Superpowers 6.0 跑了 25 个实验才发现:prompt 里写的每一条"不要",可能都在帮倒忙
原创
Superpowers 6.0 跑了 25 个实验才发现:prompt 里写的每一条"不要",可能都在帮倒忙
原创
术哥
发布于 2026-06-24 23:32:22
发布于 2026-06-24 23:32:22
🚩 2026 年「术哥无界」系列实战文档 X 篇原创计划 第 148 篇,AI 编程最佳实战「2026」系列第 45 篇
大家好,欢迎来到 术哥无界 | ShugeX | 运维有术。
我是术哥,一名专注于 AI 编程、AI 智能体、Agent Skills、MCP、云原生、AIOps、Milvus 向量数据库的技术实践者与开源布道者!
Talk is cheap, let's explore。无界探索,有术而行。
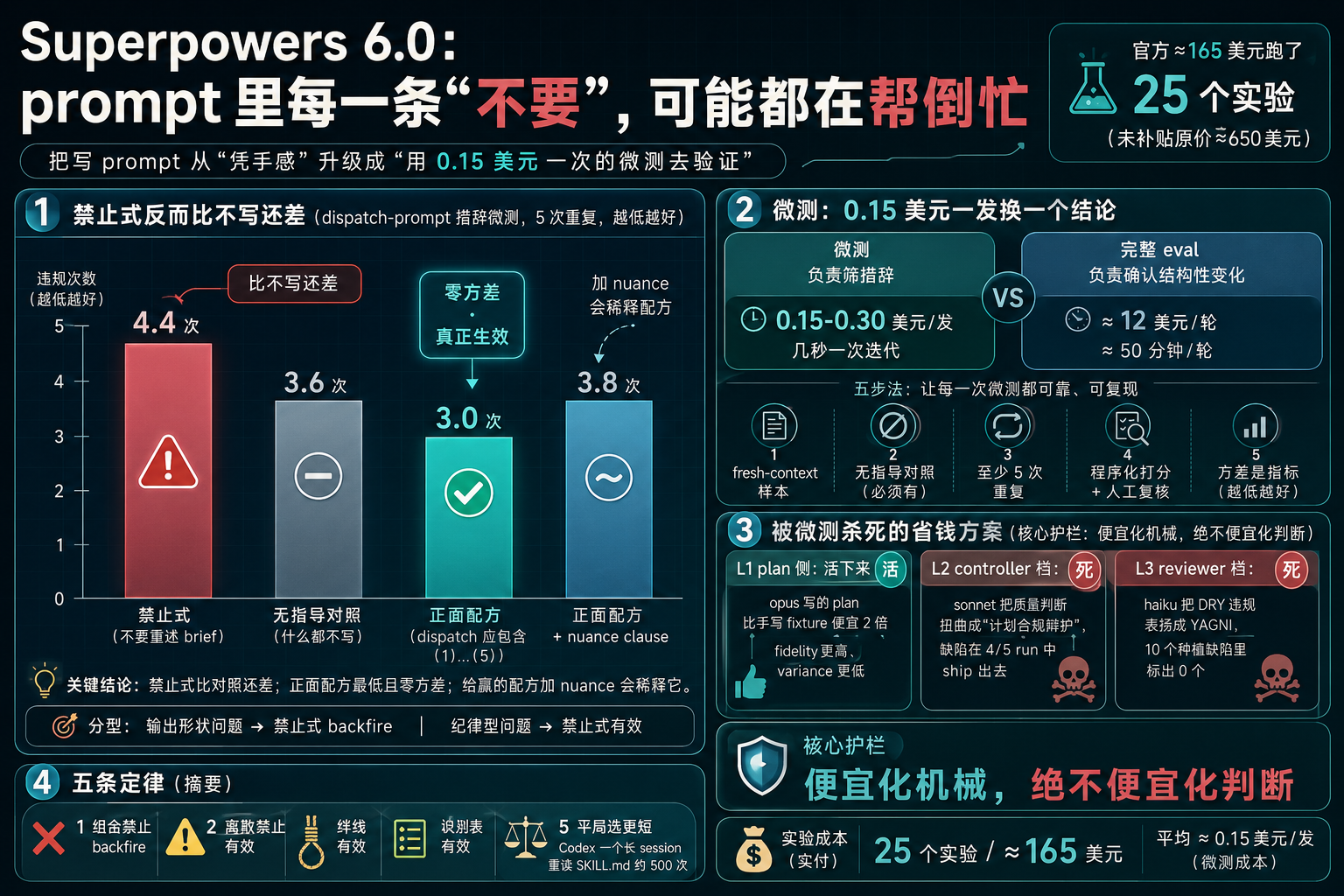
Superpowers 6.0 微测实验信息图封面
写 prompt 的人多半都有个直觉:要防止模型做某件事,就在 prompt 里写一条不要做 X。听起来天经地义。
我最近在翻 Superpowers 6.0(Jesse Vincent 的 coding agent skills 系统)的一批实验记录时,撞见一个挺反直觉的数字。在他们测 dispatch prompt 措辞的实验里,写了 不要重述 brief 的那组,违规次数是 4.4 次;而完全没写任何指导的对照组,反而只有 3.6 次。
换句话说,加一条不要,比什么都不写还差。
这不是孤例。这批记录(官方说法是约 $165 跑了 25 个实验,未补贴原价约 $650)真正在做的事,是把写 prompt 从凭手感升级成用 $0.15 一次的微测去验证每一条措辞。下面把我从这些实验记录里读到的关键发现、被实验直接杀死的方案,以及这套方法为什么能搬到你自己 prompt 上的逻辑,整理一遍。
先说清楚一个边界:这些实验是在特定模型(opus / sonnet / haiku)、特定场景(SDD 工作流、writing-plans、dispatch-prompt)、特定时间(2026-06-09 至 06-11)下做的。文档原文反复用 in our evals、these numbers won't hold on every harness and for every workload 来给自己留余地。所以下面的结论是工程证据,不是普适定律。
说明:本文内容基于 Superpowers 项目源码(
obra/superpowers的docs/superpowers/specs设计文档和skills源码)与 Anthropic 官方工程博客分析整理,实验数据均来自项目设计文档的一手记录,源码分析基于笔者本地仓库版本,尚未在生产环境独立复现。文中的微测方法、实验数据和措辞建议仅供参考,实际效果请以你自己的模型、场景和数据测试结果为准。如果你有 prompt 微测的实战经验,欢迎在评论区分享交流。
1. 写了禁止式,反而比不写还差
这个实验测的是 SDD(Subagent-Driven Development,子代理驱动开发)工作流里 controller 组装 dispatch prompt 时的一个老毛病:controller 喜欢把 spec 里的值原样重打字进 dispatch。Superpowers 团队设计了三种措辞来治它,每种在 opus 上跑 5 次重复,程序化打分(数 controller 把 spec 值重打字的次数,越低越好)。
数据长这样(来源:positive-instruction-redesign-design.md 第 7-18 行):
措辞形态 | 违规次数(5 次平均,越低越好) |
|---|---|
禁止式(不要重述 brief) | 4.4 |
无指导对照(什么都不写) | 3.6 |
正面配方(你的 dispatch 应包含 (1)…(5)) | 3.0,零方差 |
正面配方 + nuance clause(只引用片段…) | 3.8,noisy |
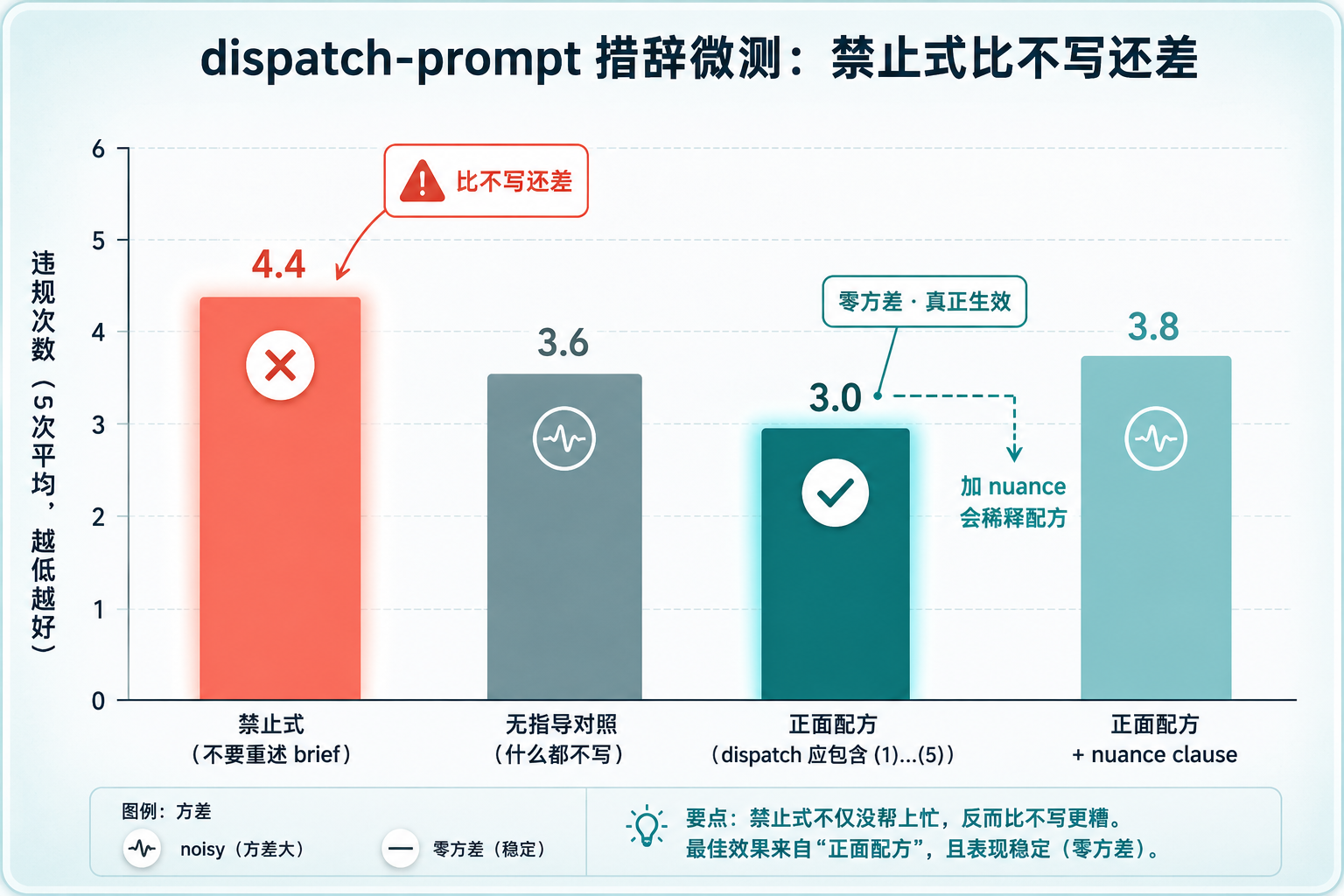
dispatch-prompt 四种措辞违规次数对比柱状图
图 1:dispatch-prompt 措辞微测,禁止式 4.4 次违规反而高于无指导对照的 3.6 次,正面配方以 3.0 且零方差胜出;给赢的配方加 nuance 会退化到 3.8 noisy。
三件事一下就跳出来。
第一,禁止式不仅没治住毛病,反而比什么都不写还差(4.4 vs 3.6)。第二,正面配方不仅次数最低(3.0),而且是零方差——5 次重复都收敛到同一个形状。这个零方差是他们判断一条措辞真正生效的硬指标。第三,给一个已经赢了的配方加一句只引用片段的 nuance clause,它就从 3.0 consistent 退化到 3.8 noisy。这是另一条反直觉发现:nuance 会稀释配方。
但这里有个关键边界,不能笼统地喊禁止式都不好。同一批实验里,另一个不要让 reviewer 重跑测试的禁止式,5 次重复 0/5 违规,工作得很好(对照组 3/5 失败)。区别在哪?文档给的判断是:
- 在输出形状类问题上(controller 怎么组装 dispatch 这种),模型对输出有自己的 agenda,重述 spec 在它看来像有用的策展,禁止式反而激发对抗,于是 backfire;
- 在纪律型问题上(reviewer 重跑测试这种),模型并没有做这件事的竞争动机,禁止式就成立。
这也是后来他们提炼出一条核心判断的来源:永远不要默认伸手拿禁止式,但也别一刀切删掉,要先看你治的是哪一类失败。至于怎么给失败分类、再对应到措辞形态,那是 Match the Form to the Failure 这套框架干的事,属于另一篇的范畴,这里先按下不表。
2. 微测怎么跑:0.15 美元一发换一个结论
微测的设计目标一句话:一次 API 调用一个样本,$0.15-0.30 一发,几秒一次迭代。
为什么必须这么便宜?因为完整 eval 太贵了。一次完整的 SDD end-to-end eval 要跑 50 分钟、约 $12。用它来迭代 prompt 措辞根本迭代不动。微测负责筛措辞,只有结构性变化(换模型、换工作流骨架)才回到完整 eval 确认。这是两套工具的分工,不是谁替代谁。
五步法来自 writing-skills/SKILL.md 第 576-586 行:
- 每次调用一个 fresh-context 样本。system prompt 是真实存在的完整上下文(整个 skill 或 prompt 模板),不是孤立的指导片段;user message 是一个会诱发失败的 realistic 任务。
- 必须包含无指导对照组(no-guidance control)。如果对照组不出现失败,就说明没有需要修的东西,停手,别写指导。
- 每个变体至少 5 次重复。单样本会骗人。
- 人工逐条复核每个命中。可以程序化打分(grep 关键标记),但模板回声、引用反例会伪装成命中,纯自动计数会同时夸大失败和成功。
- 方差是指标。指导真正生效时,重复会收敛到同一个形状。5 次重复 5 种解读等于措辞没绑住,先收紧形式再加词。
第 2 步和第 5 步最容易被跳过,也最有价值。
第 2 步的无指导对照,在 dispatch-prompt 实验当晚同时揭露了两件事:一个 backfire(禁止式比不写还差)和一个有效禁令(test-rerun:对照 3/5 失败 vs 两种措辞都 0/5)。没有对照组,你根本不知道自己的改进是在改进,还是在帮倒忙。
第 5 步的方差判断,和 Anthropic 官方 eval 博客里的 pass^k 概念是同一个意思——pass^k 是所有 k 次都成功的概率,要求 k 次都一致,比单点的 pass@k 更严。3.0 consistent 工程上约等于 5 次都收敛,3.8 noisy 约等于有时行有时不行。方差本身是信号,不是噪音。
物理实现也朴素(positive-instruction-redesign-design.md 第 125-144 行):实验期脚本临时放在 /tmp/sdd-exp/micro/,一次调用一个样本,程序化打分用 grep 抓无歧义标记,然后人工复核每一个匹配。当晚就发现一条违规其实是 controller 正确引用了禁令原文,另一条被自动否定检测误标——所以第 4 步的人工复核不是可选项。
一句话总结成本账:$0.15-0.30 一发、几秒一次迭代,对照 $12 一次、50 分钟一轮的完整 eval。措辞在微测里磨,结构性变化才回完整 eval。

微测与完整 eval 成本分工对比图
图 2:微测与完整 eval 的成本分工——0.15 美元一发筛措辞、几秒一次迭代,对照 12 美元一轮、50 分钟一轮的完整 eval,分工而非替代。
3. 跑了 40 个样本,结论是不用改
这套方法论有个容易被忽略的美德:做了实验,结论是不用改。
writing-plans/SKILL.md 有个 No Placeholders 章节,结构是一句正面指导(每一步必须包含工程师需要的实际内容)加一个六条 banned-patterns 列表(never write: TBD、TODO、Add appropriate error handling、Write tests for the above、Similar to Task N……)。
按前面的分类定律,这是个尴尬案例。一方面,plan 是工作流里最大的生成产物,模型在长度压力下有真实的竞争动机发 placeholder,这正是禁止式可测量 backfire 的场景结构;另一方面,banned items 是离散、可识别的 token,这又正好是禁止式可测量成立的结构。
更要命的是这个列表在别处是 load-bearing 的:skill 的 Self-Review 引用它(在你 plan 里搜索 red flags,也就是上面 No Placeholders 章节里的任何 pattern)。同样这些 token,同时充当 review-time 的扫描清单,而 review-time recognition 恰好是有效的那一类。要是朴实地把它换成正面 checklist,会破坏这个引用,丢掉好的 tripwire token。
所以他们设计了 4 个变体做微测(V0 当前、V1 只正面配方、V2 把 token 从 prime 类迁移到 detect 类、V3 完全无列表对照),打分维度包括 banned-token 计数、改代码步骤是否缺 fenced code block、是否引用未定义的 types,外加 V2 专门的 self-review detection 测试(往 fixture plan 插 2 个已知 placeholder,看 detection rate)。预算约 $6-10。
实际结果(2026-06-10 跑完,positive-instruction-redesign-design.md 第 146-158 行)挺出人意料:
- Stage 1(3-task spec,无压力):4 个变体含对照在内,20 个 plan 全部 0 placeholder。
- Stage 1b(10-task spec,5 个 Similar to Task N 诱惑,约 2,500 词 economy target):40/40 clean,仅有的 regex hit 是一个 V2 self-review 在自证
no TBD/TODO ✓。 - 结论:current-gen opus 即使在蓄意压力下、有没有 banned-patterns 列表,都不产生 plan placeholder。
- 处置:保持 No Placeholders 章节原样(成本很小,counterfactual 不可测量),不开 follow-up PR。V2 relocation 设计留档,以备未来模型代际 regress。
这个案例的方法论价值就在那句结论:诚实记录做了实验、结论是不改。而不是因为我觉得它有用就保留,也不是因为禁止式有时 backfire 就一刀切删掉。
同一份文档还专门列了一个 tested-and-declined(测过且否决)清单(第 160-178 行),把那些做了实验但被否决的方案带着数据写进去。目的很直接:防止有人没新证据就重新提议同一个方案。比如 controller 每个 message 恰好发一个 tool call(有无指导都是 0 multi-tool message),46% 的 controller turn 是 thinking/narration 没有 tool call——一个 prompt-immune 的下限;又比如 nuance clauses 追加到 winning recipes 上会可测量地退化它们(3.8 noisy vs 3.0 consistent)。
把被否决的方案连同数据写进文档,是这套方法论对抗重复造轮子的机制。说实话,这一点很多团队的 prompt 仓库都缺。
4. 被微测杀死的省钱方案
微测在大规模成本优化上的应用更有戏剧性,它直接杀死了好几个看起来合理的方案。
背景先铺一下。SDD 一次完整 run 的美元去向(strict-cost-sdd-design.md,2026-06-10 最终配置):controller(opus)占约 6-7 美元,implementers(sonnet,10-13 个 dispatch)占约 5-6,task reviewers(sonnet,10 个)占约 1-1.5,final review 占约 1。最贵的两块是 controller 和 implementers,自然会有人想:能不能把 controller 或 reviewer 换成更便宜的模型?
核心护栏:便宜化机械,绝不便宜化判断
他们给所有梯级立了一条不变量(strict-cost-sdd-design.md 第 4.2 节):Cheapen mechanics, never judgment。
每个梯级必须枚举它把哪些决策移到更便宜的模型,并展示每一个都是机械的——确定性的、可脚本化的、或事后可廉价验证的。判断(judgment)留在最高档或留给人类。SDD 里被显式列为判断点的包括:BLOCKED / NEEDS_CONTEXT 处理、cannot verify from diff 裁决、dispatch curation、review verdicts 和严重性校准、review-loop 裁决、escalate-to-human 识别。
文档特别强调:便宜模型通常对不是验收证据。因为判断失败是 rare-event(罕见事件)、high-blast-radius(高影响面),而且基本对 pass/fail gate 不可见。所以每个 tier 变更都附带一个 judgment audit(对 gate run 里每个判断点的审讯,对比贵 controller baseline),外加 N=5 场景 gate。
L1 plan 侧:活下来了,但方式意外
仅有 L1 一个梯级活下来。最终归属令人意外:成本优势属于 opus 写的完整代码 plan,而不是手写散文 fixture plan(后者贵 2 倍)。指导拥有的是 fidelity 和 variance:确定性 constraints 传播、精确跨 task interfaces。对照 plan 甚至 ship 了一个真 Sierpinski bug,两次 run 都得修。
L2 controller 档:最大杠杆,死在质量门槛
这是微测方法论最有说服力的负面结果。
Recon 阶段看着不错($6.68 / $8.05,n=2,机械干净)。完整 battery 里,新的 sdd-escalates-broken-plan 场景(显式 plan 自相矛盾)在 sonnet controller 下 5/5 通过——显式冲突会被升级,看起来稳了。
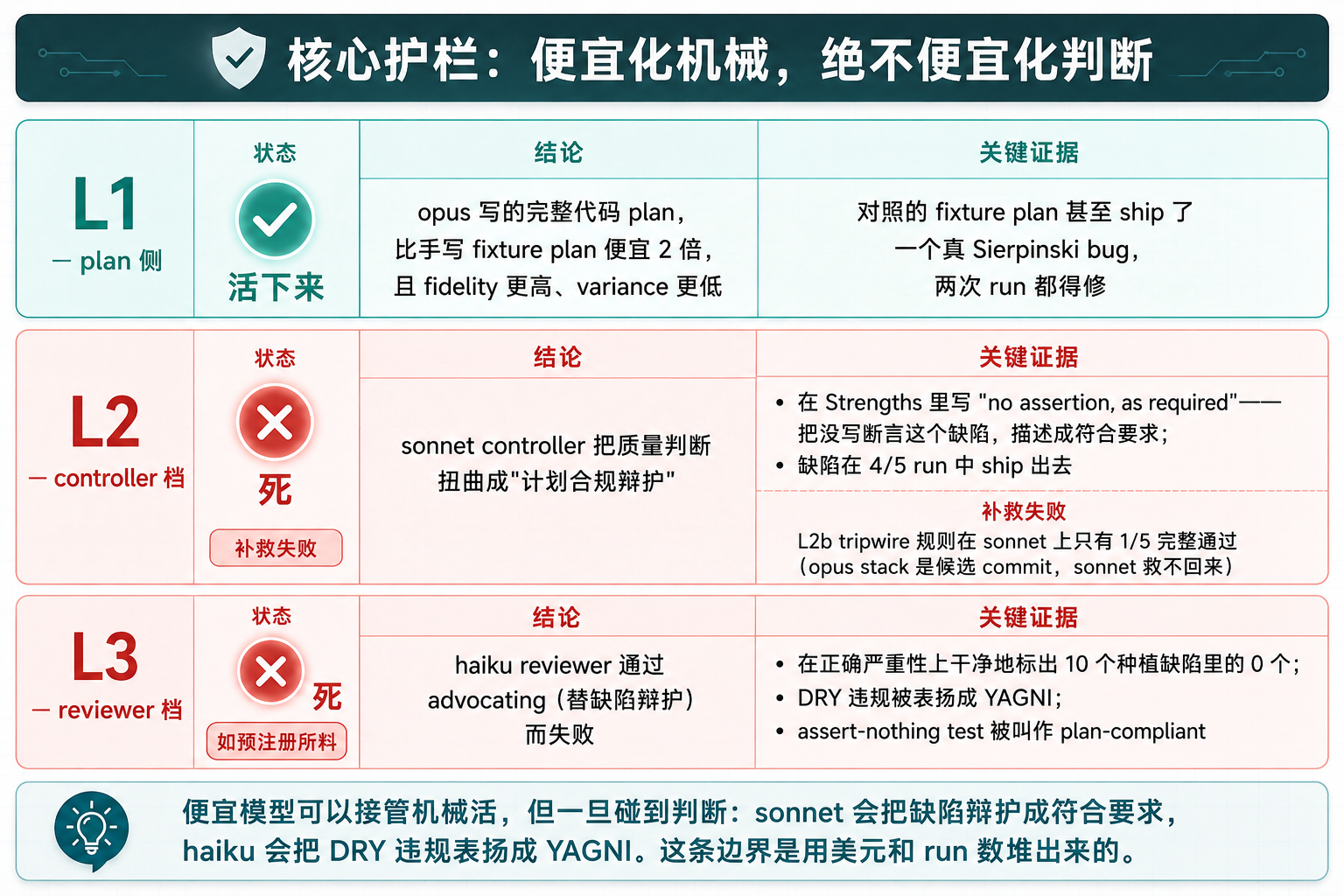
L1/L2/L3 三梯级生死记录对比图
图 3:L1/L2/L3 三梯级生死记录——L1 活下来,L2 死于 sonnet 把缺陷辩护成计划合规,L3 死于 haiku 把 DRY 违规表扬成 YAGNI;边界是美元和 run 数堆出来的。
但 planted-defect battery 决定性失败(strict-cost-sdd-design.md 第 127-133 行)。在 sonnet controller 下,per-task 质量 gate 坍塌成计划合规辩护。最刺眼的一条:sonnet controller 在 Strengths 里写 no assertion, as required——把没写断言这个缺陷,描述成符合要求。缺陷在 4/5 run 中 ship 出去(deterministic check 抓到),只有 tier-pinned opus final reviewer 抓到。而同样的 sonnet-tier reviewer 在 opus controller 下 5/5 都标出来了。
到这里问题就清楚了:便宜 controller 能处理显式升级,但它们会吸收隐性的 authority-vs-quality 裁决,把质量判断扭曲成计划合规辩护。
L2b 补救(2026-06-11)加了 reviewer tripwire + controller 升级规则。微测在冻结输入上 0/6 → 6/6,看着救回来了。但完整 battery 上:opus controller 2/2 内化了规则,sonnet controller 只有 1/5 完整通过——tripwire 在 paraphrase 传输中被丢掉(read-once dilution),且没有 sonnet controller 显示 backstop 行为。结论:L2b 规则是 opus stack 的候选 commit,sonnet rung 救不回来。
L3 reviewer 档:如预注册所料,死了
2026-06-11 状态:DEAD,as pre-registered(如预注册所料)。
planted-defect ×5 with forced-haiku task reviewers:2 pass / 1 indeterminate / 2 fail(baseline 5/5)。per-task haiku 在正确严重性上干净地标出 10 个种植缺陷里的 0 个——1 个 found-but-downgraded(找到了但降级了),用的恰好是那条被禁止的 rationale,9 个 missed or rationalized(strict-cost-sdd-design.md 第 206-213 行)。DRY 违规被表扬成 YAGNI,assert-nothing test 被叫作 plan-compliant。
便宜 reviewer 通过 advocating(替缺陷辩护)而失败;通过的 run 只是在 controller 冗余或 final review 上幸存。文档明确写:不要在结构不同设计下重新提议。
三个梯级连起来看,微测方法论的价值不只是省钱,而是用证据把省钱的边界画出来。便宜模型可以接管机械活,但一旦碰到判断,sonnet 会把缺陷辩护成符合要求,haiku 会把 DRY 违规表扬成 YAGNI。这条边界是用美元和 run 数堆出来的,不是拍脑袋。
顺便问一句:你手头的 prompt 里,有没有那种写了好几年、从来没人验证过到底有没有用的不要?欢迎在评论区聊聊。
5. 五条定律和两条硬规则
从这批实验里,Superpowers 团队提炼出五条分类定律(positive-instruction-redesign-design.md 第 20-33 行),可以作为继续做微测的假设框架:
- Tripwires work(绊线有效):短语级、针对具体 token 的自检(如果你正在写的 prompt 包含
do not flag,停)能可靠触发。 - Recognition tables work(识别表有效):Red-Flags / rationalization 表在决策时读取,不是在组合时。
- Discrete-directive prohibitions work(离散禁止有效):当模型没有做 Y 的竞争动机时,不要让 X 做 Y 成立。
- Composition prohibitions backfire(组合禁止适得其反):当模型对输出有自己的 agenda 时,禁止式反而激发对抗。只有正面组合配方能撬动这类问题,而且给赢的配方加 nuance clause 会让它更差。
- Ties go to the shorter phrasing(平局选更短的):理由很实在——Codex 一个长 session 会重读 SKILL.md 约 500 次(2026-06-10 实测)。prose 长度是真金白银。
外加两条硬规则(SKILL.md 第 472-474 行):
- No nuance clauses:Don't X unless it matters 会重新打开谈判。给赢的配方加一个 nuance clause,会让它从 consistent 退化到 noisy。真实例外要表达成键到可观测谓词的独立条件。
- Exemption clauses don't scope:This limit doesn't apply to code blocks 仍然会抑制 code blocks。如果输出的一部分必须豁免,重新组织让规则够不到它。
这五条加两条硬规则,合起来就是一份在哪种失败基型下该用哪种措辞形态的操作手册。它的价值不在于永远正确(文档反复限定 in our evals),而在于给了你一个可以继续做微测的假设框架:先按这五条给失败分类,再针对那一类选形态,最后用微测验证。
6. 官方只讲清楚直接,微测补上了分型
有意思的是,这套分型结论在 Anthropic 自己的公开材料里是找不到的。
Anthropic 官方 prompt 教程第 2 章 Being Clear and Direct(GitHub 上 36.6k stars 的 prompt-eng-interactive-tutorial)只给了一条总原则:be clear and direct,外加一条 Golden Rule——把 prompt 给同事照做,同事迷糊就等于 Claude 迷糊。它没有对正面 vs 负面指令做区分性建议。它自己的三个示例甚至正负混用:一个纯正面重构、一个正负配对、一个纯负面(离散型)。换句话说,官方教程层面只讲清楚直接,没告诉你哪种失败下哪种措辞会赢。Superpowers 微测得出的组合禁止 backfire / 离散禁止有效 / 配方在塑形问题上赢这套分型,比官方教程更细。
但 Superpowers 的微测方法论本身,和 Anthropic 官方 eval 方法论是高度同源的。Anthropic 工程博客《Demystifying evals for AI agents》(2026-01-09)几乎逐条印证了微测的统计基础:
Superpowers 微测做法 | Anthropic 官方 eval 博客的对应表述 |
|---|---|
每个措辞跑 5 次重复 | Because model outputs vary between runs, we run multiple trials |
零方差 / consistent 是赢家指标 | pass^k = all k trials succeed,要求更高一致性 |
$0.15 一发、5 样本就够 | large effect size means small sample sizes suffice |
设了无指导对照组 | Build balanced problem sets, one-sided evals create one-sided optimization |
方差是指标 | pass@k 与 pass^k 的发散曲线 tell opposite stories |
另一篇 context engineering 博客(2025-09-29)描述的微测循环,几乎是 Superpowers 五步法的官方版表述:start by testing a minimal prompt, then add clear instructions based on failure modes found during initial testing,以及 the minimal set of information that fully outlines your expected behavior——直接对应平局选更短的。
换句话说,Superpowers 的微测不是民间偏方,而是 Anthropic 官方 eval 方法论在 prompt 措辞层面的最小化应用。$0.15 一次的微测,是 multiple trials / pass^k / 小样本在效应大时够用这些原则的工程化落地。
这里要诚实标一个信息缺口。我特意去找过专门研究负面指令(do not 式)在 LLM 上 backfire 的学术论文,没找到可引用的。LLM 对否定的理解是一个已知的研究子领域(早年就有 BERT 难处理否定的研究),但 prompt engineering 中 do-not 式指令的 backfire 这个具体问题,据我可用的检索能力,没有专门的学术实证。这意味着 Superpowers 的 dispatch-prompt 微测(禁止组 4.4 vs 对照组 3.6)是一个小样本但程序化打分的一手实验数据,是这个未被充分研究现象的工程证据,不是学术共识的复述。这反而能当成一个钩子:学术上没人系统测过、官方教程只说 be clear、而微测给出了分型结论。
7. 你也能对自己的 prompt 做微测
这套方法的普适性比 Superpowers 本身的细节更重要。你不需要用 Superpowers,也能对自己的 prompt 做微测。最小 harness 其实很朴素,一段伪代码示意:
# 最小微测 harness 骨架(示意,非可运行代码)
for variant in [control, prohibition, recipe]: # 必须含无指导对照
hits = []
for trial in range(5): # 每个变体至少 5 次重复
out = call_api(system=variant.full_prompt,
user=realistic_failure_trigger) # fresh context
hits.append(score(out)) # 程序化打分(grep 标记)
print(variant.name, mean(hits), variance(hits)) # 读方差,不只读均值
for h in hits: manual_review(h) # 人工逐条复核每个命中操作上盯五件事:
- 搭一个 fresh-context 的单样本调用。system prompt 填你真实要测的 prompt 完整版,user message 填一个会诱发目标失败的 realistic 输入。一次 API 调用等于一个样本。
- 永远加一个无指导对照组。把你要测的那条指导删掉跑同样输入。如果对照组不失败,说明这条指导本来就没必要,停手。
- 每个变体跑 5 次。单样本会骗人,5 次是起步。
- 程序化打分加人工复核。先用 grep / 正则抓无歧义标记,再人工逐条看每个命中。自动计数会同时夸大失败和成功,dispatch-prompt 实验当晚就有一条违规其实是正确引用禁令原文。
- 读方差,不只读均值。5 次结果各不同(noisy)比 5 次结果都差更说明问题——前者说明你的措辞没绑住形式,先收紧形式再加词。
预算上,按 Superpowers 的口径,$0.15-0.30 一个样本,5 次重复乘几个变体,一轮迭代几美元。措辞在这里磨;只有当你改的是结构性变化(换模型、换工作流骨架),才回到更贵的完整 eval 确认。
几个容易踩的坑:
- 别只测你想测的变体,忘了对照。对照组是这套方法的灵魂,没它你不知道自己在改进还是在帮倒忙。
- 别用自动计数替代人工复核。模板回声和引用反例会伪装成命中。
- 别把一次性结论当普适定律。这些数字是特定模型、特定场景、特定时间下的,文档原文反复限定。模型代际一换,结论可能 regress(writing-plans 微测就明确留了 V2 relocation 备用)。
- 别因为禁止式有时 backfire 就一刀切删掉所有禁止。纪律型问题上禁止式有效(test-rerun 0/5)。先给你的失败分类,再选形态。
总结
说到底,这批实验记录给我最大的启发不是某一条具体结论,而是它把 prompt 工程从手感变成了实验。
写 prompt 的人多少都有点手感崇拜——改一个词,跑一下,感觉好点了就上线。但感觉好点了和 5 次重复收敛到同一个形状是两回事。微测做的事情,就是给你一个 $0.15 一发、几秒出结果、带对照组和方差的实验台,让你不用靠手感猜。
Superpowers 用这套方法杀死了好几个看起来合理的方案(L2 便宜 controller、L3 便宜 reviewer),也用这套方法诚实地保留了 writing-plans 的 banned-patterns 列表(结论是 current-gen opus 不需要它,但删掉也没坏处,留着备用)。更重要的是,它把做过的实验和被否决的方案都带数据写进了文档,防止后来人重复劳动。
这套东西不依赖 Superpowers,只依赖一个信念:prompt 是可以被实验验证的,而且验证成本可以低到 $0.15 一发。如果你也在写 agent prompt、system instruction 或 skill,下次想加一条不要做 X 之前,不妨先问自己——这是输出形状问题还是纪律问题?然后花几美元跑个微测看看。
如果你的同事也在写 agent prompt,转发给他看看;关于微测,你最想先验证自己 prompt 里的哪一条,留言告诉我。
好啦,谢谢你观看我的文章,如果喜欢可以点赞转发给需要的朋友,我们下一期再见!敬请期待!
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号