speak
•voicebox.transcribe
•voicebox.list_captures
•voicebox.list_profiles
更细的是,Voicebox 支持 per-agent voice binding。例如 Claude Code 绑定 Morgan,Cursor 绑定 Scarlett。Agent 发声时 OS-level speaking pill 会显示正在说话的 voice profile,避免后台静默播放。
Voice Personalities:声音也有角色设定
每个 voice profile 可以绑定一段 personality:这个声音是谁、怎么说话、关心什么。
当 personality 存在时,生成框里会出现两个动作:
•Compose:生成一段符合该角色的新台词。
•Speak in character:把用户输入先通过本地 Qwen3 LLM 改写成该角色口吻,再送进 TTS。
Agent 也可以通过 MCP 传 personality: true 使用同一条路径:text → personality LLM → TTS。
这让 Voicebox 不只是工具,更像是面向游戏、互动角色、播客、辅助沟通和 Agent dev loop 的声音角色系统。
API 与本地服务
Voicebox 暴露 REST API,默认地址是:http://127.0.0.1:17493。
常用接口包括:
class="language-bash">"color:#6a9955"># 生成语音
curl -X POST http://127.0.0.1:17493/generate \
-H "Content-Type: application/json" \
-d '{"text": "Hello world", "profile_id": "abc123", "language": "en"}'
"color:#6a9955"># Agent voice output
curl -X POST http://127.0.0.1:17493/speak \
-H "Content-Type: application/json" \
-H "X-Voicebox-Client-Id: my-script" \
-d '{"text": "Deploy complete.", "profile": "Morgan"}'
"color:#6a9955"># 转写音频
curl -X POST http://127.0.0.1:17493/transcribe \
-F "audio=6a9955">#c586c0">@recording.wav" \
-F "model=whisper-turbo"
"color:#6a9955"># 列出 voice profiles
curl http://127.0.0.1:17493/profiles
Docker Compose 也默认只绑定 localhost,并挂载生成音频目录、数据目录和 HuggingFace 模型缓存,降低误暴露风险。
GPU 与平台支持
README 列出的推理后端很广:
•macOS Apple Silicon:MLX / Metal,利用 Neural Engine 加速。
•Windows / Linux NVIDIA:PyTorch CUDA,应用内自动下载 CUDA binary。
•Linux AMD:PyTorch ROCm,自动配置 HSA_OVERRIDE_GFX_VERSION。
•Windows 任意 GPU:DirectML。
•Intel Arc:IPEX/XPU。
•任何平台:CPU,速度慢但可用。
下载方面,README 提供 macOS Apple Silicon、macOS Intel、Windows、Docker;Linux 预构建包尚未提供,需要按源码构建说明安装。
技术栈和工程结构
从 package.json 和仓库结构看,Voicebox 是一个多端 monorepo。
•app/:共享 React 前端。
•tauri/:Tauri + Rust 桌面应用。
•web/:Web deployment。
•backend/:Python FastAPI server。
•landing/:官网/营销站。
•docs/:文档站。
•scripts/:构建、发布、模型打包等脚本。
主要技术栈包括:
•Desktop:Tauri / Rust
•Frontend:React / TypeScript / Tailwind CSS
•State:Zustand / React Query
•Backend:FastAPI / Python
•TTS:Qwen3-TTS、Qwen CustomVoice、LuxTTS、Chatterbox、TADA、Kokoro
•STT:Whisper / Whisper Turbo
•Local LLM:Qwen3
•MCP Server:FastMCP mounted at /mcp,并提供 stdio shim
•Effects:Spotify Pedalboard
•Database:SQLite
•Audio:WaveSurfer.js、librosa
开发命令也体现了这个结构:
class="language-bash">bun run dev "color:#6a9955"># setup dev sidecar + Tauri dev
bun run dev:web "color:#6a9955"># Web dev
bun run dev:landing "color:#6a9955"># Landing dev
bun run dev:server "color:#6a9955"># FastAPI backend on 17493
bun run build "color:#6a9955"># build server + Tauri app
README 推荐本地开发用:
class="language-bash">git clone https://github.com/jamiepine/voicebox.git
cd voicebox
just setup
just dev
适合谁用
Voicebox 很适合以下人群:
•想本地运行语音克隆和 TTS,不想把声音样本上传到云端的用户。
•需要多语言、多模型、多 profile 管理的内容创作者。
•想把 Agent 回复转成语音提醒或语音角色的开发者。
•做游戏、互动角色、播客、故事、叙事工具的人。
•有听写、转写、无障碍输入需求的用户。
•需要 REST / MCP 接口,把语音能力集成进自有系统的团队。
风险与边界
Voicebox 的能力很强,但也有几个边界需要注意。
第一,语音克隆天然涉及授权和滥用风险。即使项目本地优先,也不意味着可以克隆没有授权的声音。
第二,多模型本地推理对硬件要求不低。不同 TTS / STT / LLM 后端对显存、系统依赖、CUDA/ROCm/MLX 支持有不同要求。
第三,Linux 预构建包还没有,部署复杂度会比 macOS/Windows 更高。
第四,Agent voice output 很适合通知和交互,但也需要明确“什么时候可以说话”,避免后台应用突然出声带来干扰。
工程原则观察
•KISS:本地 REST API 和 MCP 工具都很直接,/generate、/speak、/transcribe、/profiles 容易集成。
•YAGNI:普通用户不必一开始使用全部 7 个 TTS 引擎,可以先从预设 voice 和一个稳定模型开始。
•SOLID:桌面壳、共享前端、后端服务、模型推理、MCP 接入分层明确。
•DRY:同一个本地 Qwen3 LLM 同时服务 personality rewrite 和 dictation refinement,减少重复模型缓存和 GPU 占用。
•潜在挑战:功能面非常宽,模型、平台、音频效果、MCP、全局输入都耦合在一个产品中。落地时要先验证核心链路,再逐步打开高级能力。
一句话总结
Voicebox 的价值不只是“本地 TTS”,而是把声音克隆、听写输入、语音生成、故事编辑和 Agent 发声合成了一个本地优先的 voice I/O studio。
如果未来每个 Agent 都需要一种声音,Voicebox 这类工具就是让 Agent 从文本界面走向真实语音交互的一块关键拼图。
声明:本文由山行整理自:Voicebox GitHub 仓库[2],如果对您有帮助,请帮忙点赞、关注、收藏,谢谢~
参考链接
[1] Voicebox: https://github.com/jamiepine/voicebox
[2] Voicebox GitHub 仓库: https://github.com/jamiepine/voicebox
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-29,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号