初探千问 | 如何用 API 构建你的第一个智能答疑助手

初探千问 | 如何用 API 构建你的第一个智能答疑助手

dolphin57
发布于 2026-06-23 20:41:05
发布于 2026-06-23 20:41:05
挑战:当知识库变成信息迷宫

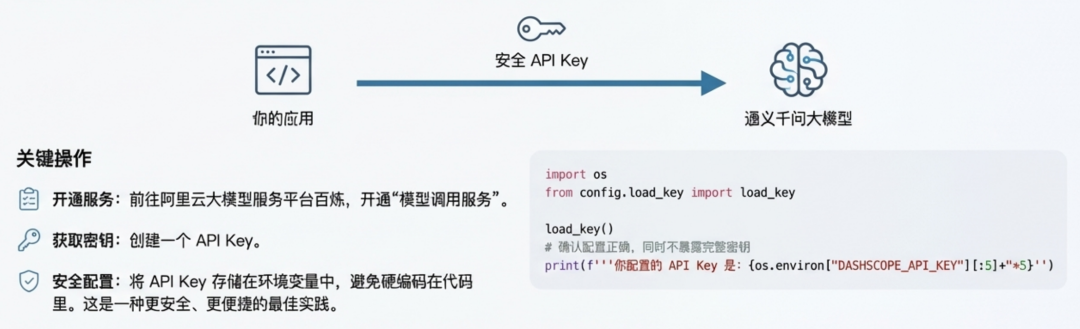
第一步:与大模型建立连接
作为开发者,我们通过 API 将大模型的能力集成到应用中。我们将使用业界广泛采纳的 OpenAl Python SDK 来调用 通义千问大模型。
常见问题
1
ModuleNotFoundError: No module named 'dashscope'
☑ 解决方案: pip install dashscope
首次对话:唤醒"公司小蜜"
创建一个名为“公司小蜜”的助手,赋予其“负责教育内容开发公司的答疑”的角色。
第一个挑战:聪明的"局外人"
现象观察
- 1. 答案不一致:即使问题完全相同, 每次的回答也略有不同。
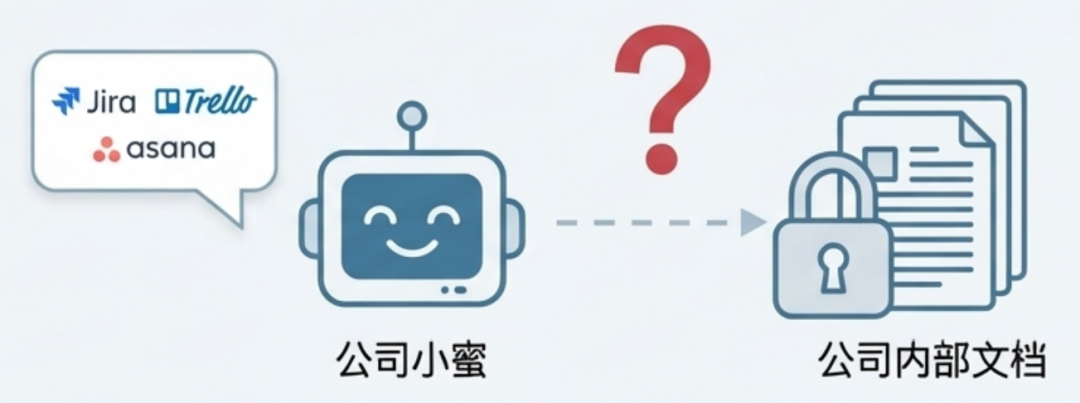
- 2. 缺乏内部知识:当被问及公司项 目管理工具时,模型推荐了 Jira、 Trello 等通用工具,但它并不知 道公司内部推荐使用 Microsoft Project(信息来源: docs/内容开发工程师岗位指导 说明书.pdf`)。
核心矛盾
大模型知识渊博,但其知识仅限于公开的训练数据。它对你公司的内部情况一无所知。
引出问题
- • 为什么大模型的回答会不一致?
- • 我们如何才能让它掌握公司的私有知识?
探究原理:大模型是如何“思考”的?
要解决模型缺乏私域知识和回答不稳定的问题,我们必须先揭开它的“神秘面纱”,理解其工作机制。

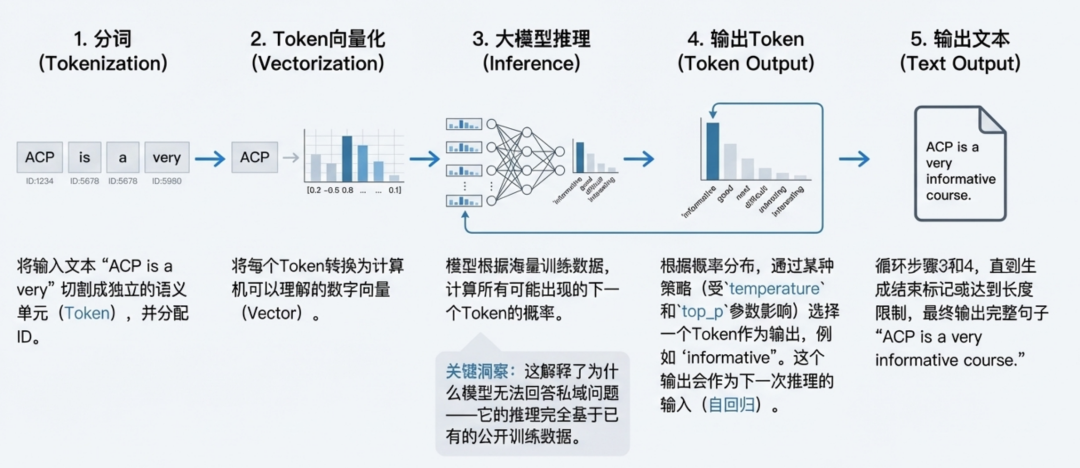
以提问“ACP is a very”为例,我们将有完整解析大模型从接收输入到生成回答的五个核心阶段。

大模型问答的五个阶段
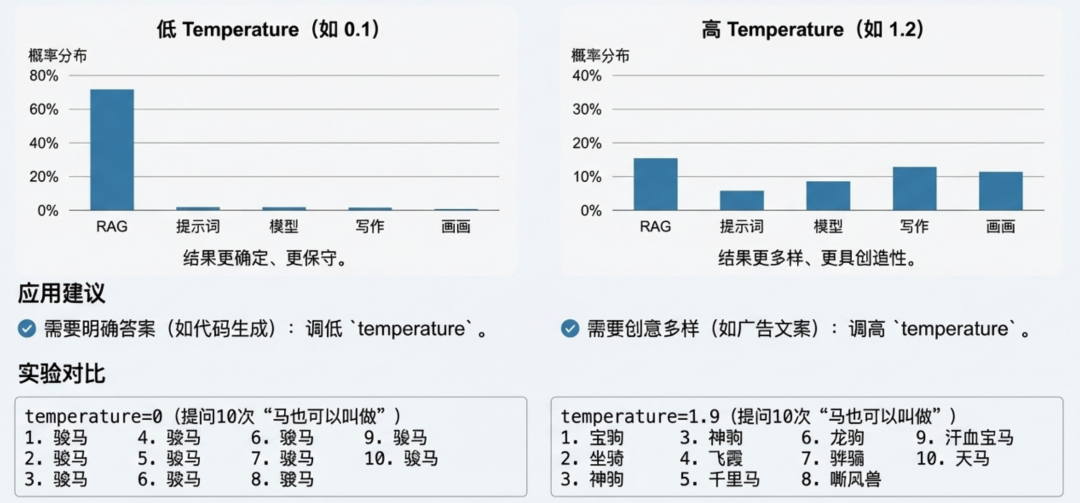
参数调优 ①:用`temperature 控制创造力
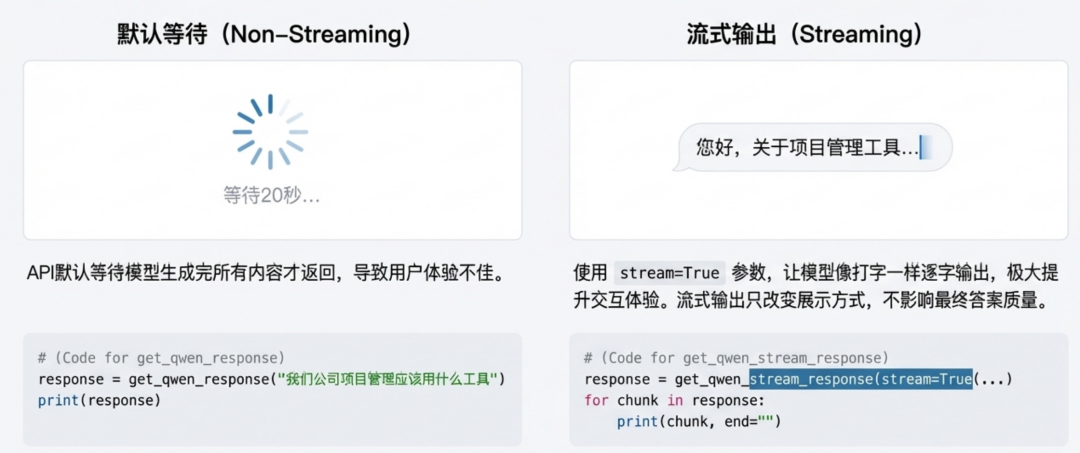
temperature 参数调优①:用 temperature 控制创造力 通过调整候选 Token 的概率分布来控制生成内容的随机性。
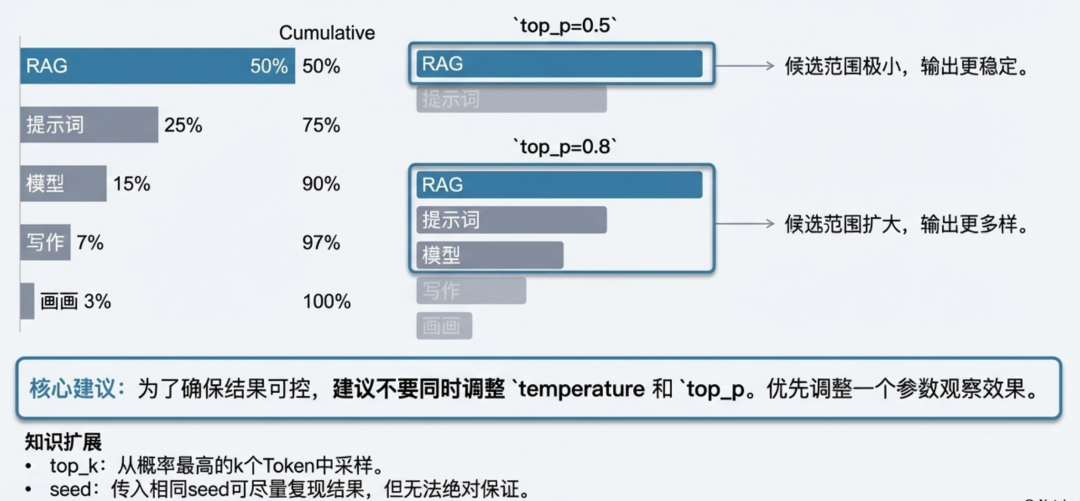
参数调优 ②:用 top_p 筛选候选范围
top_p 是一种筛选机制。它按概率从高到低累加,只在累计概率达到阈值的 Token 中进行采样。
解决方案
回归挑战:直接“喂”给模型内部知识
既然模型不知道内部知识,最直接的方法就是在提问时临时告诉它。

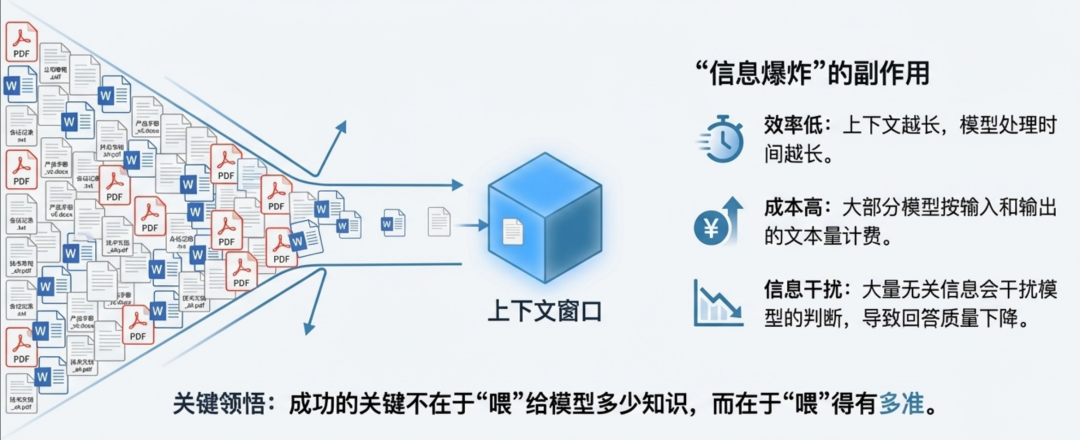
新的瓶颈:无法逾越的上下文窗口 (Context Window)
当你试图将几十上百页的公司文档都用同样的方式“喂”给大模型时,会立即遇到错误。
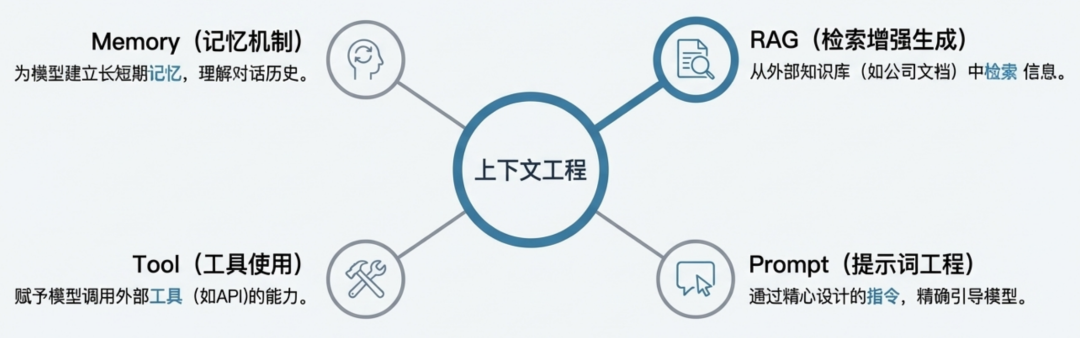
解决之道:上下文工程(Context Engineering)
系统性地设计、构建和优化上下文的实践,旨在正确的时间,将最相关、最精准的知识,动态地加载 到大模型有限的上下文窗口中。
许多大模型应用的失败,并非模型本身不够智能,而是“上下文”的失败。
在我们解决私域知识问答的征途中,RAG 是最直接、最有效的解决方案。
RAG:为大模型配备一位超级研究助理
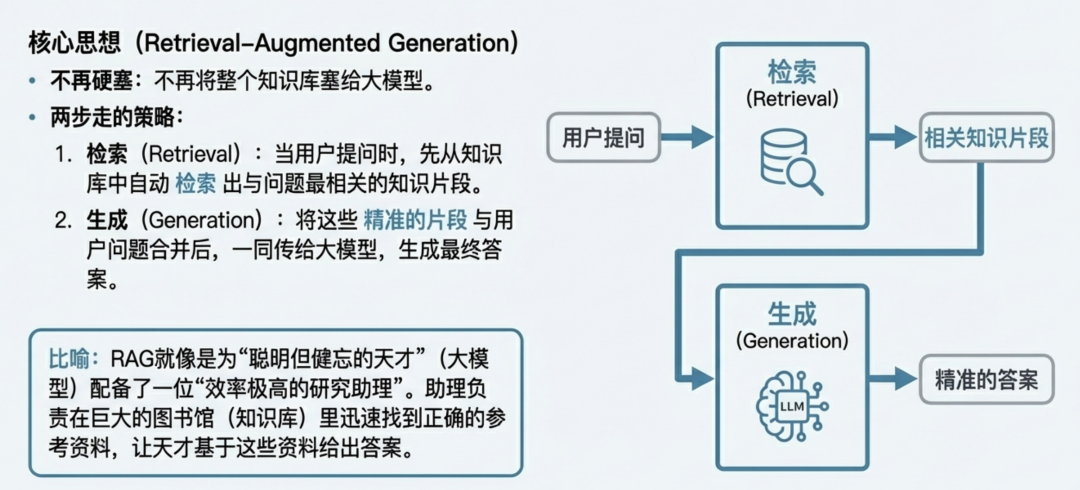
RAG 蓝图第一阶段:建立知识索引(Indexing)
将私有知识文档转换为可以被高效检索的形式。这是一个一次性的离线过程。
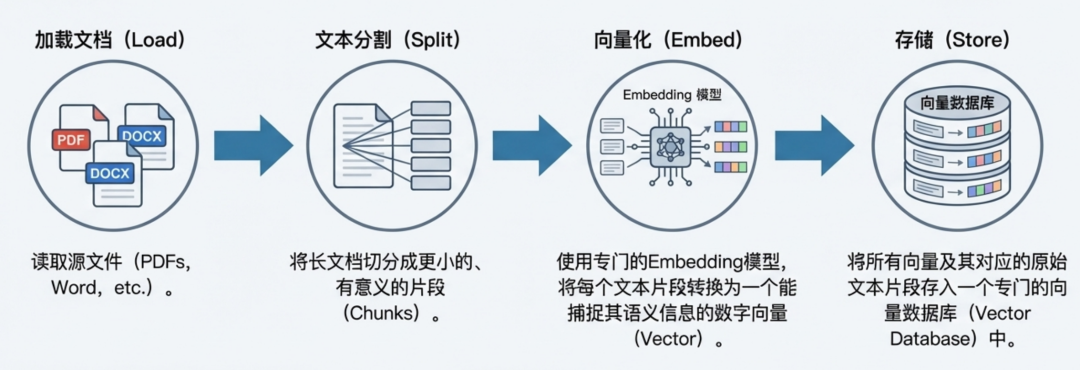
关键: 经过向量化,文本的“语义”被数字化,使得计算机可以通过计算向量间的距离来快速找到内容上最相似的文本片段。
RAG 蓝图第二阶段:检索与生成(Retrieval & Generation)
当用户发起提问时,实时地找到相关知识并生成精准回答。
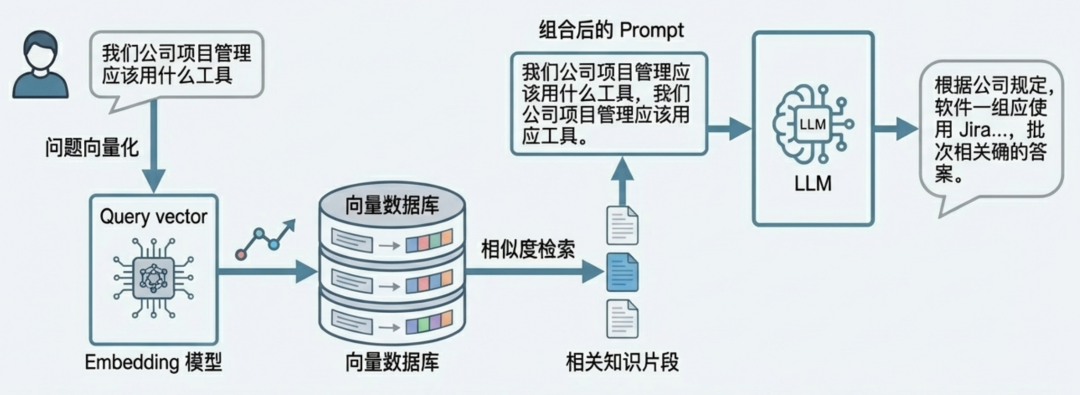
结论:RAG 架构既解决了上下文窗口的限制,又通过精准检索显著提升了回答的准确性和相关性,成功完成了我们的任务。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-12-22,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号