1.5B参数!支持本地实时语音转录

1.5B参数!支持本地实时语音转录

用户11563501
发布于 2026-06-23 11:30:55
发布于 2026-06-23 11:30:55
云端语音转录已经司空见惯,但完全离线的实时转录方案才刚刚成熟。Liquid AI发布的首个端到端音频基础模型LFM2-Audio-1.5B证明了一点:1.5B参数足以在本地设备上处理高质量的端到端音频任务。
它的核心架构包括:
- 语言模型骨干:1.2B参数的LFM2模型
- 音频编码器:基于FastConformer的115M参数编码器
- 音频分词器:使用Kyutai的Mimi,支持8个码本
- 上下文长度:32,768个token
- 支持精度:bfloat16
除了小之外,更重要的是它是一个统一的多模态模型,不需要单独的ASR和TTS组件,既能做语音转文字,也能做文字转语音,还能处理混合的多轮对话。
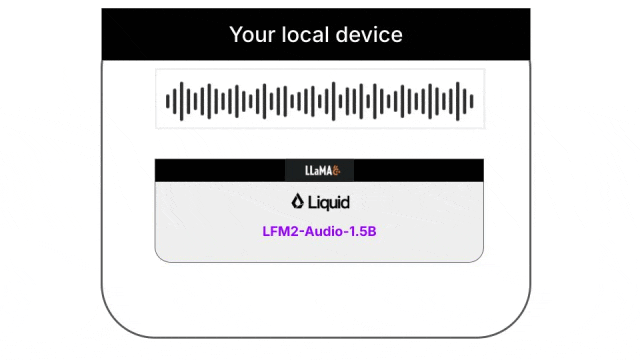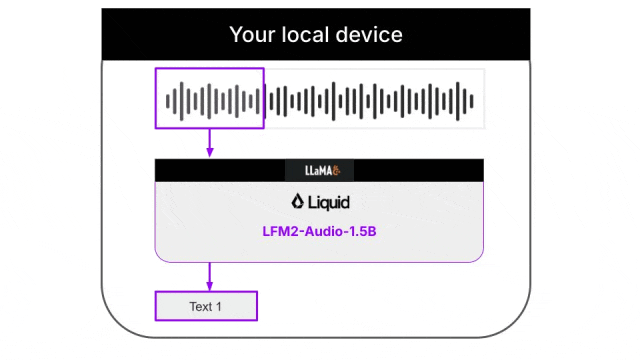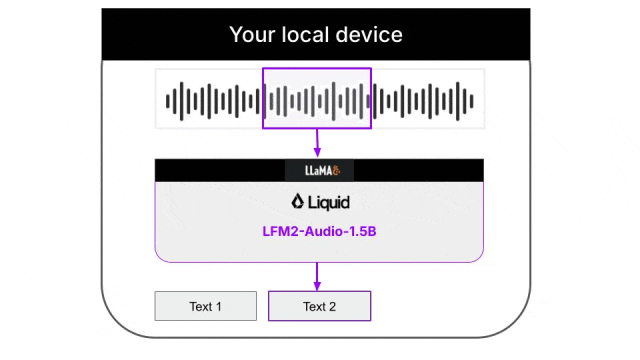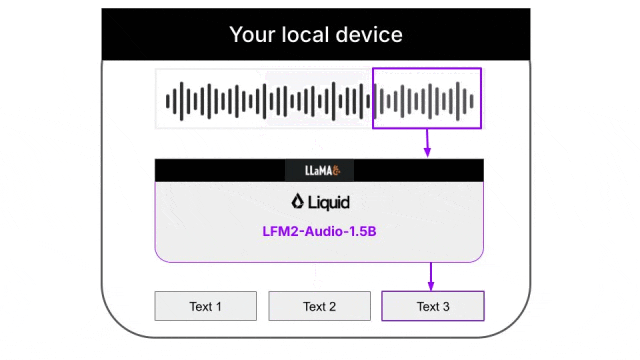
diagram.gif
模型支持两种不同的生成策略:
- 交错生成:文本和音频token按固定模式交替输出,最小化首次音频输出时间,适合实时语音对话
- 顺序生成:模型通过特殊token决定何时切换模态,适合ASR或TTS等非对话任务
这种灵活性让同一个模型能适应不同的使用场景。
从官方介绍看,以下是三种典型场景用法:
1. 语音转文字(ASR)
./llama-lfm2-audio \\
-m $CKPT/LFM2-Audio-1.5B-Q8_0.gguf \\
--mmproj $CKPT/mmproj-audioencoder-LFM2-Audio-1.5B-Q8_0.gguf \\
-mv $CKPT/audiodecoder-LFM2-Audio-1.5B-Q8_0.gguf \\
-sys "Perform ASR." \\
--audio $INPUT_WAV2. 文字转语音(TTS)
./llama-lfm2-audio \\
-m $CKPT/LFM2-Audio-1.5B-Q8_0.gguf \\
--mmproj $CKPT/mmproj-audioencoder-LFM2-Audio-1.5B-Q8_0.gguf \\
-mv $CKPT/audiodecoder-LFM2-Audio-1.5B-Q8_0.gguf \\
-sys "Perform TTS." \\
-p "My name is Pau Labarta Bajo and I love AI" \\
--output $OUTPUT_WAV3. 带语音指令的TTS
./llama-lfm2-audio \\
-m $CKPT/LFM2-Audio-1.5B-Q8_0.gguf \\
--mmproj $CKPT/mmproj-audioencoder-LFM2-Audio-1.5B-Q8_0.gguf \\
-mv $CKPT/audiodecoder-LFM2-Audio-1.5B-Q8_0.gguf \\
-sys "Perform TTS.
Use the following voice: A male speaker delivers a very expressive and animated speech, with a low-pitch voice and a slightly close-sounding tone. The recording carries a slight background noise." \\
-p "What is your name man?" \\
--output $OUTPUT_WAV虽然参数量不大,但性能不输竞争者。在VoiceBench音频输入测试中,LFM2-Audio-1.5B的综合得分达到56.78,超越了7B参数的Moshi模型(29.51分)。在ASR任务上,它的平均词错率(WER)为7.24%,与专门的Whisper-large-V3(7.93%)相当。
更有意思的对比是与Qwen2.5-Omni-3B的较量。后者参数量是LFM2的3倍多,但在多数指标上两者表现接近,这证明了Liquid AI在模型效率优化上的功力。
不过当前该模型还仅支持英文,在使用场景上有所限制。
小结
本地优先是很多应用追求的理念。确保数据隐私,不依赖网络的优势使得这类方案有大量的场景。
对于AI来讲,本地优先也将会成为重要的流行趋势。对于寻找此类解决方案的朋友可以关注。
地址:https://github.com/Liquid4All/liquid-audio
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-01-06,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号