Nat. Rev. Bioeng. | 机器学习驱动的多目标抗体设计与智能优化

Nat. Rev. Bioeng. | 机器学习驱动的多目标抗体设计与智能优化

DrugAI
发布于 2026-06-24 13:18:24
发布于 2026-06-24 13:18:24
抗体药物已成为现代生物医药领域最成功的治疗平台之一,从传统单克隆抗体到纳米抗体、双特异性抗体和多特异性抗体,其应用范围覆盖肿瘤、免疫疾病、感染性疾病以及诊断领域。然而,一个能够高效结合靶标的抗体并不一定能够成为成功药物。除了亲和力之外,抗体还必须同时满足特异性、稳定性、可溶性、低聚集倾向、低免疫原性、低多反应性以及良好的生产表达等多项成药性要求。现实中,这些性质之间往往存在复杂的权衡关系,导致抗体优化成为药物开发中最耗时、最昂贵的环节之一。
研究人员指出,传统抗体工程通常依赖大规模实验筛选和多轮定向进化,但随着人工智能和机器学习的发展,研究人员开始利用计算模型在更大的序列空间中预测和优化抗体性质,实现多个目标参数的协同优化。本文系统综述了近年来机器学习驱动的多目标抗体设计策略,包括现有抗体的协同优化、直接预测最优抗体变体,以及面向未来的从头设计(de novo design)框架。研究人员认为,AI与机器学习有望突破传统抗体工程的瓶颈,加速下一代高性能治疗性抗体的开发。

治疗性抗体已经成为全球最重要的生物药类别之一。曲妥珠单抗、阿达木单抗、帕博利珠单抗和纳武利尤单抗等重磅药物极大改变了癌症、自身免疫疾病和感染性疾病的治疗模式。传统抗体发现主要依赖杂交瘤技术、单B细胞筛选以及噬菌体展示、酵母展示等体外筛选平台。通过这些方法获得候选抗体后,还需要进一步优化其亲和力、人源化程度、稳定性和成药性。
近年来,除了传统IgG抗体之外,纳米抗体和双特异性抗体也迅速发展。纳米抗体来源于骆驼科动物重链抗体可变区,具有体积小、组织穿透能力强以及能够识别隐藏表位等优势。双特异性抗体则能够同时识别两个不同靶点,在肿瘤免疫治疗和跨组织递送等领域展现出巨大潜力。
然而,无论是哪种抗体形式,都面临同样的问题:提高一种性质往往会牺牲另一种性质。例如,提高亲和力可能增加非特异性结合和自聚集风险;聚集倾向增强又可能增加免疫原性。因此,抗体优化本质上是一个多目标优化问题,而不是单一指标优化问题。
研究人员认为,多目标优化是当前抗体工程最关键、同时也是最具挑战性的任务,而AI和机器学习则为解决这一问题提供了新的技术路径。
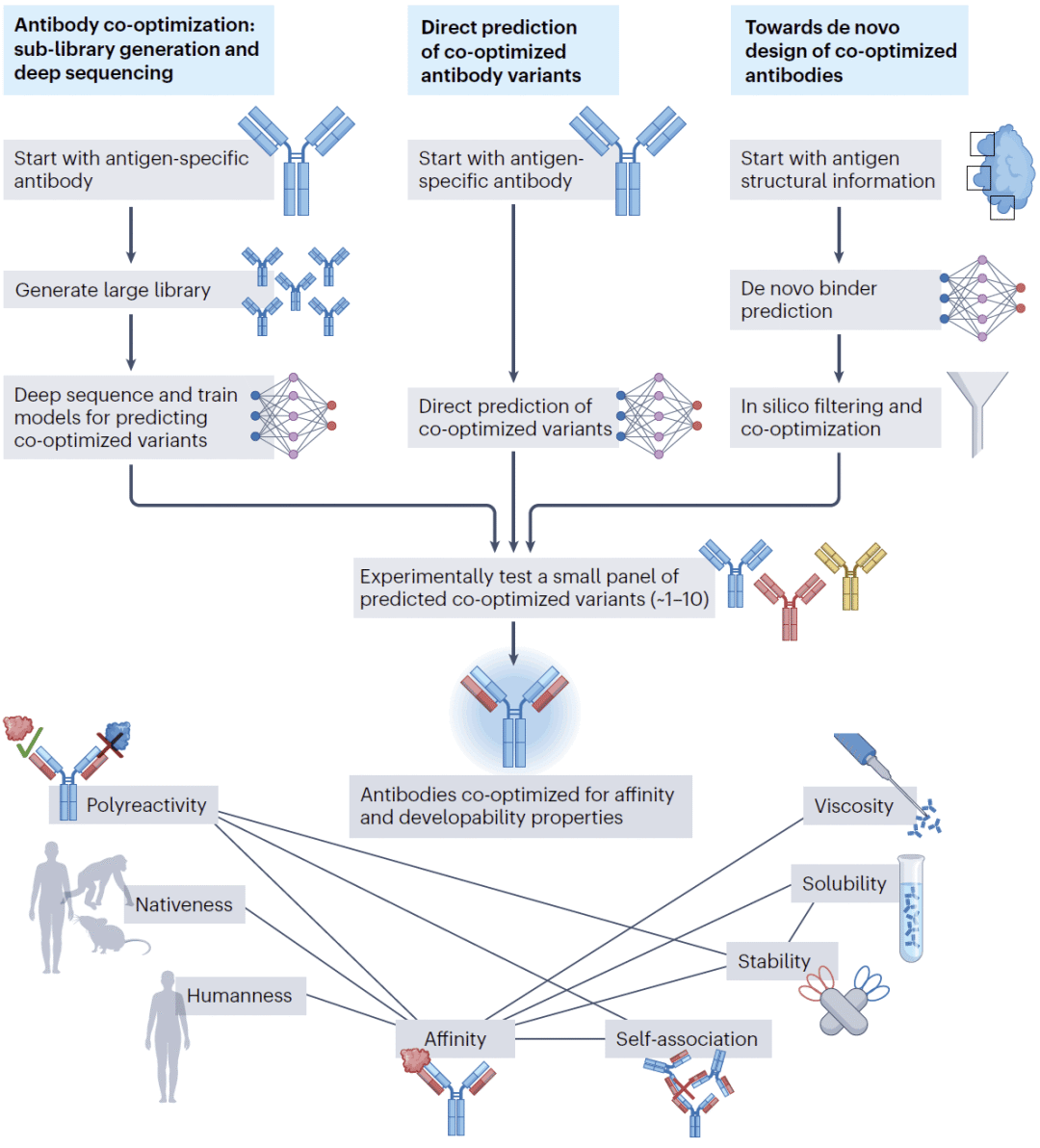
图1:AI驱动的多目标抗体优化总体框架。
现有抗体的多目标优化
基于子文库构建与深度测序的协同优化
最早的机器学习抗体优化策略仍然依赖实验筛选。研究人员首先针对现有抗体构建局部突变文库,然后利用高通量筛选和深度测序获得大量序列—功能数据,最后训练机器学习模型预测新的优良变体。
以曲妥珠单抗为例,研究人员对HCDR3区域进行随机突变,并利用流式细胞分选筛选结合与非结合克隆。随后通过深度测序获取大量训练数据,再利用卷积神经网络预测具有高亲和力且成药性更优的新变体。预测结果经过进一步过滤后,最终获得兼具高结合能力、良好可溶性和较低免疫原性的候选抗体。
另一项研究针对Emibetuzumab开展优化。研究人员同时测量抗原结合能力和多反应性,并利用线性判别分析模型构建亲和力与多反应性的联合预测空间。在这一框架下,不仅能够找到当前数据中的最佳平衡点,还能够预测原始实验空间之外的潜在优良变体,从而实现真正意义上的多目标协同优化。
随着抗体语言模型的发展,研究人员开始利用海量天然抗体数据库训练深度学习模型。例如利用OAS数据库训练RoBERTa架构模型,对数万种曲妥珠单抗突变体进行预测。模型不仅能够预测结合亲和力,还能够评估抗体“天然性(nativeness)”。结果显示,在巨大的突变空间中,同时提升亲和力和天然性的变体极为罕见,而遗传算法能够显著提高搜索效率,帮助发现这些稀有的最优解。
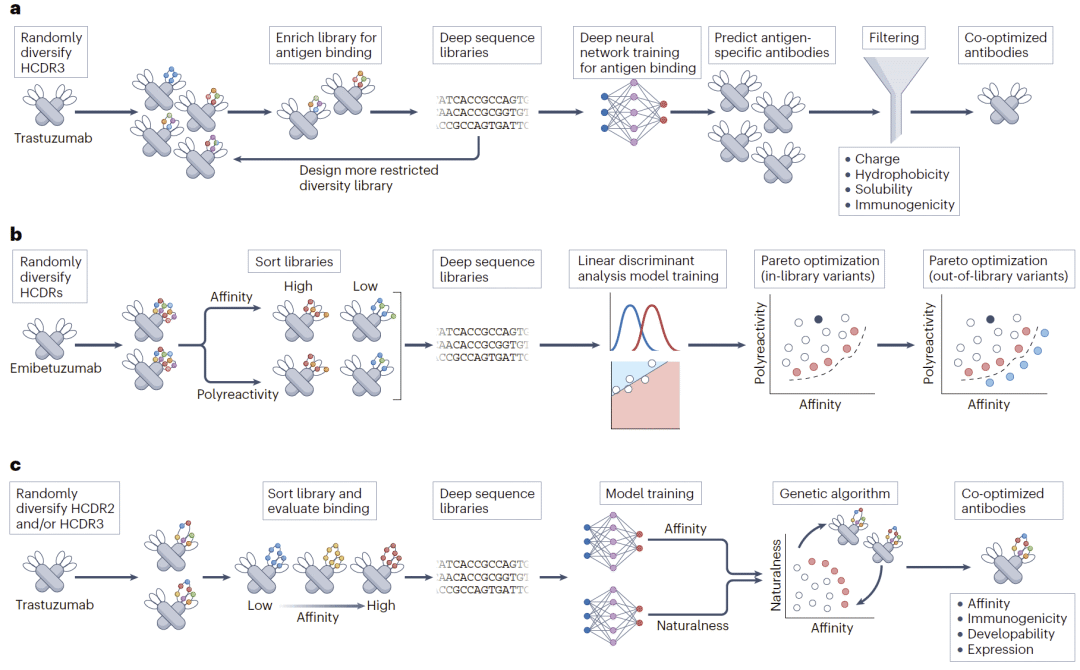
图2:深度测序结合机器学习的抗体协同优化流程。
直接预测协同优化抗体变体
相比依赖大规模实验文库的方法,另一类策略试图直接通过计算模型预测最优抗体序列,从而减少实验负担。
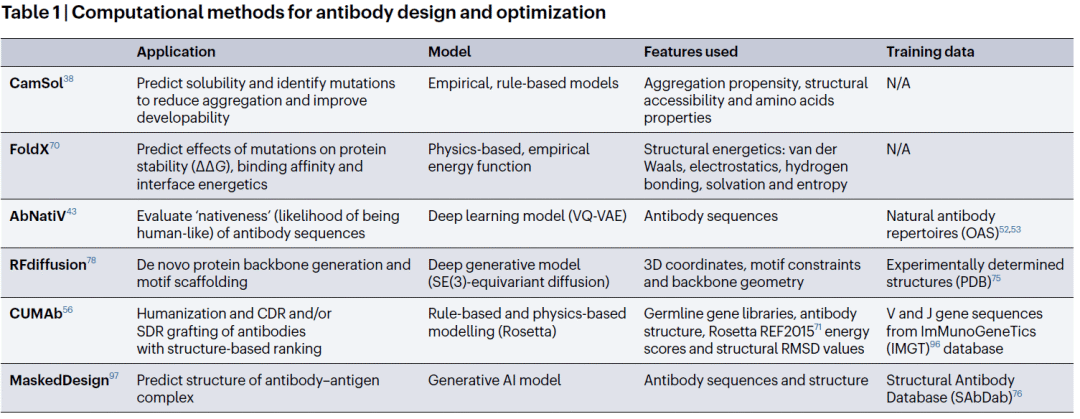
在人源化方面,研究人员开发了CUMAb框架。该方法不再简单寻找最相似的人源框架,而是系统组合大量人类V基因和J基因形成候选框架,再利用Rosetta能量函数评估结构稳定性。研究结果表明,该方法能够获得兼具高人源化程度和高稳定性的抗体,并且保持与原始抗体相近的结合能力。
在降低非特异性结合方面,研究人员建立了基于80个临床阶段抗体的数据集,分别测量抗体自聚集倾向和多反应性。利用结构特征训练出的可解释机器学习模型发现,静电性质主要决定自聚集,而疏水和离子斑块分布则主导多反应性。基于这些规律设计的突变体中,大多数成功降低了不良生物物理性质,同时维持甚至提高了结合亲和力。
另一项工作则聚焦于稳定性和可溶性的联合优化。研究人员将CamSol可溶性预测工具与FoldX稳定性分析结合,通过系统扫描潜在突变位点,筛选同时提升可溶性和稳定性的候选突变。最终得到的抗体变体在保持结合能力的同时,表现出更高稳定性和更好的制剂开发潜力。
迈向从头设计的协同优化抗体
虽然现有抗体优化已取得显著进展,但研究人员认为最终目标仍然是从抗原信息直接设计全新的抗体,即真正意义上的从头设计。
一种代表性策略结合逆折叠模型、蛋白语言模型以及结构过滤方法。研究人员以SARS-CoV-2抗体为案例,利用蛋白语言模型生成CDR突变,再通过Rosetta评估结构合理性,并结合多种成药性过滤规则筛除不良变体。最终获得兼具广谱结合能力、较低聚集倾向以及较高热稳定性的抗体。
另一类方法采用片段组装思想。研究人员从蛋白质结构数据库中提取大量类似CDR的结合片段,然后根据目标表位结构自动匹配和组合这些片段,并通过侧链优化增强结合界面作用。最终生成的新抗体不仅能够识别目标表位,还能够同时满足结合能力与可溶性要求。
近年来扩散模型的发展进一步推动了这一方向。RFdiffusion等生成模型能够根据目标抗原结构直接生成新的抗体骨架,再利用ProteinMPNN设计CDR序列。研究人员认为,这种结构生成与序列设计协同工作的框架代表了未来抗体从头设计的重要方向。
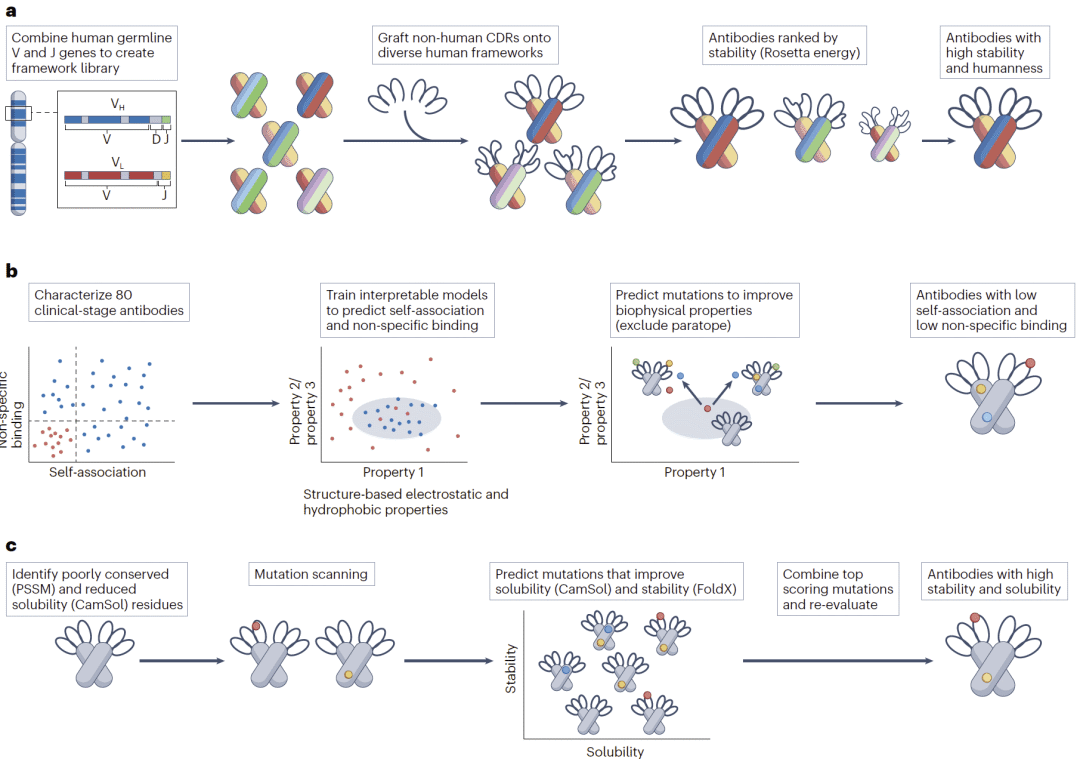
图3:从头抗体设计与生成式AI框架。
蛋白语言模型与逆折叠模型推动抗体工程
文章特别强调了基础模型在抗体工程中的重要作用。随着OAS、UniRef等大规模数据库的发展,蛋白语言模型已经能够学习天然抗体序列中的深层规律。
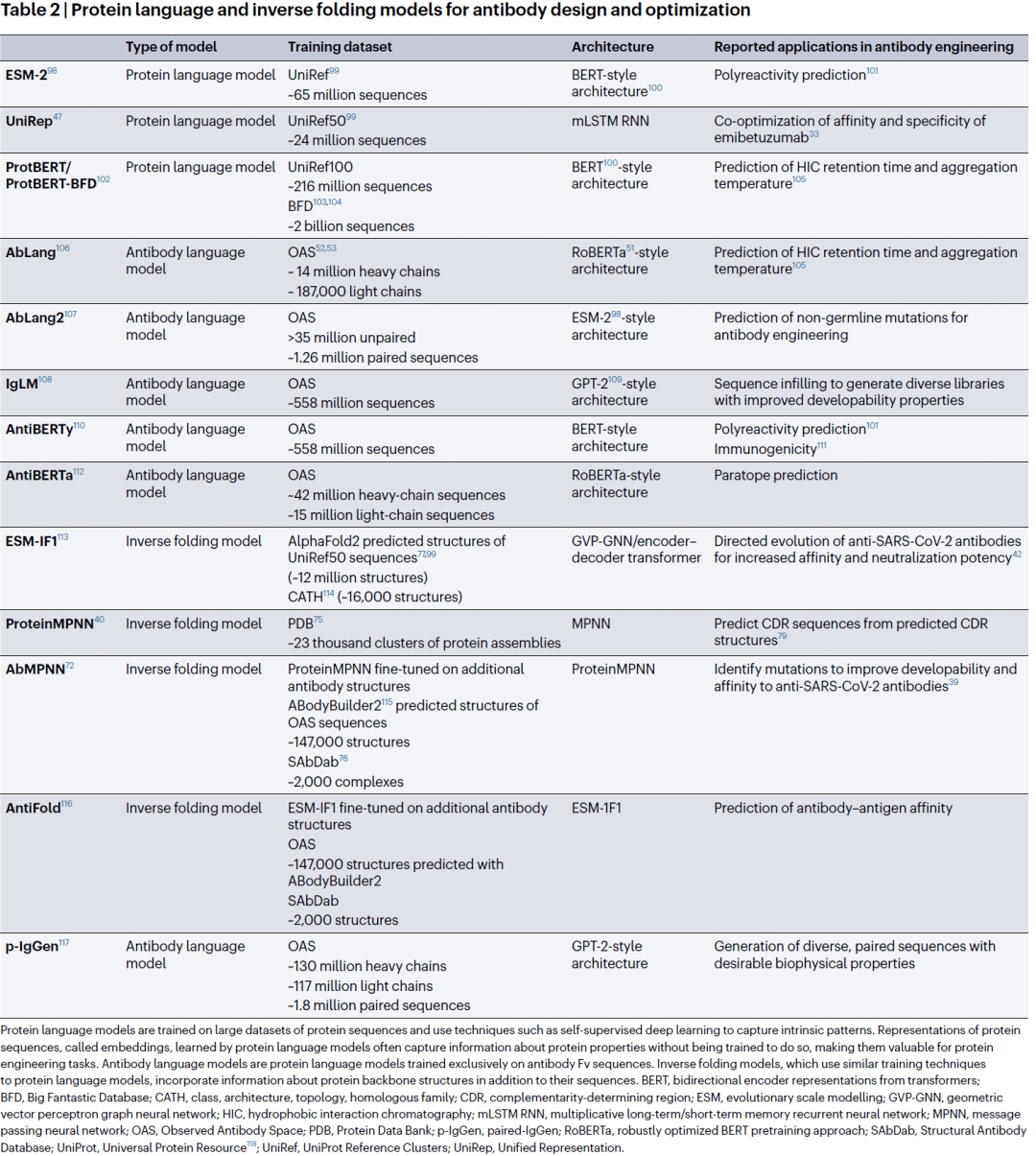
研究人员总结了当前主流模型的发展路线。早期模型包括UniRep、ProtBERT和ESM系列,主要从蛋白序列中学习通用表示。随后出现了专门针对抗体训练的AbLang、AntiBERTy、AntiBERTa和IgLM等模型,它们能够更准确地理解抗体序列特征。
与此同时,逆折叠模型开始将结构信息纳入训练过程。例如ESM-IF1、ProteinMPNN、AbMPNN和AntiFold等模型,可以根据蛋白骨架反向生成序列,从而实现结构约束下的抗体设计。研究表明,这些模型不仅能够提高亲和力预测准确性,还能够直接用于抗体成熟、CDR设计以及成药性优化。
研究人员认为,未来蛋白语言模型与结构生成模型的融合,将成为多目标抗体设计的重要基础设施。
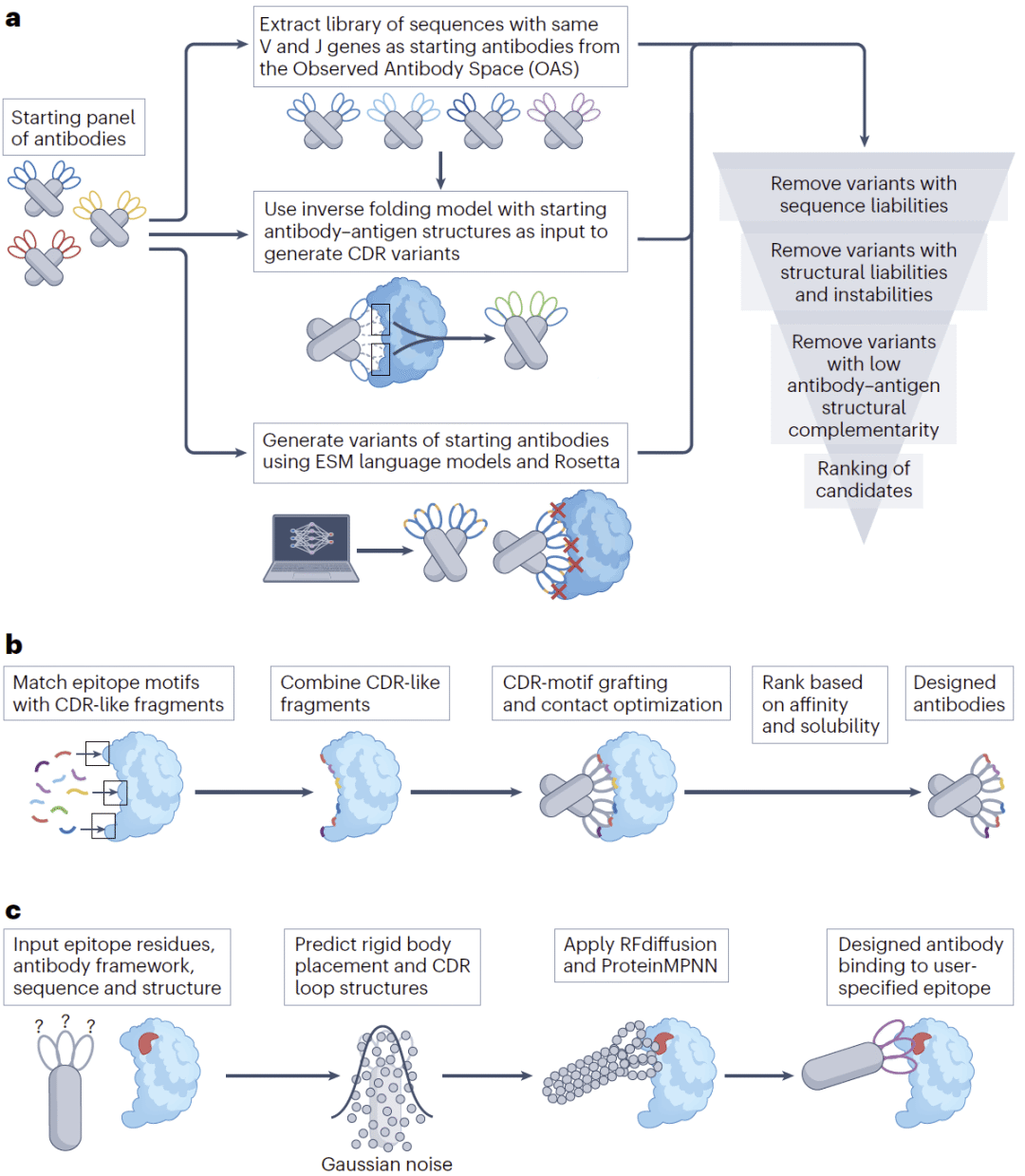
图4:蛋白语言模型与逆折叠模型驱动的抗体设计体系。
展望与讨论
研究人员认为,多目标优化正在成为下一代抗体工程的核心范式。过去的抗体开发通常围绕单一指标进行优化,而未来抗体设计需要同时考虑亲和力、特异性、稳定性、可溶性、表达水平、免疫原性、自聚集倾向以及生产可制造性等多个维度。
当前最成熟的方法仍然依赖实验文库与机器学习结合,但越来越多证据表明,直接预测和从头设计将逐渐成为主流。特别是在GPCR、离子通道、多跨膜蛋白等难靶点领域,传统实验筛选效率有限,而生成式AI能够在更大空间中寻找解决方案。
不过,研究人员也指出,目前AI抗体设计仍处于早期阶段。真正进入临床的AI设计抗体数量仍然有限,大多数方法仍需要实验验证与迭代优化。未来需要更加完善的数据集、更准确的结构预测模型、更可靠的成药性评价体系以及更强的多目标优化算法。
总体而言,机器学习正在推动抗体工程从“筛选驱动”向“设计驱动”转变。未来的理想状态将是:研究人员输入抗原结构和目标需求,AI直接生成同时满足亲和力、稳定性、安全性和可制造性的最佳抗体候选物,从而真正实现抗体药物的智能化设计。
整理 | DrugOne团队
参考资料
Kuo, YH., Brown, C.N., Akin, E. et al. Multi-objective antibody design and optimization using machine learning. Nat Rev Bioeng (2026).
https://doi.org/10.1038/s44222-026-00444-4

内容为【DrugOne】公众号原创|转载请注明来源
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-11,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号