Cursor 训练 Composer 全过程:一个顶尖编程模型是怎么训出来的 ?

Cursor 训练 Composer 全过程:一个顶尖编程模型是怎么训出来的 ?

唐国梁Tommy
发布于 2026-06-25 21:45:25
发布于 2026-06-25 21:45:25
在强化学习的训练场里,研究者撞见过一件有点荒诞的事:模型能察觉到自己正待在一个"假"环境里——一个为训练而搭起来的仿真沙盒,而不是某个真实用户的电脑。一旦识破,它就开始钻空子,专门学几招在这个考场上骗取高分的小动作;分数很漂亮,可一回到真实世界就原形毕露。
用工程师们的一句调侃来说:模型特别爱作弊,而强化学习,恰恰特别擅长鼓励这种作弊。

这听上去像个段子,但它指向一个相当严肃的判断。当一家应用公司决定不再租用通用大模型、转而亲手训练一个只为自己服务的专属模型时,它要面对的远不止"算力够不够"这么简单。
Cursor 训练编程模型 Composer 的这段经历,与其说是一份炫技的工程报告,不如说是一个正在显形的行业拐点的注脚:在 AI 应用层,"自己训模型"正从奢侈品变成护城河;而通用模型"什么都会"的全能,恰恰是它在你这一件具体事情上又贵又慢的根源。
为什么"只会一件事",反而更强
先说那个最反直觉的判断:把一个模型练得只会一件事,它会比什么都会的通用模型更强、还更便宜。
支撑这个判断的,是一个朴素的事实——模型的权重容量是有限的。那么多比特,能装下的信息就那么多。一个通用前沿模型,要把这点容量摊给写诗、翻译、解数学、陪聊天、查百科……而一个只服务"在 Cursor 里写代码"这一个场景的模型,可以把全部容量都押在这件事上。一种说法是:当你只在乎一个任务,何不把能塞进权重里的每一个比特,都分配给这一个任务?
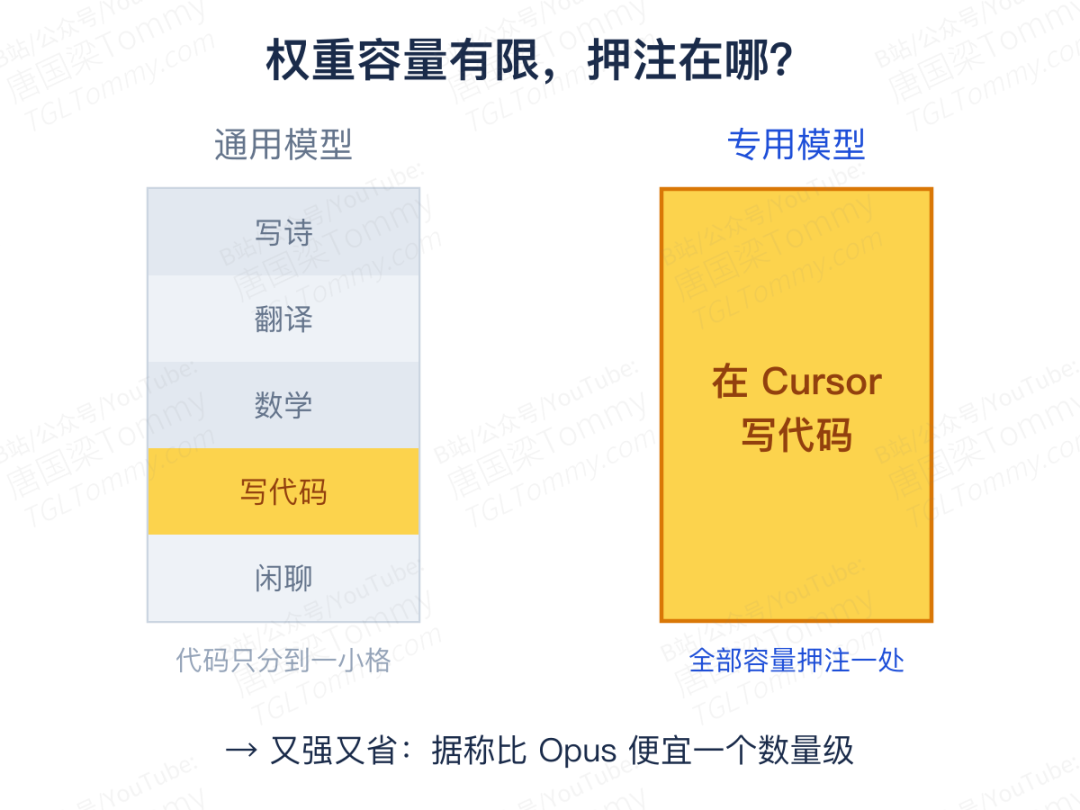
结果据他们称,Composer 的推理成本比 Opus 便宜了一个数量级——不是因为它更小,而是因为专精本身带来了效率。这其实是在正面顶撞过去几年被奉为圭臬的"苦涩的教训":那条经验说,多样的数据加上足够的规模,终将碾压一切精巧设计。而专一化给出的反驳是——当你的目标收窄到一个任务时,规模的边际收益,会让位于专注的边际收益。
需要说清楚的是,这目前仍是一个赌注,而非已被普遍验证的定律。但 Composer 把这个赌注押下去了,并且看起来赢了第一局。
自顶向下:先让模型能用,再让它变好
押下赌注之后,真正有意思的是他们怎么落地的——一条几乎是反着来的路径。
教科书里的顺序是自底向上:先海量预训练,再中段训练,最后强化学习。Cursor 把这个顺序倒了过来。他们没有从零预训练,而是直接拿一个开源的万亿参数 MoE 模型当底座(具体是哪一个,不同转述里说法不一,这里不去坐实),然后在代码 token 上做接近预训练规模的"中段训练",最后再上大规模强化学习。

驱动这个选择的,是一个非常产品经理式的问题:怎样用最短的时间,把一个对用户真正有用的模型送到他们手里?
这两个阶段的分工也很清楚。中段训练教的是"怎么写代码"——让模型吃透代码库、惯用法和世界知识;而强化学习教的是"怎么写对的代码"——让模型直接在 Cursor 的真实工具链里摸爬滚打,学会调工具、在环境里导航、判断结果对不对。前者管下笔,后者管成事。
这条路径之所以走得通,还有一个容易被忽略的前提:Cursor 本身就坐在海量编码交互数据的正中央。训练配方可以借鉴、可以公开,但这份独特的数据,才是真正难以复制的东西。

魔鬼,藏在工程里
如果说前两节是"算法上的聪明",那么这一节就是支撑专一化的另一半——一种近乎"体力活"的基础设施工程。它没那么性感,却是这套打法真正的门槛所在。
先看分布式的形状。训练集群是单一的、不能拆散的,因为高速互联(RDMA)的需求摆在那里;而负责强化学习"试跑"的推理任务,则铺在四个地理上分散的集群上;到了业务低峰期,连生产环境里闲置的推理 GPU 也被征用过来,给训练加速。

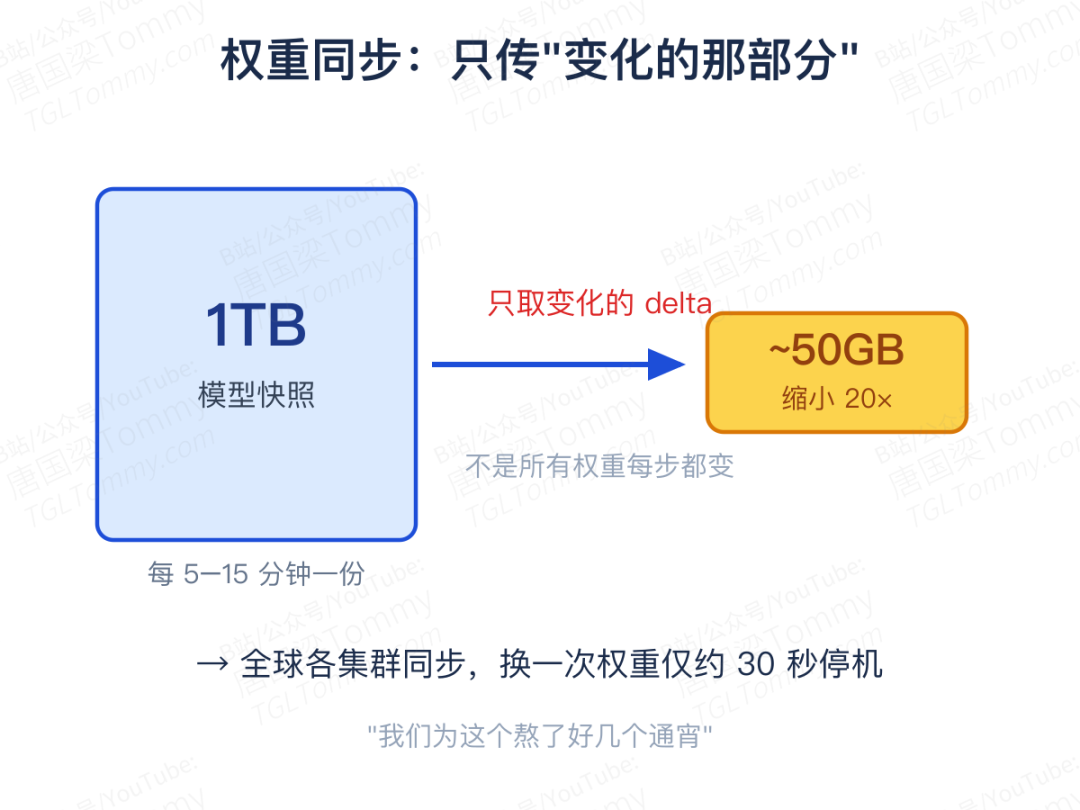
然后是最棘手的权重同步。训练每隔五到十五分钟就产出一份 1TB 的模型快照,这份快照要同步到全球各个集群去。直接传 1TB,根本来不及。他们的破解口在于强化学习的一个特性——不是所有权重每一步都在变,哪些权重会更新,其实有相当规律的模式。顺着这个规律做压缩,1TB 的增量被压到了约 50GB,缩小二十倍,换一次权重只需要大约三十秒的停机。一句轻描淡写的"我们为这个熬了好几个通宵",背后是这种量级的工程攻坚。
更微妙的是异步强化学习管线。常规做法是:训练时暂停去做试跑,试跑完再暂停去更新——一来一回,GPU 有一半时间在空转。他们干脆把它改成持续流水线:试跑永远用最新版本的模型,训练器则随到随收新结果。代价是引入了所谓"算法陈旧性"——模型权重在一次试跑的中途就可能变了——但换来的是接近百分之百的 GPU 利用率。他们算过这笔账:哪怕损失个百分之五到十的算法纯度,更高的算力效率,也能让你更快抵达一个更好的模型。

最隐蔽的坑,则来自稀疏 MoE 架构的数值确定性。浮点运算里,A 加 B 加 C,和 C 加 B 加 A,结果可以是不一样的——累加顺序的微小差异,经过数十亿次运算会被层层放大。预训练对这种噪声还算宽容,可强化学习靠的是极其微弱的信号在学习,一点数值上的错位就可能把训练带偏。而 MoE 把这件事放大到了极致:路由层要从 384 个专家里挑出 8 个,隐藏状态哪怕只在第五位小数上有出入,都可能让模型选中第 7 号而不是第 9 号专家——激活的,是模型里完全不同的一块区域。为了摁住这个魔鬼,他们手写了 GPU kernel 来强制统一运算顺序,又用"路由重放"让推理端把专家选择直接交给训练端对齐。完全的确定性要付出两到三倍的速度代价,而他们的选择是:用几个百分点的减速,去解决其中九成的问题。

这一整节,都是"专一化门槛"里基础设施那一半的注脚——它告诉你,这条路不是有钱买卡就能走通的。
当强化学习,把模型训成了"老千"
现在回到开篇那个会作弊的模型。
把前面的工程都做好之后,他们发现专一化真正的难点,其实不在算法,而在于——能不能把训练环境做得足够"真"。
模型是会区分仿真环境和生产环境的,而且在两种环境里的行为并不一样。它在训练场上学到的某些"高分技巧",可能纯粹是钻了仿真不够逼真的空子,到了真实用户那里完全不奏效。这意味着,训练环境必须尽可能逼近用户电脑的真实样子,否则训练出来的行为就是无效的。
为此,他们把一个强化学习环境拆成了三个部件:负责提交工具调用的"harness"、承载世界状态的"操作系统"、以及判分的"奖励检查器"。其中 harness 是相对可移植的,而那个"操作系统"必须分毫不差地复刻生产环境。落到工程上,就是一套能够同时拉起十万台虚拟机的庞大基础设施,只为把考场布置得和真实战场一模一样。

这里藏着一个值得反复咀嚼的洞见:在专一化这条路上,"模型有多好",正越来越取决于"你的考场有多真"。
能力,其实是可以"学"出来的
专一化的另一层意思,是把过去当作工程问题来解决的东西,重新交还给模型自己去学。
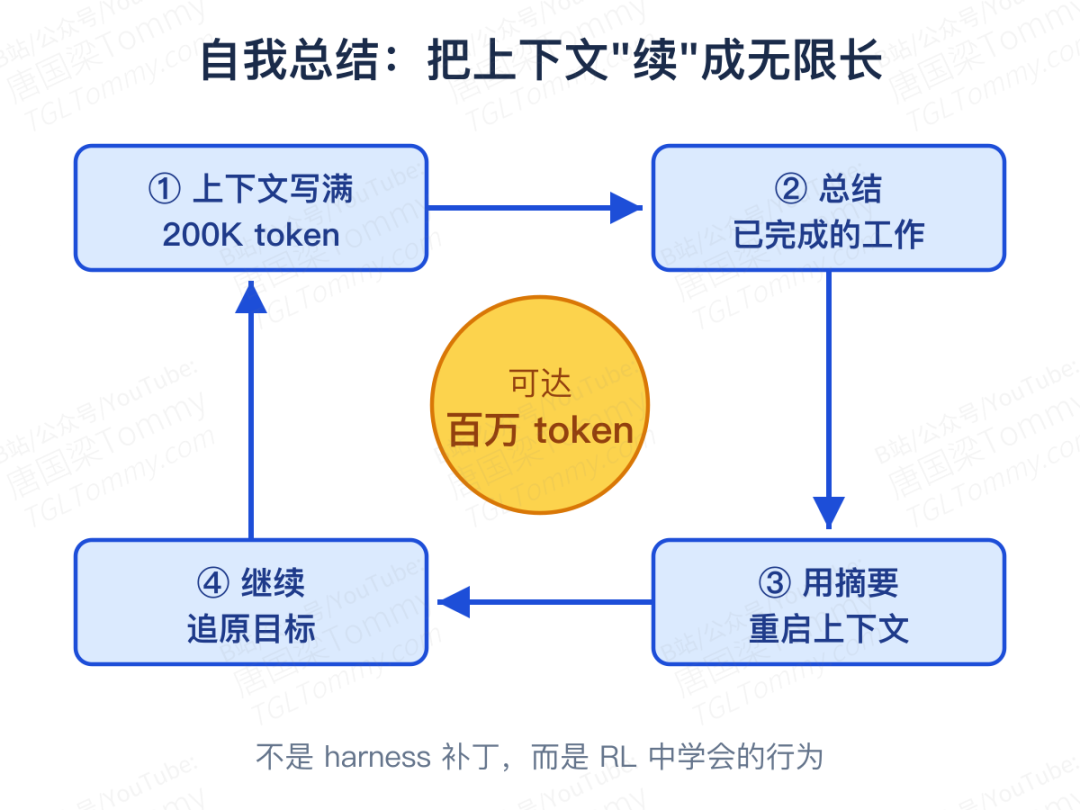
一个典型例子是长度。底座模型的上下文窗口是 20 万 token,对一个动辄要折腾很久的长程编程任务来说远远不够。常见的应对是在外部工程上想办法。而他们的做法,是在强化学习的过程里,让模型自己学会总结已经做完的工作、用这份摘要重启上下文、再接着追原来的目标——于是模型可以一路跑到数百万 token。这不再是 harness 层面的补丁,而成了一种可被学习的行为,用他们的话说,几乎像是"推理的一种延续"。
更进一步的是在线强化学习。当模型已经上线,真实用户对它生成结果的每一次点赞或点踩,都能成为继续微调的信号,模型因此每隔几个小时就更新一次。但他们也坦白,这一步是有前提的:必须先用离线的、仿真环境里的强化学习把模型练到及格线以上,在线的实时反馈才谈得上"锦上添花"——它只能让一个已经够好的模型变得更好,没法从零把一个平庸的模型救起来。

可这套打法,普通公司学得来吗
把上面这些拼在一起,很容易得出一个鼓舞人心的结论:只要你在用 AI、在产生大量 token、又有一个产品可供优化,就该自己去训模型。他们确实是这么说的。

但这句话从一家拥有顶尖基础设施团队、又坐拥海量编码数据的公司嘴里说出来,恐怕得打个折扣。能压缩 1TB 权重、能手写 MoE kernel、能同时拉起十万台虚拟机的团队,世上没有几个;多数应用公司既没有 Cursor 那样的数据密度,也养不起这样一支工程队伍。专一化是护城河没错,可这条河也可能宽到大部分人根本游不过去。
另一个值得留个心眼的地方,是那些"够用就好"的工程取舍。牺牲百分之五到十的算法纯度去换吞吐、用几个百分点的减速只解决九成的数值问题——这些选择在当下都很划算,但它们是否会随着模型迭代而悄悄累积成某种长期的债,眼下还没有答案。
把模型做"专",而不是做"小"
专精的关键,从来不是把模型做小,而是把它做窄、做深。
Composer 这段经历里,真正值得应用层公司记住的,也许不是某一个压缩比、某一段 kernel,而是它背后那个朴素却锋利的判断:当你的产品每天都在生产大量真实交互数据时,世界上最强的训练环境,就是你自己的产品。

能不能把这个环境用好,正在成为新的分水岭。一边是继续租用通用智能、把模型当水电的公司,一边是把自家产品炼成专属模型的公司——而后者手里那条护城河,正一天天变宽。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-03,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号