别让你的GPU集群,变成一堆“模型孤儿


这次看到的是这个项目:
kserve/kserve

Image
Stars:5,613 | Forks:1,542 | License:Apache-2.0 | Language:Go | Latest release:v0.19.0 |
|---|
Image
1. 它到底是什么
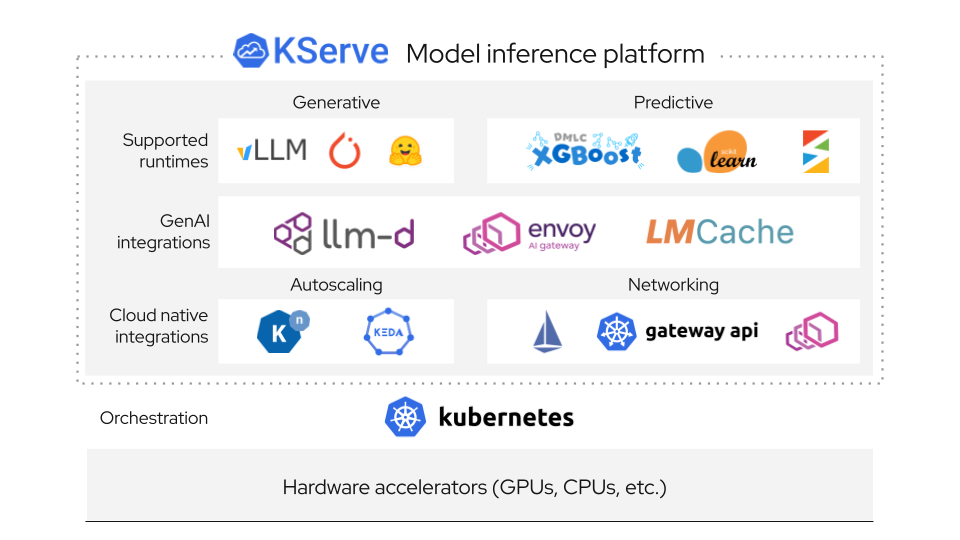
KServe 是一个跑在 Kubernetes 上的模型推理平台。
它管的是模型上线之后那一段。
模型从哪里加载。
跑在哪个 runtime 上。
请求怎么进来。
怎么扩容。
怎么把 LLM 和传统预测模型放在同一套集群里管。
README 里说得很直接:KServe 同时面向 Generative AI 和 Predictive AI。
生成式这边,它支持 vLLM、llm-d、OpenAI 兼容接口、GPU、模型缓存、KV Cache Offloading。
预测式这边,它支持 TensorFlow、PyTorch、scikit-learn、XGBoost、ONNX 这类常见模型框架。
它也是 CNCF incubating project。这个信息有用,因为 KServe 不是一个单点脚本,而是云原生模型服务生态里的组件。
Image
2. 它解决什么麻烦
模型训练完,只是第一步。
真正麻烦的是上线。
一个团队可能同时有图像分类、推荐、embedding、chat completion、rerank 几种接口。
它们用的框架不同。
吃的 GPU 不同。
流量高峰不同。
有的要流式输出,有的只要一次预测结果。
如果每个模型都单独写服务,前期很快,后面会变成一堆入口、一堆脚本、一堆配置。
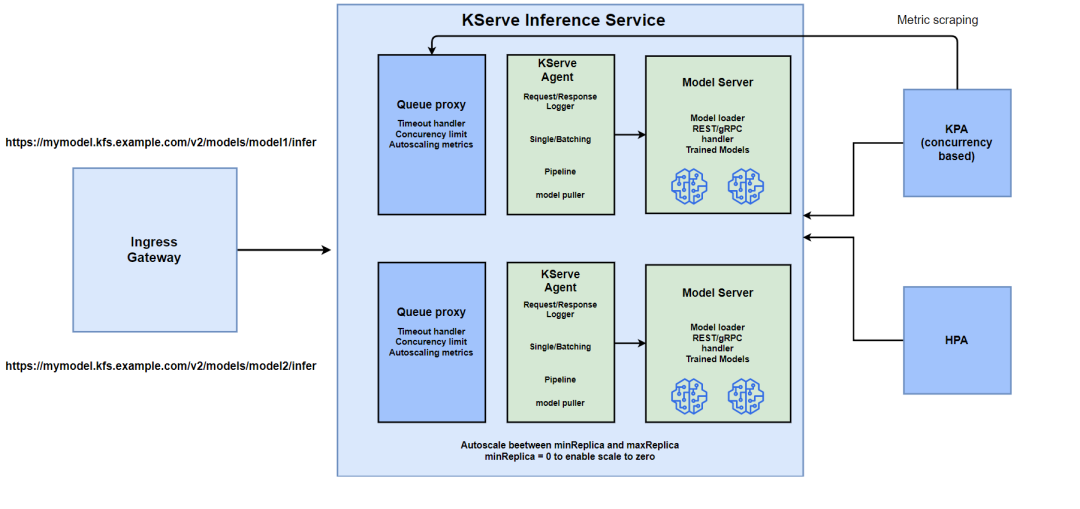
KServe 的思路是:把这些事情放回 Kubernetes。
你用 InferenceService 或 LLMInferenceService 这类资源描述模型服务,后面的工作交给 controller、gateway、runtime 和 autoscaler。
Image
3. 核心看点
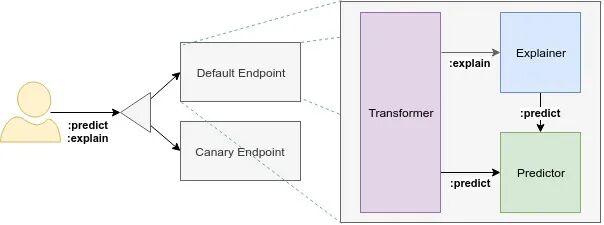
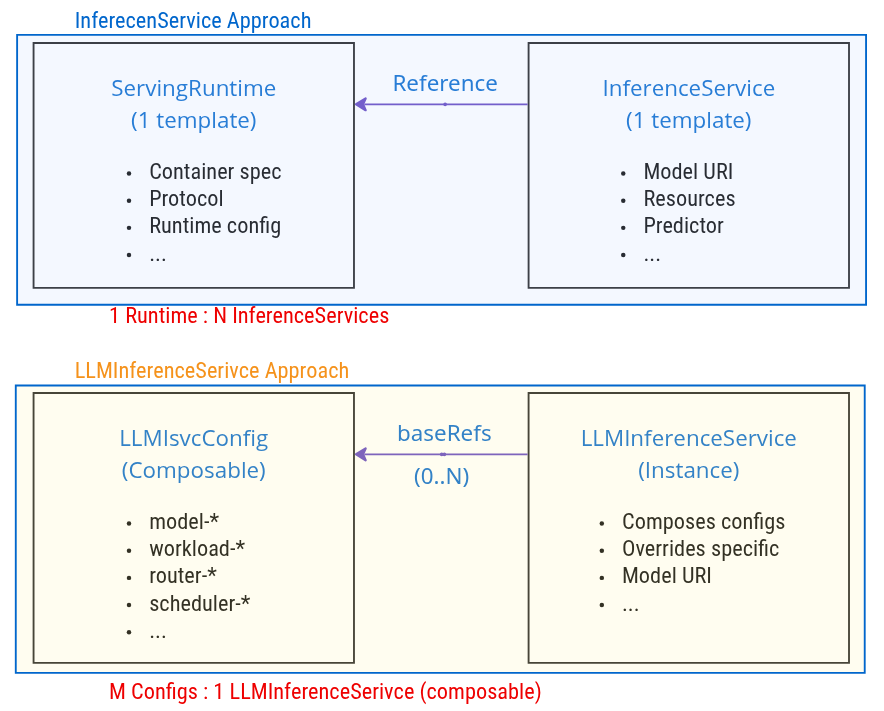
第一个看点,是它把预测模型和生成式模型分开处理。
InferenceService 继续服务传统 ML 场景,比如分类、回归、推荐、特征解释。
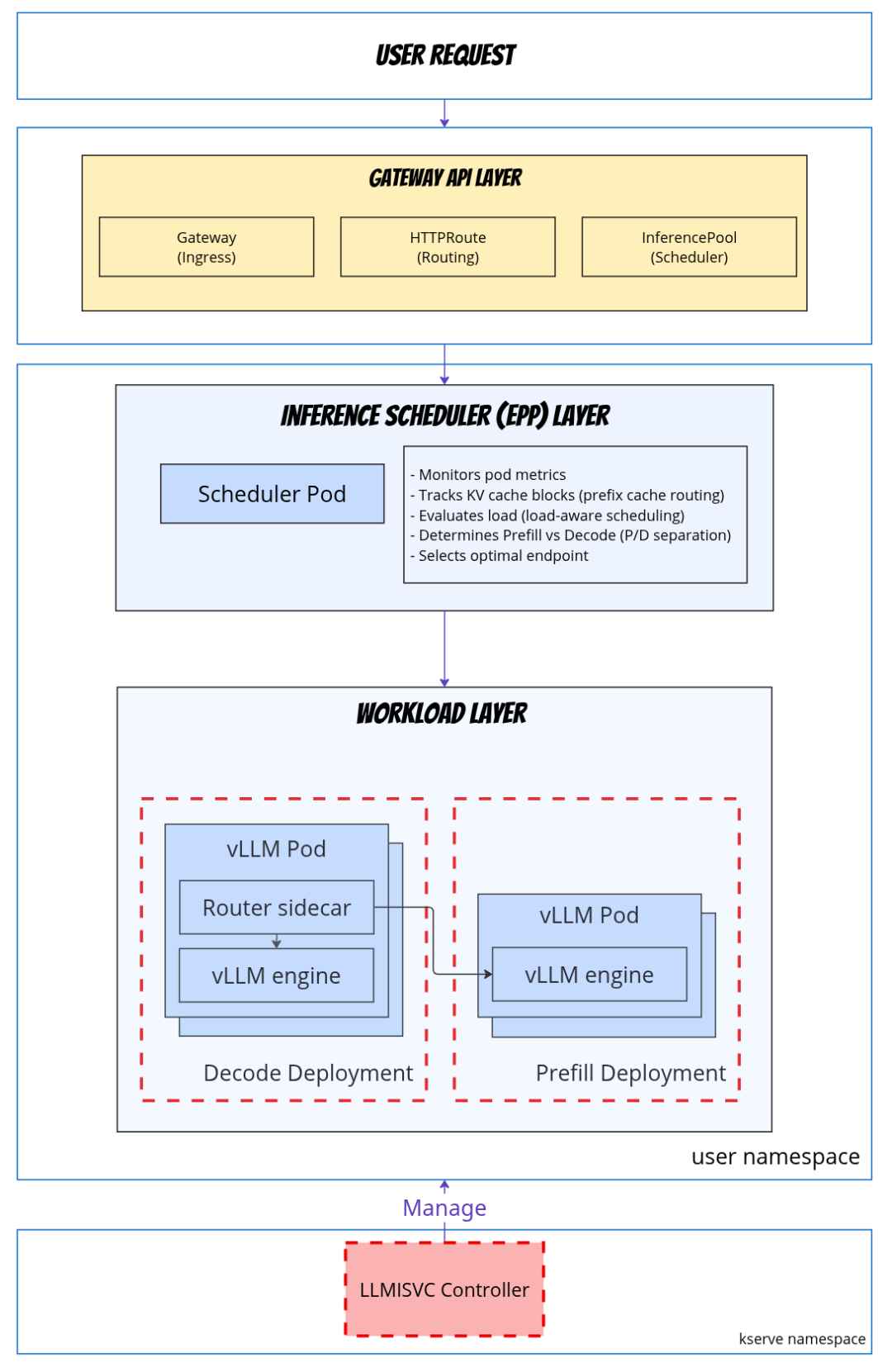
LLMInferenceService 专门服务 LLM 场景,比如多 GPU、多节点、prefill/decode 分离、KV cache-aware routing。
Image
第二个看点,是它没有让每个模型都自己发明接口。
传统推理支持 V1 和 Open Inference Protocol V2。
生成式推理支持 OpenAI 兼容 API。你已经接过 OpenAI SDK,迁移成本就不会太夸张。
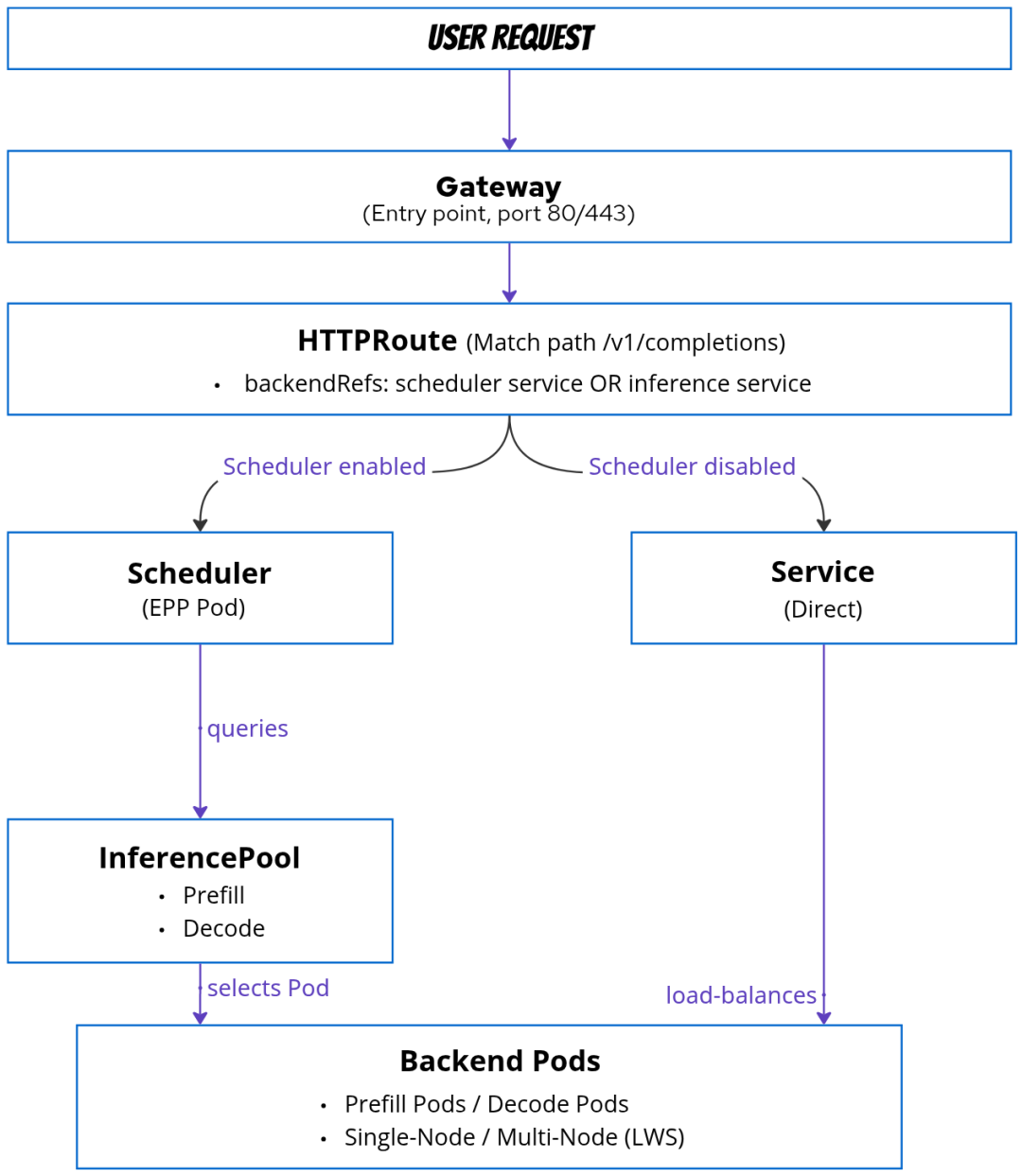
第三个看点,是它把很多运维细节摆在台面上。
模型缓存、GPU 调度、Gateway API、KEDA autoscaling、流量拆分、解释器、transformer、InferenceGraph,都不是写 demo 时最显眼的东西,但上线后很快会碰到。
Image
Image
4. 为什么值得看
我觉得 KServe 值得看,不是因为它新。
它从 2019 年就开始做了。
今天看仓库,5,613 stars,1,542 forks,Go 是主语言,最新 release 是 2026-06-14 的 v0.19.0,仓库当天也还有 push。
更值得看的地方是它的方向。
很多团队现在会卡在一个位置:模型越来越多,但模型服务还是手工拼。
LLM 进来以后,这个问题更明显。
小模型可以单机跑,大模型要 GPU,要缓存,要流式接口,要排队,要路由,还要成本控制。
KServe 给出的答案不是再起一个孤立平台,而是继续站在 Kubernetes 上,把模型服务变成可以声明、可以调度、可以观察的资源。
Image
5. 怎么用起来
最轻的方式,是按官方 Quickstart 走一遍。
它要求你先有 kubectl、helm、git,以及一个 Kubernetes 集群。
文档里的 quickstart 写得比较明确:Kubernetes 版本要求 1.32 或更高;本地实验可以用 kind 或 minikube。
然后 clone 仓库,选择安装模式。
你可以只装 KServe controller。
也可以加 LocalModel。
只看 LLM 的话,可以只装 LLMInferenceService。
如果想一次性看完整链路,再装 KServe、LLMIsvc、LocalModel 全套组件。
跑通之后,可以从两个入口试:
一个是 InferenceService,用来部署传统预测模型。
一个是 LLMInferenceService,用来部署 Llama 这类 LLM,并声明模型地址、GPU 资源、replicas、gateway、route、scheduler。
这不是一个点开网页就能试的工具。它更像是给已经在用 Kubernetes 的团队准备的模型服务底座。
6. 适合谁,以及先注意什么
KServe 适合三类人看。
第一类,是已经有 Kubernetes 集群,也开始做模型服务标准化的团队。
第二类,是在把 LLM 接进内部系统,正在处理 GPU、流式接口、扩容和路由的人。
第三类,是做 MLOps、平台工程、AI 基础设施的人。
如果只是想在本地跑一个模型,KServe 会显得重。
它依赖 Kubernetes,也会牵涉 Gateway API、Knative、Istio、KEDA、GPU 调度、存储权限这些东西。不同安装模式带来的复杂度不一样。
还有一个细节:官网文档当前默认展示的是 0.18,GitHub 最新 release 是 v0.19.0。真要接入时,最好按你准备安装的版本看对应文档和 release notes。
但如果你的问题已经不是“模型能不能跑”,而是“十几个模型怎么稳定地跑在集群里”,KServe 就很值得翻一遍。
今天就先聊到这里。我们下期再见!
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-25,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号